 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawLLM: Law Large Language Model for the US Legal System
Jul 27, 2024



In the rapidly evolving field of legal analytics, finding relevant cases and accurately predicting judicial outcomes are challenging because of the complexity of legal language, which often includes specialized terminology, complex syntax, and historical context. Moreover, the subtle distinctions between similar and precedent cases require a deep understanding of legal knowledge. Researchers often conflate these concepts, making it difficult to develop specialized techniques to effectively address these nuanced tasks. In this paper, we introduce the Law Large Language Model (LawLLM), a multi-task model specifically designed for the US legal domain to address these challenges. LawLLM excels at Similar Case Retrieval (SCR), Precedent Case Recommendation (PCR), and Legal Judgment Prediction (LJP). By clearly distinguishing between precedent and similar cases, we provide essential clarity, guiding future research in developing specialized strategies for these tasks. We propose customized data preprocessing techniques for each task that transform raw legal data into a trainable format. Furthermore, we also use techniques such as in-context learning (ICL) and advanced information retrieval methods in LawLLM. The evaluation results demonstrate that LawLLM consistently outperforms existing baselines in both zero-shot and few-shot scenarios, offering unparalleled multi-task capabilities and filling critical gaps in the legal domain.
Sentiment analysis with adaptive multi-head attention in Transformer
Oct 23, 2023
We propose a novel framework based on the attention mechanism to identify the sentiment of a movie review document. Previous efforts on deep neural networks with attention mechanisms focus on encoder and decoder with fixed numbers of multi-head attention. Therefore, we need a mechanism to stop the attention process automatically if no more useful information can be read from the memory.In this paper, we propose an adaptive multi-head attention architecture (AdaptAttn) which varies the number of attention heads based on length of sentences. AdaptAttn has a data preprocessing step where each document is classified into any one of the three bins small, medium or large based on length of the sentence. The document classified as small goes through two heads in each layer, the medium group passes four heads and the large group is processed by eight heads. We examine the merit of our model on the Stanford large movie review dataset. The experimental results show that the F1 score from our model is on par with the baseline model.
Summarization from Leaderboards to Practice: Choosing A Representation Backbone and Ensuring Robustness
Jun 18, 2023



Academic literature does not give much guidance on how to build the best possible customer-facing summarization system from existing research components. Here we present analyses to inform the selection of a system backbone from popular models; we find that in both automatic and human evaluation, BART performs better than PEGASUS and T5. We also find that when applied cross-domain, summarizers exhibit considerably worse performance. At the same time, a system fine-tuned on heterogeneous domains performs well on all domains and will be most suitable for a broad-domain summarizer. Our work highlights the need for heterogeneous domain summarization benchmarks. We find considerable variation in system output that can be captured only with human evaluation and are thus unlikely to be reflected in standard leaderboards with only automatic evaluation.
Learning to Perform Complex Tasks through Compositional Fine-Tuning of Language Models
Oct 23, 2022



How to usefully encode compositional task structure has long been a core challenge in AI. Recent work in chain of thought prompting has shown that for very large neural language models (LMs), explicitly demonstrating the inferential steps involved in a target task may improve performance over end-to-end learning that focuses on the target task alone. However, chain of thought prompting has significant limitations due to its dependency on huge pretrained LMs. In this work, we present compositional fine-tuning (CFT): an approach based on explicitly decomposing a target task into component tasks, and then fine-tuning smaller LMs on a curriculum of such component tasks. We apply CFT to recommendation tasks in two domains, world travel and local dining, as well as a previously studied inferential task (sports understanding). We show that CFT outperforms end-to-end learning even with equal amounts of data, and gets consistently better as more component tasks are modeled via fine-tuning. Compared with chain of thought prompting, CFT performs at least as well using LMs only 7.4% of the size, and is moreover applicable to task domains for which data are not available during pretraining.
Stolen Probability: A Structural Weakness of Neural Language Models
May 05, 2020

