 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Option-Critic
Jan 07, 2022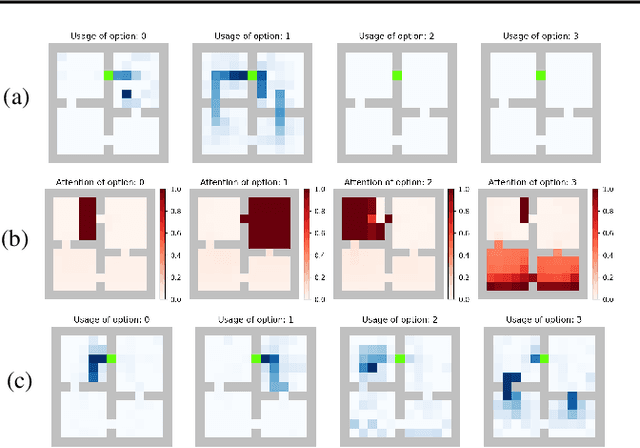
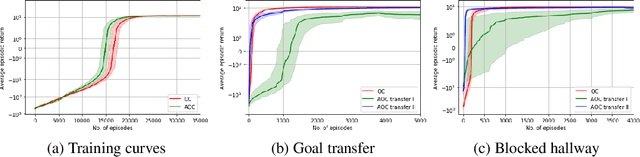
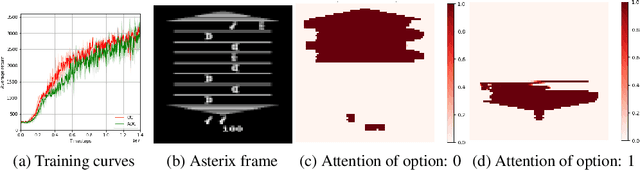
Temporal abstraction in reinforcement learning is the ability of an agent to learn and use high-level behaviors, called options. The option-critic architecture provides a gradient-based end-to-end learning method to construct options. We propose an attention-based extension to this framework, which enables the agent to learn to focus different options on different aspects of the observation space. We show that this leads to behaviorally diverse options which are also capable of state abstraction, and prevents the degeneracy problems of option domination and frequent option switching that occur in option-critic, while achieving a similar sample complexity. We also demonstrate the more efficient, interpretable, and reusable nature of the learned options in comparison with option-critic, through different transfer learning tasks. Experimental results in a relatively simple four-rooms environment and the more complex ALE (Arcade Learning Environment) showcase the efficacy of our approach.
Single-Shot Pruning for Offline Reinforcement Learning
Dec 31, 2021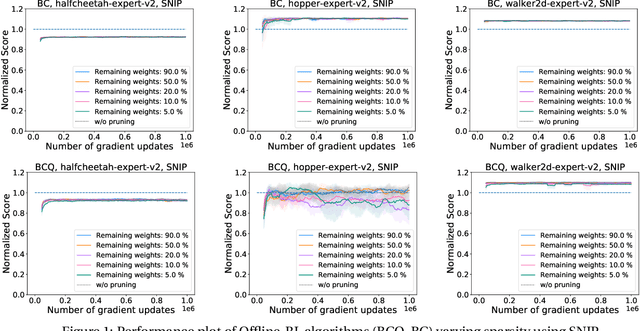
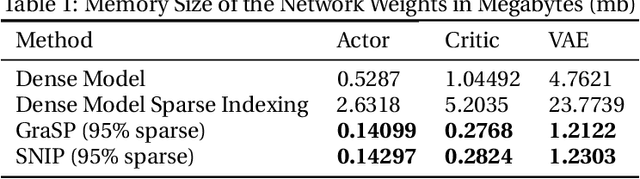
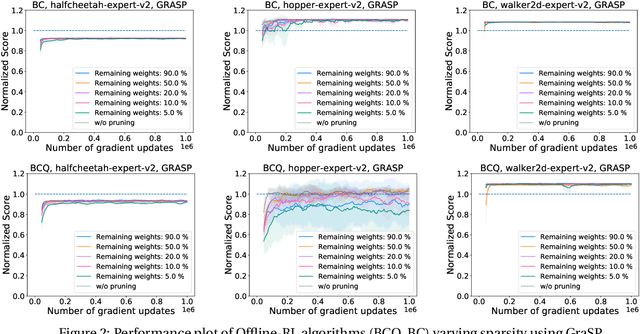
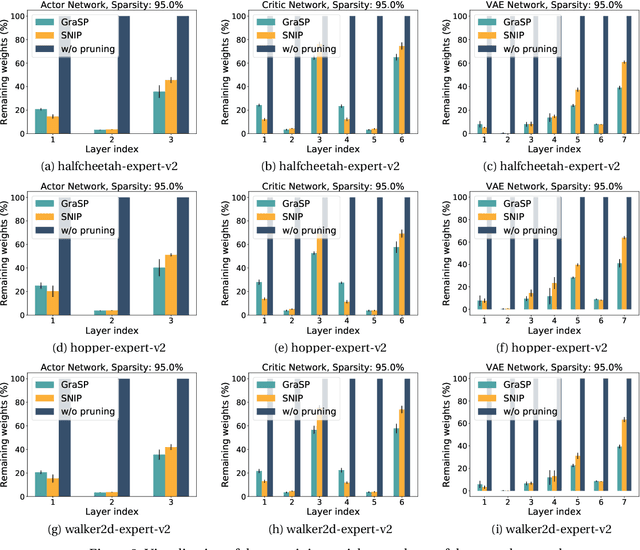
Deep Reinforcement Learning (RL) is a powerful framework for solving complex real-world problems. Large neural networks employed in the framework are traditionally associated with better generalization capabilities, but their increased size entails the drawbacks of extensive training duration, substantial hardware resources, and longer inference times. One way to tackle this problem is to prune