 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPS++: Reviving the Art of Message Passing for Molecular Property Prediction
Feb 06, 2023



We present GPS++, a hybrid Message Passing Neural Network / Graph Transformer model for molecular property prediction. Our model integrates a well-tuned local message passing component and biased global attention with other key ideas from prior literature to achieve state-of-the-art results on large-scale molecular dataset PCQM4Mv2. Through a thorough ablation study we highlight the impact of individual components and, contrary to expectations set by recent trends, find that nearly all of the model's performance can be maintained without any use of global self-attention. We also show that our approach is significantly more accurate than prior art when 3D positional information is not available.
Task-Agnostic Graph Neural Network Evaluation via Adversarial Collaboration
Jan 27, 2023It has been increasingly demanding to develop reliable Graph Neural Network (GNN) evaluation methods to quantify the progress of the rapidly expanding GNN research. Existing GNN benchmarking methods focus on comparing the GNNs with respect to their performances on some node/graph classification/regression tasks in certain datasets. There lacks a principled, task-agnostic method to directly compare two GNNs. Moreover, most of the existing graph self-supervised learning (SSL) works incorporate handcrafted augmentations to the graph, which has several severe difficulties due to the unique characteristics of graph-structured data. To address the aforementioned issues, we propose GraphAC (Graph Adversarial Collaboration) -- a conceptually novel, principled, task-agnostic, and stable framework for evaluating GNNs through contrastive self-supervision. GraphAC succeeds in distinguishing GNNs of different expressiveness across various aspects, and has been proven to be a principled and reliable GNN evaluation method, eliminating the need for handcrafted augmentations for stable SSL.
GPS++: An Optimised Hybrid MPNN/Transformer for Molecular Property Prediction
Dec 06, 2022



This technical report presents GPS++, the first-place solution to the Open Graph Benchmark Large-Scale Challenge (OGB-LSC 2022) for the PCQM4Mv2 molecular property prediction task. Our approach implements several key principles from the prior literature. At its core our GPS++ method is a hybrid MPNN/Transformer model that incorporates 3D atom positions and an auxiliary denoising task. The effectiveness of GPS++ is demonstrated by achieving 0.0719 mean absolute error on the independent test-challenge PCQM4Mv2 split. Thanks to Graphcore IPU acceleration, GPS++ scales to deep architectures (16 layers), training at 3 minutes per epoch, and large ensemble (112 models), completing the final predictions in 1 hour 32 minutes, well under the 4 hour inference budget allocated. Our implementation is publicly available at: https://github.com/graphcore/ogb-lsc-pcqm4mv2.
Long Range Graph Benchmark
Jun 16, 2022
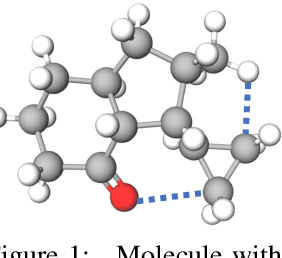
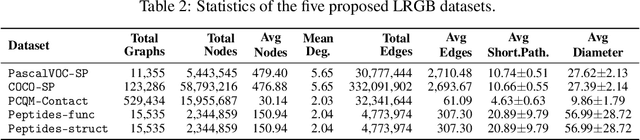

Graph Neural Networks (GNNs) that are based on the message passing (MP) paradigm exchange information between 1-hop neighbors to build node representations at each layer. In principle, such networks are not able to capture long-range interactions (LRI) that may be desired or necessary for learning a given task on graphs. Recently, there has been an increasing interest in development of Transformer-based methods for graphs that can consider full node connectivity beyond the original sparse structure, thus enabling the modeling of LRI. However, MP-GNNs that simply rely on 1-hop message passing often fare better in several existing graph benchmarks when combined with positional feature representations, among other innovations, hence limiting the perceived utility and ranking of Transformer-like architectures. Here, we present the Long Range Graph Benchmark (LRGB) with 5 graph learning datasets: PascalVOC-SP, COCO-SP, PCQM-Contact, Peptides-func and Peptides-struct that arguably require LRI reasoning to achieve strong performance in a given task. We benchmark both baseline GNNs and Graph Transformer networks to verify that the models which capture long-range dependencies perform significantly better on these tasks. Therefore, these datasets are suitable for benchmarking and exploration of MP-GNNs and Graph Transformer architectures that are intended to capture LRI.
