 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Continuous Pairwise Markov Random Fields
Oct 28, 2020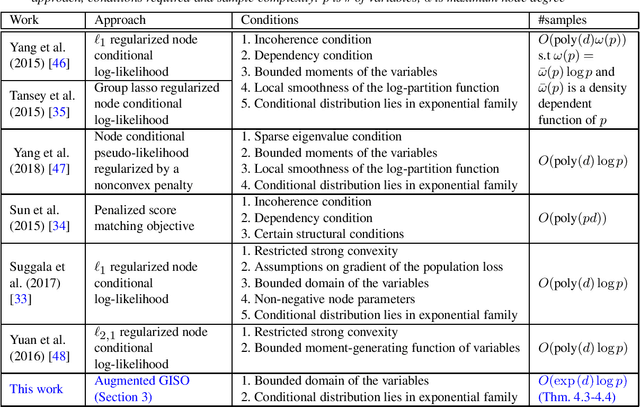
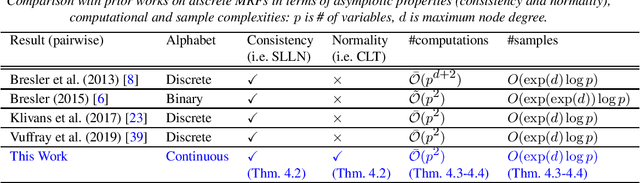
We consider learning a sparse pairwise Markov Random Field (MRF) with continuous-valued variables from i.i.d samples. We adapt the algorithm of Vuffray et al. (2019) to this setting and provide finite-sample analysis revealing sample complexity scaling logarithmically with the number of variables, as in the discrete and Gaussian settings. Our approach is applicable to a large class of pairwise MRFs with continuous variables and also has desirable asymptotic properties, including consistency and normality under mild conditions. Further, we establish that the population version of the optimization criterion employed in Vuffray et al. (2019) can be interpreted as local maximum likelihood estimation (MLE). As part of our analysis, we introduce a robust variation of sparse linear regression a` la Lasso, which may be of interest in its own right.
On Principal Component Regression in a High-Dimensional Error-in-Variables Setting
Oct 27, 2020
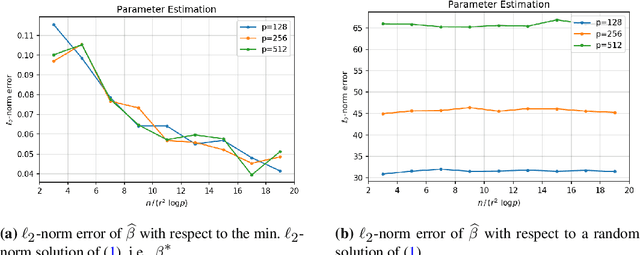
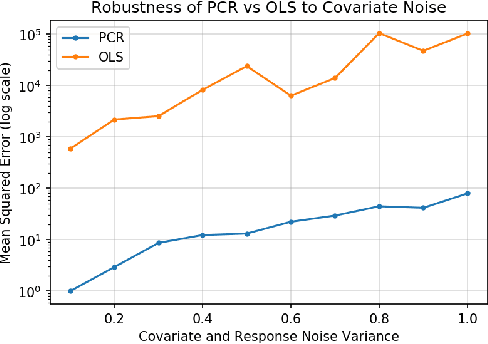
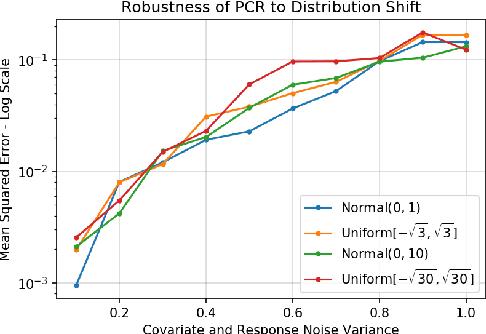
We analyze the classical method of Principal Component Regression (PCR) in the high-dimensional error-in-variables setting. Here, the observed covariates are not only noisy and contain missing data, but the number of covariates can also exceed the sample size. Under suitable conditions, we establish that PCR identifies the unique model parameter with minimum $\ell_2$-norm, and derive non-asymptotic $\ell_2$-rates of convergence that show its consistency. We further provide non-asymptotic out-of-sample prediction performance guarantees that again prove consistency, even in the presence of corrupted unseen data. Notably, our results do not require the out-of-samples covariates to follow the same distribution as that of the in-sample covariates, but rather that they obey a simple linear algebraic constraint. We finish by presenting simulations that illustrate our theoretical results.
