 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fusion Framework for Camouflaged Moving Foreground Detection in the Wavelet Domain
Apr 16, 2018


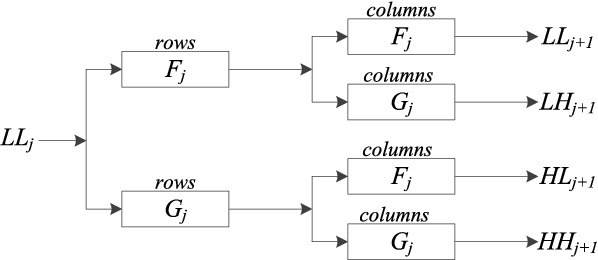
Detecting camouflaged moving foreground objects has been known to be difficult due to the similarity between the foreground objects and the background. Conventional methods cannot distinguish the foreground from background due to the small differences between them and thus suffer from under-detection of the camouflaged foreground objects. In this paper, we present a fusion framework to address this problem in the wavelet domain. We first show that the small differences in the image domain can be highlighted in certain wavelet bands. Then the likelihood of each wavelet coefficient being foreground is estimated by formulating foreground and background models for each wavelet band. The proposed framework effectively aggregates the likelihoods from different wavelet bands based on the characteristics of the wavelet transform. Experimental results demonstrated that the proposed method significantly outperformed existing methods in detecting camouflaged foreground objects. Specifically, the average F-measure for the proposed algorithm was 0.87, compared to 0.71 to 0.8 for the other state-of-the-art methods.
Deep Learning Based Speech Beamforming
Feb 15, 2018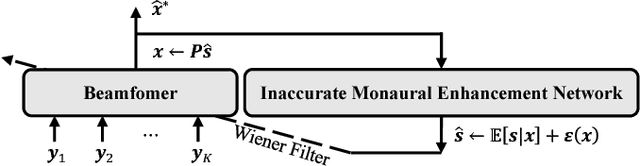
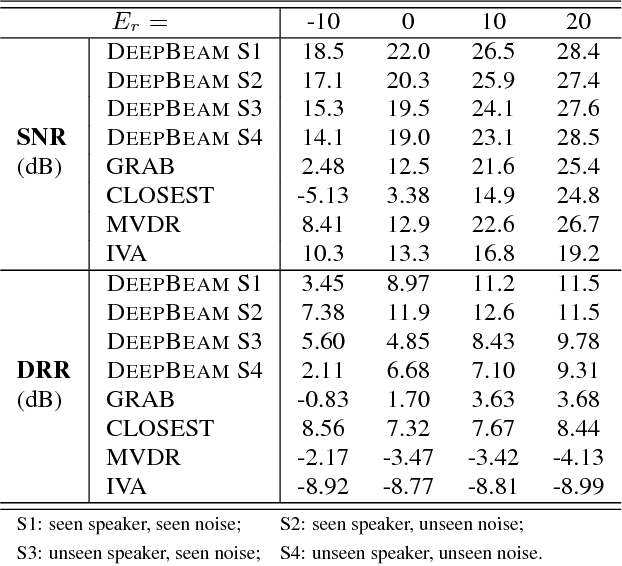
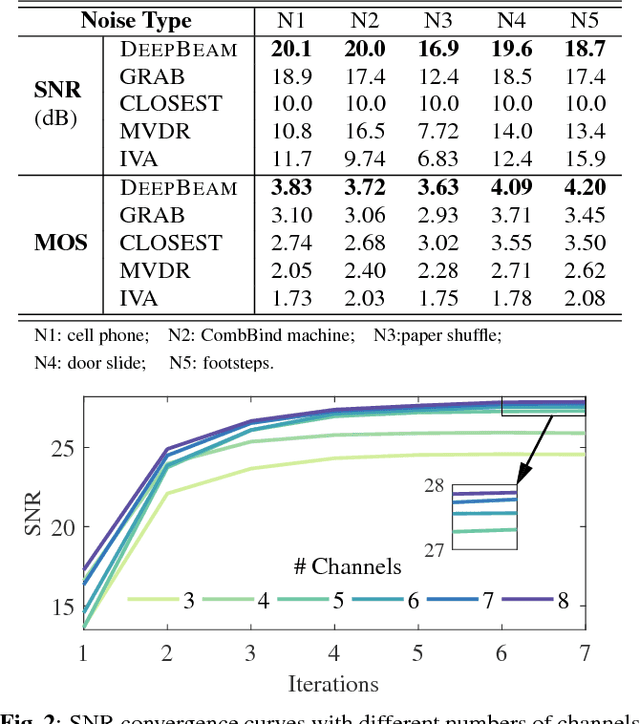
Multi-channel speech enhancement with ad-hoc sensors has been a challenging task. Speech model guided beamforming algorithms are able to recover natural sounding speech, but the speech models tend to be oversimplified or the inference would otherwise be too complicated. On the other hand, deep learning based enhancement approaches are able to learn complicated speech distributions and perform efficient inference, but they are unable to deal with variable number of input channels. Also, deep learning approaches introduce a lot of errors, particularly in the presence of unseen noise types and settings. We have therefore proposed an enhancement framework called DEEPBEAM, which combines the two complementary classes of algorithms. DEEPBEAM introduces a beamforming filter to produce natural sounding speech, but the filter coefficients are determined with the help of a monaural speech enhancement neural network. Experiments on synthetic and real-world data show that DEEPBEAM is able to produce clean, dry and natural sounding speech, and is robust against unseen noise.
