 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking a Bird AI Expert Work for You and Me
Dec 06, 2021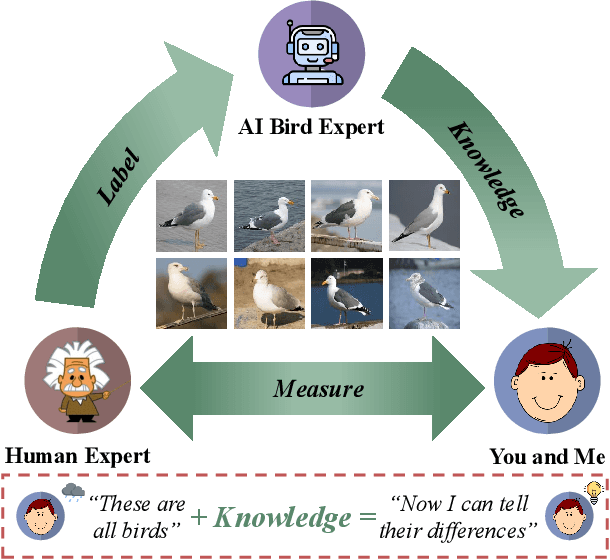



As powerful as fine-grained visual classification (FGVC) is, responding your query with a bird name of "Whip-poor-will" or "Mallard" probably does not make much sense. This however commonly accepted in the literature, underlines a fundamental question interfacing AI and human -- what constitutes transferable knowledge for human to learn from AI? This paper sets out to answer this very question using FGVC as a test bed. Specifically, we envisage a scenario where a trained FGVC model (the AI expert) functions as a knowledge provider in enabling average people (you and me) to become better domain experts ourselves, i.e. those capable in distinguishing between "Whip-poor-will" and "Mallard". Fig. 1 lays out our approach in answering this question. Assuming an AI expert trained using expert human labels, we ask (i) what is the best transferable knowledge we can extract from AI, and (ii) what is the most practical means to measure the gains in expertise given that knowledge? On the former, we propose to represent knowledge as highly discriminative visual regions that are expert-exclusive. For that, we devise a multi-stage learning framework, which starts with modelling visual attention of domain experts and novices before discriminatively distilling their differences to acquire the expert exclusive knowledge. For the latter, we simulate the evaluation process as book guide to best accommodate the learning practice of what is accustomed to humans. A comprehensive human study of 15,000 trials shows our method is able to consistently improve people of divergent bird expertise to recognise once unrecognisable birds. Interestingly, our approach also leads to improved conventional FGVC performance when the extracted knowledge defined is utilised as means to achieve discriminative localisation. Codes are available at: https://github.com/PRIS-CV/Making-a-Bird-AI-Expert-Work-for-You-and-Me
Fine-Grained Visual Classification via Simultaneously Learning of Multi-regional Multi-grained Features
Jan 31, 2021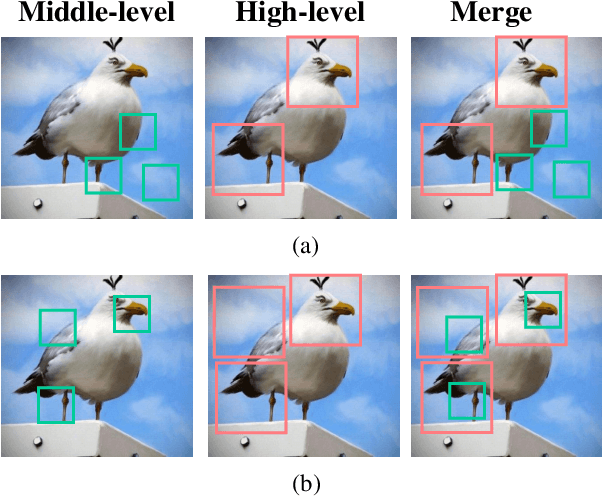
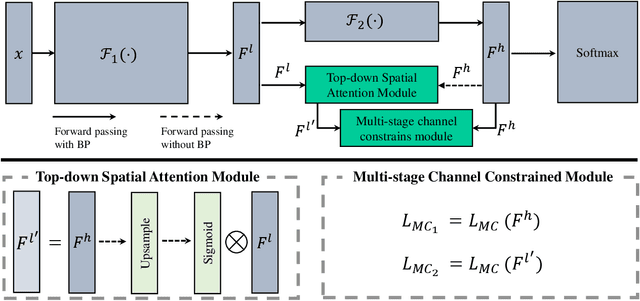
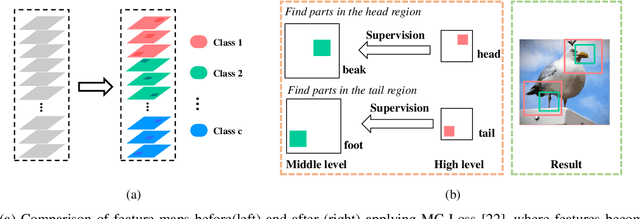

