 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Interpret and Tell: Entity-aware Contextualised Image Captioning in Wikipedia
Sep 21, 2022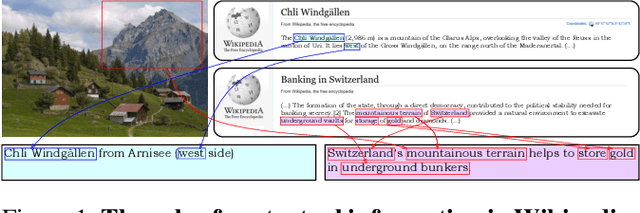
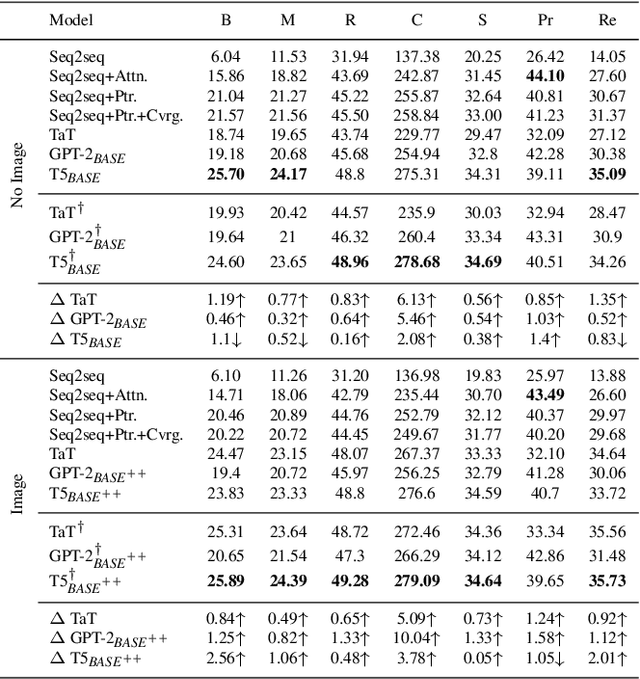
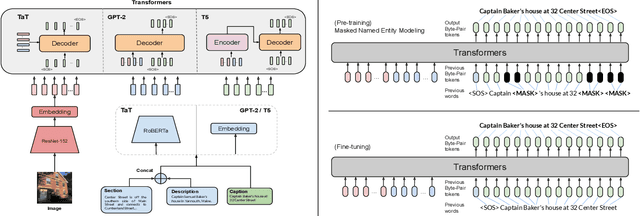
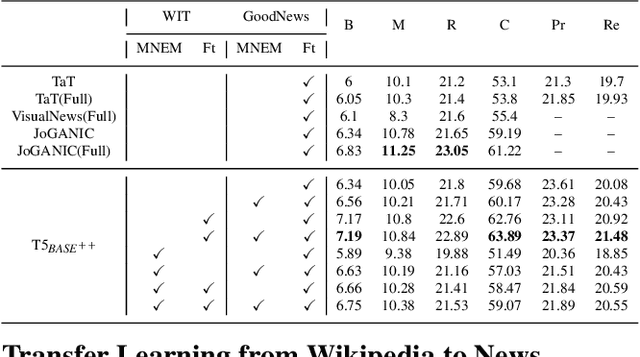
Humans exploit prior knowledge to describe images, and are able to adapt their explanation to specific contextual information, even to the extent of inventing plausible explanations when contextual information and images do not match. In this work, we propose the novel task of captioning Wikipedia images by integrating contextual knowledge. Specifically, we produce models that jointly reason over Wikipedia articles, Wikimedia images and their associated descriptions to produce contextualized captions. Particularly, a similar Wikimedia image can be used to illustrate different articles, and the produced caption needs to be adapted to a specific context, therefore allowing us to explore the limits of a model to adjust captions to different contextual information. A particular challenging task in this domain is dealing with out-of-dictionary words and Named Entities. To address this, we propose a pre-training objective, Masked Named Entity Modeling (MNEM), and show that this pretext task yields an improvement compared to baseline models. Furthermore, we verify that a model pre-trained with the MNEM objective in Wikipedia generalizes well to a News Captioning dataset. Additionally, we define two different test splits according to the difficulty of the captioning task. We offer insights on the role and the importance of each modality and highlight the limitations of our model. The code, models and data splits are publicly available at Upon acceptance.