On Multivariate Singular Spectrum Analysis
Jun 24, 2020
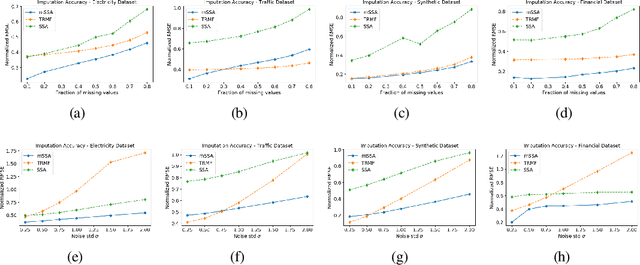
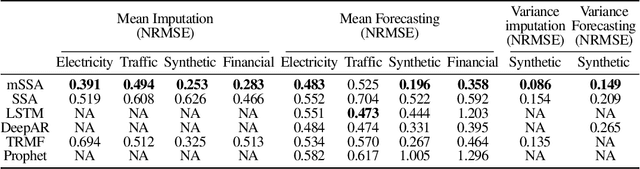
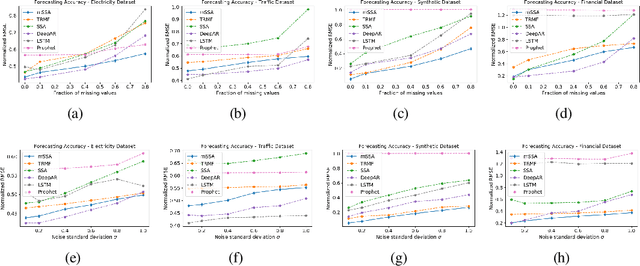
We analyze a variant of multivariate singular spectrum analysis (mSSA), a widely used multivariate time series method, which we find to perform competitively with respect to the state-of-art neural network time series methods (LSTM, DeepAR). Its restriction for single time series, singular spectrum analysis (SSA), has been analyzed recently. Despite its popularity, theoretical understanding of mSSA is absent. Towards this, we introduce a natural spatio-temporal factor model to analyze mSSA. We establish the in-sample prediction error for imputation and forecasting under mSSA scales as $1/\sqrt{NT}$, for $N$ time series with $T$ observations per time series. In contrast, for SSA the error scales as $1/\sqrt{T}$ and for matrix factorization based time series methods, the error scales as ${1}/{\min(N, T)}$. We utilize an online learning framework to analyze the one-step-ahead prediction error of mSSA and establish it has a regret of ${1}/{(\sqrt{N}T^{0.04})}$ with respect to in-sample forecasting error. By applying mSSA on the square of the time series observations, we furnish an algorithm to estimate the time-varying variance of a time series and establish it has in-sample imputation / forecasting error scaling as $1/\sqrt{NT}$. To establish our results, we make three technical contributions. First, we establish that the "stacked" Page Matrix time series representation, the core data structure in mSSA, has an approximate low-rank structure for a large class of time series models used in practice under the spatio-temporal factor model. Second, we extend the theory of online convex optimization to address the variant when the constraints are time-varying. Third, we extend the analysis prediction error analysis of Principle Component Regression beyond recent work to when the covariate matrix is approximately low-rank.
