 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelatedly: Scaffolding Literature Reviews with Existing Related Work Sections
Feb 13, 2023Scholars who want to research a scientific topic must take time to read, extract meaning, and identify connections across many papers. As scientific literature grows, this becomes increasingly challenging. Meanwhile, authors summarize prior research in papers' related work sections, though this is scoped to support a single paper. A formative study found that while reading multiple related work paragraphs helps overview a topic, it is hard to navigate overlapping and diverging references and research foci. In this work, we design a system, Relatedly, that scaffolds exploring and reading multiple related work paragraphs on a topic, with features including dynamic re-ranking and highlighting to spotlight unexplored dissimilar information, auto-generated descriptive paragraph headings, and low-lighting of redundant information. From a within-subjects user study (n=15), we found that scholars generate more coherent, insightful, and comprehensive topic outlines using Relatedly compared to a baseline paper list.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Dec 19, 2022Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.
SciRepEval: A Multi-Format Benchmark for Scientific Document Representations
Nov 23, 2022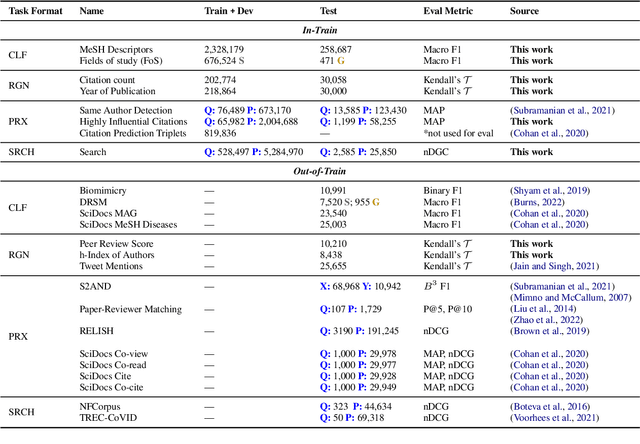
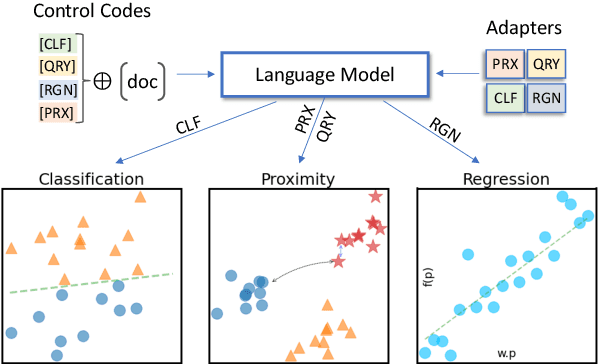
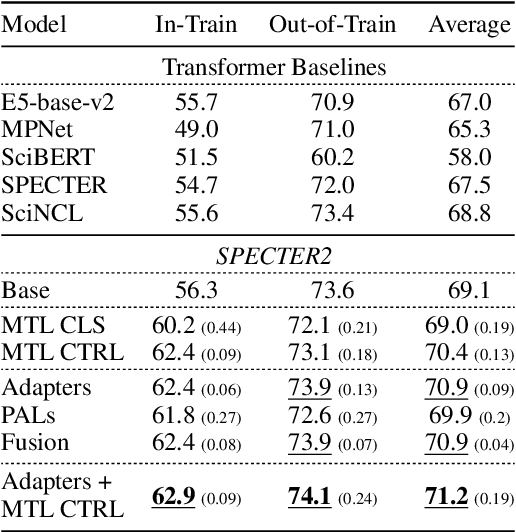
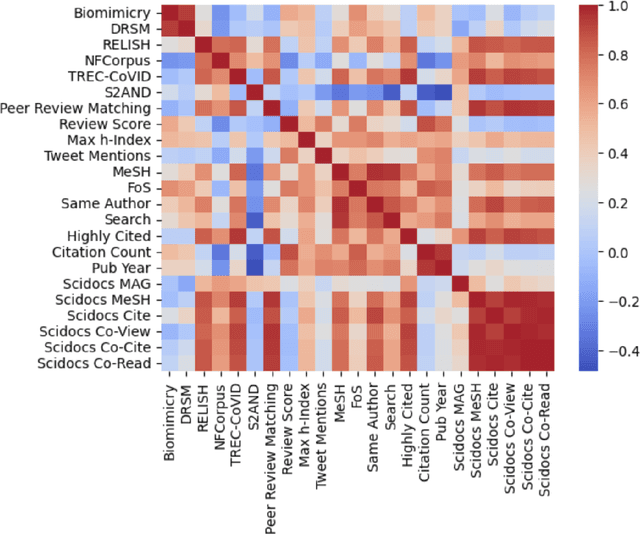
Learned representations of scientific documents can serve as valuable input features for downstream tasks, without the need for further fine-tuning. However, existing benchmarks for evaluating these representations fail to capture the diversity of relevant tasks. In response, we introduce SciRepEval, the first comprehensive benchmark for training and evaluating scientific document representations. It includes 25 challenging and realistic tasks, 11 of which are new, across four formats: classification, regression, ranking and search. We then use the benchmark to study and improve the generalization ability of scientific document representation models. We show how state-of-the-art models struggle to generalize across task formats, and that simple multi-task training fails to improve them. However, a new approach that learns multiple embeddings per document, each tailored to a different format, can improve performance. We experiment with task-format-specific control codes and adapters in a multi-task setting and find that they outperform the existing single-embedding state-of-the-art by up to 1.5 points absolute.
Learning to Perform Complex Tasks through Compositional Fine-Tuning of Language Models
Oct 23, 2022



