 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDmitry Berenson
TAMPC: A Controller for Escaping Traps in Novel Environments
Oct 23, 2020
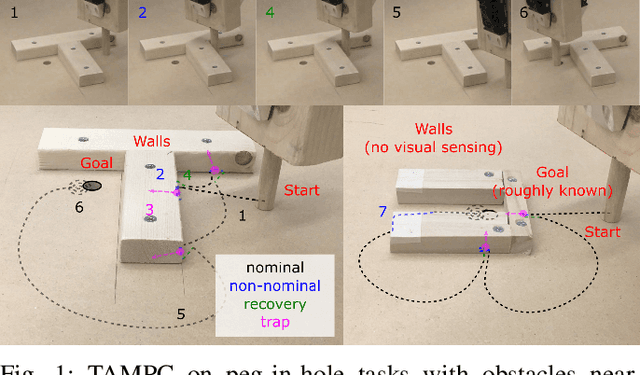
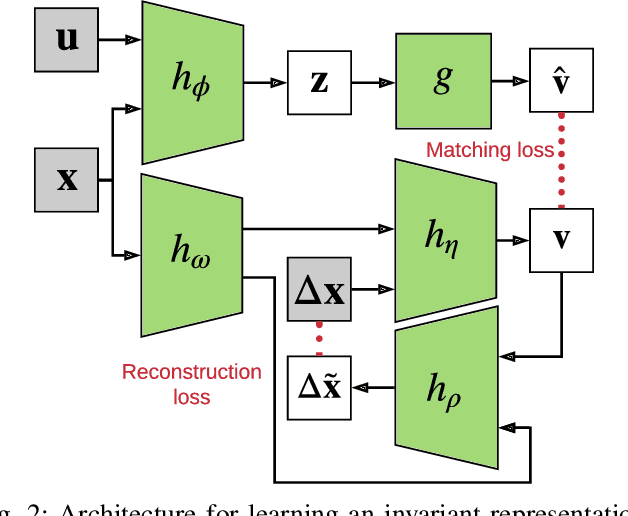
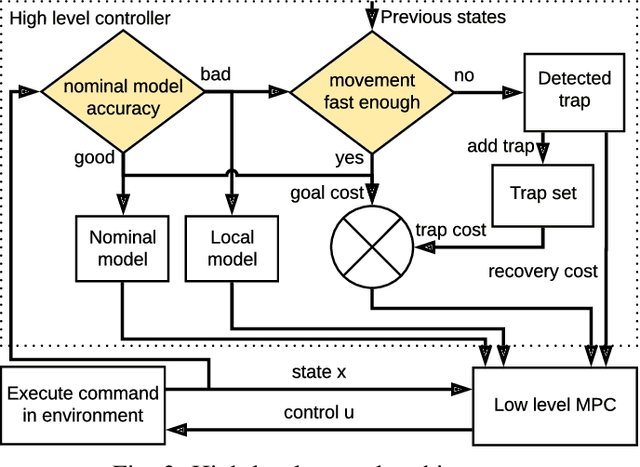
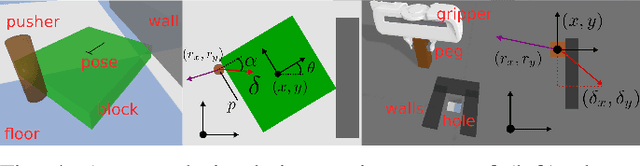
We propose an approach to online model adaptation and control in the challenging case of hybrid and discontinuous dynamics where actions may lead to difficult-to-escape "trap" states. We first learn dynamics for a given system from training data which does not contain unexpected traps (since we do not know what traps will be encountered online). These "nominal" dynamics allow us to perform tasks under ideal conditions, but when unexpected traps arise in execution, we must find a way to adapt our dynamics and control strategy and continue attempting the task. Our approach, Trap-Aware Model Predictive Control (TAMPC), is a two-level hierarchical control algorithm that reasons about traps and non-nominal dynamics to decide between goal-seeking and recovery policies. An important requirement of our method is the ability to recognize nominal dynamics even when we encounter data that is out-of-distribution w.r.t the training data. We achieve this by learning a representation for dynamics that exploits invariance in the nominal environment, thus allowing better generalization. We evaluate our method on simulated planar pushing and peg-in-hole as well as real robot peg-in-hole problems against adaptive control and reinforcement learning baselines, where traps arise due to unexpected obstacles that we only observe through contact. Our results show that our method significantly outperforms the baselines in all tested scenarios.