neural networks leaving only the necessary parameters. State-of-the-art concurrent pruning techniques for imposing sparsity perform demonstrably well in applications where data distributions are fixed. However, they have not yet been substantially explored in the context of RL. We close the gap between RL and single-shot pruning techniques and present a general pruning approach to the Offline RL. We leverage a fixed dataset to prune neural networks before the start of RL training. We then run experiments varying the network sparsity level and evaluating the validity of pruning at initialization techniques in continuous control tasks. Our results show that with 95% of the network weights pruned, Offline-RL algorithms can still retain performance in the majority of our experiments. To the best of our knowledge, no prior work utilizing pruning in RL retained performance at such high levels of sparsity. Moreover, pruning at initialization techniques can be easily integrated into any existing Offline-RL algorithms without changing the learning objective.
Importance of Empirical Sample Complexity Analysis for Offline Reinforcement Learning
Dec 31, 2021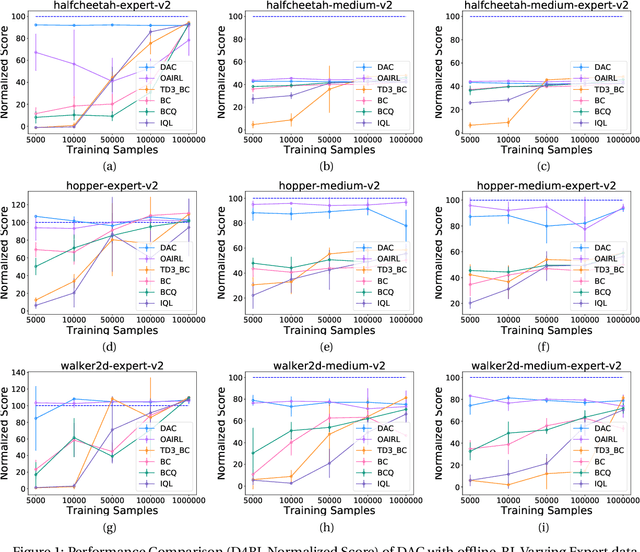
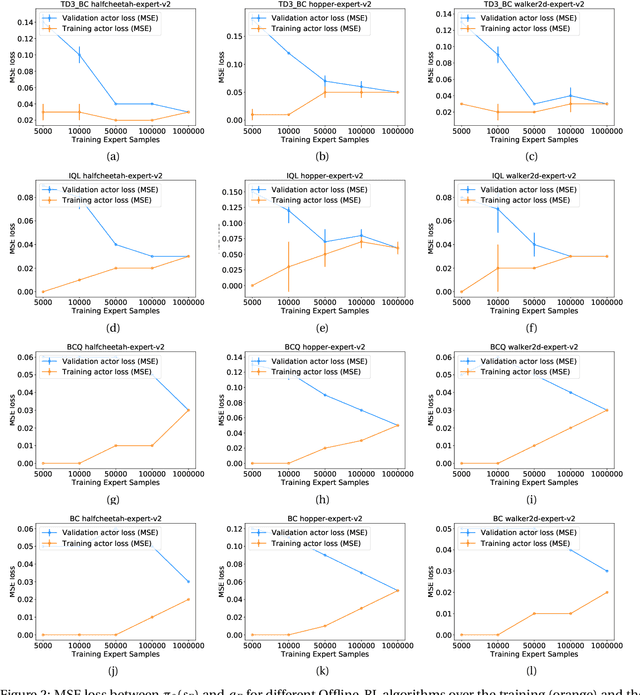
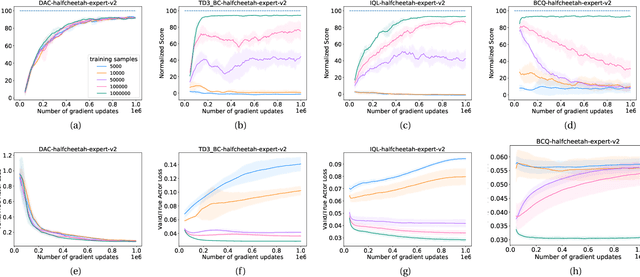
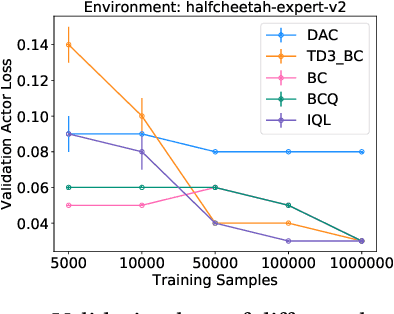
We hypothesize that empirically studying the sample complexity of offline reinforcement learning (RL) is crucial for the practical applications of RL in the real world. Several recent works have demonstrated the ability to learn policies directly from offline data. In this work, we ask the question of the dependency on the number of samples for learning from offline data. Our objective is to emphasize that studying sample complexity for offline RL is important, and is an indicator of the usefulness of existing offline algorithms. We propose an evaluation approach for sample complexity analysis of offline RL.