MUST-VQA: MUltilingual Scene-text VQA
Sep 14, 2022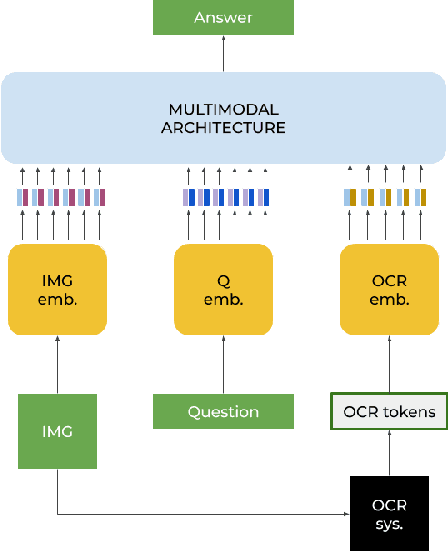
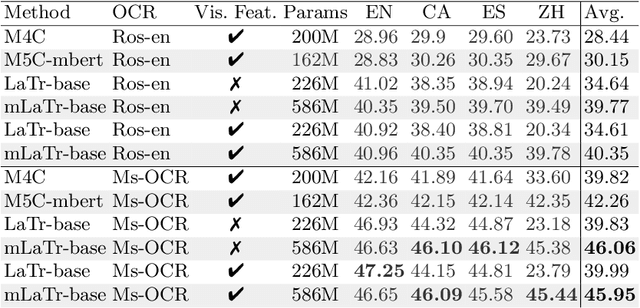
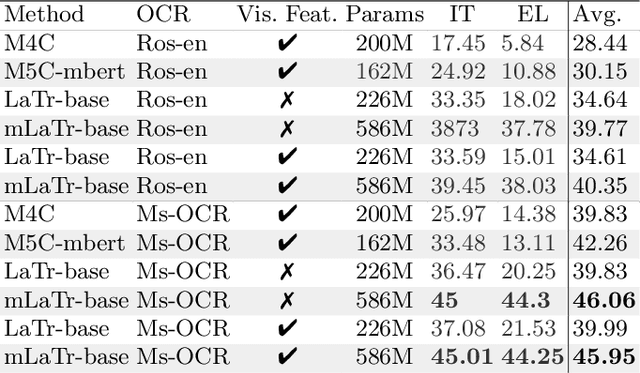
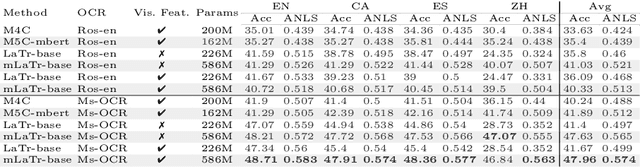
In this paper, we present a framework for Multilingual Scene Text Visual Question Answering that deals with new languages in a zero-shot fashion. Specifically, we consider the task of Scene Text Visual Question Answering (STVQA) in which the question can be asked in different languages and it is not necessarily aligned to the scene text language. Thus, we first introduce a natural step towards a more generalized version of STVQA: MUST-VQA. Accounting for this, we discuss two evaluation scenarios in the constrained setting, namely IID and zero-shot and we demonstrate that the models can perform on a par on a zero-shot setting. We further provide extensive experimentation and show the effectiveness of adapting multilingual language models into STVQA tasks.
Out-of-Vocabulary Challenge Report
Sep 14, 2022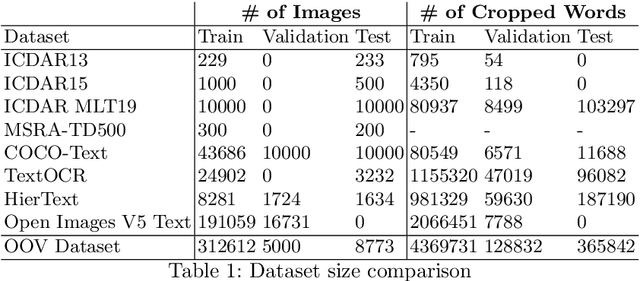

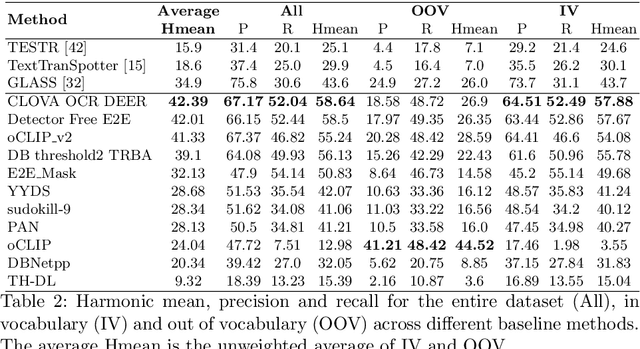
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.