Planning with Learned Dynamics: Guaranteed Safety and Reachability via Lipschitz Constants
Oct 18, 2020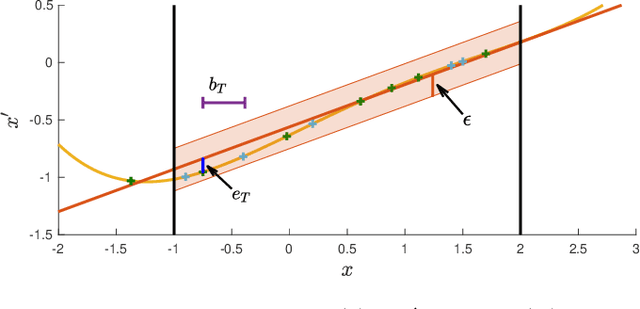
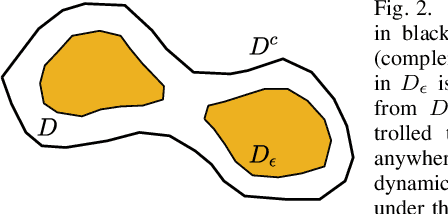
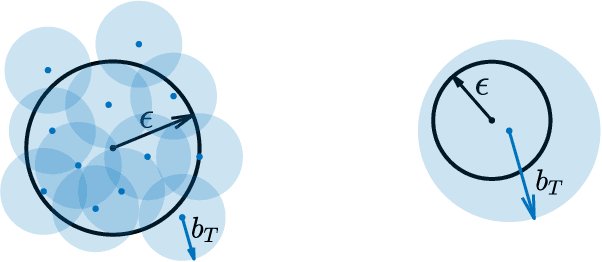
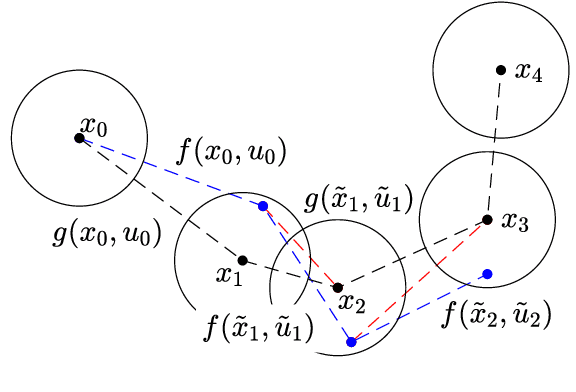
We present an approach for feedback motion planning of systems with unknown dynamics which provides guarantees on safety, reachability, and stability about the goal. Given a learned control-affine approximation of the true dynamics, we estimate the Lipschitz constant of the difference between the true and learned dynamics to determine a trusted domain for our learned model. Provided the system has at least as many controls as states, we further derive the conditions under which a one-step feedback law exists. This allows fora small bound on the tracking error when the trajectory is executed on the real system. Our method imposes a check for the existence of the feedback law as constraints in a sampling-based planner, which returns a feedback policy ensuring that under the true dynamics, the goal is reachable, the path is safe in execution, and the closed-loop system is invariant in a small set about the goal. We demonstrate our approach by planning using learned models of a 6D quadrotor and a 7DOF Kuka arm.We show that a baseline which plans using the same learned dynamics without considering the error bound or the existence of the feedback law can fail to stabilize around the plan and become unsafe.
