 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Prompt Generalization in Detecting AI-Generated Fake News Using Interpretable Linguistic Features
Jun 02, 2026The increasing use of large language models has raised concerns about the spread of AI-generated fake news, particularly under varying prompting strategies. Most existing detection models are trained and evaluated under a single generation setting, leaving their ability to generalize across unseen prompts unclear. In this study, we investigate cross-prompt generalization in fake news detection using three datasets of AI-generated articles produced under distinct prompts, combined with real news articles. We extract interpretable linguistic features capturing lexical diversity, readability, and emotion-based characteristics and evaluate a random forest classifier under a cross-prompt framework, where models trained on one prompt are tested on another. Across all six train-test combinations, performance remains consistently high, with AUC values ranging from 0.988 to 1.000. Analysis of feature distributions shows that AI-generated text exhibits increased lexical diversity, reduced readability, and substantially lower emotional intensity compared to the overall dataset, with variations across prompts. Despite these distributional shifts, the classifier maintains strong performance, indicating that these features capture stable properties of AI-generated text that generalize across prompting strategies. These findings suggest that feature-based approaches can provide robust detection of AI-generated fake news under prompt variability.
A Nonparametric Adaptive EWMA Control Chart for Binary Monitoring of Multiple Stream Processes
Apr 13, 2026Monitoring binomial proportions across multiple independent streams is a critical challenge in Statistical Process Control (SPC), with applications from manufacturing to cybersecurity. While EWMA charts offer sensitivity to small shifts, existing implementations rely on asymptotic variance approximations that fail during early-phase monitoring. We introduce a Cumulative Standardized Binomial EWMA (CSB-EWMA) chart that overcomes this limitation by deriving the exact time-varying variance of the EWMA statistic for binary multiple-stream data, enabling adaptive control limits that ensure statistical rigor from the first sample. Through extensive simulations, we identify optimal smoothing (λ) and limit (L) parameters to achieve target in-control average run length (ARL0) of 370 and 500. The CSB-EWMA chart demonstrates rapid shift detection across both ARL0 targets, with out-of-control average run length (ARL1) dropping to 3-7 samples for moderate shifts (δ=0.2), and exhibits exceptional robustness across different data distributions, with low ARL1 Coefficients of Variation (CV < 0.10 for small shifts) for both ARL0 = 370 and 500. This work provides practitioners with a distribution-free, sensitive, and theoretically sound tool for early change detection in binomial multiple-stream processes.
Human vs. Machine Deception: Distinguishing AI-Generated and Human-Written Fake News Using Ensemble Learning
Apr 10, 2026The rapid adoption of large language models has introduced a new class of AI-generated fake news that coexists with traditional human-written misinformation, raising important questions about how these two forms of deceptive content differ and how reliably they can be distinguished. This study examines linguistic, structural, and emotional differences between human-written and AI-generated fake news and evaluates machine learning and ensemble-based methods for distinguishing these content types. A document-level feature representation is constructed using sentence structure, lexical diversity, punctuation patterns, readability indices, and emotion-based features capturing affective dimensions such as fear, anger, joy, sadness, trust, and anticipation. Multiple classification models, including logistic regression, random forest, support vector machines, extreme gradient boosting, and a neural network, are applied alongside an ensemble framework that aggregates predictions across models. Model performance is assessed using accuracy and area under the receiver operating characteristic curve. The results show strong and consistent classification performance, with readability-based features emerging as the most informative predictors and AI-generated text exhibiting more uniform stylistic patterns. Ensemble learning provides modest but consistent improvements over individual models. These findings indicate that stylistic and structural properties of text provide a robust basis for distinguishing AI-generated misinformation from human-written fake news.
Integrating Causal Inference with Graph Neural Networks for Alzheimer's Disease Analysis
Nov 18, 2025Deep graph learning has advanced Alzheimer's (AD) disease classification from MRI, but most models remain correlational, confounding demographic and genetic factors with disease specific features. We present Causal-GCN, an interventional graph convolutional framework that integrates do-calculus-based back-door adjustment to identify brain regions exerting stable causal influence on AD progression. Each subject's MRI is represented as a structural connectome where nodes denote cortical and subcortical regions and edges encode anatomical connectivity. Confounders such as age, sec, and APOE4 genotype are summarized via principal components and included in the causal adjustment set. After training, interventions on individual regions are simulated by serving their incoming edges and altering node features to estimate average causal effects on disease probability. Applied to 484 subjects from the ADNI cohort, Causal-GCN achieves performance comparable to baseline GNNs while providing interpretable causal effect rankings that highlight posterior, cingulate, and insular hubs consistent with established AD neuropathology.