Foreground Detection in Camouflaged Scenes
Jul 11, 2017
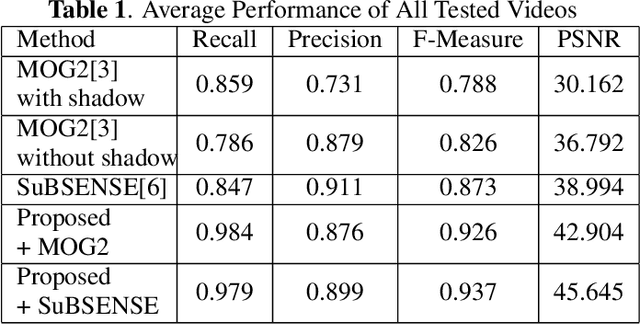

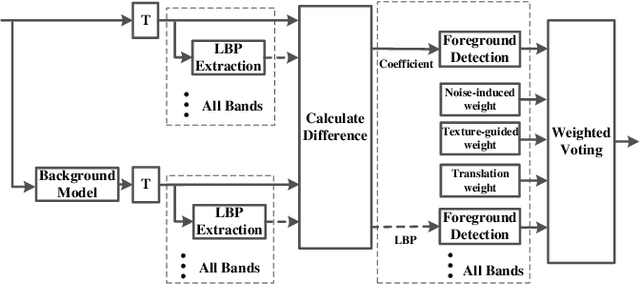
Foreground detection has been widely studied for decades due to its importance in many practical applications. Most of the existing methods assume foreground and background show visually distinct characteristics and thus the foreground can be detected once a good background model is obtained. However, there are many situations where this is not the case. Of particular interest in video surveillance is the camouflage case. For example, an active attacker camouflages by intentionally wearing clothes that are visually similar to the background. In such cases, even given a decent background model, it is not trivial to detect foreground objects. This paper proposes a texture guided weighted voting (TGWV) method which can efficiently detect foreground objects in camouflaged scenes. The proposed method employs the stationary wavelet transform to decompose the image into frequency bands. We show that the small and hardly noticeable differences between foreground and background in the image domain can be effectively captured in certain wavelet frequency bands. To make the final foreground decision, a weighted voting scheme is developed based on intensity and texture of all the wavelet bands with weights carefully designed. Experimental results demonstrate that the proposed method achieves superior performance compared to the current state-of-the-art results.
Joint Denoising / Compression of Image Contours via Shape Prior and Context Tree
Apr 30, 2017
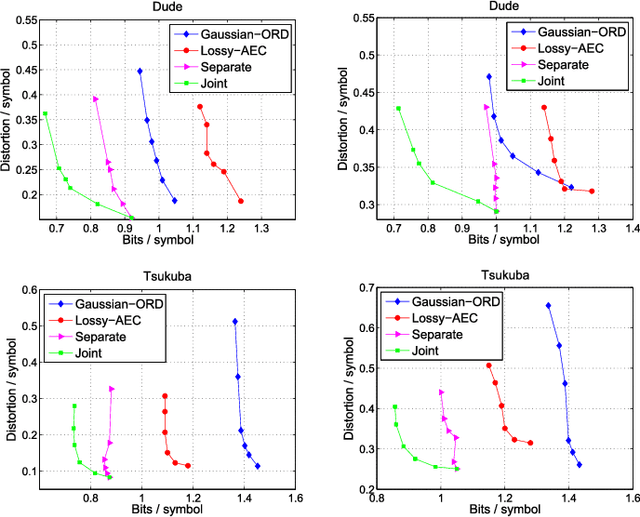
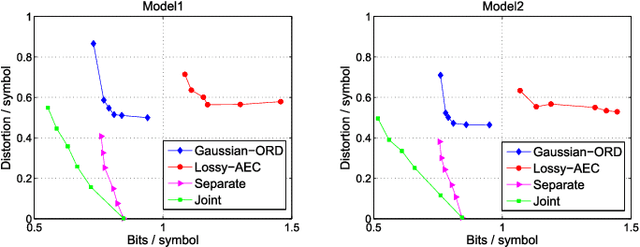
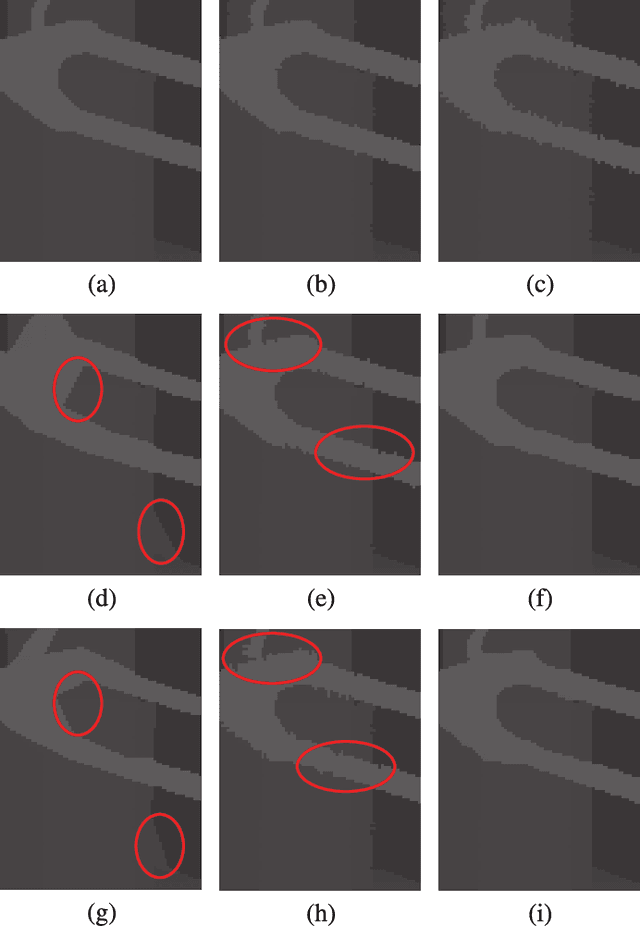