Constructing a Good Behavior Basis for Transfer using Generalized Policy Updates
Dec 30, 2021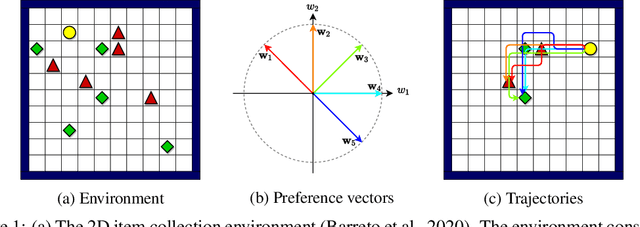

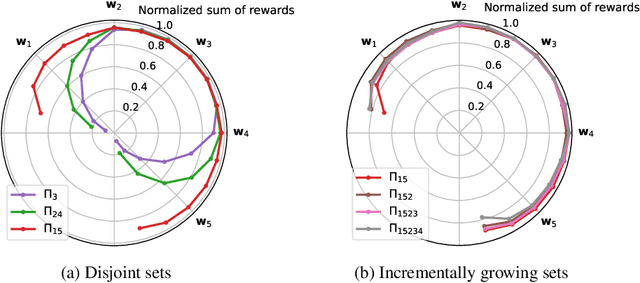
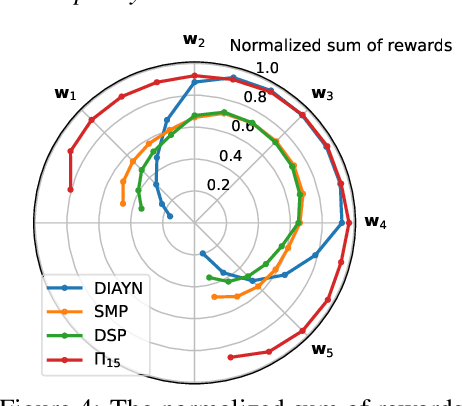
We study the problem of learning a good set of policies, so that when combined together, they can solve a wide variety of unseen reinforcement learning tasks with no or very little new data. Specifically, we consider the framework of generalized policy evaluation and improvement, in which the rewards for all tasks of interest are assumed to be expressible as a linear combination of a fixed set of features. We show theoretically that, under certain assumptions, having access to a specific set of diverse policies, which we call a set of independent policies, can allow for instantaneously achieving high-level performance on all possible downstream tasks which are typically more complex than the ones on which the agent was trained. Based on this theoretical analysis, we propose a simple algorithm that iteratively constructs this set of policies. In addition to empirically validating our theoretical results, we compare our approach with recently proposed diverse policy set construction methods and show that, while others fail, our approach is able to build a behavior basis that enables instantaneous transfer to all possible downstream tasks. We also show empirically that having access to a set of independent policies can better bootstrap the learning process on downstream tasks where the new reward function cannot be described as a linear combination of the features. Finally, we demonstrate that this policy set can be useful in a realistic lifelong reinforcement learning setting.