Estimation of Skill Distributions
Jun 15, 2020
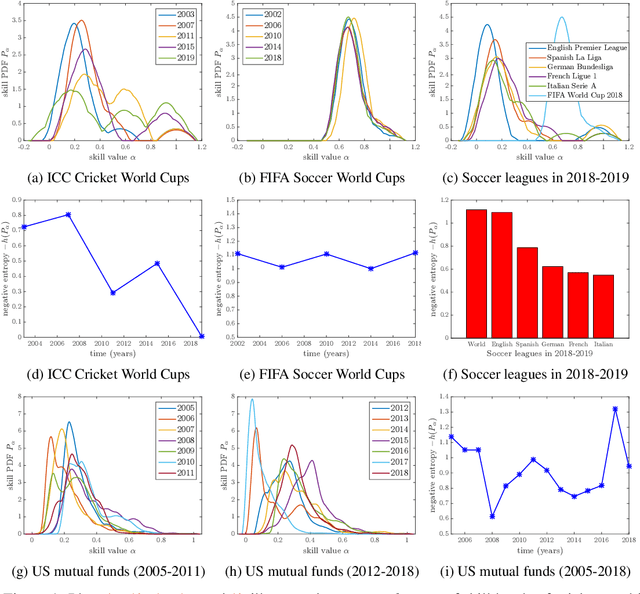
In this paper, we study the problem of learning the skill distribution of a population of agents from observations of pairwise games in a tournament. These games are played among randomly drawn agents from the population. The agents in our model can be individuals, sports teams, or Wall Street fund managers. Formally, we postulate that the likelihoods of game outcomes are governed by the Bradley-Terry-Luce (or multinomial logit) model, where the probability of an agent beating another is the ratio between its skill level and the pairwise sum of skill levels, and the skill parameters are drawn from an unknown skill density of interest. The problem is, in essence, to learn a distribution from noisy, quantized observations. We propose a simple and tractable algorithm that learns the skill density with near-optimal minimax mean squared error scaling as $n^{-1+\varepsilon}$, for any $\varepsilon>0$, when the density is smooth. Our approach brings together prior work on learning skill parameters from pairwise comparisons with kernel density estimation from non-parametric statistics. Furthermore, we prove minimax lower bounds which establish minimax optimality of the skill parameter estimation technique used in our algorithm. These bounds utilize a continuum version of Fano's method along with a covering argument. We apply our algorithm to various soccer leagues and world cups, cricket world cups, and mutual funds. We find that the entropy of a learnt distribution provides a quantitative measure of skill, which provides rigorous explanations for popular beliefs about perceived qualities of sporting events, e.g., soccer league rankings. Finally, we apply our method to assess the skill distributions of mutual funds. Our results shed light on the abundance of low quality funds prior to the Great Recession of 2008, and the domination of the industry by more skilled funds after the financial crisis.
Synthetic Interventions
Jun 13, 2020
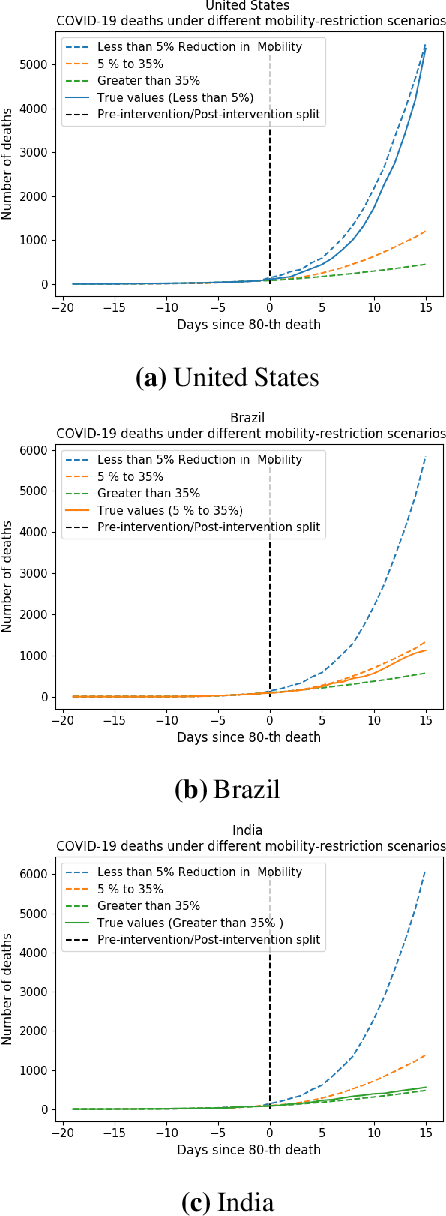

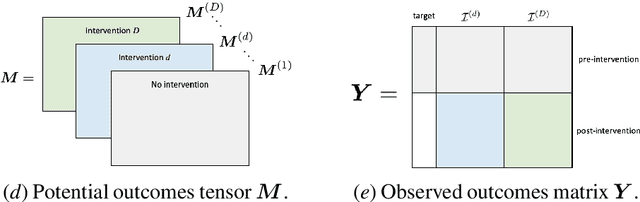
We develop a method to help quantify the impact different levels of mobility restrictions could have had on COVID-19 related deaths across nations. Synthetic control (SC) has emerged as a standard tool in such scenarios to produce counterfactual estimates if a particular intervention had not occurred, using just observational data. However, it remains an important open problem of how to extend SC to obtain counterfactual estimates if a particular intervention had occurred - this is exactly the question of the impact of mobility restrictions stated above. As our main contribution, we introduce synthetic interventions (SI), which helps resolve this open problem by allowing one to produce counterfactual