How to usefully encode compositional task structure has long been a core challenge in AI. Recent work in chain of thought prompting has shown that for very large neural language models (LMs), explicitly demonstrating the inferential steps involved in a target task may improve performance over end-to-end learning that focuses on the target task alone. However, chain of thought prompting has significant limitations due to its dependency on huge pretrained LMs. In this work, we present compositional fine-tuning (CFT): an approach based on explicitly decomposing a target task into component tasks, and then fine-tuning smaller LMs on a curriculum of such component tasks. We apply CFT to recommendation tasks in two domains, world travel and local dining, as well as a previously studied inferential task (sports understanding). We show that CFT outperforms end-to-end learning even with equal amounts of data, and gets consistently better as more component tasks are modeled via fine-tuning. Compared with chain of thought prompting, CFT performs at least as well using LMs only 7.4% of the size, and is moreover applicable to task domains for which data are not available during pretraining.
FeedLens: Polymorphic Lenses for Personalizing Exploratory Search over Knowledge Graphs
Aug 16, 2022
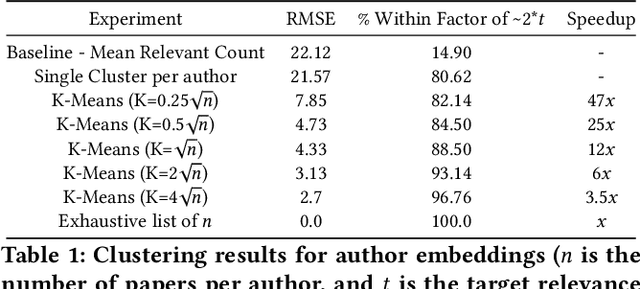

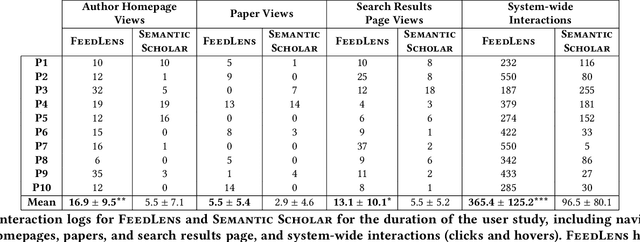
The vast scale and open-ended nature of knowledge graphs (KGs) make exploratory search over them cognitively demanding for users. We introduce a new technique, polymorphic lenses, that improves exploratory search over a KG by obtaining new leverage from the existing preference models that KG-based systems maintain for recommending content. The approach is based on a simple but powerful observation: in a KG, preference models can be re-targeted to recommend not only entities of a single base entity type (e.g., papers in the scientific literature KG, products in an e-commerce KG), but also all other types (e.g., authors, conferences, institutions; sellers, buyers). We implement our technique in a novel system, FeedLens, which is built over Semantic Scholar, a production system for navigating the scientific literature KG. FeedLens reuses the existing preference models on Semantic Scholar -- people's curated research feeds -- as lenses for exploratory search. Semantic Scholar users can curate multiple feeds/lenses for different topics of interest, e.g., one for human-centered AI and another for document embeddings. Although these lenses are defined in terms of papers, FeedLens re-purposes them to also guide search over authors, institutions, venues, etc. Our system design is based on feedback from intended users via two pilot surveys (n=17 and n=13, respectively). We compare FeedLens and Semantic Scholar via a third (within-subjects) user study (n=15) and find that FeedLens increases user engagement while reducing the cognitive effort required to complete a short literature review task. Our qualitative results also highlight people's preference for this more effective exploratory search experience enabled by FeedLens.
