 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Optimal Regret for Learning Adversarial MDPs with Linear Function Approximation
Feb 17, 2021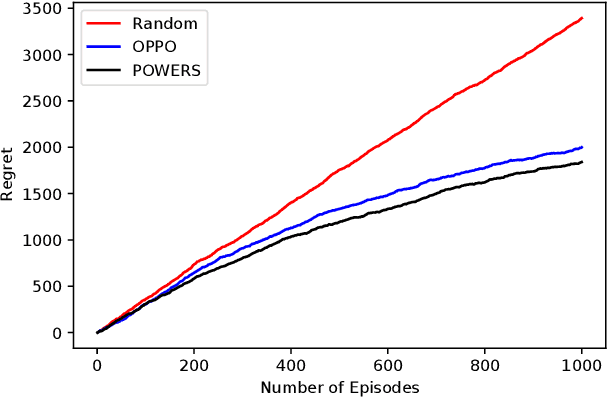
We study the reinforcement learning for finite-horizon episodic Markov decision processes with adversarial reward and full information feedback, where the unknown transition probability function is a linear function of a given feature mapping. We propose an optimistic policy optimization algorithm with Bernstein bonus and show that it can achieve $\tilde{O}(dH\sqrt{T})$ regret, where $H$ is the length of the episode, $T$ is the number of interaction with the MDP and $d$ is the dimension of the feature mapping. Furthermore, we also prove a matching lower bound of $\tilde{\Omega}(dH\sqrt{T})$ up to logarithmic factors. To the best of our knowledge, this is the first computationally efficient, nearly minimax optimal algorithm for adversarial Markov decision processes with linear function approximation.
Almost Optimal Algorithms for Two-player Markov Games with Linear Function Approximation
Feb 15, 2021We study reinforcement learning for two-player zero-sum Markov games with simultaneous moves in the finite-horizon setting, where the transition kernel of the underlying Markov games can be parameterized by a linear function over the current state, both players' actions and the next state. In particular, we assume that we can control both players and aim to find the Nash Equilibrium by minimizing the duality gap. We propose an algorithm Nash-UCRL-VTR based on the principle "Optimism-in-Face-of-Uncertainty". Our algorithm only needs to find a Coarse Correlated Equilibrium (CCE), which is computationally very efficient. Specifically, we show that Nash-UCRL-VTR can provably achieve an $\tilde{O}(dH\sqrt{T})$ regret, where $d$ is the linear function dimension, $H$ is the length of the game and $T$ is the total number of steps in the game. To access the optimality of our algorithm, we also prove an $\tilde{\Omega}( dH\sqrt{T})$ lower bound on the regret. Our upper bound matches the lower bound up to logarithmic factors, which suggests the optimality of our algorithm.
Nearly Minimax Optimal Regret for Learning Infinite-horizon Average-reward MDPs with Linear Function Approximation
Feb 15, 2021
We study reinforcement learning in an infinite-horizon average-reward setting with linear function approximation, where the transition probability function of the underlying Markov Decision Process (MDP) admits a linear form over a feature mapping of the current state, action, and next state. We propose a new algorithm UCRL2-VTR, which can be seen as an extension of the UCRL2 algorithm with linear function approximation. We show that UCRL2-VTR with Bernstein-type bonus can achieve a regret of $\tilde{O}(d\sqrt{DT})$, where $d$ is the dimension of the feature mapping, $T$ is the horizon, and $\sqrt{D}$ is the diameter of the MDP. We also prove a matching lower bound $\tilde{\Omega}(d\sqrt{DT})$, which suggests that the proposed UCRL2-VTR is minimax optimal up to logarithmic factors. To the best of our knowledge, our algorithm is the first nearly minimax optimal RL algorithm with function approximation in the infinite-horizon average-reward setting.