estimates if there are multiple interventions of interest. We prove SI produces consistent counterfactual estimates under a tensor factor model. Our finite sample analysis shows the test error decays as $1/T_0$, where $T_0$ is the amount of observed pre-intervention data. As a special case, this improves upon the $1/\sqrt{T_0}$ bound on test error for SC in prior works. Our test error bound holds under a certain "subspace inclusion" condition; we furnish a data-driven hypothesis test with provable guarantees to check for this condition. This also provides a quantitative hypothesis test for when to use SC, currently absent in the literature. Technically, we establish the parameter estimation and test error for Principal Component Regression (a key subroutine in SI and several SC variants) under the setting of error-in-variable regression decays as $1/T_0$, where $T_0$ is the number of samples observed; this improves the best prior test error bound of $1/\sqrt{T_0}$. In addition to the COVID-19 case study, we show how SI can be used to run data-efficient, personalized randomized control trials using real data from a large e-commerce website and a large developmental economics study.
Sample Efficient Reinforcement Learning via Low-Rank Matrix Estimation
Jun 11, 2020


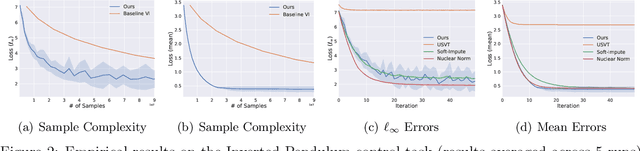
We consider the question of learning $Q$-function in a sample efficient manner for reinforcement learning with continuous state and action spaces under a generative model. If $Q$-function is Lipschitz continuous, then the minimal sample complexity for estimating $\epsilon$-optimal $Q$-function is known to scale as ${\Omega}(\frac{1}{\epsilon^{d_1+d_2 +2}})$ per classical non-parametric learning theory, where $d_1$ and $d_2$ denote the dimensions of the state and action spaces respectively. The $Q$-function, when viewed as a kernel, induces a Hilbert-Schmidt operator and hence possesses square-summable spectrum. This motivates us to consider a parametric class of $Q$-functions parameterized by its "rank" $r$, which contains all Lipschitz $Q$-functions as $r \to \infty$. As our key contribution, we develop a simple, iterative learning algorithm that finds $\epsilon$-optimal $Q$-function with sample complexity of $\widetilde{O}(\frac{1}{\epsilon^{\max(d_1, d_2)+2}})$ when the optimal $Q$-function has low rank $r$ and the discounting factor $\gamma$ is below a certain threshold. Thus, this provides an exponential improvement in sample complexity. To enable our result, we develop a novel Matrix Estimation algorithm that faithfully estimates an unknown low-rank matrix in the $\ell_\infty$ sense even in the presence of arbitrary bounded noise, which might be of interest in its own right. Empirical results on several stochastic control tasks confirm the efficacy of our "low-rank" algorithms.