Recipe for a General, Powerful, Scalable Graph Transformer
May 25, 2022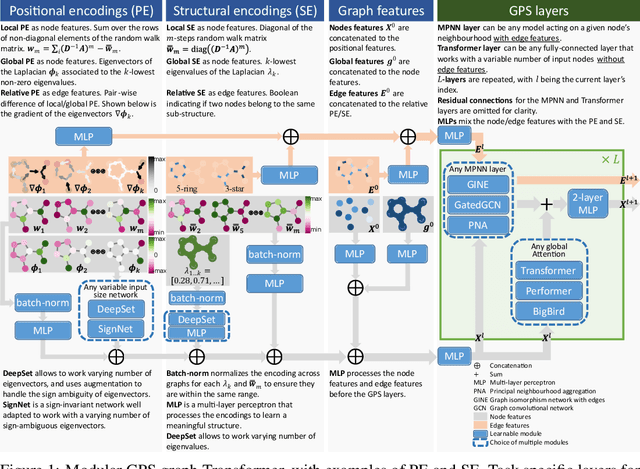
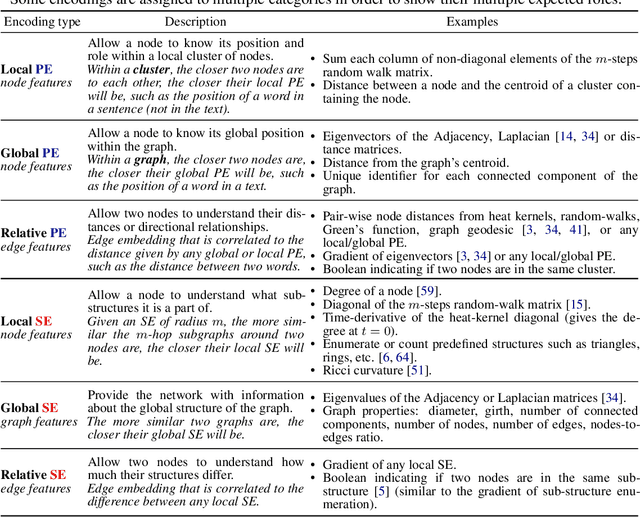
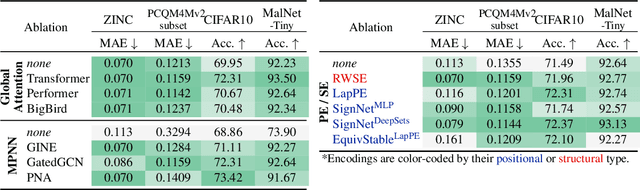
We propose a recipe on how to build a general, powerful, scalable (GPS) graph Transformer with linear complexity and state-of-the-art results on a diverse set of benchmarks. Graph Transformers (GTs) have gained popularity in the field of graph representation learning with a variety of recent publications but they lack a common foundation about what constitutes a good positional or structural encoding, and what differentiates them. In this paper, we summarize the different types of encodings with a clearer definition and categorize them as being $\textit{local}$, $\textit{global}$ or $\textit{relative}$. Further, GTs remain constrained to small graphs with few hundred nodes, and we propose the first architecture with a complexity linear to the number of nodes and edges $O(N+E)$ by decoupling the local real-edge aggregation from the fully-connected Transformer. We argue that this decoupling does not negatively affect the expressivity, with our architecture being a universal function approximator for graphs. Our GPS recipe consists of choosing 3 main ingredients: (i) positional/structural encoding, (ii) local message-passing mechanism, and (iii) global attention mechanism. We build and open-source a modular framework $\textit{GraphGPS}$ that supports multiple types of encodings and that provides efficiency and scalability both in small and large graphs. We test our architecture on 11 benchmarks and show very competitive results on all of them, show-casing the empirical benefits gained by the modularity and the combination of different strategies.
