 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Prompting for Multimodal Machine Translation
Jul 23, 2025Multimodal Machine Translation (MMT) typically enhances text-only translation by incorporating aligned visual features. Despite the remarkable progress, state-of-the-art MMT approaches often rely on paired image-text inputs at inference and are sensitive to irrelevant visual noise, which limits their robustness and practical applicability. To address these issues, we propose D2P-MMT, a diffusion-based dual-branch prompting framework for robust vision-guided translation. Specifically, D2P-MMT requires only the source text and a reconstructed image generated by a pre-trained diffusion model, which naturally filters out distracting visual details while preserving semantic cues. During training, the model jointly learns from both authentic and reconstructed images using a dual-branch prompting strategy, encouraging rich cross-modal interactions. To bridge the modality gap and mitigate training-inference discrepancies, we introduce a distributional alignment loss that enforces consistency between the output distributions of the two branches. Extensive experiments on the Multi30K dataset demonstrate that D2P-MMT achieves superior translation performance compared to existing state-of-the-art approaches.
Fairness and Accuracy in Federated Learning
Dec 18, 2020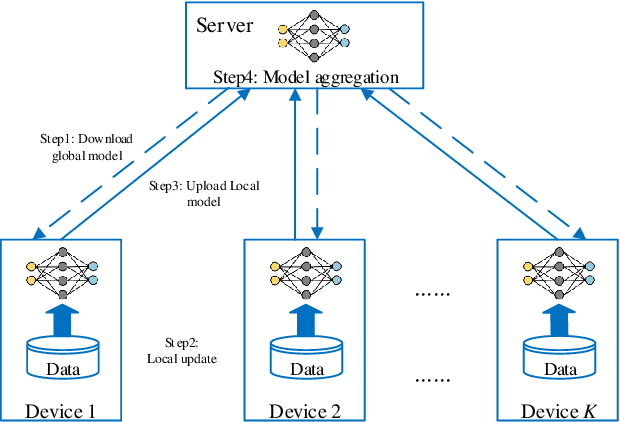
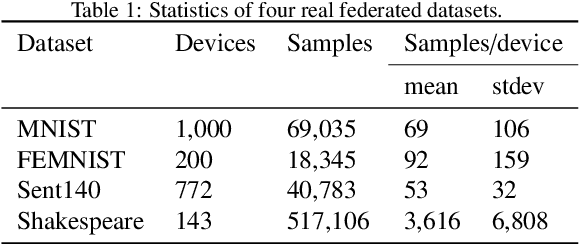
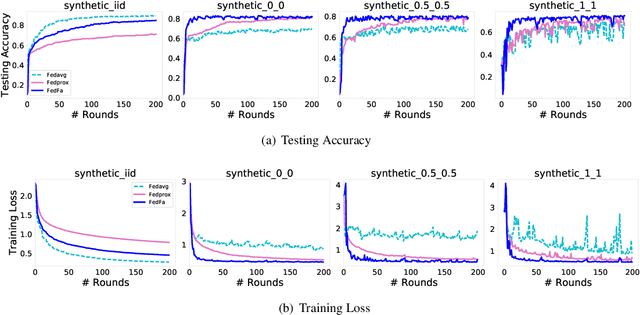
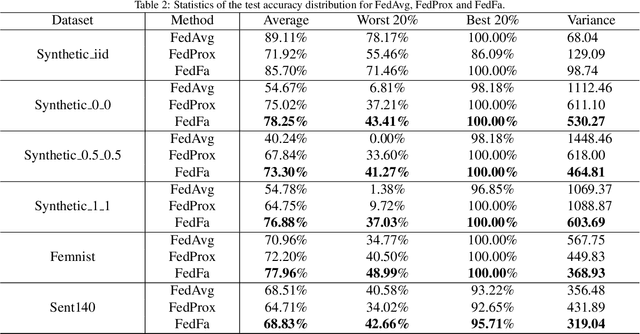
In the federated learning setting, multiple clients jointly train a model under the coordination of the central server, while the training data is kept on the client to ensure privacy. Normally, inconsistent distribution of data across different devices in a federated network and limited communication bandwidth between end devices impose both statistical heterogeneity and expensive communication as major challenges for federated learning. This paper proposes an algorithm to achieve more fairness and accuracy in federated learning (FedFa). It introduces an optimization scheme that employs a double momentum gradient, thereby accelerating the convergence rate of the model. An appropriate weight selection algorithm that combines the information quantity of training accuracy and training frequency to measure the weights is proposed. This procedure assists in addressing the issue of unfairness in federated learning due to preferences for certain clients. Our results show that the proposed FedFa algorithm outperforms the baseline algorithm in terms of accuracy and fairness.