 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to cooperate: Emergent communication in multi-agent navigation
Apr 02, 2020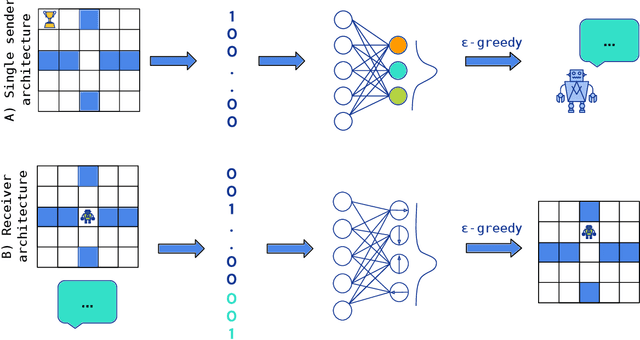

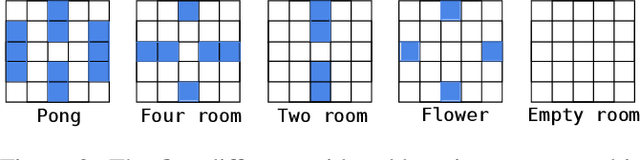
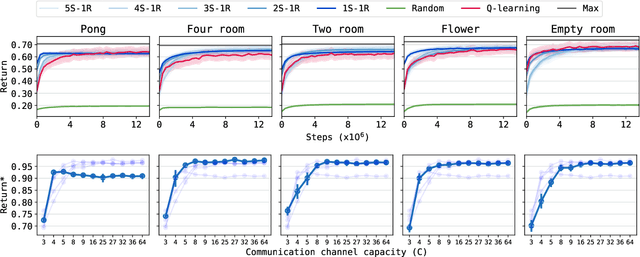
Emergent communication in artificial agents has been studied to understand language evolution, as well as to develop artificial systems that learn to communicate with humans. We show that agents performing a cooperative navigation task in various gridworld environments learn an interpretable communication protocol that enables them to efficiently, and in many cases, optimally, solve the task. An analysis of the agents' policies reveals that emergent signals spatially cluster the state space, with signals referring to specific locations and spatial directions such as "left", "up", or "upper left room". Using populations of agents, we show that the emergent protocol has basic compositional structure, thus exhibiting a core property of natural language.
A Distributional Analysis of Sampling-Based Reinforcement Learning Algorithms
Mar 27, 2020
We present a distributional approach to theoretical analyses of reinforcement learning algorithms for constant step-sizes. We demonstrate its effectiveness by presenting simple and unified proofs of convergence for a variety of commonly-used methods. We show that value-based methods such as TD($\lambda$) and $Q$-Learning have update rules which are contractive in the space of distributions of functions, thus establishing their exponentially fast convergence to a stationary distribution. We demonstrate that the stationary distribution obtained by any algorithm whose target is an expected Bellman update has a mean which is equal to the true value function. Furthermore, we establish that the distributions concentrate around their mean as the step-size shrinks. We further analyse the optimistic policy iteration algorithm, for which the contraction property does not hold, and formulate a probabilistic policy improvement property which entails the convergence of the algorithm.