Fine-grained visual classification is a challenging task that recognizes the sub-classes belonging to the same meta-class. Large inter-class similarity and intra-class variance is the main challenge of this task. Most exiting methods try to solve this problem by designing complex model structures to explore more minute and discriminative regions. In this paper, we argue that mining multi-regional multi-grained features is precisely the key to this task. Specifically, we introduce a new loss function, termed top-down spatial attention loss (TDSA-Loss), which contains a multi-stage channel constrained module and a top-down spatial attention module. The multi-stage channel constrained module aims to make the feature channels in different stages category-aligned. Meanwhile, the top-down spatial attention module uses the attention map generated by high-level aligned feature channels to make middle-level aligned feature channels to focus on particular regions. Finally, we can obtain multiple discriminative regions on high-level feature channels and obtain multiple more minute regions within these discriminative regions on middle-level feature channels. In summary, we obtain multi-regional multi-grained features. Experimental results over four widely used fine-grained image classification datasets demonstrate the effectiveness of the proposed method. Ablative studies further show the superiority of two modules in the proposed method. Codes are available at: https://github.com/dongliangchang/Top-Down-Spatial-Attention-Loss.
Grad-CAM guided channel-spatial attention module for fine-grained visual classification
Jan 24, 2021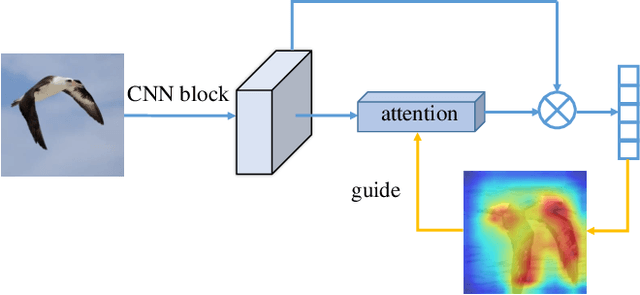
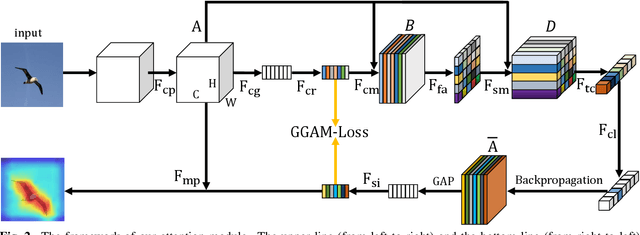
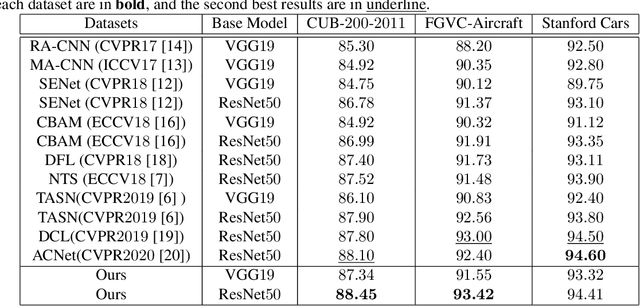
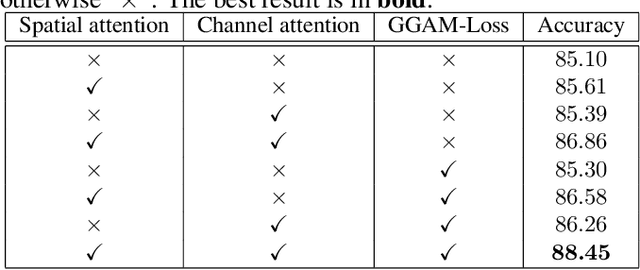
Fine-grained visual classification (FGVC) is becoming an important research field, due to its wide applications and the rapid development of computer vision technologies. The current state-of-the-art (SOTA) methods in the FGVC usually employ attention mechanisms to first capture the semantic parts and then discover their subtle differences between distinct classes. The channel-spatial attention mechanisms, which focus on the discriminative channels and regions simultaneously, have significantly improved the