3D Infomax improves GNNs for Molecular Property Prediction
Oct 08, 2021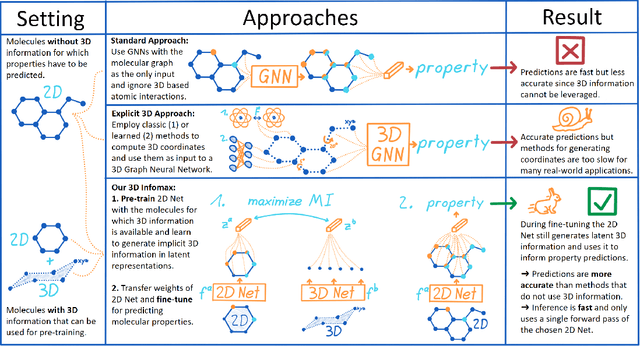
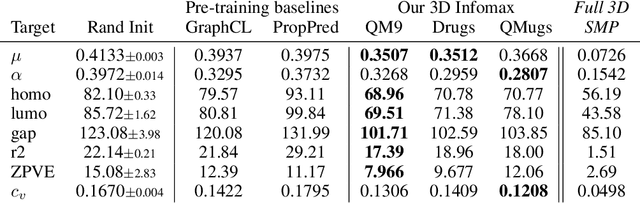
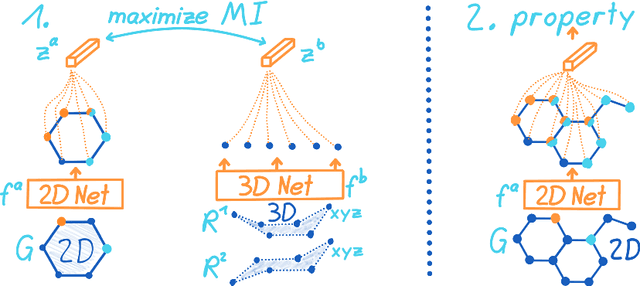

Molecular property prediction is one of the fastest-growing applications of deep learning with critical real-world impacts. Including 3D molecular structure as input to learned models their performance for many molecular tasks. However, this information is infeasible to compute at the scale required by several real-world applications. We propose pre-training a model to reason about the geometry of molecules given only their 2D molecular graphs. Using methods from self-supervised learning, we maximize the mutual information between 3D summary vectors and the representations of a Graph Neural Network (GNN) such that they contain latent 3D information. During fine-tuning on molecules with unknown geometry, the GNN still generates implicit 3D information and can use it to improve downstream tasks. We show that 3D pre-training provides significant improvements for a wide range of properties, such as a 22% average MAE reduction on eight quantum mechanical properties. Moreover, the learned representations can be effectively transferred between datasets in different molecular spaces.
Rethinking Graph Transformers with Spectral Attention
Jun 09, 2021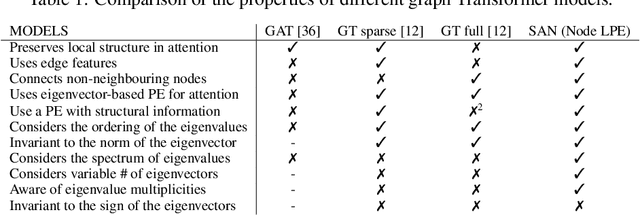
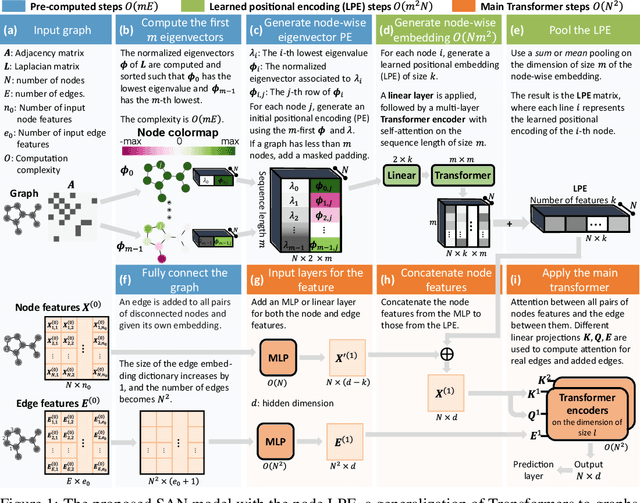

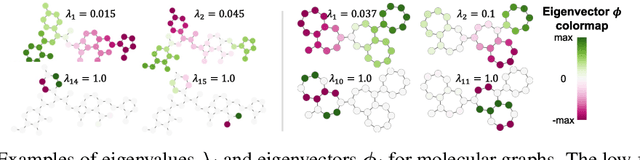
In recent years, the Transformer architecture has proven to be very successful in sequence processing, but its application to other data structures, such as graphs, has remained limited due to the difficulty of properly defining positions. Here, we present the $\textit{Spectral Attention Network}$ (SAN), which uses a learned positional encoding (LPE) that can take advantage of the full Laplacian spectrum to learn the position of each node in a given graph. This LPE is then added to the node features of the graph and passed to a fully-connected Transformer. By leveraging the full spectrum of the Laplacian, our model is theoretically powerful in distinguishing graphs, and can better detect similar sub-structures from their resonance. Further, by fully connecting the graph, the Transformer does not suffer from over-squashing, an information bottleneck of most GNNs, and enables better modeling of physical phenomenons such as heat transfer and electric interaction. When tested empirically on a set of 4 standard datasets, our model performs on par or better than state-of-the-art GNNs, and outperforms any attention-based model by a wide margin, becoming the first fully-connected architecture to perform well on graph benchmarks.