Stable Reinforcement Learning with Unbounded State Space
Jun 08, 2020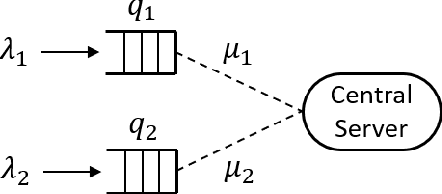

We consider the problem of reinforcement learning (RL) with unbounded state space motivated by the classical problem of scheduling in a queueing network. Traditional policies as well as error metric that are designed for finite, bounded or compact state space, require infinite samples for providing any meaningful performance guarantee (e.g. $\ell_\infty$ error) for unbounded state space. That is, we need a new notion of performance metric. As the main contribution of this work, inspired by the literature in queuing systems and control theory, we propose stability as the notion of "goodness": the state dynamics under the policy should remain in a bounded region with high probability. As a proof of concept, we propose an RL policy using Sparse-Sampling-based Monte Carlo Oracle and argue that it satisfies the stability property as long as the system dynamics under the optimal policy respects a Lyapunov function. The assumption of existence of a Lyapunov function is not restrictive as it is equivalent to the positive recurrence or stability property of any Markov chain, i.e., if there is any policy that can stabilize the system then it must possess a Lyapunov function. And, our policy does not utilize the knowledge of the specific Lyapunov function. To make our method sample efficient, we provide an improved, sample efficient Sparse-Sampling-based Monte Carlo Oracle with Lipschitz value function that may be of interest in its own right. Furthermore, we design an adaptive version of the algorithm, based on carefully constructed statistical tests, which finds the correct tuning parameter automatically.
Two Burning Questions on COVID-19: Did shutting down the economy help? Can we reopen the economy without risking the second wave?
May 10, 2020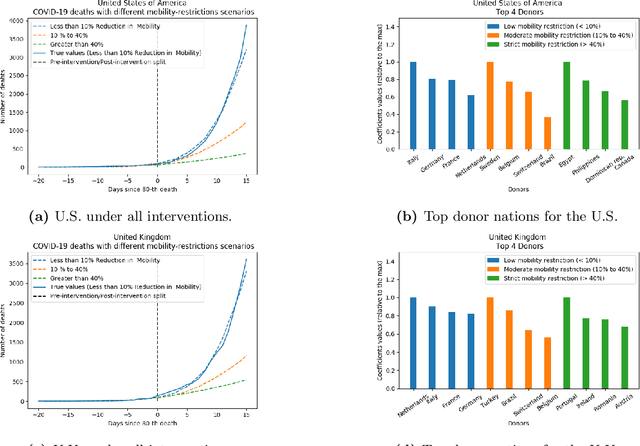
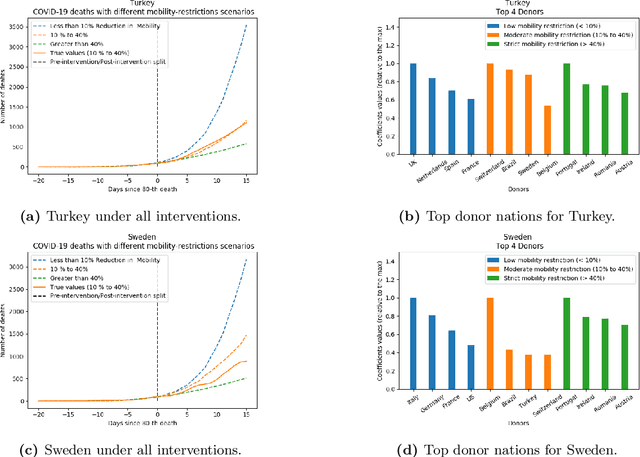

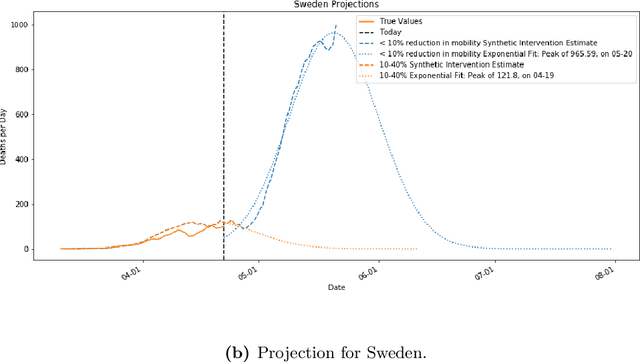
As we reach the apex of the COVID-19 pandemic, the most pressing question facing us is: can we even partially reopen the economy without risking a second wave? We first need to understand if shutting down the economy helped. And if it did, is it possible to achieve similar gains in the war against the pandemic while partially opening up the economy? To do so, it is critical to understand the effects of the various interventions that can be put into place and their corresponding health and economic