Proving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021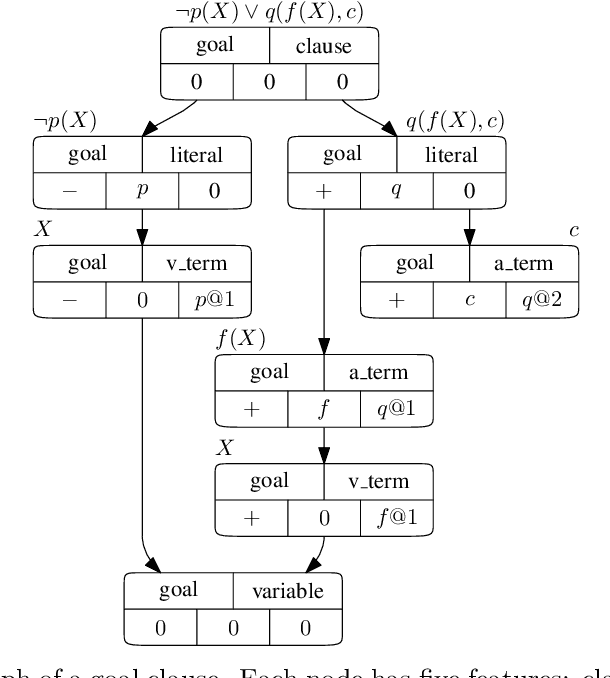
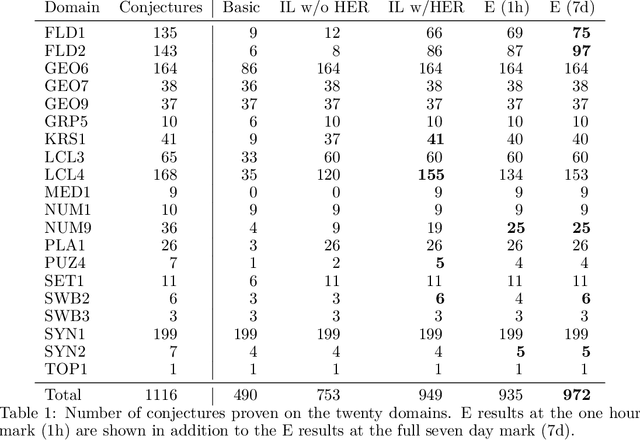
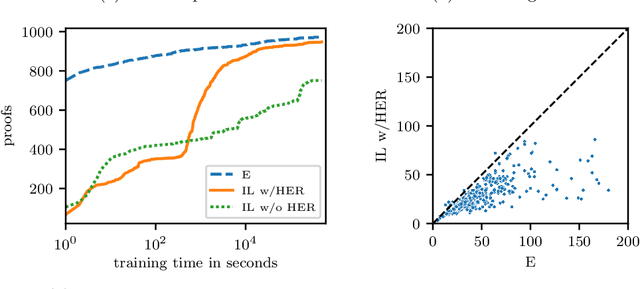
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
Flexible Option Learning
Dec 06, 2021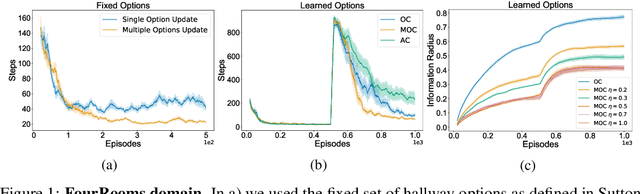
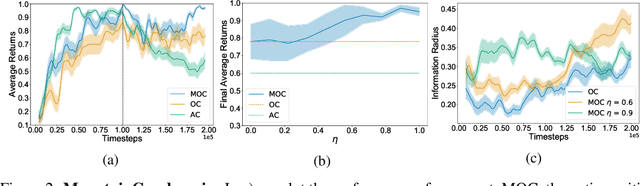

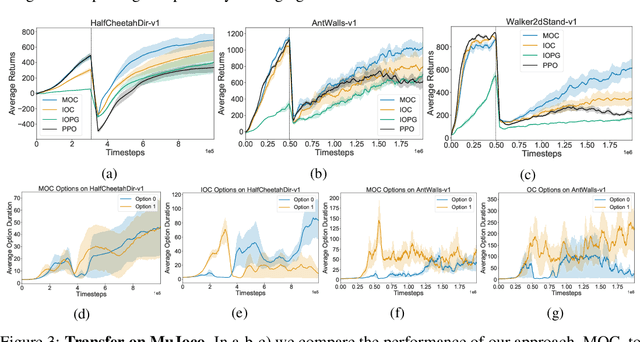
Temporal abstraction in reinforcement learning (RL), offers the promise of improving generalization and knowledge transfer in complex environments, by propagating information more efficiently over time. Although option learning was initially formulated in a way that allows updating many options simultaneously, using off-policy, intra-option learning (Sutton, Precup & Singh, 1999), many of the recent hierarchical reinforcement learning approaches only update a single option at a time: the option currently executing. We revisit and extend intra-option learning in the context of deep reinforcement learning, in order to enable updating all options consistent with current primitive action choices, without introducing any additional estimates. Our method can therefore be