classification performance. However, the existing attention modules are poorly guided since part-based detectors in the FGVC depend on the network learning ability without the supervision of part annotations. As obtaining such part annotations is labor-intensive, some visual localization and explanation methods, such as gradient-weighted class activation mapping (Grad-CAM), can be utilized for supervising the attention mechanism. We propose a Grad-CAM guided channel-spatial attention module for the FGVC, which employs the Grad-CAM to supervise and constrain the attention weights by generating the coarse localization maps. To demonstrate the effectiveness of the proposed method, we conduct comprehensive experiments on three popular FGVC datasets, including CUB-$200$-$2011$, Stanford Cars, and FGVC-Aircraft datasets. The proposed method outperforms the SOTA attention modules in the FGVC task. In addition, visualizations of feature maps also demonstrate the superiority of the proposed method against the SOTA approaches.
Progressive Co-Attention Network for Fine-grained Visual Classification
Jan 21, 2021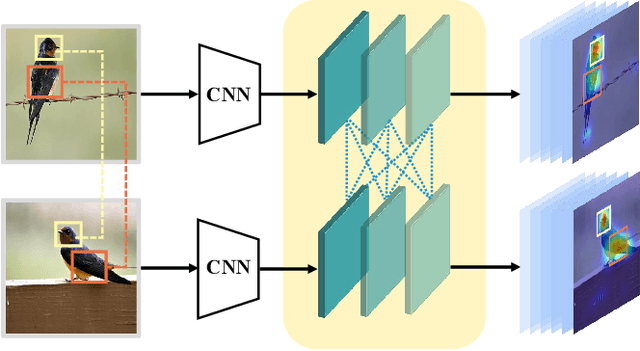

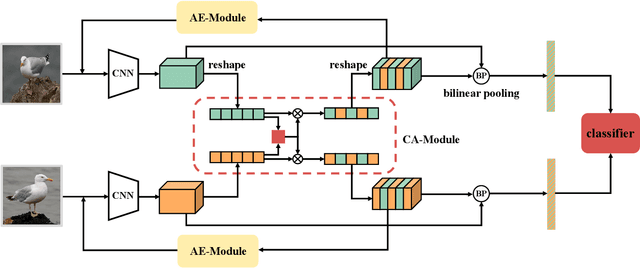

Fine-grained visual classification aims to recognize images belonging to multiple sub-categories within a same category. It is a challenging task due to the inherently subtle variations among highly-confused categories. Most existing methods only take individual image as input, which may limit the ability of models to recognize contrastive clues from different images. In this paper, we propose an effective method called progressive co-attention network (PCA-Net) to tackle this problem. Specifically, we calculate the channel-wise similarity by interacting the feature channels within same-category images to capture the common discriminative features. Considering that complementary imformation is also crucial for recognition, we erase the prominent areas enhanced by the channel interaction to force the network to focus on other discriminative regions. The proposed model can be trained in an end-to-end manner, and only requires image-level label supervision. It has achieved competitive results on three fine-grained visual classification benchmark datasets: CUB-200-2011, Stanford Cars, and FGVC Aircraft.