Directional Graph Networks
Oct 06, 2020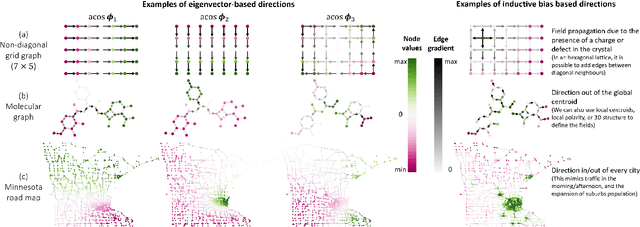

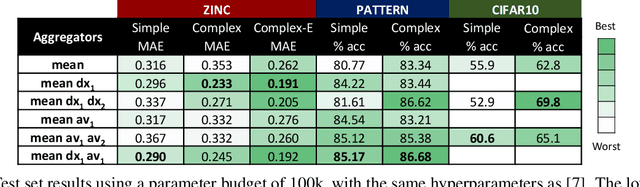
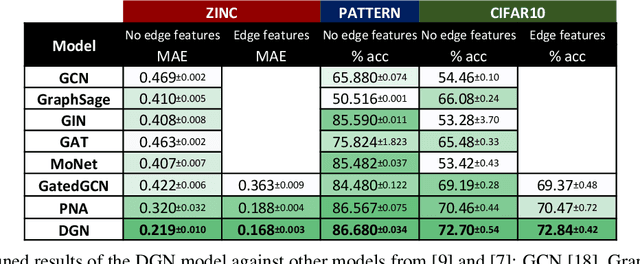
In order to overcome the expressive limitations of graph neural networks (GNNs), we propose the first method that exploits vector flows over graphs to develop globally consistent directional and asymmetric aggregation functions. We show that our directional graph networks (DGNs) generalize convolutional neural networks (CNNs) when applied on a grid. Whereas recent theoretical works focus on understanding local neighbourhoods, local structures and local isomorphism with no global information flow, our novel theoretical framework allows directional convolutional kernels in any graph. First, by defining a vector field in the graph, we develop a method of applying directional derivatives and smoothing by projecting node-specific messages into the field. Then we propose the use of the Laplacian eigenvectors as such vector field, and we show that the method generalizes CNNs on an n-dimensional grid. Finally, we bring the power of CNN data augmentation to graphs by providing a means of doing reflection, rotation and distortion on the underlying directional field. We evaluate our method on different standard benchmarks and see a relative error reduction of 8% on the CIFAR10 graph dataset and 11% to 32% on the molecular ZINC dataset. An important outcome of this work is that it enables to translate any physical or biological problems with intrinsic directional axes into a graph network formalism with an embedded directional field.