Interference and Generalization in Temporal Difference Learning
Mar 13, 2020
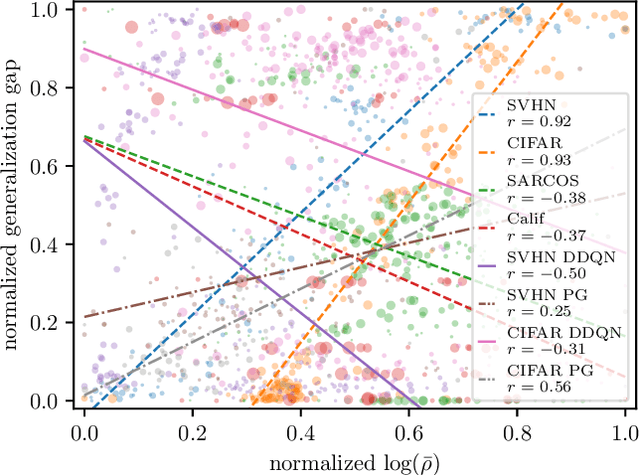
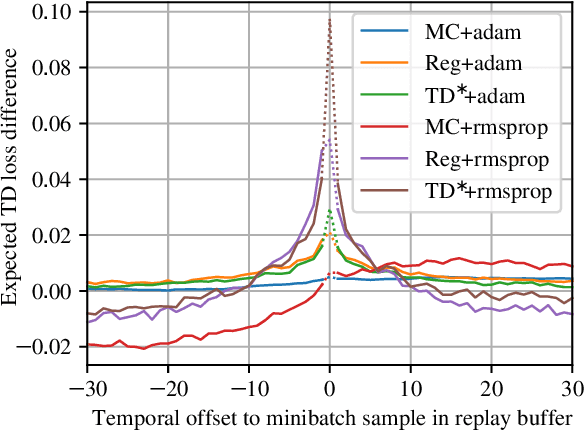
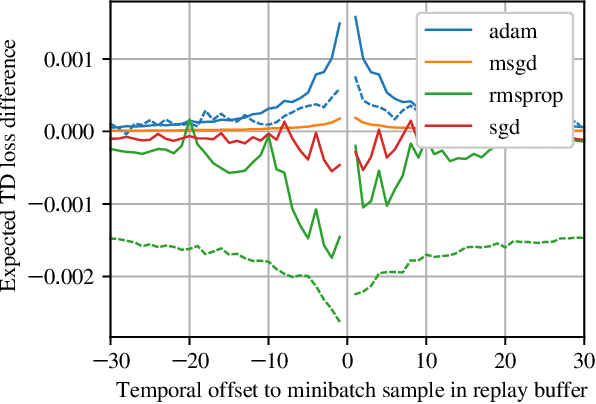
We study the link between generalization and interference in temporal-difference (TD) learning. Interference is defined as the inner product of two different gradients, representing their alignment. This quantity emerges as being of interest from a variety of observations about neural networks, parameter sharing and the dynamics of learning. We find that TD easily leads to low-interference, under-generalizing parameters, while the effect seems reversed in supervised learning. We hypothesize that the cause can be traced back to the interplay between the dynamics of interference and bootstrapping. This is supported empirically by several observations: the negative relationship between the generalization gap and interference in TD, the negative effect of bootstrapping on interference and the local coherence of targets, and the contrast between the propagation rate of information in TD(0) versus TD($\lambda$) and regression tasks such as Monte-Carlo policy evaluation. We hope that these new findings can guide the future discovery of better bootstrapping methods.
Invariant Causal Prediction for Block MDPs
Mar 12, 2020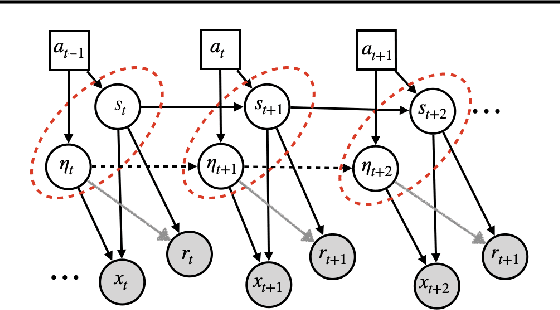
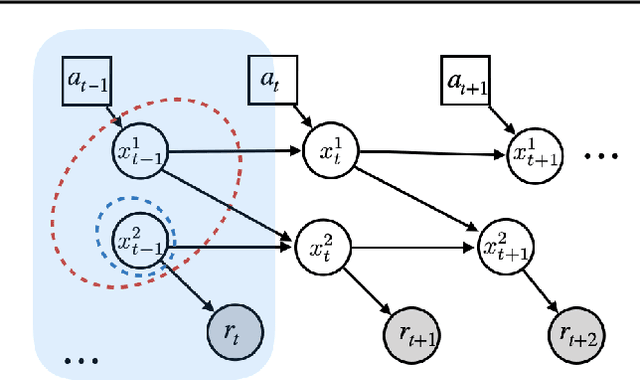
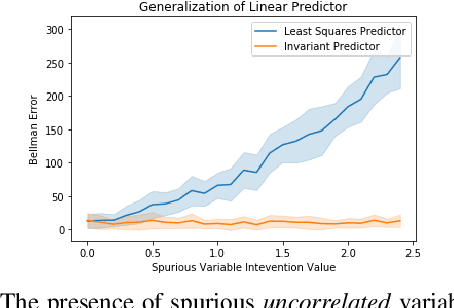
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give empirical evidence that our methods work in both linear and nonlinear settings, attaining improved generalization over single- and multi-task baselines.