Knowledge Transfer Based Fine-grained Visual Classification
Dec 21, 2020
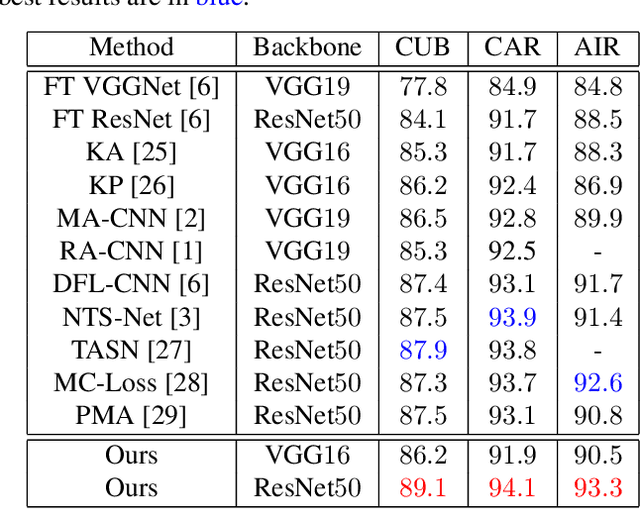
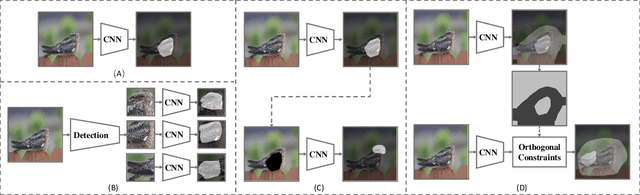

Fine-grained visual classification (FGVC) aims to distinguish the sub-classes of the same category and its essential solution is to mine the subtle and discriminative regions. Convolution neural networks (CNNs), which employ the cross entropy loss (CE-loss) as the loss function, show poor performance since the model can only learn the most discriminative part and ignore other meaningful regions. Some existing works try to solve this problem by mining more discriminative regions by some detection techniques or attention mechanisms. However, most of them will meet the background noise problem when trying to find more discriminative regions. In this paper, we address it in a knowledge transfer learning manner. Multiple models are trained one by one, and all previously trained models are regarded as teacher models to supervise the training of the current one. Specifically, a orthogonal loss (OR-loss) is proposed to encourage the network to find diverse and meaningful regions. In addition, the first model is trained with only CE-Loss. Finally, all models' outputs with complementary knowledge are combined together for the final prediction result. We demonstrate the superiority of the proposed method and obtain state-of-the-art (SOTA) performances on three popular FGVC datasets.