Text-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Mar 16, 2022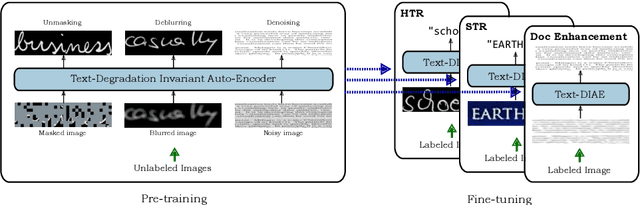
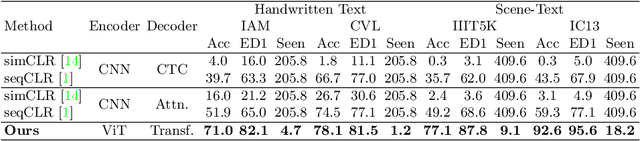
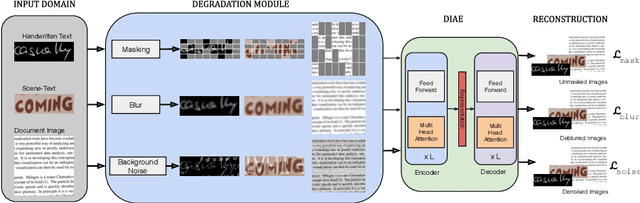
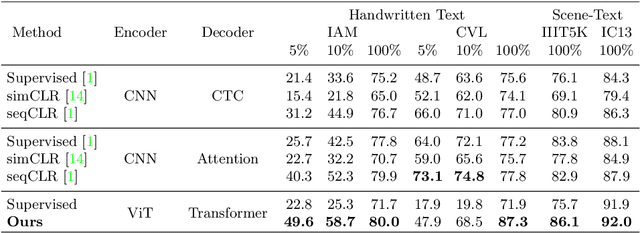
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.
OCR-IDL: OCR Annotations for Industry Document Library Dataset
Feb 25, 2022

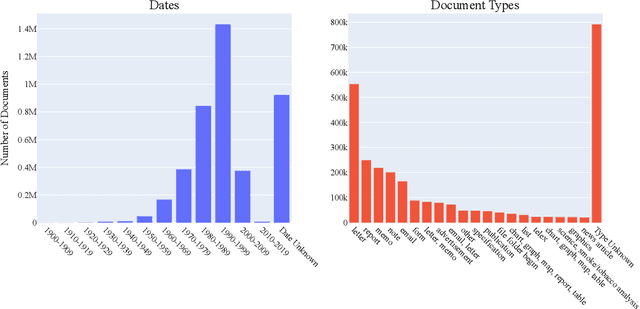
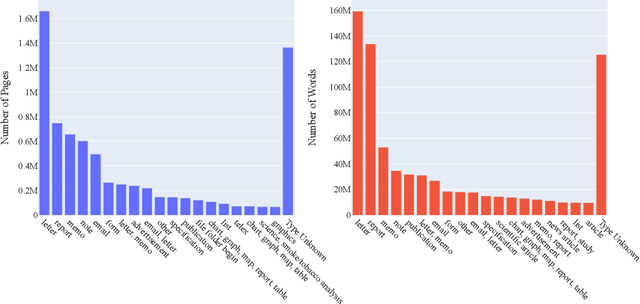
Pretraining has proven successful in Document Intelligence tasks where deluge of documents are used to pretrain the models only later to be finetuned on downstream tasks. One of the problems of the pretraining approaches is the inconsistent usage of pretraining data with different OCR engines leading to incomparable results between models. In other words, it is not obvious whether the performance gain is coming from diverse usage of amount of data and distinct OCR engines or from the proposed models. To remedy the problem, we make public the OCR annotations for IDL documents using commercial OCR engine given their superior performance over open source OCR models. The contributed dataset (OCR-IDL) has an estimated monetary value over 20K US$. It is our hope that OCR-IDL can be a starting point for future works on Document Intelligence. All of our data and its collection process with the annotations can be found in https://github.com/furkanbiten/idl_data.
