 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Produce Responses Perceived to be Empathic
Mar 26, 2024



Large Language Models (LLMs) have demonstrated surprising performance on many tasks, including writing supportive messages that display empathy. Here, we had these models generate empathic messages in response to posts describing common life experiences, such as workplace situations, parenting, relationships, and other anxiety- and anger-eliciting situations. Across two studies (N=192, 202), we showed human raters a variety of responses written by several models (GPT4 Turbo, Llama2, and Mistral), and had people rate these responses on how empathic they seemed to be. We found that LLM-generated responses were consistently rated as more empathic than human-written responses. Linguistic analyses also show that these models write in distinct, predictable ``styles", in terms of their use of punctuation, emojis, and certain words. These results highlight the potential of using LLMs to enhance human peer support in contexts where empathy is important.
Evaluating Subjective Cognitive Appraisals of Emotions from Large Language Models
Oct 22, 2023The emotions we experience involve complex processes; besides physiological aspects, research in psychology has studied cognitive appraisals where people assess their situations subjectively, according to their own values (Scherer, 2005). Thus, the same situation can often result in different emotional experiences. While the detection of emotion is a well-established task, there is very limited work so far on the automatic prediction of cognitive appraisals. This work fills the gap by presenting CovidET-Appraisals, the most comprehensive dataset to-date that assesses 24 appraisal dimensions, each with a natural language rationale, across 241 Reddit posts. CovidET-Appraisals presents an ideal testbed to evaluate the ability of large language models -- excelling at a wide range of NLP tasks -- to automatically assess and explain cognitive appraisals. We found that while the best models are performant, open-sourced LLMs fall short at this task, presenting a new challenge in the future development of emotionally intelligent models. We release our dataset at https://github.com/honglizhan/CovidET-Appraisals-Public.
Using Positive Matching Contrastive Loss with Facial Action Units to mitigate bias in Facial Expression Recognition
Mar 08, 2023Machine learning models automatically learn discriminative features from the data, and are therefore susceptible to learn strongly-correlated biases, such as using protected attributes like gender and race. Most existing bias mitigation approaches aim to explicitly reduce the model's focus on these protected features. In this work, we propose to mitigate bias by explicitly guiding the model's focus towards task-relevant features using domain knowledge, and we hypothesize that this can indirectly reduce the dependence of the model on spurious correlations it learns from the data. We explore bias mitigation in facial expression recognition systems using facial Action Units (AUs) as the task-relevant feature. To this end, we introduce Feature-based Positive Matching Contrastive Loss which learns the distances between the positives of a sample based on the similarity between their corresponding AU embeddings. We compare our approach with representative baselines and show that incorporating task-relevant features via our method can improve model fairness at minimal cost to classification performance.
ReaSCAN: Compositional Reasoning in Language Grounding
Sep 18, 2021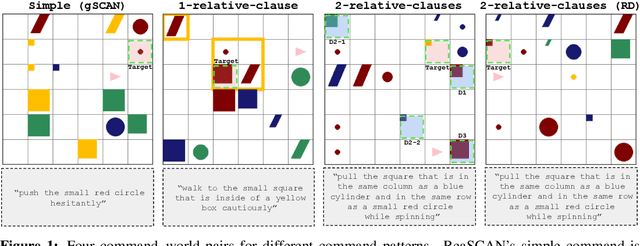

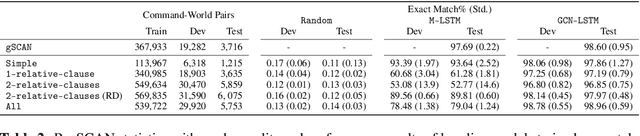
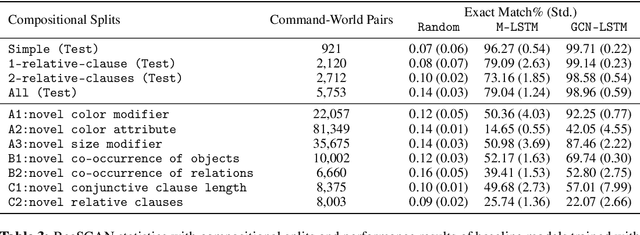
The ability to compositionally map language to referents, relations, and actions is an essential component of language understanding. The recent gSCAN dataset (Ruis et al. 2020, NeurIPS) is an inspiring attempt to assess the capacity of models to learn this kind of grounding in scenarios involving navigational instructions. However, we show that gSCAN's highly constrained design means that it does not require compositional interpretation and that many details of its instructions and scenarios are not required for task success. To address these limitations, we propose ReaSCAN, a benchmark dataset that builds off gSCAN but requires compositional language interpretation and reasoning about entities and relations. We assess two models on ReaSCAN: a multi-modal baseline and a state-of-the-art graph convolutional neural model. These experiments show that ReaSCAN is substantially harder than gSCAN for both neural architectures. This suggests that ReaSCAN can serve as a valuable benchmark for advancing our understanding of models' compositional generalization and reasoning capabilities.
* 26 pages, 8 figures
Not All Negatives are Equal: Label-Aware Contrastive Loss for Fine-grained Text Classification
Sep 12, 2021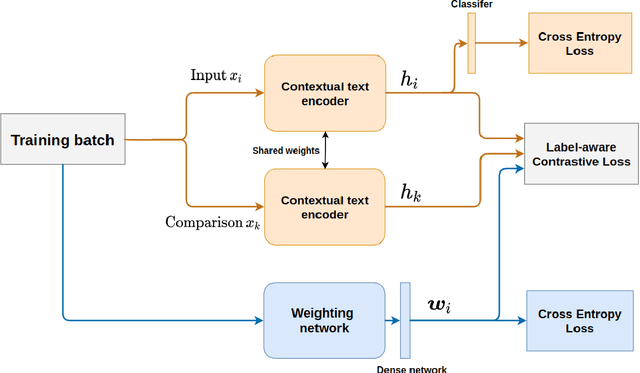

