 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
May 13, 2024



Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5\% and 89.6\%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.
Gradient Alignment with Prototype Feature for Fully Test-time Adaptation
Feb 14, 2024



In context of Test-time Adaptation(TTA), we propose a regularizer, dubbed Gradient Alignment with Prototype feature (GAP), which alleviates the inappropriate guidance from entropy minimization loss from misclassified pseudo label. We developed a gradient alignment loss to precisely manage the adaptation process, ensuring that changes made for some data don't negatively impact the model's performance on other data. We introduce a prototype feature of a class as a proxy measure of the negative impact. To make GAP regularizer feasible under the TTA constraints, where model can only access test data without labels, we tailored its formula in two ways: approximating prototype features with weight vectors of the classifier, calculating gradient without back-propagation. We demonstrate GAP significantly improves TTA methods across various datasets, which proves its versatility and effectiveness.
Read-only Prompt Optimization for Vision-Language Few-shot Learning
Aug 29, 2023



In recent years, prompt tuning has proven effective in adapting pre-trained vision-language models to downstream tasks. These methods aim to adapt the pre-trained models by introducing learnable prompts while keeping pre-trained weights frozen. However, learnable prompts can affect the internal representation within the self-attention module, which may negatively impact performance variance and generalization, especially in data-deficient settings. To address these issues, we propose a novel approach, Read-only Prompt Optimization (RPO). RPO leverages masked attention to prevent the internal representation shift in the pre-trained model. Further, to facilitate the optimization of RPO, the read-only prompts are initialized based on special tokens of the pre-trained model. Our extensive experiments demonstrate that RPO outperforms CLIP and CoCoOp in base-to-new generalization and domain generalization while displaying better robustness. Also, the proposed method achieves better generalization on extremely data-deficient settings, while improving parameter efficiency and computational overhead. Code is available at https://github.com/mlvlab/RPO.
Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation
Aug 07, 2023



Sequential recommendation addresses the issue of preference drift by predicting the next item based on the user's previous behaviors. Recently, a promising approach using contrastive learning has emerged, demonstrating its effectiveness in recommending items under sparse user-item interactions. Significantly, the effectiveness of combinations of various augmentation methods has been demonstrated in different domains, particularly in computer vision. However, when it comes to augmentation within a contrastive learning framework in sequential recommendation, previous research has only focused on limited conditions and simple structures. Thus, it is still possible to extend existing approaches to boost the effects of augmentation methods by using progressed structures with the combinations of multiple augmentation methods. In this work, we propose a novel framework called Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation(HCLRec) to overcome the aforementioned limitation. Our framework leverages existing augmentation methods hierarchically to improve performance. By combining augmentation methods continuously, we generate low-level and high-level view pairs. We employ a Transformers-based model to encode the input sequence effectively. Furthermore, we introduce additional blocks consisting of Transformers and position-wise feed-forward network(PFFN) layers to learn the invariance of the original sequences from hierarchically augmented views. We pass the input sequence to subsequent layers based on the number of increment levels applied to the views to handle various augmentation levels. Within each layer, we compute contrastive loss between pairs of views at the same level. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art approaches and that HCLRec is robust even when faced with the problem of sparse interaction.
Uncertain Pose Estimation during Contact Tasks using Differentiable Contact Features
May 26, 2023



For many robotic manipulation and contact tasks, it is crucial to accurately estimate uncertain object poses, for which certain geometry and sensor information are fused in some optimal fashion. Previous results for this problem primarily adopt sampling-based or end-to-end learning methods, which yet often suffer from the issues of efficiency and generalizability. In this paper, we propose a novel differentiable framework for this uncertain pose estimation during contact, so that it can be solved in an efficient and accurate manner with gradient-based solver. To achieve this, we introduce a new geometric definition that is highly adaptable and capable of providing differentiable contact features. Then we approach the problem from a bi-level perspective and utilize the gradient of these contact features along with differentiable optimization to efficiently solve for the uncertain pose. Several scenarios are implemented to demonstrate how the proposed framework can improve existing methods.