naturally adopted in most hierarchical RL frameworks. When we combine our approach with the option-critic algorithm for option discovery, we obtain significant improvements in performance and data-efficiency across a wide variety of domains.
On the Expressivity of Markov Reward
Nov 01, 2021


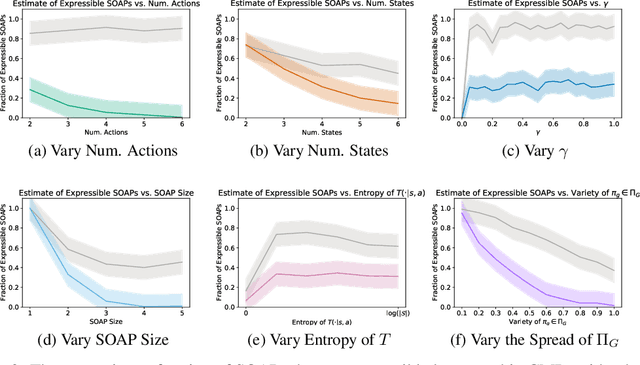
Reward is the driving force for reinforcement-learning agents. This paper is dedicated to understanding the expressivity of reward as a way to capture tasks that we would want an agent to perform. We frame this study around three new abstract notions of "task" that might be desirable: (1) a set of acceptable behaviors, (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Our main results prove that while reward can express many of these tasks, there exist instances of each task type that no Markov reward function can capture. We then provide a set of polynomial-time algorithms that construct a Markov reward function that allows an agent to optimize tasks of each of these three types, and correctly determine when no such reward function exists. We conclude with an empirical study that corroborates and illustrates our theoretical findings.