Explaining Multi-stage Tasks by Learning Temporal Logic Formulas from Suboptimal Demonstrations
Jun 03, 2020

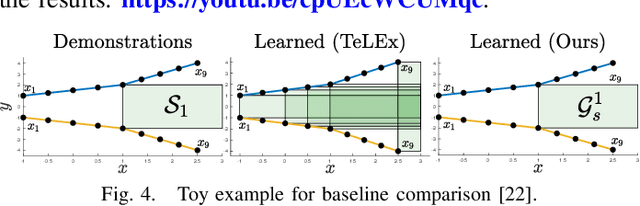
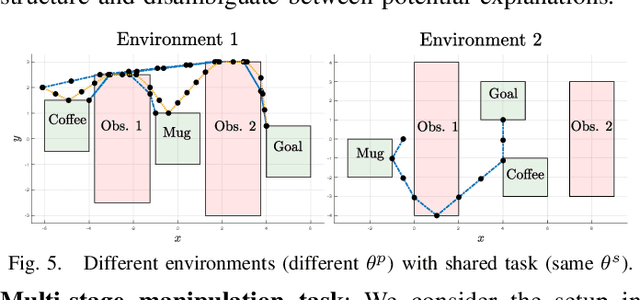
We present a method for learning multi-stage tasks from demonstrations by learning the logical structure and atomic propositions of a consistent linear temporal logic (LTL) formula. The learner is given successful but potentially suboptimal demonstrations, where the demonstrator is optimizing a cost function while satisfying the LTL formula, and the cost function is uncertain to the learner. Our algorithm uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations together with a counterexample-guided falsification strategy to learn the atomic proposition parameters and logical structure of the LTL formula, respectively. We provide theoretical guarantees on the conservativeness of the recovered atomic proposition sets, as well as completeness in the search for finding an LTL formula consistent with the demonstrations. We evaluate our method on high-dimensional nonlinear systems by learning LTL formulas explaining multi-stage tasks on 7-DOF arm and quadrotor systems and show that it outperforms competing methods for learning LTL formulas from positive examples.
Inferring Obstacles and Path Validity from Visibility-Constrained Demonstrations
May 11, 2020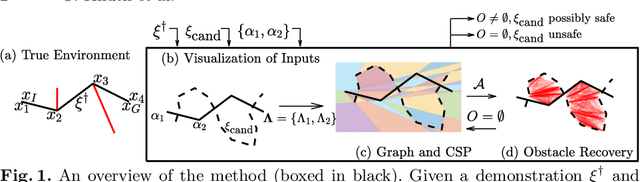
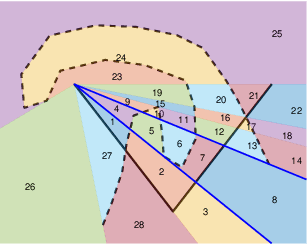
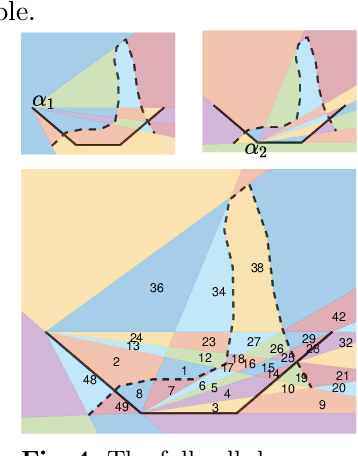
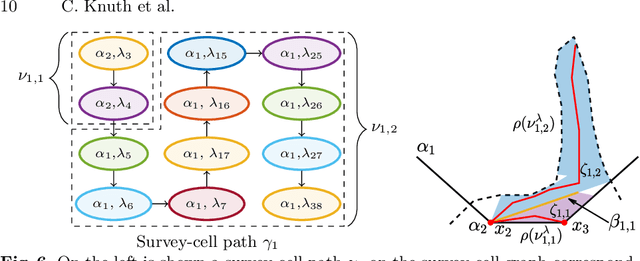
Many methods in learning from demonstration assume that the demonstrator has knowledge of the full environment. However, in many scenarios, a demonstrator only sees part of the environment and they continuously replan as they gather information. To plan new paths or to reconstruct the environment, we must consider the visibility constraints and replanning process of the demonstrator, which, to our knowledge, has not been done in previous work. We consider the problem of inferring obstacle configurations in a 2D environment from demonstrated paths for a point robot that is capable of seeing in any direction but not through obstacles. Given a set of \textit{survey points}, which describe where the demonstrator obtains new information, and a candidate path, we construct a Constraint Satisfaction Problem (CSP) on a cell decomposition of the environment. We parameterize a set of obstacles corresponding to an assignment from the CSP and sample from the set to find valid environments. We show that there is a probabilistically-complete, yet not entirely tractable, algorithm that can guarantee novel paths in the space are unsafe or possibly safe. We also present an incomplete, but empirically-successful, heuristic-guided algorithm that we apply in our experiments to 1) planning novel paths and 2) recovering a probabilistic representation of the environment.