Modular and Parallelizable Multibody Physics Simulation via Subsystem-Based ADMM
Feb 28, 2023


In this paper, we present a new multibody physics simulation framework that utilizes the subsystem-based structure and the Alternating Direction Method of Multiplier (ADMM). The major challenge in simulating complex high degree of freedom systems is a large number of coupled constraints and large-sized matrices. To address this challenge, we first split the multibody into several subsystems and reformulate the dynamics equation into a subsystem perspective based on the structure of their interconnection. Then we utilize ADMM with our novel subsystem-based variable splitting scheme to solve the equation, which allows parallelizable and modular architecture. The resulting algorithm is fast, scalable, versatile, and converges well while maintaining solution consistency. Several illustrative examples are implemented with performance evaluation results showing advantages over other state-of-the-art algorithms.
A Learning-Based Estimation and Control Framework for Contact-Intensive Tight-Tolerance Tasks
Oct 11, 2022

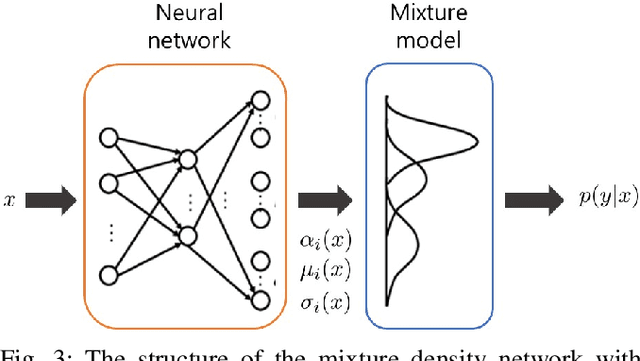
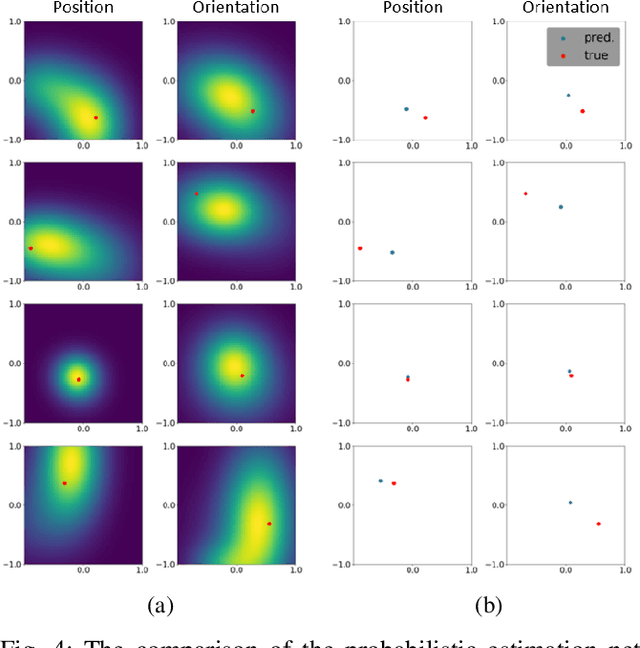
We propose a novel data-driven estimation and control framework for contact-rich tight tolerance tasks, which estimates the pose of the object precisely using data-driven methods and compensates for the remaining error via reinforcement learning (RL). First, the sequential particle filter estimator updates with the mixture density network (MDN), which is to represent the general non-injective conditional probability and thus is suitable for finding out the pose from the measurements including relatively low-dimensional contact wrench sensing. We further develop the RL-based fastening controller that adapts to the remaining error by optimizing the admittance gain to complete the task. The proposed framework is evaluated using an accurate real-time simulator on the bolting task and successfully transferred to an experimental environment.