Policy Evaluation Networks
Feb 26, 2020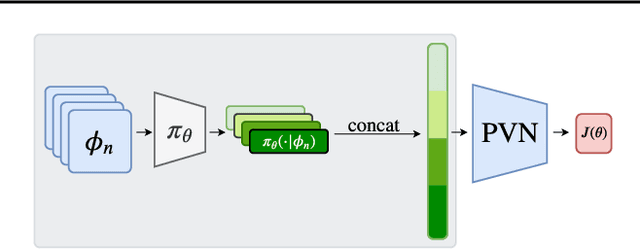
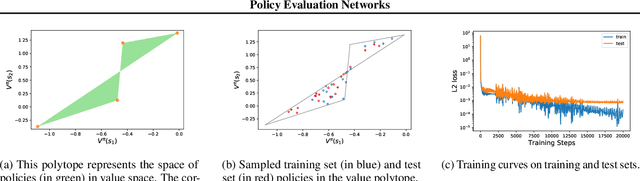
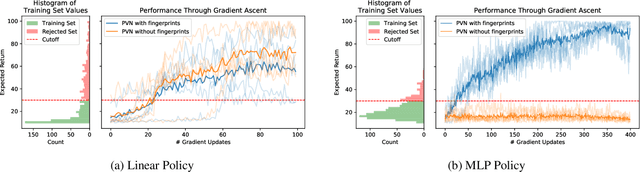
Many reinforcement learning algorithms use value functions to guide the search for better policies. These methods estimate the value of a single policy while generalizing across many states. The core idea of this paper is to flip this convention and estimate the value of many policies, for a single set of states. This approach opens up the possibility of performing direct gradient ascent in policy space without seeing any new data. The main challenge for this approach is finding a way to represent complex policies that facilitates learning and generalization. To address this problem, we introduce a scalable, differentiable fingerprinting mechanism that retains essential policy information in a concise embedding. Our empirical results demonstrate that combining these three elements (learned Policy Evaluation Network, policy fingerprints, gradient ascent) can produce policies that outperform those that generated the training data, in zero-shot manner.
oIRL: Robust Adversarial Inverse Reinforcement Learning with Temporally Extended Actions
Feb 20, 2020

Explicit engineering of reward functions for given environments has been a major hindrance to reinforcement learning methods. While Inverse Reinforcement Learning (IRL) is a solution to recover reward functions from demonstrations only, these learned rewards are generally heavily \textit{entangled} with the dynamics of the environment and therefore not portable or \emph{robust} to changing environments. Modern adversarial methods have yielded some success in reducing reward entanglement in the IRL setting. In this work, we leverage one such method, Adversarial Inverse Reinforcement Learning (AIRL), to propose an algorithm that learns hierarchical disentangled rewards with a policy over options. We show that this method has the ability to learn \emph{generalizable} policies and reward functions in complex transfer learning tasks, while yielding results in continuous control benchmarks that are comparable to those of the state-of-the-art methods.