implications. Since many interventions exist, the key challenge facing policy makers is understanding the potential trade-offs between them, and choosing the particular set of interventions that works best for their circumstance. In this memo, we provide an overview of Synthetic Interventions (a natural generalization of Synthetic Control), a data-driven and statistically principled method to perform what-if scenario planning, i.e., for policy makers to understand the trade-offs between different interventions before having to actually enact them. In essence, the method leverages information from different interventions that have already been enacted across the world and fits it to a policy maker's setting of interest, e.g., to estimate the effect of mobility-restricting interventions on the U.S., we use daily death data from countries that enforced severe mobility restrictions to create a "synthetic low mobility U.S." and predict the counterfactual trajectory of the U.S. if it had indeed applied a similar intervention. Using Synthetic Interventions, we find that lifting severe mobility restrictions and only retaining moderate mobility restrictions (at retail and transit locations), seems to effectively flatten the curve. We hope this provides guidance on weighing the trade-offs between the safety of the population, strain on the healthcare system, and impact on the economy.
On Reinforcement Learning for Turn-based Zero-sum Markov Games
Feb 25, 2020
We consider the problem of finding Nash equilibrium for two-player turn-based zero-sum games. Inspired by the AlphaGo Zero (AGZ) algorithm, we develop a Reinforcement Learning based approach. Specifically, we propose Explore-Improve-Supervise (EIS) method that combines "exploration", "policy improvement"' and "supervised learning" to find the value function and policy associated with Nash equilibrium. We identify sufficient conditions for convergence and correctness for such an approach. For a concrete instance of EIS where random policy is used for "exploration", Monte-Carlo Tree Search is used for "policy improvement" and Nearest Neighbors is used for "supervised learning", we establish that this method finds an $\varepsilon$-approximate value function of Nash equilibrium in $\widetilde{O}(\varepsilon^{-(d+4)})$ steps when the underlying state-space of the game is continuous and $d$-dimensional. This is nearly optimal as we establish a lower bound of $\widetilde{\Omega}(\varepsilon^{-(d+2)})$ for any policy.