A Custom IC Layout Generation Engine Based on Dynamic Templates and Grids
Jul 24, 2022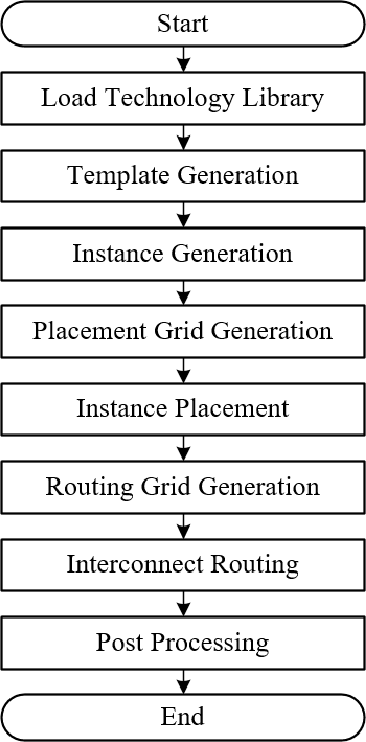
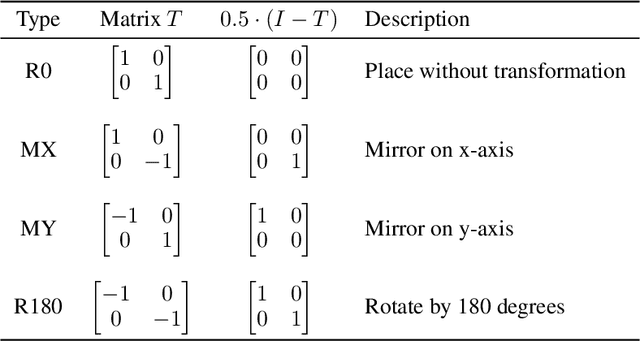
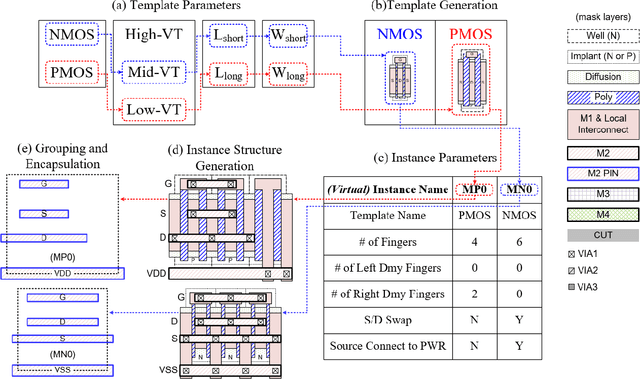

This paper presents an automatic layout generation framework in advanced CMOS technologies. The framework extends the template-and-grid-based layout generation methodology with the following additional techniques applied to produce optimal layouts more effectively. First, layout templates and grids are dynamically created and adjusted during runtime to serve various structural, functional, and design requirements. Virtual instances support the dynamic template-and-grid-based layout generation process. The framework also implements various post-processing functions to handle process-specific requirements efficiently. The post-processing functions include cut/dummy pattern generation and multiple-patterning adjustment. The generator description capability is enhanced with circular grid indexing/slicing and conditional conversion operators. The layout generation framework is applied to various design examples and generates DRC/LVS clean layouts automatically in multiple CMOS technologies.
A Multi-Task Benchmark for Korean Legal Language Understanding and Judgement Prediction
Jun 10, 2022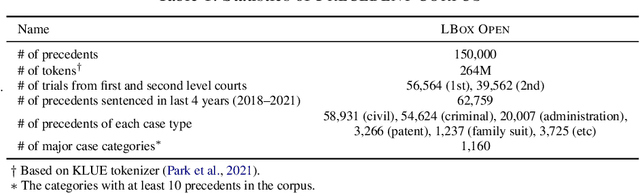
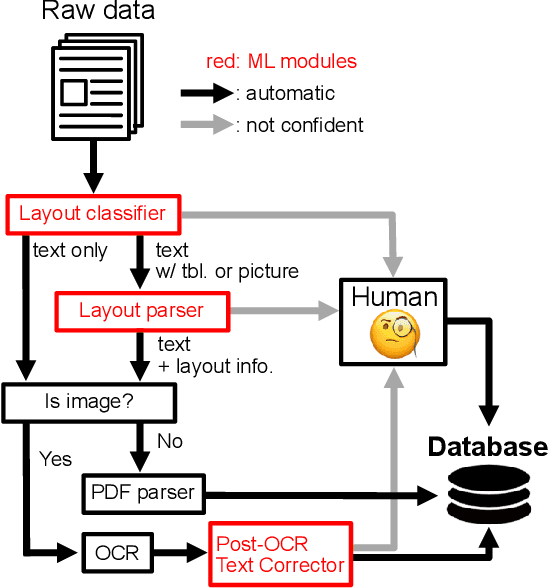
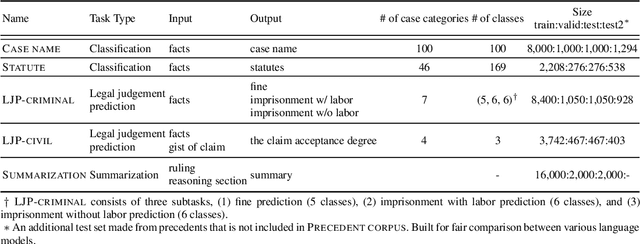
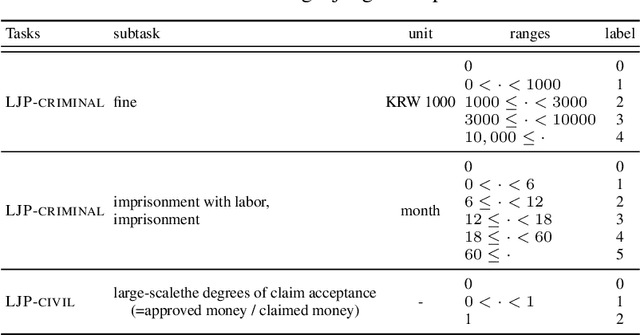