Value-driven Hindsight Modelling
Feb 19, 2020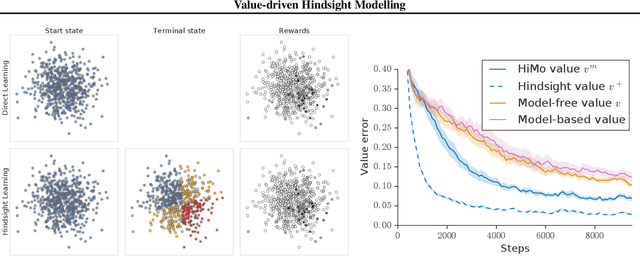
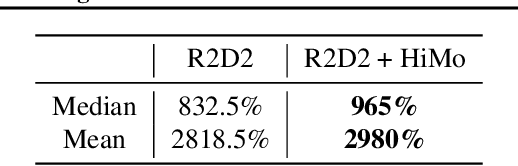
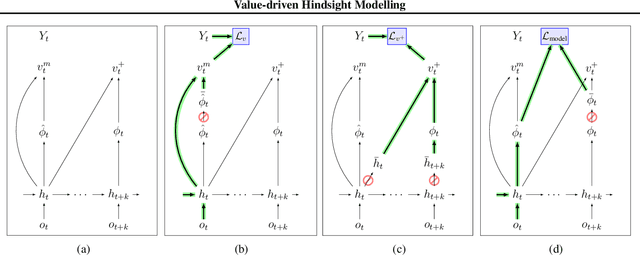

Value estimation is a critical component of the reinforcement learning (RL) paradigm. The question of how to effectively learn predictors for value from data is one of the major problems studied by the RL community, and different approaches exploit structure in the problem domain in different ways. Model learning can make use of the rich transition structure present in sequences of observations, but this approach is usually not sensitive to the reward function. In contrast, model-free methods directly leverage the quantity of interest from the future but have to compose with a potentially weak scalar signal (an estimate of the return). In this paper we develop an approach for representation learning in RL that sits in between these two extremes: we propose to learn what to model in a way that can directly help value prediction. To this end we determine which features of the future trajectory provide useful information to predict the associated return. This provides us with tractable prediction targets that are directly relevant for a task, and can thus accelerate learning of the value function. The idea can be understood as reasoning, in hindsight, about which aspects of the future observations could help past value prediction. We show how this can help dramatically even in simple policy evaluation settings. We then test our approach at scale in challenging domains, including on 57 Atari 2600 games.
Provably efficient reconstruction of policy networks
Feb 07, 2020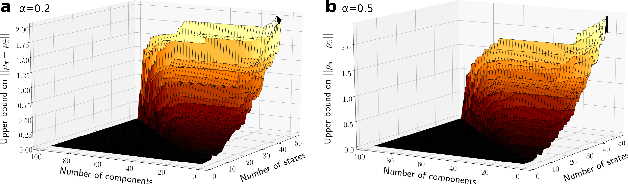
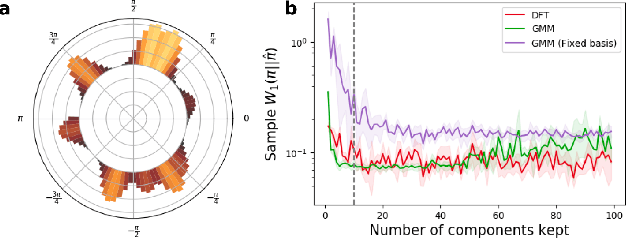
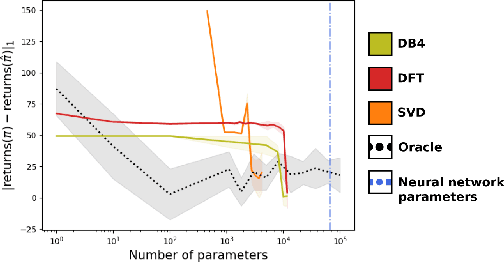
Recent research has shown that learning poli-cies parametrized by large neural networks can achieve significant success on challenging reinforcement learning problems. However, when memory is limited, it is not always possible to store such models exactly for inference, and com-pressing the policy into a compact representation might be necessary. We propose a general framework for policy representation, which reduces this problem to finding a low-dimensional embedding of a given density function in a separable inner product space. Our framework allows us to de-rive strong theoretical guarantees, controlling the error of the reconstructed policies. Such guaran-tees are typically lacking in black-box models, but are very desirable in risk-sensitive tasks. Our experimental results suggest that the reconstructed policies can use less than 10%of the number of parameters in the original networks, while incurring almost no decrease in rewards.