Fast Planning Over Roadmaps via Selective Densification
Feb 12, 2020
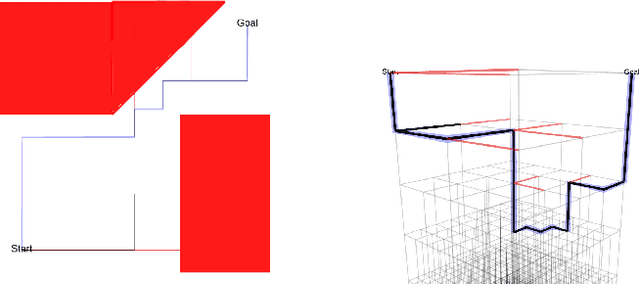
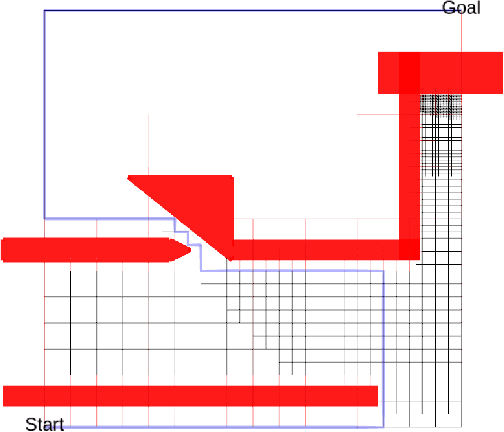
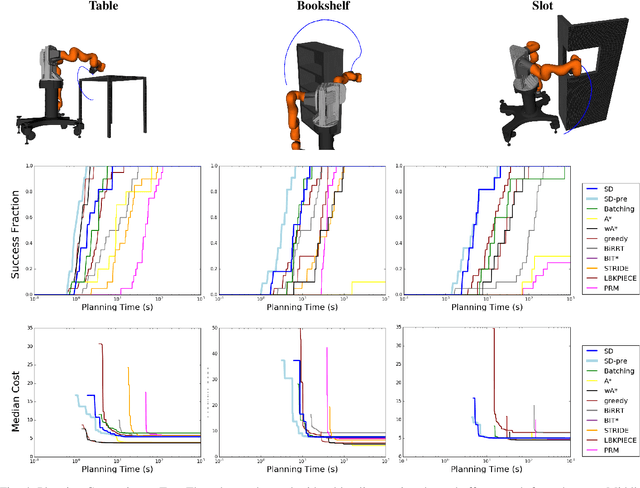
We propose the Selective Densification method for fast motion planning through configuration space. We create a sequence of roadmaps by iteratively adding configurations. We organize these roadmaps into layers and add edges between identical configurations between layers. We find a path using best-first search, guided by our proposed estimate of remaining planning time. This estimate prefers to expand nodes closer to the goal and nodes on sparser layers. We present proofs of the path quality and maximum depth of nodes expanded using our proposed graph and heuristic. We also present experiments comparing Selective Densification to bidirectional RRT-connect, as well as many graph search approaches. In difficult environments that require exploration on the dense layers we find Selective Densification finds solutions faster than all other approaches.