Your "Labrador" is My "Dog": Fine-Grained, or Not
Nov 18, 2020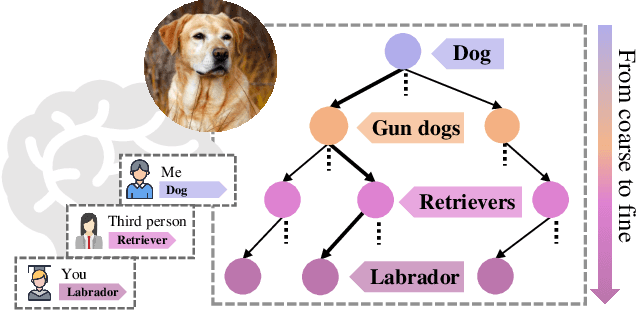

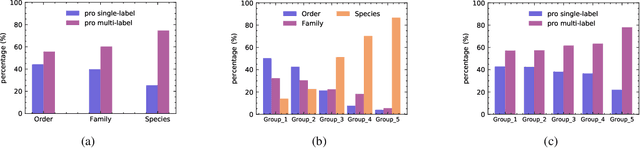
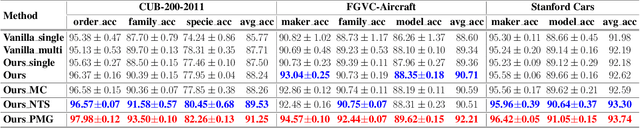
Whether what you see in Figure 1 is a "labrador" or a "dog", is the question we ask in this paper. While fine-grained visual classification (FGVC) strives to arrive at the former, for the majority of us non-experts just "dog" would probably suffice. The real question is therefore -- how can we tailor for different fine-grained definitions under divergent levels of expertise. For that, we re-envisage the traditional setting of FGVC, from single-label classification, to that of top-down traversal of a pre-defined coarse-to-fine label hierarchy -- so that our answer becomes "dog"-->"gun dog"-->"retriever"-->"labrador". To approach this new problem, we first conduct a comprehensive human study where we confirm that most participants prefer multi-granularity labels, regardless whether they consider themselves experts. We then discover the key intuition that: coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier. This discovery enables us to design a very simple albeit surprisingly effective solution to our new problem, where we (i) leverage level-specific classification heads to disentangle coarse-level features with fine-grained ones, and (ii) allow finer-grained features to participate in coarser-grained label predictions, which in turn helps with better disentanglement. Experiments show that our method achieves superior performance in the new FGVC setting, and performs better than state-of-the-art on traditional single-label FGVC problem as well. Thanks to its simplicity, our method can be easily implemented on top of any existing FGVC frameworks and is parameter-free.
CC-Loss: Channel Correlation Loss For Image Classification
Oct 12, 2020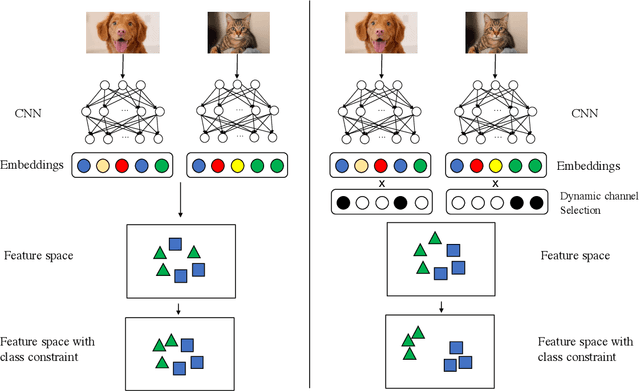

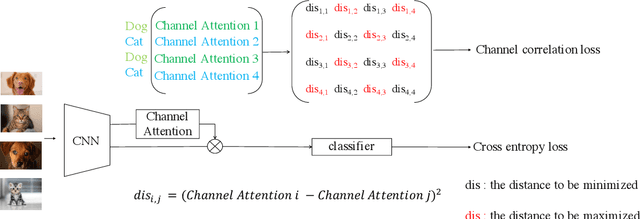
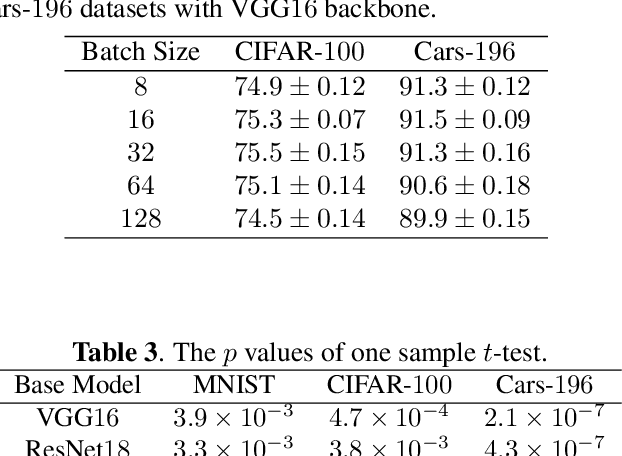
The loss function is a key component in deep learning models. A commonly used loss function for classification is the cross entropy loss, which is a simple yet effective application of information theory for classification problems. Based on this loss, many other loss functions have been proposed,~\emph{e.g.}, by adding intra-class and inter-class constraints to enhance the discriminative ability of the learned features. However, these loss functions fail to consider the connections between the feature distribution and the model structure. Aiming at addressing this problem, we propose a channel correlation loss (CC-Loss) that is able to constrain the specific relations between classes and channels as well as maintain the intra-class and the inter-class separability. CC-Loss uses a channel attention module to generate channel attention of features for each sample in the training stage. Next, an Euclidean distance matrix is calculated to make the channel attention vectors associated with the same class become identical and to increase the difference between different classes. Finally, we obtain a feature embedding with good intra-class compactness and inter-class separability.Experimental results show that two different backbone models trained with the proposed CC-Loss outperform the state-of-the-art loss functions on three image classification datasets.