The recent advances of deep learning have dramatically changed how machine learning, especially in the domain of natural language processing, can be applied to legal domain. However, this shift to the data-driven approaches calls for larger and more diverse datasets, which are nevertheless still small in number, especially in non-English languages. Here we present the first large-scale benchmark of Korean legal AI datasets, LBox Open, that consists of one legal corpus, two classification tasks, two legal judgement prediction (LJP) tasks, and one summarization task. The legal corpus consists of 150k Korean precedents (264M tokens), of which 63k are sentenced in last 4 years and 96k are from the first and the second level courts in which factual issues are reviewed. The two classification tasks are case names (10k) and statutes (3k) prediction from the factual description of individual cases. The LJP tasks consist of (1) 11k criminal examples where the model is asked to predict fine amount, imprisonment with labor, and imprisonment without labor ranges for the given facts, and (2) 5k civil examples where the inputs are facts and claim for relief and outputs are the degrees of claim acceptance. The summarization task consists of the Supreme Court precedents and the corresponding summaries. We also release LCube, the first Korean legal language model trained on the legal corpus from this study. Given the uniqueness of the Law of South Korea and the diversity of the legal tasks covered in this work, we believe that LBox Open contributes to the multilinguality of global legal research. LBox Open and LCube will be publicly available.
Fast and Accurate Data-Driven Simulation Framework for Contact-Intensive Tight-Tolerance Robotic Assembly Tasks
Feb 26, 2022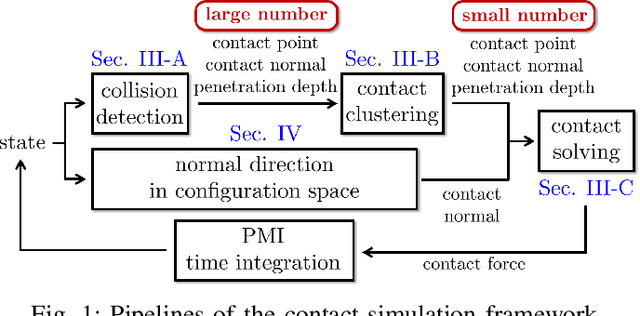