ICDAR 2021 Competition on Document VisualQuestion Answering
Nov 10, 2021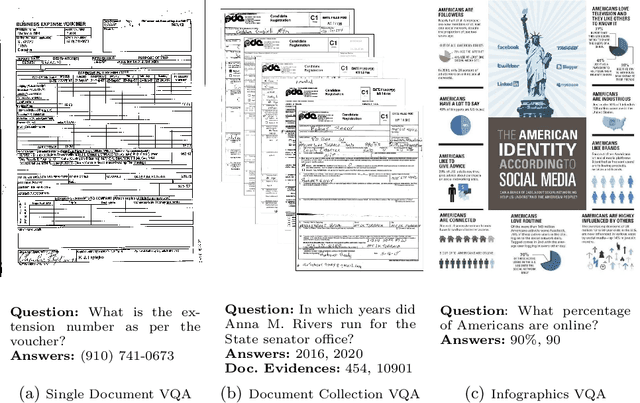
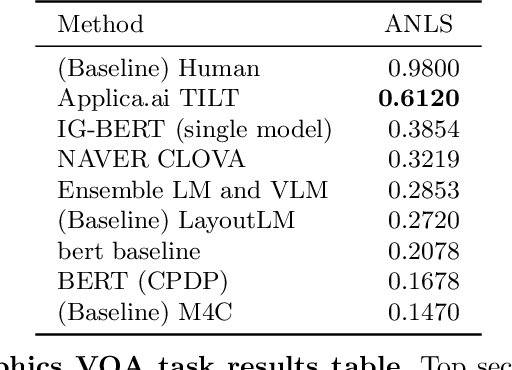
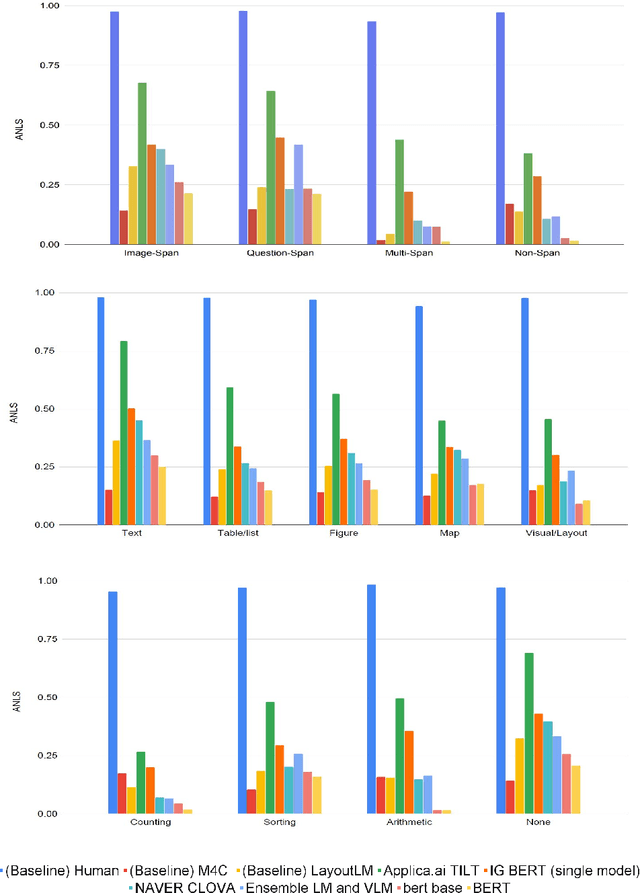
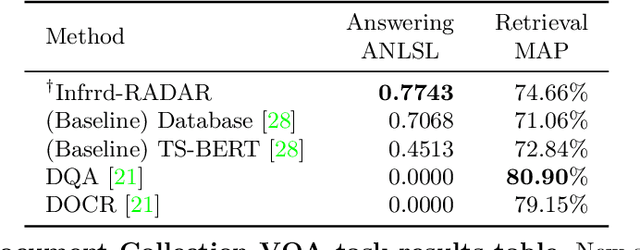
In this report we present results of the ICDAR 2021 edition of the Document Visual Question Challenges. This edition complements the previous tasks on Single Document VQA and Document Collection VQA with a newly introduced on Infographics VQA. Infographics VQA is based on a new dataset of more than 5,000 infographics images and 30,000 question-answer pairs. The winner methods have scored 0.6120 ANLS in Infographics VQA task, 0.7743 ANLSL in Document Collection VQA task and 0.8705 ANLS in Single Document VQA. We present a summary of the datasets used for each task, description of each of the submitted methods and the results and analysis of their performance. A summary of the progress made on Single Document VQA since the first edition of the DocVQA 2020 challenge is also presented.