Learning When to Trust a Dynamics Model for Planning in Reduced State Spaces
Jan 29, 2020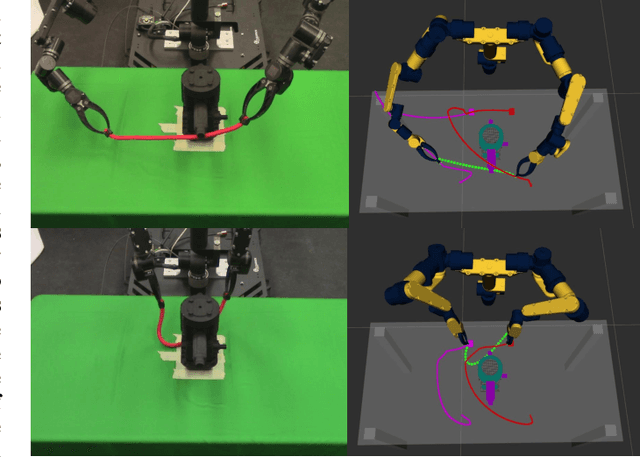
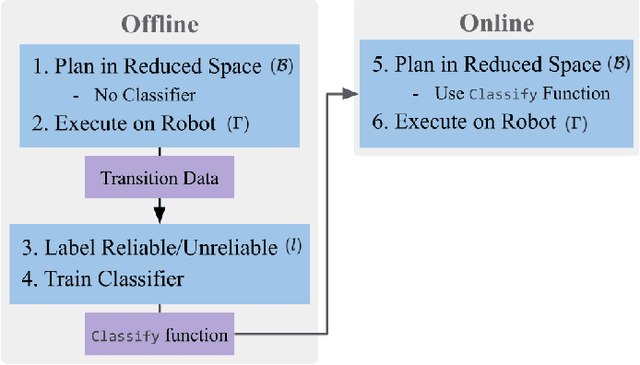
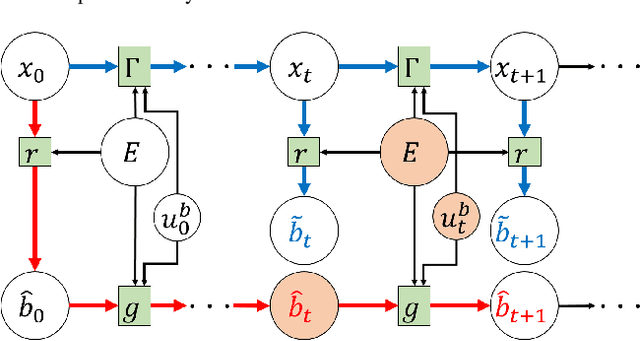
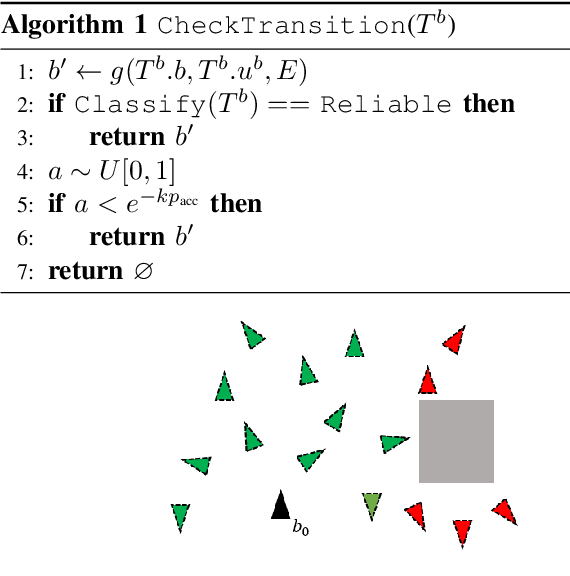
When the dynamics of a system are difficult to model and/or time-consuming to evaluate, such as in deformable object manipulation tasks, motion planning algorithms struggle to find feasible plans efficiently. Such problems are often reduced to state spaces where the dynamics are straightforward to model and evaluate. However, such reductions usually discard information about the system for the benefit of computational efficiency, leading to cases where the true and reduced dynamics disagree on the result of an action. This paper presents a formulation for planning in reduced state spaces that uses a classifier to bias the planner away from state-action pairs that are not reliably feasible under the true dynamics. We present a method to generate and label data to train such a classifier, as well as an application of our framework to rope manipulation, where we use a Virtual Elastic Band (VEB) approximation to the true dynamics. Our experiments with rope manipulation demonstrate that the classifier significantly improves the success rate of our RRT-based planner in several difficult scenarios which are designed to cause the VEB to produce incorrect predictions in key parts of the environment.