Temporal Abstraction in Reinforcement Learning with the Successor Representation
Oct 12, 2021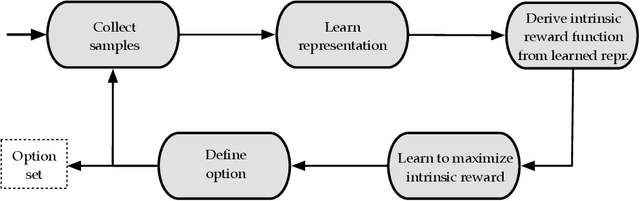
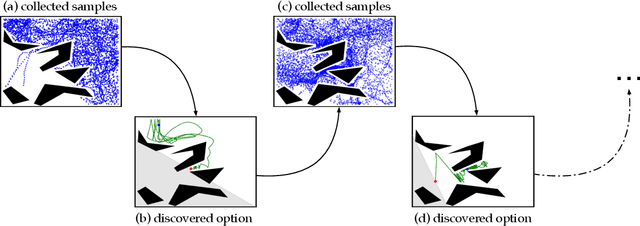
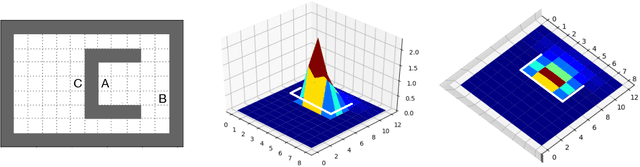
Reasoning at multiple levels of temporal abstraction is one of the key attributes of intelligence. In reinforcement learning, this is often modeled through temporally extended courses of actions called options. Options allow agents to make predictions and to operate at different levels of abstraction within an environment. Nevertheless, approaches based on the options framework often start with the assumption that a reasonable set of options is known beforehand. When this is not the case, there are no definitive answers for which options one should consider. In this paper, we argue that the successor representation (SR), which encodes states based on the pattern of state visitation that follows them, can be seen as a natural substrate for the discovery and use of temporal abstractions. To support our claim, we take a big picture view of recent results, showing how the SR can be used to discover options that facilitate either temporally-extended exploration or planning. We cast these results as instantiations of a general framework for option discovery in which the agent's representation is used to identify useful options, which are then used to further improve its representation. This results in a virtuous, never-ending, cycle in which both the representation and the options are constantly refined based on each other. Beyond option discovery itself, we discuss how the SR allows us to augment a set of options into a combinatorially large counterpart without additional learning. This is achieved through the combination of previously learned options. Our empirical evaluation focuses on options discovered for temporally-extended exploration and on the use of the SR to combine them. The results of our experiments shed light on design decisions involved in the definition of options and demonstrate the synergy of different methods based on the SR, such as eigenoptions and the option keyboard.
Is Heterophily A Real Nightmare For Graph Neural Networks To Do Node Classification?
Sep 12, 2021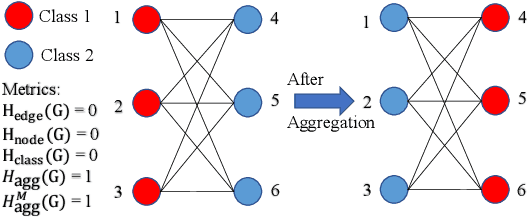
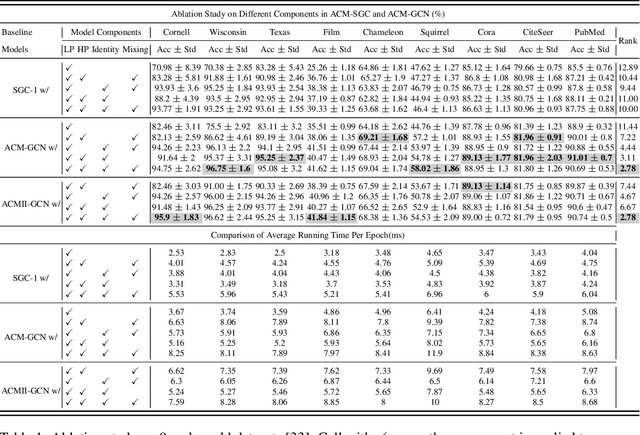
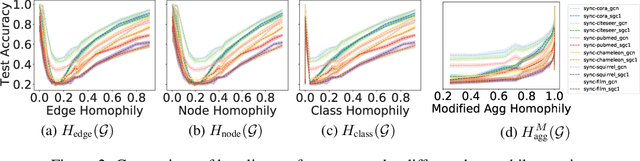
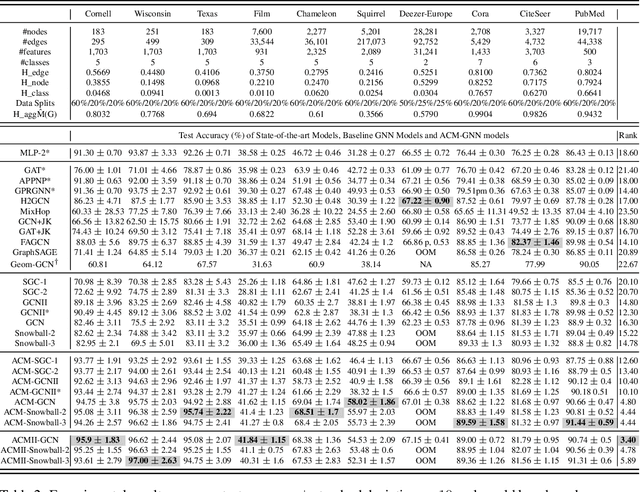
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using the graph structures based on the relational inductive bias (homophily assumption). Though GNNs are believed to outperform NNs in real-world tasks, performance advantages of GNNs over graph-agnostic NNs seem not generally satisfactory. Heterophily has been considered as a main cause and numerous works have been put forward to address it. In this paper, we first show that not all cases of heterophily are harmful for GNNs with aggregation operation. Then, we propose new metrics based on a similarity matrix which considers the influence of both graph structure and input features on GNNs. The metrics demonstrate advantages over the commonly used homophily metrics by tests on synthetic graphs. From the metrics and the observations, we find some cases of harmful heterophily can be addressed by diversification operation. With this fact and knowledge of filterbanks, we propose the Adaptive Channel Mixing (ACM) framework to adaptively exploit aggregation, diversification and identity channels in each GNN layer to address harmful heterophily. We validate the ACM-augmented baselines with 10 real-world node classification tasks. They consistently achieve significant performance gain and exceed the state-of-the-art GNNs on most of the tasks without incurring significant computational burden.