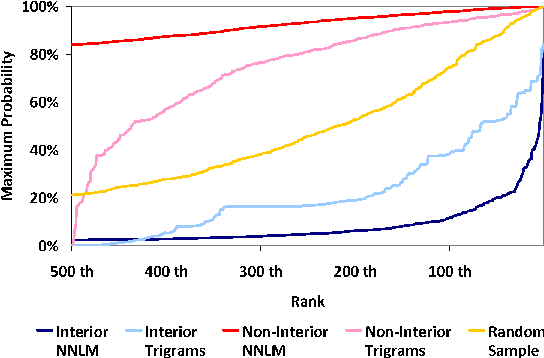

Neural Network Language Models (NNLMs) generate probability distributions by applying a softmax function to a distance metric formed by taking the dot product of a prediction vector with all word vectors in a high-dimensional embedding space. The dot-product distance metric forms part of the inductive bias of NNLMs. Although NNLMs optimize well with this inductive bias, we show that this results in a sub-optimal ordering of the embedding space that structurally impoverishes some words at the expense of others when assigning probability. We present numerical, theoretical and empirical analyses showing that words on the interior of the convex hull in the embedding space have their probability bounded by the probabilities of the words on the hull.
Just Add Functions: A Neural-Symbolic Language Model
Dec 11, 2019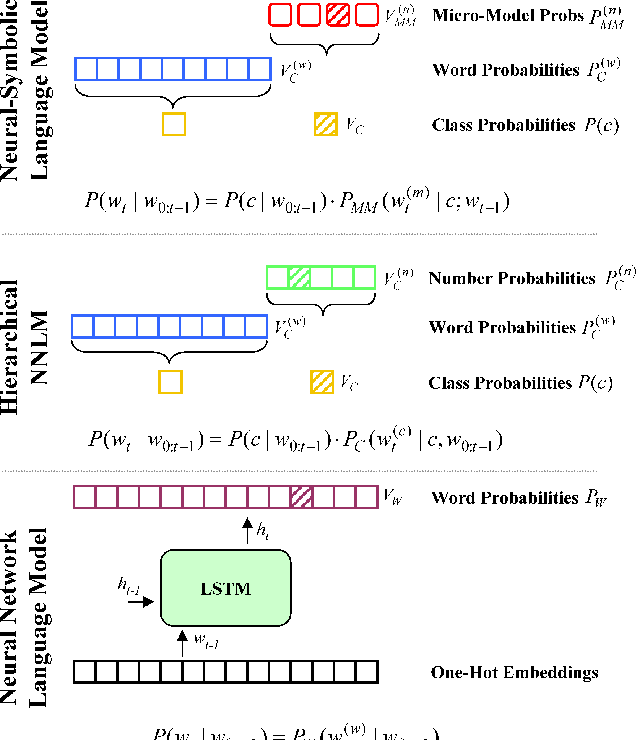

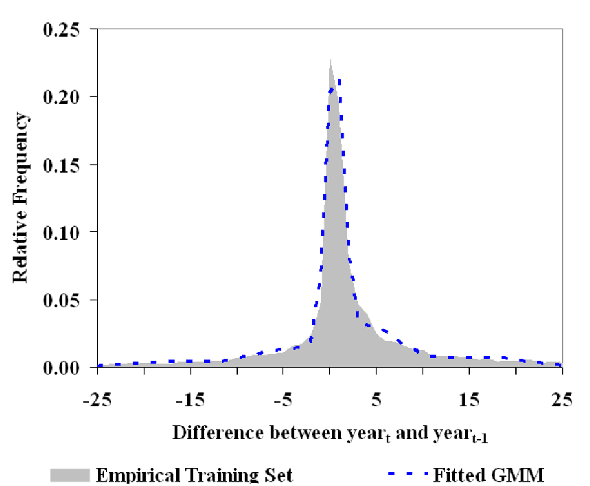
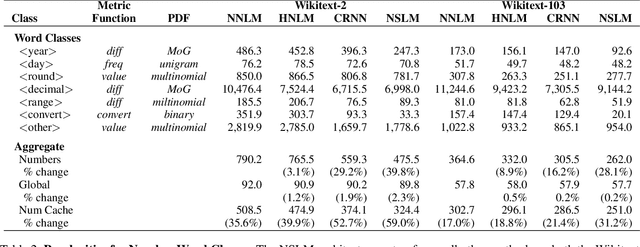
Neural network language models (NNLMs) have achieved ever-improving accuracy due to more sophisticated architectures and increasing amounts of training data. However, the inductive bias of these models (formed by the distributional hypothesis of language), while ideally suited to modeling most running text, results in key limitations for today's models. In particular, the models often struggle to learn certain spatial, temporal, or quantitative relationships, which are commonplace in text and are second-nature for human readers. Yet, in many cases, these relationships can be encoded with simple mathematical or logical expressions. How can we augment today's neural models with such encodings? In this paper, we propose a general methodology to enhance the inductive bias of NNLMs by incorporating simple functions into a neural architecture to form a hierarchical neural-symbolic language model (NSLM). These functions explicitly encode symbolic deterministic relationships to form probability distributions over words. We explore the effectiveness of this approach on numbers and geographic locations, and show that NSLMs significantly reduce perplexity in small-corpus language modeling, and that the performance improvement persists for rare tokens even on much larger corpora. The approach is simple and general, and we discuss how it can be applied to other word classes beyond numbers and geography.