Nearly Minimax Optimal Reinforcement Learning for Linear Mixture Markov Decision Processes
Jan 07, 2021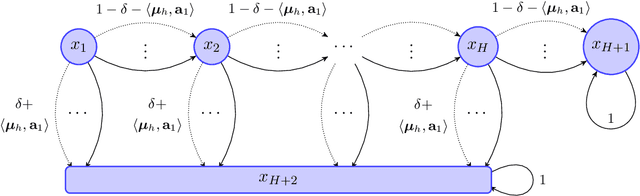
We study reinforcement learning (RL) with linear function approximation where the underlying transition probability kernel of the Markov decision process (MDP) is a linear mixture model (Jia et al., 2020; Ayoub et al., 2020; Zhou et al., 2020) and the learning agent has access to either an integration or a sampling oracle of the individual basis kernels. We propose a new Bernstein-type concentration inequality for self-normalized martingales for linear bandit problems with bounded noise. Based on the new inequality, we propose a new, computationally efficient algorithm with linear function approximation named $\text{UCRL-VTR}^{+}$ for the aforementioned linear mixture MDPs in the episodic undiscounted setting. We show that $\text{UCRL-VTR}^{+}$ attains an $\tilde O(dH\sqrt{T})$ regret where $d$ is the dimension of feature mapping, $H$ is the length of the episode and $T$ is the number of interactions with the MDP. We also prove a matching lower bound $\Omega(dH\sqrt{T})$ for this setting, which shows that $\text{UCRL-VTR}^{+}$ is minimax optimal up to logarithmic factors. In addition, we propose the $\text{UCLK}^{+}$ algorithm for the same family of MDPs under discounting and show that it attains an $\tilde O(d\sqrt{T}/(1-\gamma)^{1.5})$ regret, where $\gamma\in [0,1)$ is the discount factor. Our upper bound matches the lower bound $\Omega(d\sqrt{T}/(1-\gamma)^{1.5})$ proved by Zhou et al. (2020) up to logarithmic factors, suggesting that $\text{UCLK}^{+}$ is nearly minimax optimal. To the best of our knowledge, these are the first computationally efficient, nearly minimax optimal algorithms for RL with linear function approximation.
Provably Efficient Reinforcement Learning with Linear Function Approximation Under Adaptivity Constraints
Jan 06, 2021We study reinforcement learning (RL) with linear function approximation under the adaptivity constraint. We consider two popular limited adaptivity models: batch learning model and rare policy switch model, and propose two efficient online RL algorithms for linear Markov decision processes. In specific, for the batch learning model, our proposed LSVI-UCB-Batch algorithm achieves an $\tilde O(\sqrt{d^3H^3T} + dHT/B)$ regret, where $d$ is the dimension of the feature mapping, $H$ is the episode length, $T$ is the number of interactions and $B$ is the number of batches. Our result suggests that it suffices to use only $\sqrt{T/dH}$ batches to obtain $\tilde O(\sqrt{d^3H^3T})$ regret. For the rare policy switch model, our proposed LSVI-UCB-RareSwitch algorithm enjoys an $\tilde O(\sqrt{d^3H^3T[1+T/(dH)]^{dH/B}})$ regret, which implies that $dH\log T$ policy switches suffice to obtain the $\tilde O(\sqrt{d^3H^3T})$ regret. Our algorithms achieve the same regret as the LSVI-UCB algorithm (Jin et al., 2019), yet with a substantially smaller amount of adaptivity.
Logarithmic Regret for Reinforcement Learning with Linear Function Approximation
Nov 23, 2020Reinforcement learning (RL) with linear function approximation has received increasing attention recently. However, existing work has focused on obtaining $\sqrt{T}$-type regret bound, where $T$ is the number of steps. In this paper, we show that logarithmic regret is attainable under two recently proposed linear MDP assumptions provided that there exists a positive sub-optimality gap for the optimal action-value function. In specific, under the linear MDP assumption (Jin et al. 2019), the LSVI-UCB algorithm can achieve $\tilde{O}(d^{3}H^5/\text{gap}_{\text{min}}\cdot \log(T))$ regret; and under the linear mixture model assumption (Ayoub et al. 2020), the UCRL-VTR algorithm can achieve $\tilde{O}(d^{2}H^5/\text{gap}_{\text{min}}\cdot \log^3(T))$ regret, where $d$ is the dimension of feature mapping, $H$ is the length of episode, and $\text{gap}_{\text{min}}$ is the minimum of sub-optimality gap. To the best of our knowledge, these are the first logarithmic regret bounds for RL with linear function approximation.