Where Did You Learn That From? Surprising Effectiveness of Membership Inference Attacks Against Temporally Correlated Data in Deep Reinforcement Learning
Sep 08, 2021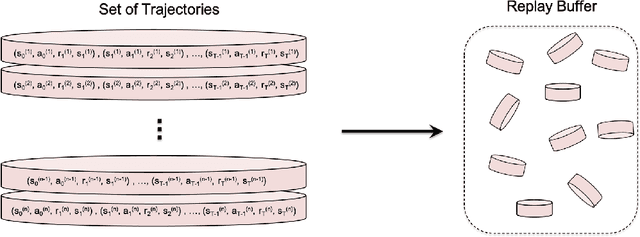
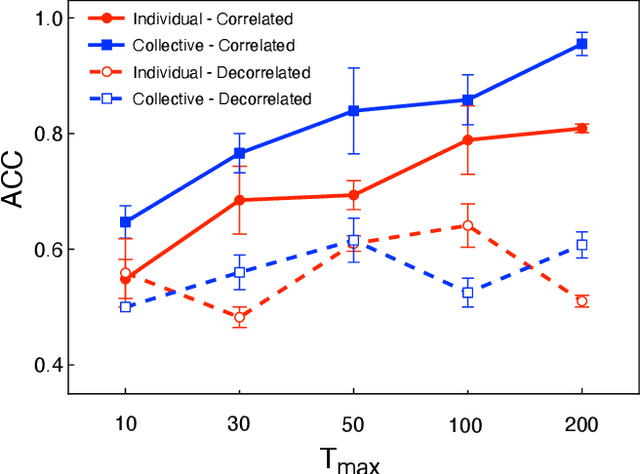
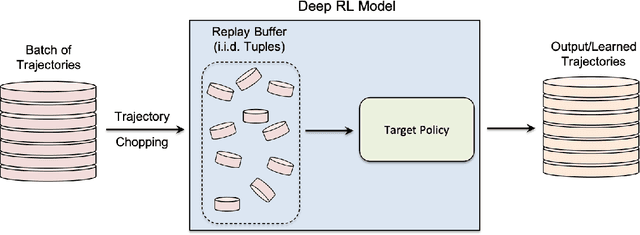

While significant research advances have been made in the field of deep reinforcement learning, a major challenge to widespread industrial adoption of deep reinforcement learning that has recently surfaced but little explored is the potential vulnerability to privacy breaches. In particular, there have been no concrete adversarial attack strategies in literature tailored for studying the vulnerability of deep reinforcement learning algorithms to membership inference attacks. To address this gap, we propose an adversarial attack framework tailored for testing the vulnerability of deep reinforcement learning algorithms to membership inference attacks. More specifically, we design a series of experiments to investigate the impact of temporal correlation, which naturally exists in reinforcement learning training data, on the probability of information leakage. Furthermore, we study the differences in the performance of \emph{collective} and \emph{individual} membership attacks against deep reinforcement learning algorithms. Experimental results show that the proposed adversarial attack framework is surprisingly effective at inferring the data used during deep reinforcement training with an accuracy exceeding $84\%$ in individual and $97\%$ in collective mode on two different control tasks in OpenAI Gym, which raises serious privacy concerns in the deployment of models resulting from deep reinforcement learning. Moreover, we show that the learning state of a reinforcement learning algorithm significantly influences the level of the privacy breach.