Principal Neighbourhood Aggregation for Graph Nets
Apr 12, 2020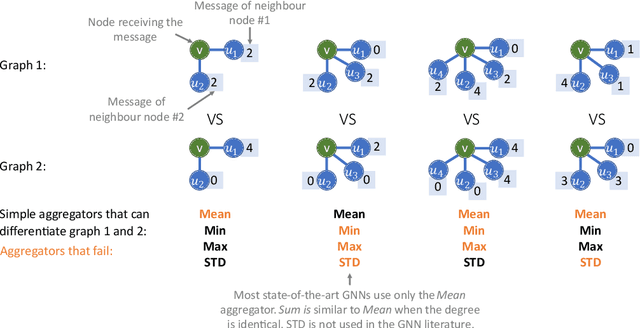
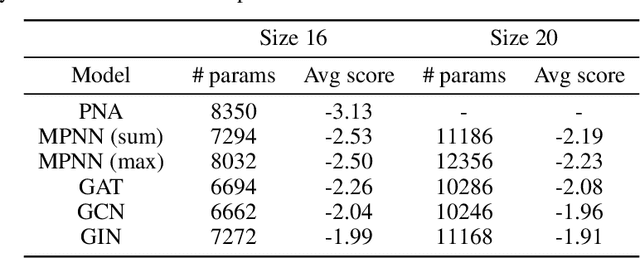


Graph Neural Networks (GNNs) have been shown to be effective models for different predictive tasks on graph-structured data. Recent work on their expressive power has focused on isomorphism tasks and countable feature spaces. We extend this theoretical framework to include continuous features - which occur regularly in real-world input domains and within the hidden layers of GNNs - and we demonstrate the requirement for multiple aggregation functions in this setting. Accordingly, we propose Principal Neighbourhood Aggregation (PNA), a novel architecture combining multiple aggregators with degree-scalers (which generalize the sum aggregator). Finally, we compare the capacity of different models to capture and exploit the graph structure via a benchmark containing multiple tasks taken from classical graph theory, which demonstrates the capacity of our model.
Improving Convolutional Neural Networks Via Conservative Field Regularisation and Integration
Mar 11, 2020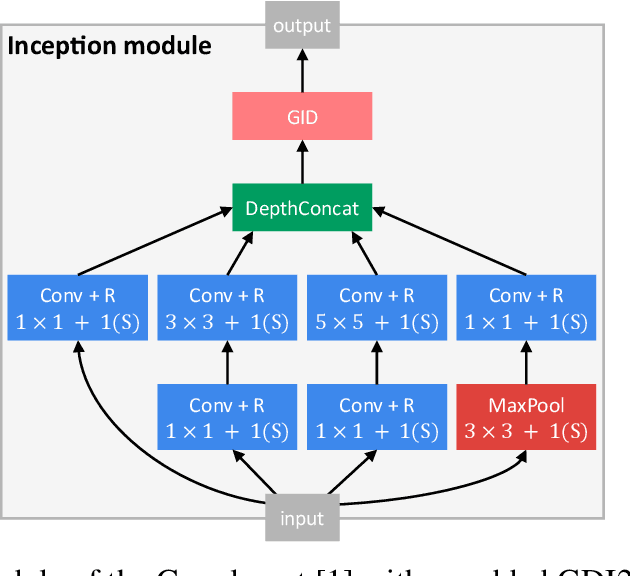
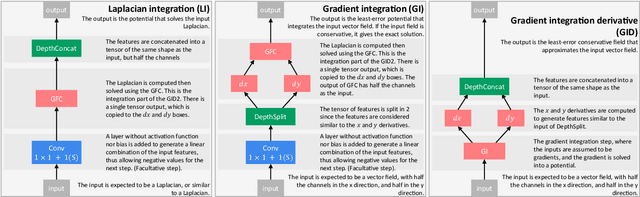
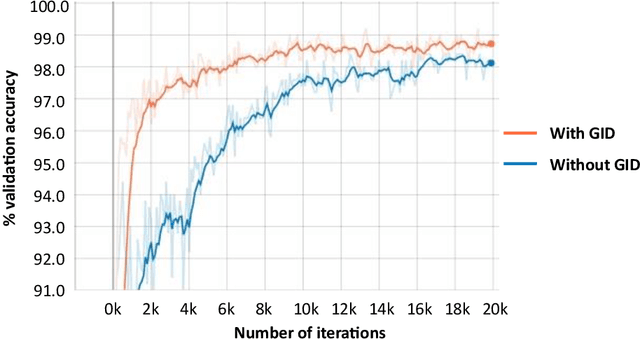
Current research in convolutional neural networks (CNN) focuses mainly on changing the architecture of the networks, optimizing the hyper-parameters and improving the gradient descent. However, most work use only 3 standard families of operations inside the CNN, the convolution, the activation function, and the pooling. In this work, we propose a new family of operations based on the Green's function of the Laplacian, which allows the network to solve the Laplacian, to integrate any vector field and to regularize the field by forcing it to be conservative. Hence, the Green's function (GF) is the first operation that regularizes the 2D or 3D feature space by forcing it to be conservative and physically interpretable, instead of regularizing the norm of the weights. Our results show that such regularization allows the network to learn faster, to have smoother training curves and to better generalize, without any additional parameter. The current manuscript presents early results, more work is required to benchmark the proposed method.