Provable Multi-Objective Reinforcement Learning with Generative Models
Nov 19, 2020Multi-objective reinforcement learning (MORL) is an extension of ordinary, single-objective reinforcement learning (RL) that is applicable to many real world tasks where multiple objectives exist without known relative costs. We study the problem of single policy MORL, which learns an optimal policy given the preference of objectives. Existing methods require strong assumptions such as exact knowledge of the multi-objective Markov decision process, and are analyzed in the limit of infinite data and time. We propose a new algorithm called model-based envelop value iteration (EVI), which generalizes the enveloped multi-objective $Q$-learning algorithm in Yang, 2019. Our method can learn a near-optimal value function with polynomial sample complexity and linear convergence speed. To the best of our knowledge, this is the first finite-sample analysis of MORL algorithms.
Neural Thompson Sampling
Oct 02, 2020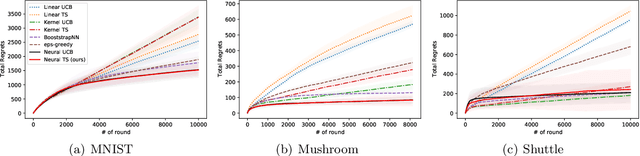
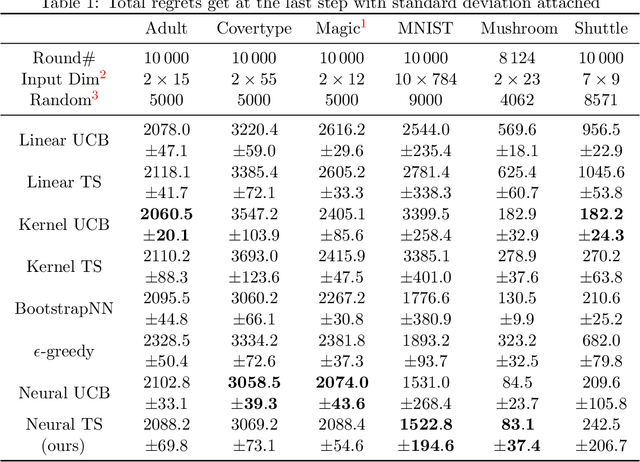
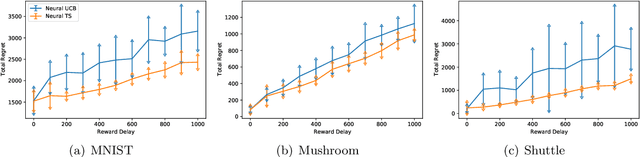
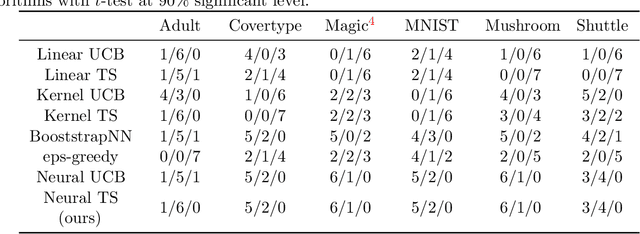
Thompson Sampling (TS) is one of the most effective algorithms for solving contextual multi-armed bandit problems. In this paper, we propose a new algorithm, called Neural Thompson Sampling, which adapts deep neural networks for both exploration and exploitation. At the core of our algorithm is a novel posterior distribution of the reward, where its mean is the neural network approximator, and its variance is built upon the neural tangent features of the corresponding neural network. We prove that, provided the underlying reward function is bounded, the proposed algorithm is guaranteed to achieve a cumulative regret of $\mathcal{O}(T^{1/2})$, which matches the regret of other contextual bandit algorithms in terms of total round number $T$. Experimental comparisons with other benchmark bandit algorithms on various data sets corroborate our theory.