Manipulating Deformable Objects by Interleaving Prediction, Planning, and Control
Jan 27, 2020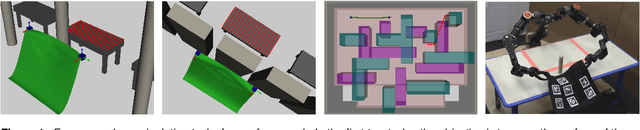

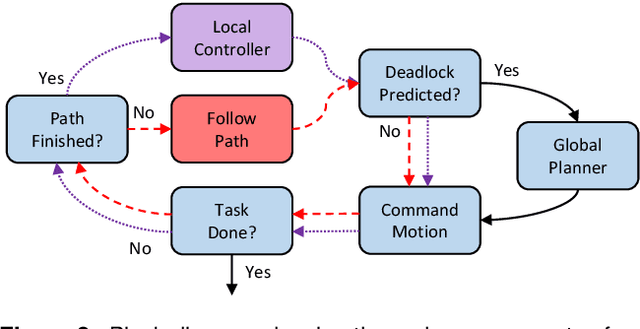

We present a framework for deformable object manipulation that interleaves planning and control, enabling complex manipulation tasks without relying on high-fidelity modeling or simulation. The key question we address is when should we use planning and when should we use control to achieve the task? Planners are designed to find paths through complex configuration spaces, but for highly underactuated systems, such as deformable objects, achieving a specific configuration is very difficult even with high-fidelity models. Conversely, controllers can be designed to achieve specific configurations, but they can be trapped in undesirable local minima due to obstacles. Our approach consists of three components: (1) A global motion planner to generate gross motion of the deformable object; (2) A local controller for refinement of the configuration of the deformable object; and (3) A novel deadlock prediction algorithm to determine when to use planning versus control. By separating planning from control we are able to use different representations of the deformable object, reducing overall complexity and enabling efficient computation of motion. We provide a detailed proof of probabilistic completeness for our planner, which is valid despite the fact that our system is underactuated and we do not have a steering function. We then demonstrate that our framework is able to successfully perform several manipulation tasks with rope and cloth in simulation which cannot be performed using either our controller or planner alone. These experiments suggest that our planner can generate paths efficiently, taking under a second on average to find a feasible path in three out of four scenarios. We also show that our framework is effective on a 16 DoF physical robot, where reachability and dual-arm constraints make the planning more difficult.
Learning Constraints from Locally-Optimal Demonstrations under Cost Function Uncertainty
Jan 25, 2020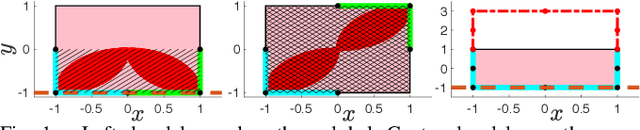
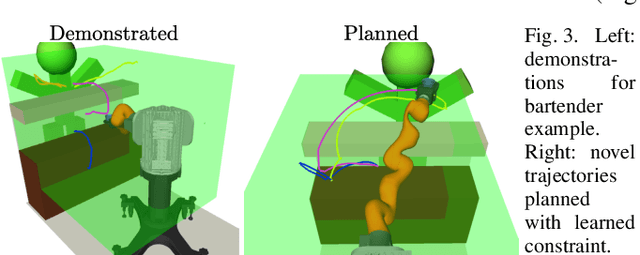