With the advent of depth sensing technologies, the extraction of object contours in images---a common and important pre-processing step for later higher-level computer vision tasks like object detection and human action recognition---has become easier. However, acquisition noise in captured depth images means that detected contours suffer from unavoidable errors. In this paper, we propose to jointly denoise and compress detected contours in an image for bandwidth-constrained transmission to a client, who can then carry out aforementioned application-specific tasks using the decoded contours as input. We first prove theoretically that in general a joint denoising / compression approach can outperform a separate two-stage approach that first denoises then encodes contours lossily. Adopting a joint approach, we first propose a burst error model that models typical errors encountered in an observed string y of directional edges. We then formulate a rate-constrained maximum a posteriori (MAP) problem that trades off the posterior probability p(x'|y) of an estimated string x' given y with its code rate R(x'). We design a dynamic programming (DP) algorithm that solves the posed problem optimally, and propose a compact context representation called total suffix tree (TST) that can reduce complexity of the algorithm dramatically. Experimental results show that our joint denoising / compression scheme outperformed a competing separate scheme in rate-distortion performance noticeably.
Precision Enhancement of 3D Surfaces from Multiple Compressed Depth Maps
Feb 25, 2014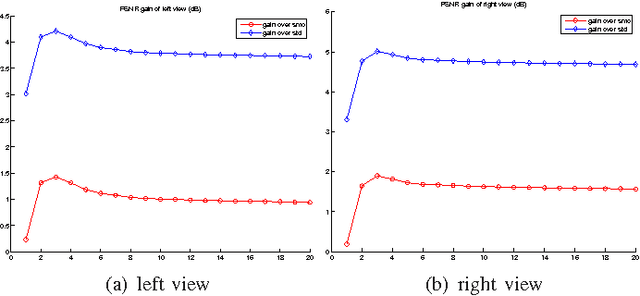
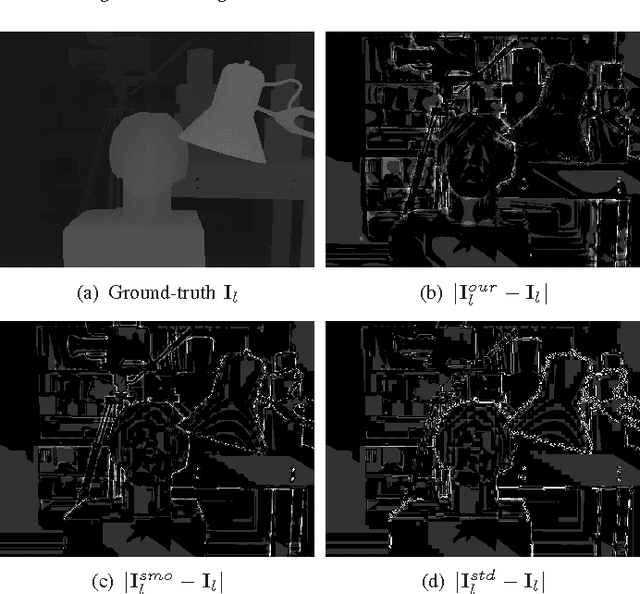
In texture-plus-depth representation of a 3D scene, depth maps from different camera viewpoints are typically lossily compressed via the classical transform coding / coefficient quantization paradigm. In this paper we propose to reduce distortion of the decoded depth maps due to quantization. The key observation is that depth maps from different viewpoints constitute multiple descriptions (MD) of the same 3D scene. Considering the MD jointly, we perform a POCS-like iterative procedure to project a reconstructed signal from one depth map to the other and back, so that the converged depth maps have higher precision than the original quantized versions.