Embedding Recycling for Language Models
Jul 11, 2022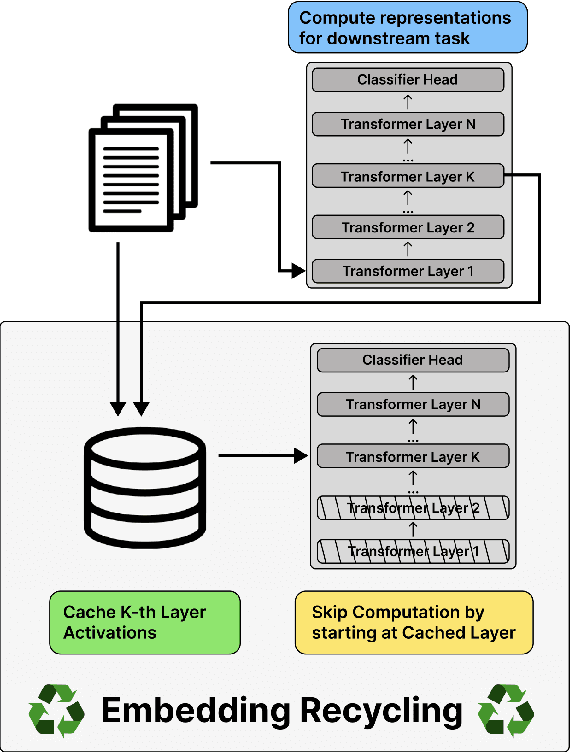
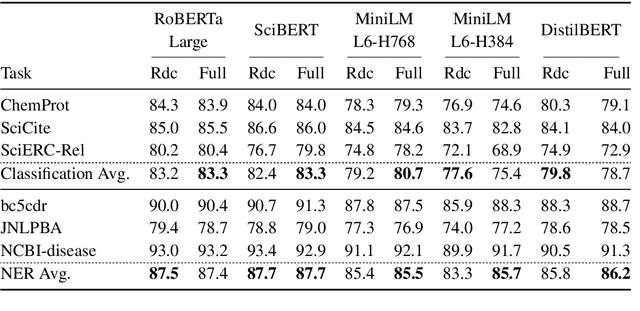
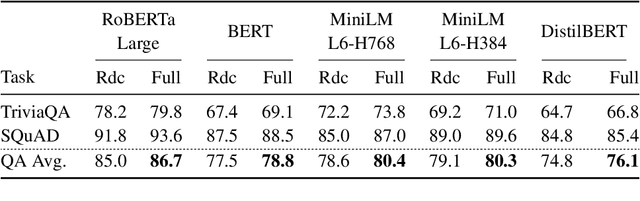
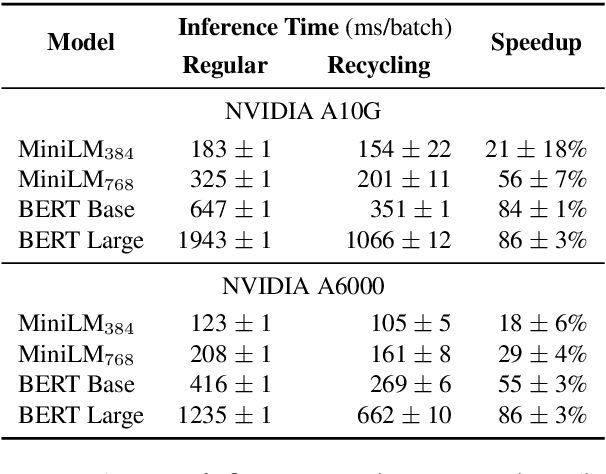
Training and inference with large neural models is expensive. However, for many application domains, while new tasks and models arise frequently, the underlying documents being modeled remain mostly unchanged. We study how to decrease computational cost in such settings through embedding recycling (ER): re-using activations from previous model runs when performing training or inference. In contrast to prior work focusing on freezing small classification heads for finetuning which often leads to notable drops in performance, we propose caching an intermediate layer's output from a pretrained model and finetuning the remaining layers for new tasks. We show that our method provides a 100% speedup during training and a 55-86% speedup for inference, and has negligible impacts on accuracy for text classification and entity recognition tasks in the scientific domain. For general-domain question answering tasks, ER offers a similar speedup and lowers accuracy by a small amount. Finally, we identify several open challenges and future directions for ER.
Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities
Jun 23, 2022
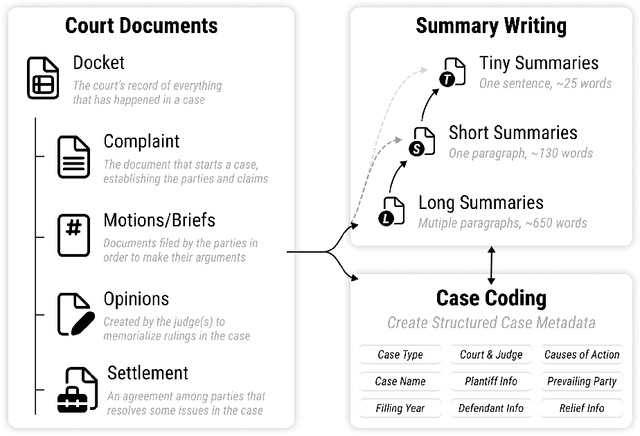


With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC) (https://clearinghouse.net),which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further research in summarization methods as well as to facilitate development of applications to assist in the CRLC's mission at https://multilexsum.github.io.
Penguins Don't Fly: Reasoning about Generics through Instantiations and Exceptions
May 23, 2022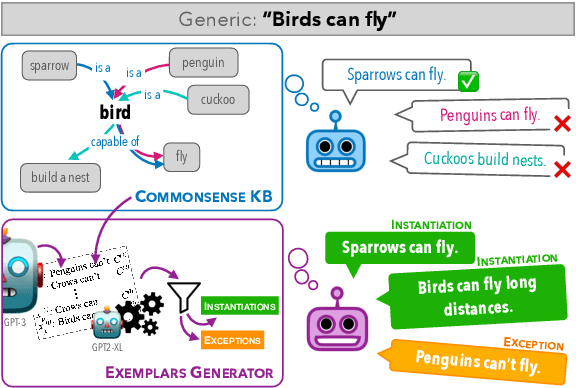


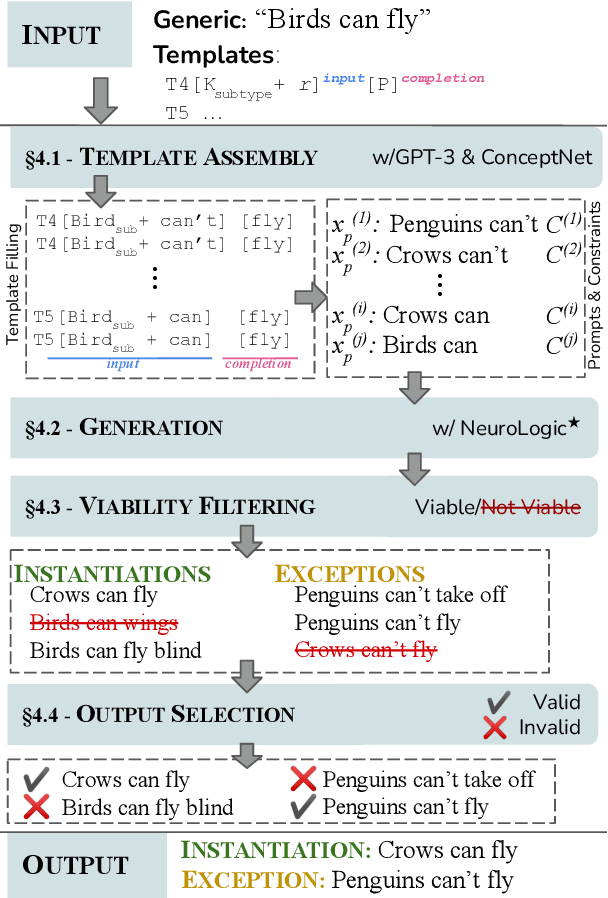
Generics express generalizations about the world (e.g., "birds can fly"). However, they are not universally true -- while sparrows and penguins are both birds, only sparrows can fly and penguins cannot. Commonsense knowledge bases, which are used extensively in many NLP tasks as a source of world-knowledge, can often encode generic knowledge but, by-design, cannot encode such exceptions. Therefore, it is crucial to realize the specific instances when a generic statement is true or false. In this work, we present a novel framework to generate pragmatically relevant true and false instances of a generic. We use pre-trained language models, constraining the generation based on insights from linguistic theory, and produce ${\sim}20k$ exemplars for ${\sim}650$ generics. Our system outperforms few-shot generation from GPT-3 (by 12.5 precision points) and our analysis highlights the importance of constrained decoding for this task and the implications of generics exemplars for language inference tasks.
CascadER: Cross-Modal Cascading for Knowledge Graph Link Prediction