OSLNet: Deep Small-Sample Classification with an Orthogonal Softmax Layer
Apr 20, 2020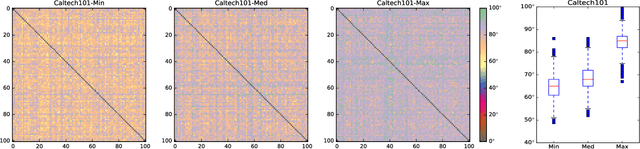
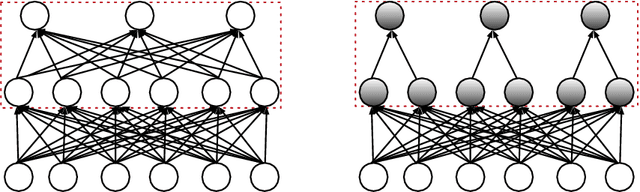
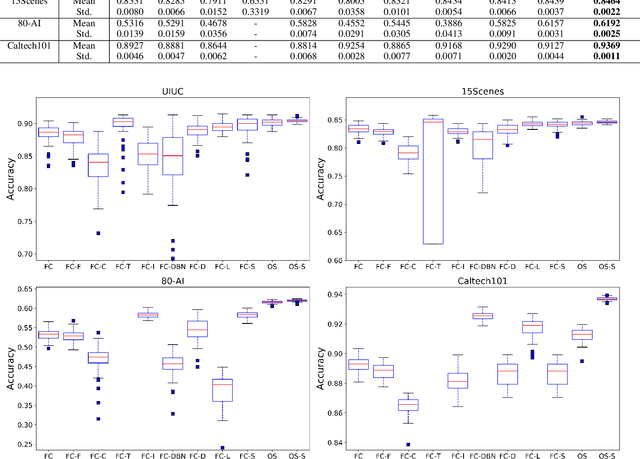
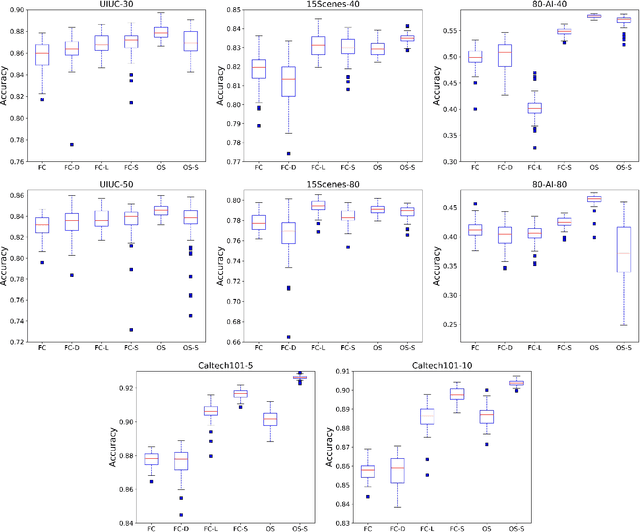
A deep neural network of multiple nonlinear layers forms a large function space, which can easily lead to overfitting when it encounters small-sample data. To mitigate overfitting in small-sample classification, learning more discriminative features from small-sample data is becoming a new trend. To this end, this paper aims to find a subspace of neural networks that can facilitate a large decision margin. Specifically, we propose the Orthogonal Softmax Layer (OSL), which makes the weight vectors in the classification layer remain orthogonal during both the training and test processes. The Rademacher complexity of a network using the OSL is only $\frac{1}{K}$, where $K$ is the number of classes, of that of a network using the fully connected classification layer, leading to a tighter generalization error bound. Experimental results demonstrate that the proposed OSL has better performance than the methods used for comparison on four small-sample benchmark datasets, as well as its applicability to large-sample datasets. Codes are available at: https://github.com/dongliangchang/OSLNet.