Minimax Optimal Reinforcement Learning for Discounted MDPs
Oct 01, 2020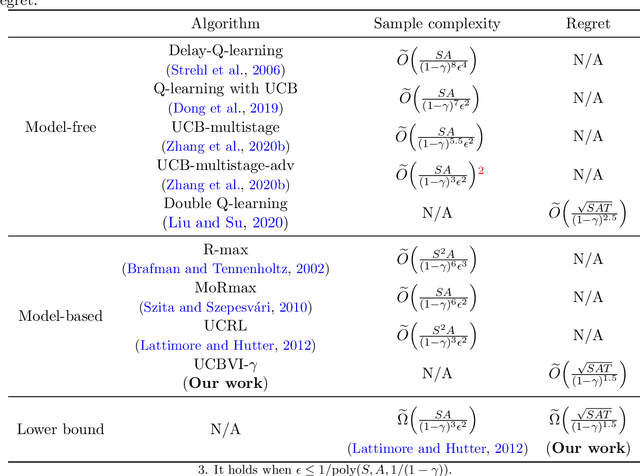
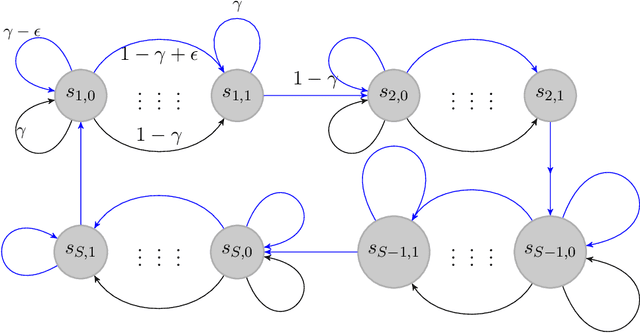
We study the reinforcement learning problem for discounted Markov Decision Processes (MDPs) in the tabular setting. We propose a model-based algorithm named UCBVI-$\gamma$, which is based on the optimism in the face of uncertainty principle and the Bernstein-type bonus. It achieves $\tilde{O}\big({\sqrt{SAT}}/{(1-\gamma)^{1.5}}\big)$ regret, where $S$ is the number of states, $A$ is the number of actions, $\gamma$ is the discount factor and $T$ is the number of steps. In addition, we construct a class of hard MDPs and show that for any algorithm, the expected regret is at least $\tilde{\Omega}\big({\sqrt{SAT}}/{(1-\gamma)^{1.5}}\big)$. Our upper bound matches the minimax lower bound up to logarithmic factors, which suggests that UCBVI-$\gamma$ is near optimal for discounted MDPs.
Provably Efficient Reinforcement Learning for Discounted MDPs with Feature Mapping
Jun 23, 2020
Modern tasks in reinforcement learning are always with large state and action spaces. To deal with them efficiently, one often uses predefined feature mapping to represents states and actions in a low dimensional space. In this paper, we study reinforcement learning with feature mapping for discounted Markov Decision Processes (MDPs). We propose a novel algorithm which makes use of the feature mapping and obtains a $\tilde O(d\sqrt{T}/(1-\gamma)^2)$ regret, where $d$ is the dimension of the feature space, $T$ is the time horizon and $\gamma$ is the discount factor of the MDP. To the best of our knowledge, this is the first polynomial regret bound without accessing to a generative model or making strong assumptions such as ergodicity of the MDP. By constructing a special class of MDPs, we also show that for any algorithms, the regret is lower bounded by $\Omega(d\sqrt{T}/(1-\gamma)^{1.5})$. Our upper and lower bound results together suggest that the proposed reinforcement learning algorithm is near-optimal up to a $(1-\gamma)^{-0.5}$ factor.