Option-critic in cooperative multi-agent systems
Jan 06, 2020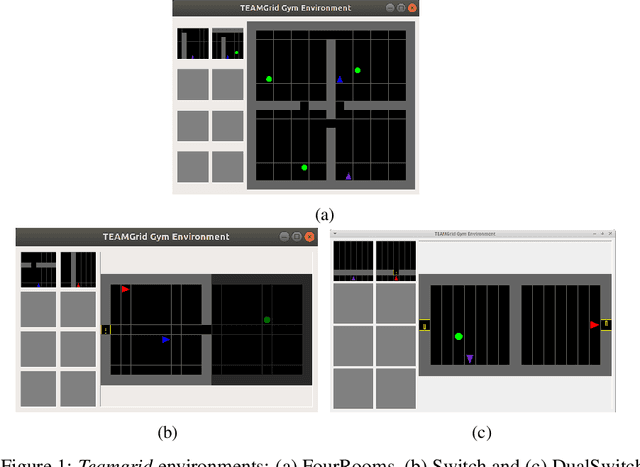
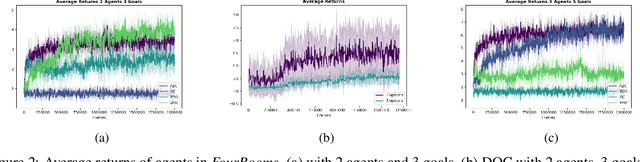
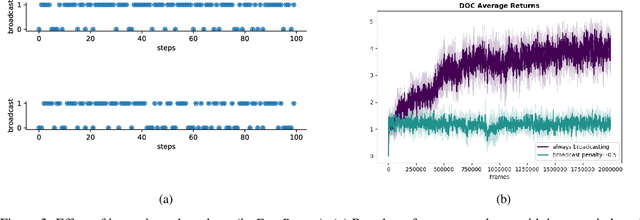
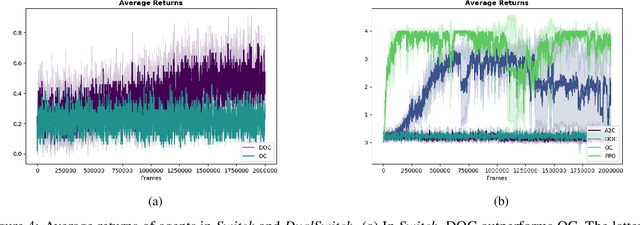
In this paper, we investigate learning temporal abstractions in cooperative multi-agent systems using the options framework (Sutton et al, 1999) and provide a model-free algorithm for this problem. First, we address the planning problem for the decentralized POMDP represented by the multi-agent system, by introducing a common information approach. We use common beliefs and broadcasting to solve an equivalent centralized POMDP problem. Then, we propose the Distributed Option Critic (DOC) algorithm, motivated by the work of Bacon et al (2017) in the single-agent setting. Our approach uses centralized option evaluation and decentralized intra-option improvement. We analyze theoretically the asymptotic convergence of DOC and validate its performance in grid-world environments, where we implement DOC using a deep neural network. Our experiments show that DOC performs competitively with state-of-the-art algorithms and that it is scalable when the number of agents increases.
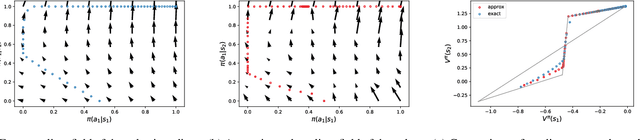
Options of Interest: Temporal Abstraction with Interest Functions
Jan 01, 2020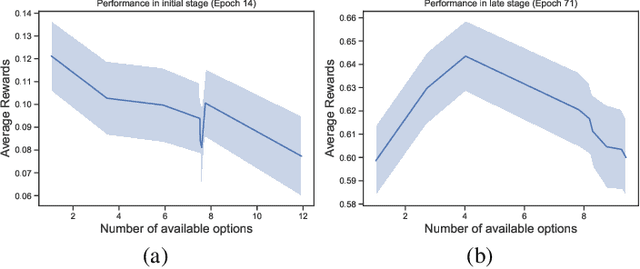

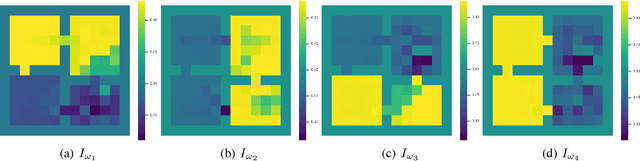
Temporal abstraction refers to the ability of an agent to use behaviours of controllers which act for a limited, variable amount of time. The options framework describes such behaviours as consisting of a subset of states in which they can initiate, an internal policy and a stochastic termination condition. However, much of the subsequent work on option discovery has ignored the initiation set, because of difficulty in learning it from data. We provide a generalization of initiation sets suitable for general function approximation, by defining an interest function associated with an option. We derive a gradient-based learning algorithm for interest functions, leading to a new interest-option-critic architecture. We investigate how interest functions can be leveraged to learn interpretable and reusable temporal abstractions. We demonstrate the efficacy of the proposed approach through quantitative and qualitative results, in both discrete and continuous environments.