Dual-attention Guided Dropblock Module for Weakly Supervised Object Localization
Mar 19, 2020
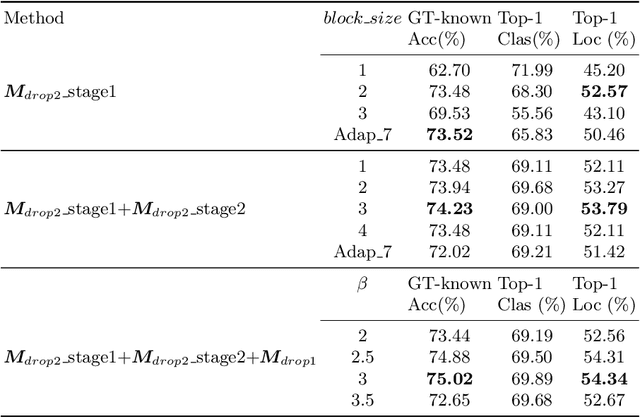
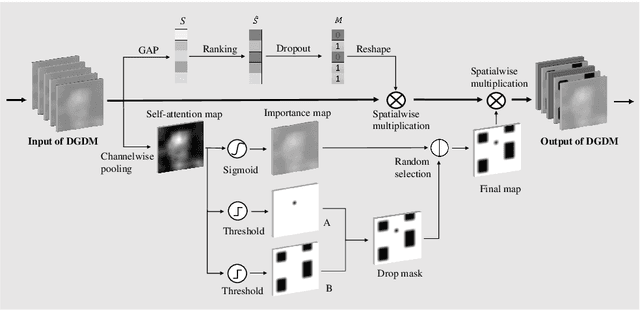
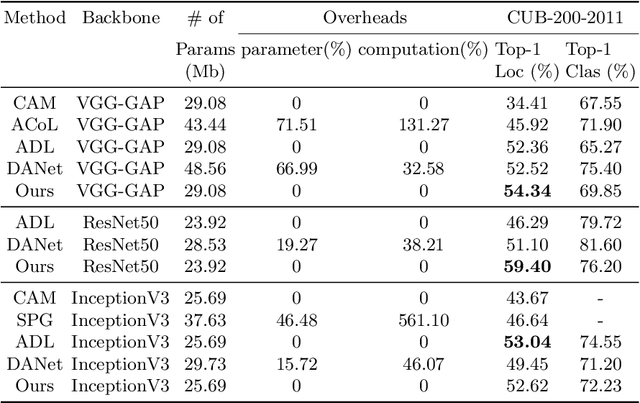
In this paper, we present a dual-attention guided dropblock module, and aim at learning the informative and complementary visual features for weakly supervised object localization (WSOL). The attention mechanism is extended to the task of WSOL, and design two types of attention modules to learn the discriminative features for better feature representations. Based on two types of attention mechanism, we propose a channel attention guided dropout (CAGD) and a spatial attention guided dropblock (SAGD). The CAGD ranks channel attention by a measure of importance and consider the top-k largest magnitude attentions as important ones. The SAGD can not only completely remove the information by erasing the contiguous regions of feature maps rather than individual pixels, but also simply distinguish the foreground objects and background regions to alleviate the attention misdirection. Extensive experiments demonstrate that the proposed method achieves new state-of-the-art localization accuracy on a challenging dataset.