Ensemble Survival Analysis for Preclinical Cognitive Decline Prediction in Alzheimer's Disease Using Longitudinal Biomarkers
Mar 20, 2025Predicting the risk of clinical progression from cognitively normal (CN) status to mild cognitive impairment (MCI) or Alzheimer's disease (AD) is critical for early intervention in Alzheimer's disease (AD). Traditional survival models often fail to capture complex longitudinal biomarker patterns associated with disease progression. We propose an ensemble survival analysis framework integrating multiple survival models to improve early prediction of clinical progression in initially cognitively normal individuals. We analyzed longitudinal biomarker data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, including 721 participants, limiting analysis to up to three visits (baseline, 6-month follow-up, 12-month follow-up). Of these, 142 (19.7%) experienced clinical progression to MCI or AD. Our approach combined penalized Cox regression (LASSO, Elastic Net) with advanced survival models (Random Survival Forest, DeepSurv, XGBoost). Model predictions were aggregated using ensemble averaging and Bayesian Model Averaging (BMA). Predictive performance was assessed using Harrell's concordance index (C-index) and time-dependent area under the curve (AUC). The ensemble model achieved a peak C-index of 0.907 and an integrated time-dependent AUC of 0.904, outperforming baseline-only models (C-index 0.608). One follow-up visit after baseline significantly improved prediction accuracy (48.1% C-index, 48.2% AUC gains), while adding a second follow-up provided only marginal gains (2.1% C-index, 2.7% AUC). Our ensemble survival framework effectively integrates diverse survival models and aggregation techniques to enhance early prediction of preclinical AD progression. These findings highlight the importance of leveraging longitudinal biomarker data, particularly one follow-up visit, for accurate risk stratification and personalized intervention strategies.
XCAT-2.0: A Comprehensive Library of Personalized Digital Twins Derived from CT Scans
May 18, 2024



Virtual Imaging Trials (VIT) offer a cost-effective and scalable approach for evaluating medical imaging technologies. Computational phantoms, which mimic real patient anatomy and physiology, play a central role in VIT. However, the current libraries of computational phantoms face limitations, particularly in terms of sample size and diversity. Insufficient representation of the population hampers accurate assessment of imaging technologies across different patient groups. Traditionally, phantoms were created by manual segmentation, which is a laborious and time-consuming task, impeding the expansion of phantom libraries. This study presents a framework for realistic computational phantom modeling using a suite of four deep learning segmentation models, followed by three forms of automated organ segmentation quality control. Over 2500 computational phantoms with up to 140 structures illustrating a sophisticated approach to detailed anatomical modeling are released. Phantoms are available in both voxelized and surface mesh formats. The framework is aggregated with an in-house CT scanner simulator to produce realistic CT images. The framework can potentially advance virtual imaging trials, facilitating comprehensive and reliable evaluations of medical imaging technologies. Phantoms may be requested at https://cvit.duke.edu/resources/, code, model weights, and sample CT images are available at https://xcat-2.github.io.