Is An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Oct 06, 2021


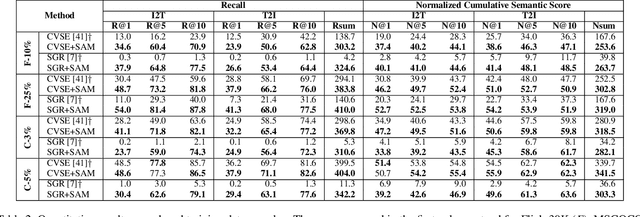
The task of image-text matching aims to map representations from different modalities into a common joint visual-textual embedding. However, the most widely used datasets for this task, MSCOCO and Flickr30K, are actually image captioning datasets that offer a very limited set of relationships between images and sentences in their ground-truth annotations. This limited ground truth information forces us to use evaluation metrics based on binary relevance: given a sentence query we consider only one image as relevant. However, many other relevant images or captions may be present in the dataset. In this work, we propose two metrics that evaluate the degree of semantic relevance of retrieved items, independently of their annotated binary relevance. Additionally, we incorporate a novel strategy that uses an image captioning metric, CIDEr, to define a Semantic Adaptive Margin (SAM) to be optimized in a standard triplet loss. By incorporating our formulation to existing models, a \emph{large} improvement is obtained in scenarios where available training data is limited. We also demonstrate that the performance on the annotated image-caption pairs is maintained while improving on other non-annotated relevant items when employing the full training set. Code with our metrics and adaptive margin formulation will be made public.
Let there be a clock on the beach: Reducing Object Hallucination in Image Captioning
Oct 04, 2021
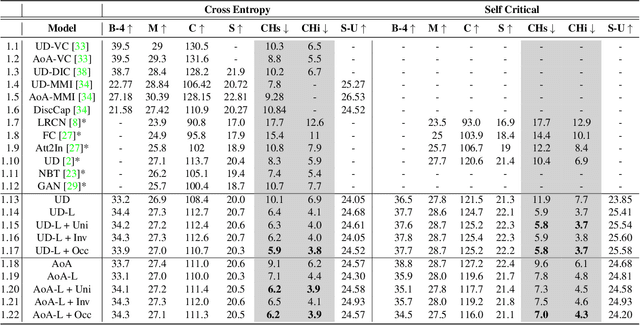
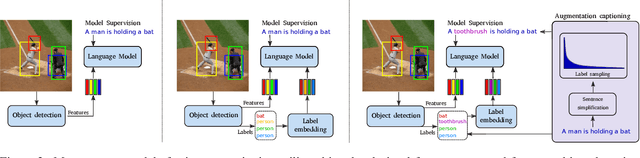

Explaining an image with missing or non-existent objects is known as object bias (hallucination) in image captioning. This behaviour is quite common in the state-of-the-art captioning models which is not desirable by humans. To decrease the object hallucination in captioning, we propose three simple yet efficient training augmentation method for sentences which requires no new training data or increase in the model size. By extensive analysis, we show that the proposed methods can significantly diminish our models' object bias on hallucination metrics. Moreover, we experimentally demonstrate that our methods decrease the dependency on the visual features. All of our code, configuration files and model weights will be made public.