Short and Wide Network Paths
Nov 01, 2019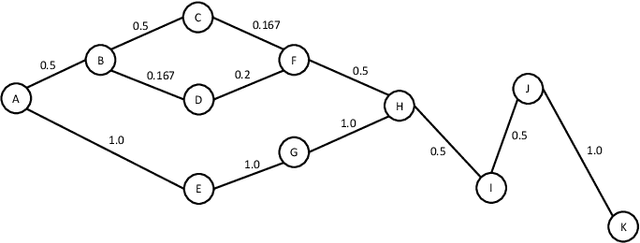
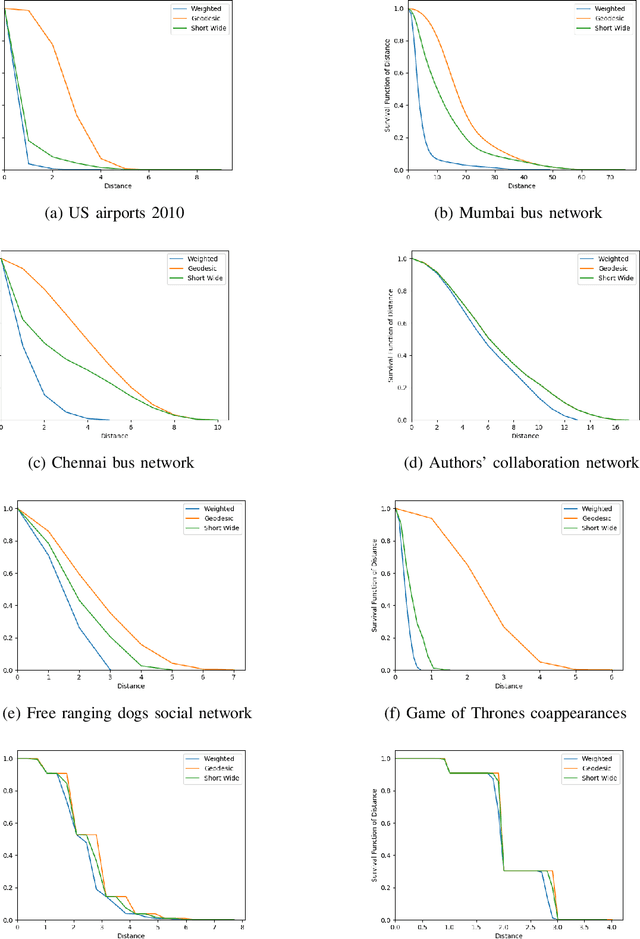
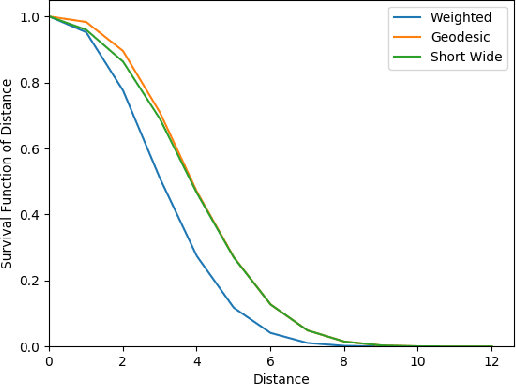
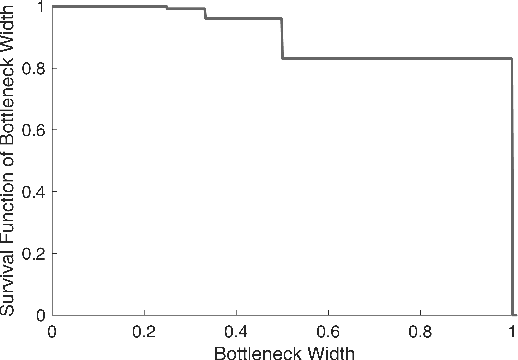
Network flow is a powerful mathematical framework to systematically explore the relationship between structure and function in biological, social, and technological networks. We introduce a new pipelining model of flow through networks where commodities must be transported over single paths rather than split over several paths and recombined. We show this notion of pipelined network flow is optimized using network paths that are both short and wide, and develop efficient algorithms to compute such paths for given pairs of nodes and for all-pairs. Short and wide paths are characterized for many real-world networks. To further demonstrate the utility of this network characterization, we develop novel information-theoretic lower bounds on computation speed in nervous systems due to limitations from anatomical connectivity and physical noise. For the nematode Caenorhabditis elegans, we find these bounds are predictive of biological timescales of behavior. Further, we find the particular C. elegans connectome is globally less efficient for information flow than random networks, but the hub-and-spoke architecture of functional subcircuits is optimal under constraint on number of synapses. This suggests functional subcircuits are a primary organizational principle of this small invertebrate nervous system.