Fine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches
Mar 10, 2020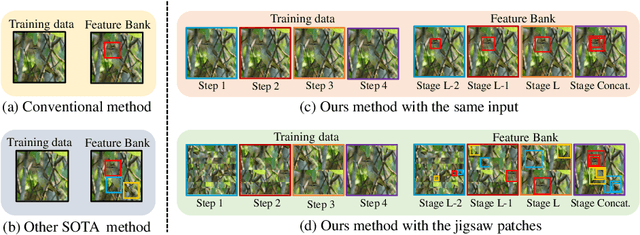
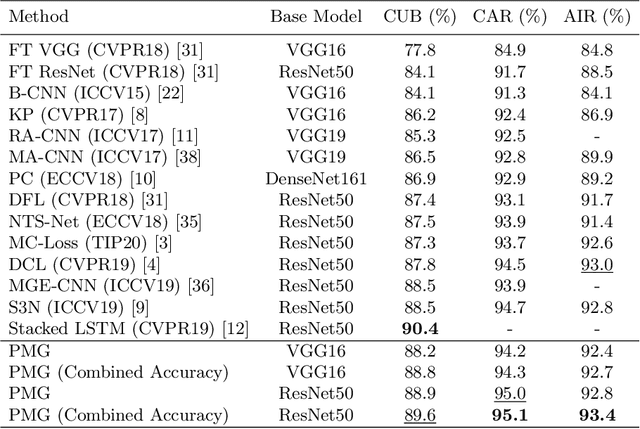
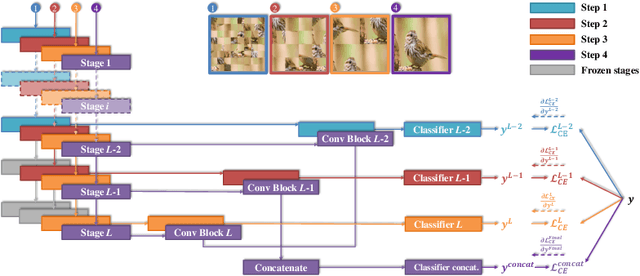
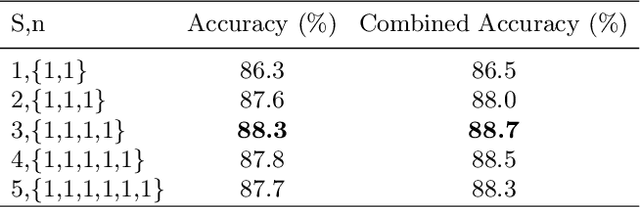
Fine-grained visual classification (FGVC) is much more challenging than traditional classification tasks due to the inherently subtle intra-class object variations. Recent works mainly tackle this problem by focusing on how to locate the most discriminative parts, more complementary parts, and parts of various granularities. However, less effort has been placed to which granularities are the most discriminative and how to fuse information cross multi-granularity. In this work, we propose a novel framework for fine-grained visual classification to tackle these problems. In particular, we propose: (i) a novel progressive training strategy that adds new layers in each training step to exploit information based on the smaller granularity information found at the last step and the previous stage. (ii) a simple jigsaw puzzle generator to form images contain information of different granularity levels. We obtain state-of-the-art performances on several standard FGVC benchmark datasets, where the proposed method consistently outperforms existing methods or delivers competitive results. The code will be available at https://github.com/RuoyiDu/PMG-Progressive-Multi-Granularity-Training.