Asking questions on handwritten document collections
Oct 02, 2021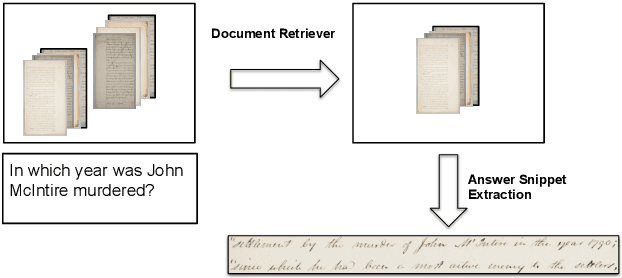

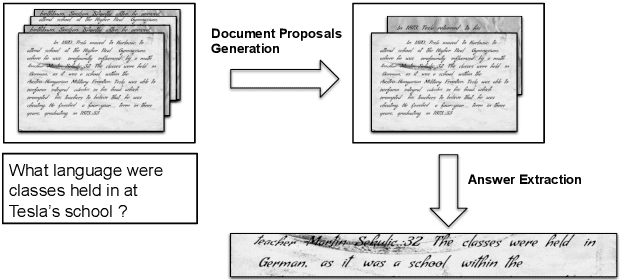

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
One-shot Compositional Data Generation for Low Resource Handwritten Text Recognition
May 11, 2021
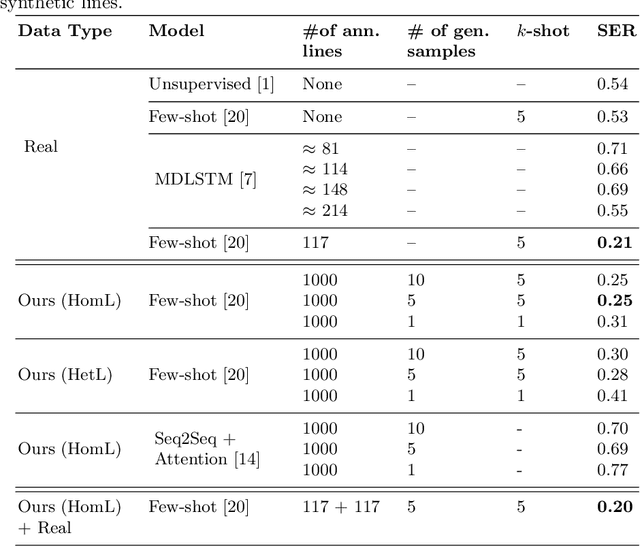
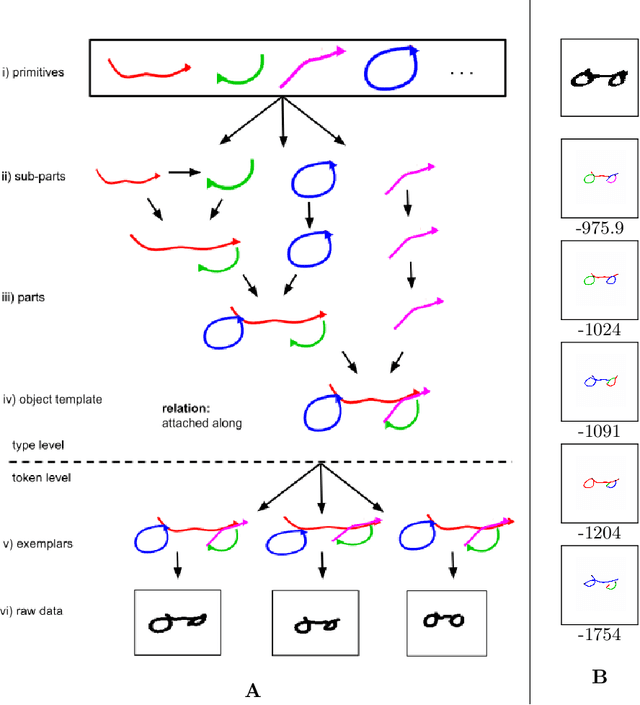

Low resource Handwritten Text Recognition (HTR) is a hard problem due to the scarce annotated data and the very limited linguistic information (dictionaries and language models). This appears, for example, in the case of historical ciphered manuscripts, which are usually written with invented alphabets to hide the content. Thus, in this paper we address this problem through a data generation technique based on Bayesian Program Learning (BPL). Contrary to traditional generation approaches, which require a huge amount of annotated images, our method is able to generate human-like handwriting using only one sample of each symbol from the desired alphabet. After generating symbols, we create synthetic lines to train state-of-the-art HTR architectures in a segmentation free fashion. Quantitative and qualitative analyses were carried out and confirm the effectiveness of the proposed method, achieving competitive results compared to the usage of real annotated data.