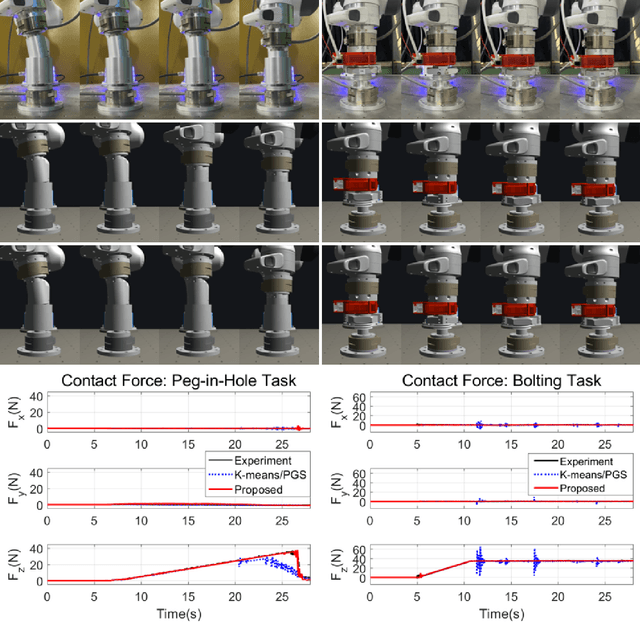
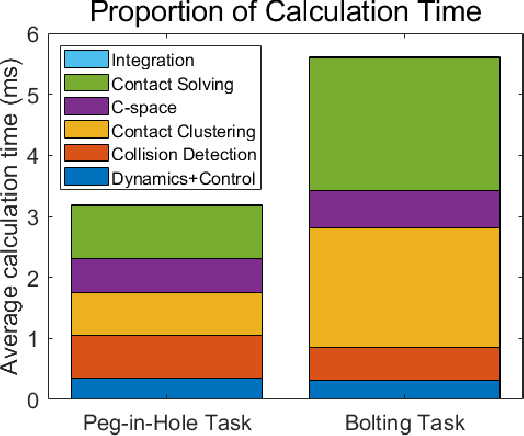
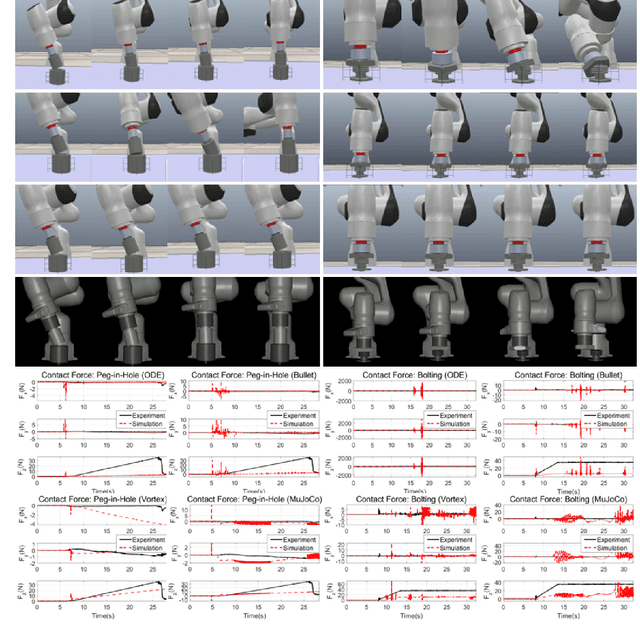
We propose a novel fast and accurate simulation framework for contact-intensive tight-tolerance robotic assembly tasks. The key components of our framework are as follows: 1) data-driven contact point clustering with a certain variable-input network, which is explicitly trained for simulation accuracy (with real experimental data) and able to accommodate complex/non-convex object shapes; 2) contact force solving, which precisely/robustly enforces physics of contact (i.e., no penetration, Coulomb friction, maximum energy dissipation) with contact mechanics of contact nodes augmented with that of their object; 3) contact detection with a neural network, which is parallelized for each contact point, thus, can be computed very quickly even for complex shape objects with no exhaust pair-wise test; and 4) time integration with PMI (passive mid-point integration), whose discrete-time passivity improves overall simulation accuracy, stability, and speed. We then implement our proposed framework for two widely-encountered/benchmarked contact-intensive tight-tolerance tasks, namely, peg-in-hole assembly and bolt-nut assembly, and validate its speed and accuracy against real experimental data. It is worthwhile to mention that our proposed simulation framework is applicable to other general contact-intensive tight-tolerance robotic assembly tasks as well. We also compare its performance with other physics engines and manifest its robustness via haptic rendering of virtual bolting task.