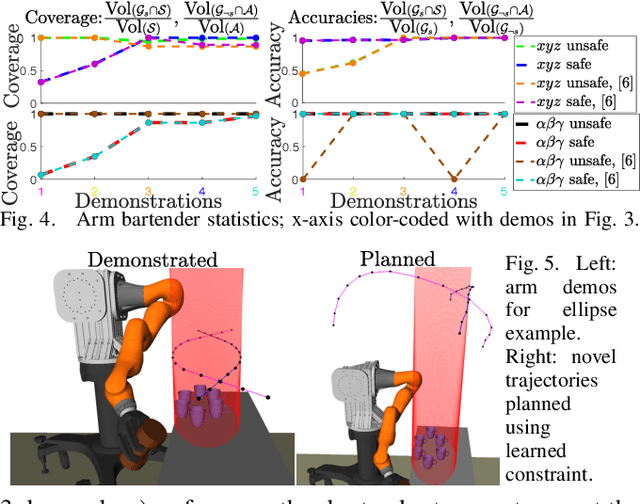
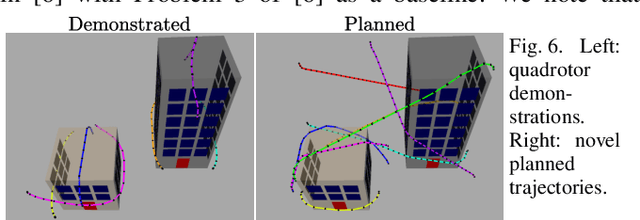
We present an algorithm for learning parametric constraints from locally-optimal demonstrations, where the cost function being optimized is uncertain to the learner. Our method uses the Karush-Kuhn-Tucker (KKT) optimality conditions of the demonstrations within a mixed integer linear program (MILP) to learn constraints which are consistent with the local optimality of the demonstrations, by either using a known constraint parameterization or by incrementally growing a parameterization that is consistent with the demonstrations. We provide theoretical guarantees on the conservativeness of the recovered safe/unsafe sets and analyze the limits of constraint learnability when using locally-optimal demonstrations. We evaluate our method on high-dimensional constraints and systems by learning constraints for 7-DOF arm and quadrotor examples, show that it outperforms competing constraint-learning approaches, and can be effectively used to plan new constraint-satisfying trajectories in the environment.
Learning Parametric Constraints in High Dimensions from Demonstrations
Oct 08, 2019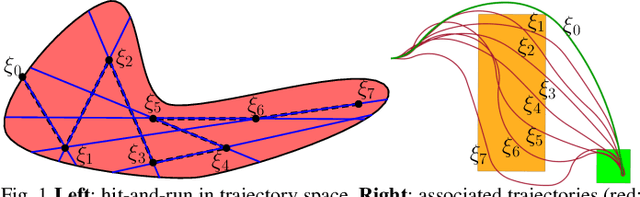
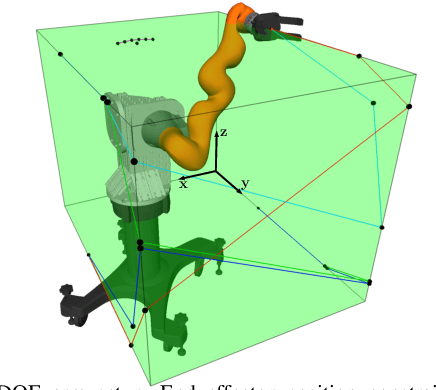
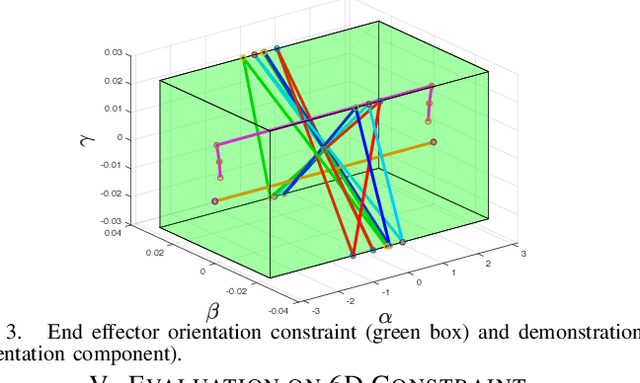
We present a scalable algorithm for learning parametric constraints in high dimensions from safe expert demonstrations. To reduce the ill-posedness of the constraint recovery problem, our method uses hit-and-run sampling to generate lower cost, and thus unsafe, trajectories. Both safe and unsafe trajectories are used to obtain a representation of the unsafe set that is compatible with the data by solving an integer program in that representation's parameter space. Our method can either leverage a known parameterization or incrementally grow a parameterization while remaining consistent with the data, and we provide theoretical guarantees on the conservativeness of the recovered unsafe set. We evaluate our method on high-dimensional constraints for high-dimensional systems by learning constraints for 7-DOF arm, quadrotor, and planar pushing examples, and show that our method outperforms baseline approaches.