VLST: Virtual Lung Screening Trial for Lung Cancer Detection Using Virtual Imaging Trial
Apr 17, 2024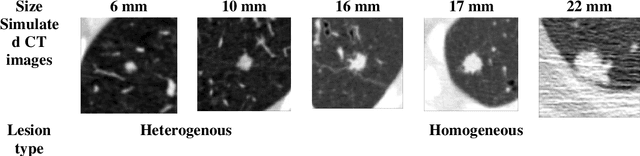

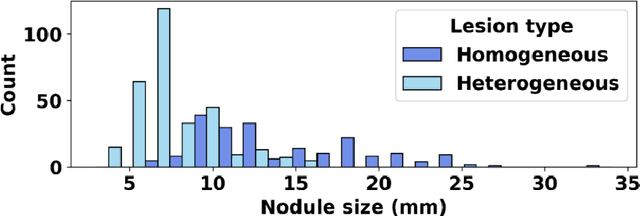
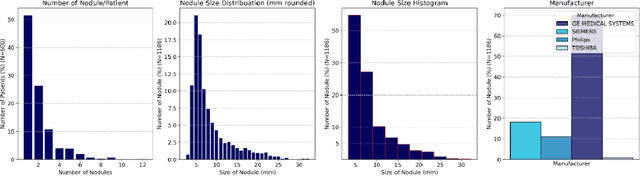
Importance: The efficacy of lung cancer screening can be significantly impacted by the imaging modality used. This Virtual Lung Screening Trial (VLST) addresses the critical need for precision in lung cancer diagnostics and the potential for reducing unnecessary radiation exposure in clinical settings. Objectives: To establish a virtual imaging trial (VIT) platform that accurately simulates real-world lung screening trials (LSTs) to assess the diagnostic accuracy of CT and CXR modalities. Design, Setting, and Participants: Utilizing computational models and machine learning algorithms, we created a diverse virtual patient population. The cohort, designed to mirror real-world demographics, was assessed using virtual imaging techniques that reflect historical imaging technologies. Main Outcomes and Measures: The primary outcome was the difference in the Area Under the Curve (AUC) for CT and CXR modalities across lesion types and sizes. Results: The study analyzed 298 CT and 313 CXR simulated images from 313 virtual patients, with a lesion-level AUC of 0.81 (95% CI: 0.78-0.84) for CT and 0.55 (95% CI: 0.53-0.56) for CXR. At the patient level, CT demonstrated an AUC of 0.85 (95% CI: 0.80-0.89), compared to 0.53 (95% CI: 0.47-0.60) for CXR. Subgroup analyses indicated CT's superior performance in detecting homogeneous lesions (AUC of 0.97 for lesion-level) and heterogeneous lesions (AUC of 0.71 for lesion-level) as well as in identifying larger nodules (AUC of 0.98 for nodules > 8 mm). Conclusion and Relevance: The VIT platform validated the superior diagnostic accuracy of CT over CXR, especially for smaller nodules, underscoring its potential to replicate real clinical imaging trials. These findings advocate for the integration of virtual trials in the evaluation and improvement of imaging-based diagnostic tools.
Prism: Private Verifiable Set Computation over Multi-Owner Outsourced Databases
Apr 07, 2021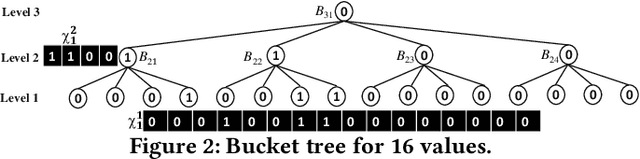

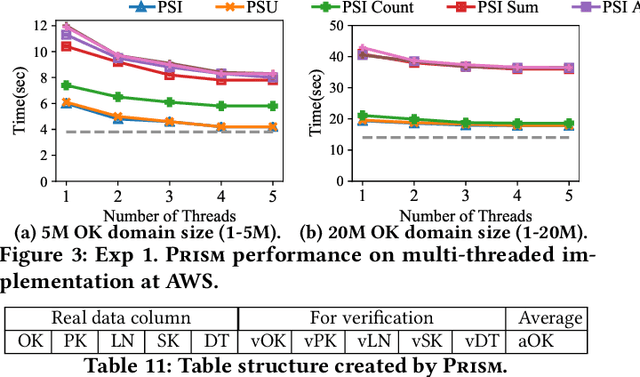

This paper proposes Prism, a secret sharing based approach to compute private set operations (i.e., intersection and union), as well as aggregates over outsourced databases belonging to multiple owners. Prism enables data owners to pre-load the data onto non-colluding servers and exploits the additive and multiplicative properties of secret-shares to compute the above-listed operations in (at most) two rounds of communication between the servers (storing the secret-shares) and the querier, resulting in a very efficient implementation. Also, Prism does not require communication among the servers and supports result verification techniques for each operation to detect malicious adversaries. Experimental results show that Prism scales both in terms of the number of data owners and database sizes, to which prior approaches do not scale.