May 16, 2022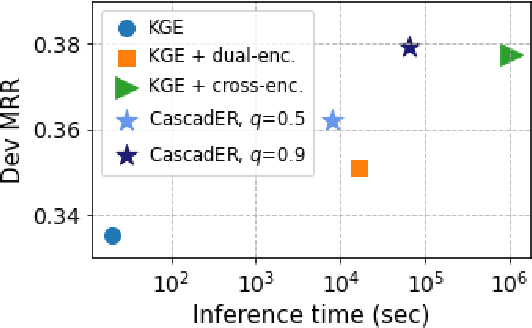
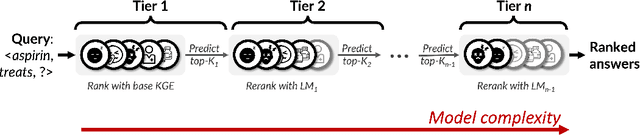
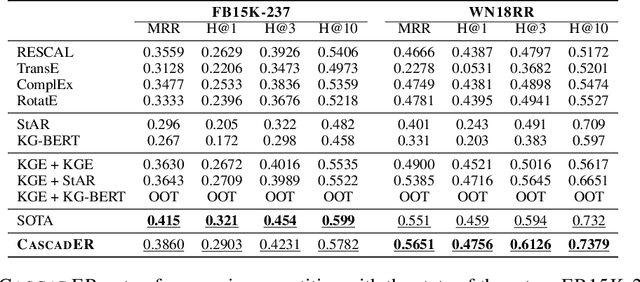
Knowledge graph (KG) link prediction is a fundamental task in artificial intelligence, with applications in natural language processing, information retrieval, and biomedicine. Recently, promising results have been achieved by leveraging cross-modal information in KGs, using ensembles that combine knowledge graph embeddings (KGEs) and contextual language models (LMs). However, existing ensembles are either (1) not consistently effective in terms of ranking accuracy gains or (2) impractically inefficient on larger datasets due to the combinatorial explosion problem of pairwise ranking with deep language models. In this paper, we propose a novel tiered ranking architecture CascadER to maintain the ranking accuracy of full ensembling while improving efficiency considerably. CascadER uses LMs to rerank the outputs of more efficient base KGEs, relying on an adaptive subset selection scheme aimed at invoking the LMs minimally while maximizing accuracy gain over the KGE. Extensive experiments demonstrate that CascadER improves MRR by up to 9 points over KGE baselines, setting new state-of-the-art performance on four benchmarks while improving efficiency by one or more orders of magnitude over competitive cross-modal baselines. Our empirical analyses reveal that diversity of models across modalities and preservation of individual models' confidence signals help explain the effectiveness of CascadER, and suggest promising directions for cross-modal cascaded architectures. Code and pretrained models are available at https://github.com/tsafavi/cascader.