Robust Humanoid Contact Planning with Learned Zero- and One-Step Capturability Prediction
Sep 19, 2019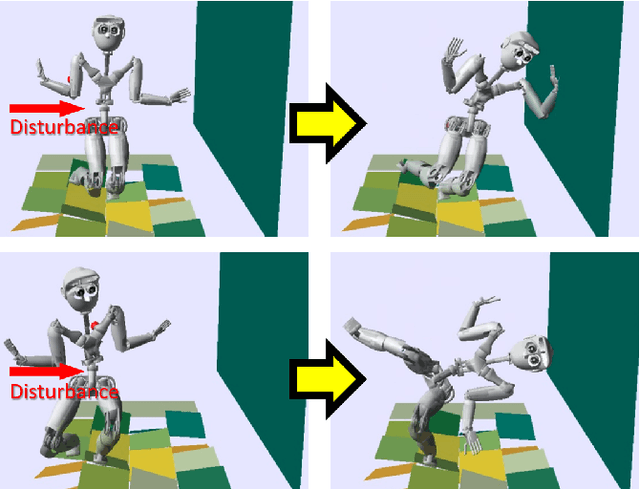
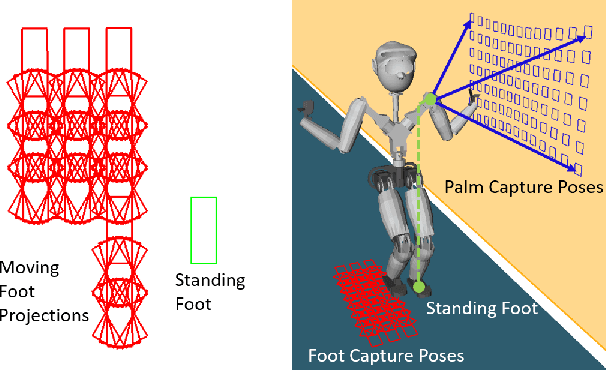
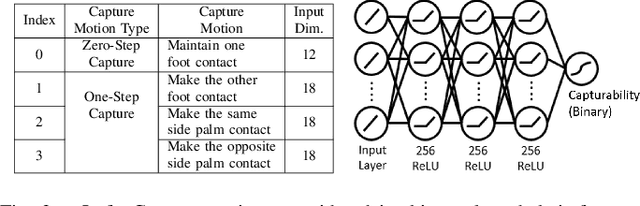
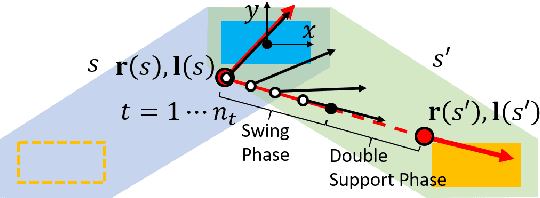
Humanoid robots maintain balance and navigate by controlling the contact wrenches applied to the environment. While it is possible to plan dynamically-feasible motion that applies appropriate wrenches using existing methods, a humanoid may also be affected by external disturbances. Existing systems typically rely on controllers to reactively recover from disturbances. However, such controllers may fail when the robot cannot reach contacts capable of rejecting a given disturbance. In this paper, we propose a search-based footstep planner which aims to maximize the probability of the robot successfully reaching the goal without falling under disturbances. The planner considers not only the poses of the planned contact sequence, but also alternative contacts near the planned contact sequence that can be used to recover from external disturbances. Although this additional consideration significantly increases the computation load, we train neural networks to efficiently predict multi-contact zero-step and one-step capturability, which allows the planner to generate robust contact sequences efficiently. Our results show that our approach generates footstep sequences that are more robust to external disturbances than a conventional footstep planner in four challenging scenarios.