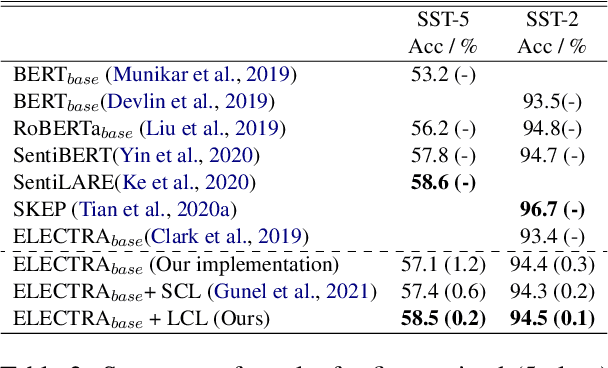
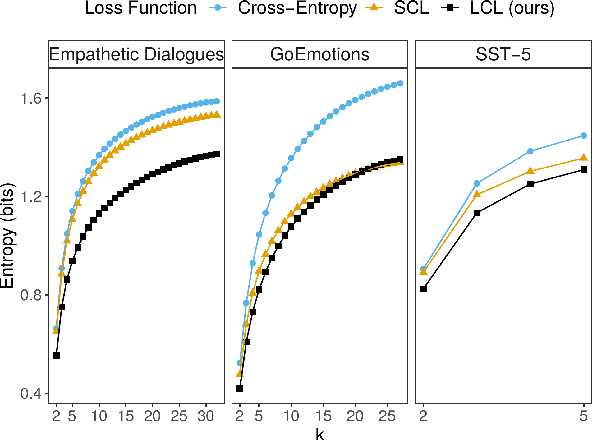
Fine-grained classification involves dealing with datasets with larger number of classes with subtle differences between them. Guiding the model to focus on differentiating dimensions between these commonly confusable classes is key to improving performance on fine-grained tasks. In this work, we analyse the contrastive fine-tuning of pre-trained language models on two fine-grained text classification tasks, emotion classification and sentiment analysis. We adaptively embed class relationships into a contrastive objective function to help differently weigh the positives and negatives, and in particular, weighting closely confusable negatives more than less similar negative examples. We find that Label-aware Contrastive Loss outperforms previous contrastive methods, in the presence of larger number and/or more confusable classes, and helps models to produce output distributions that are more differentiated.
Using Knowledge-Embedded Attention to Augment Pre-trained Language Models for Fine-Grained Emotion Recognition
Jul 31, 2021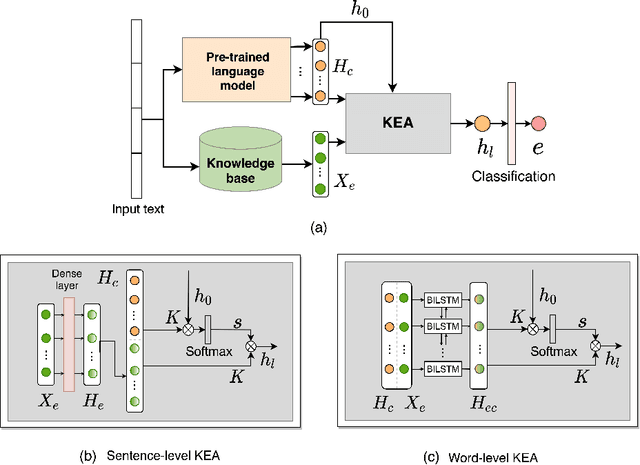
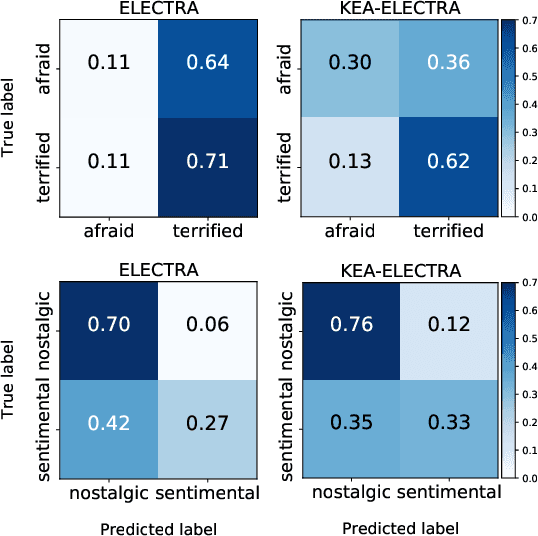
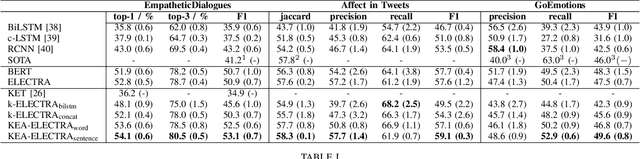

Modern emotion recognition systems are trained to recognize only a small set of emotions, and hence fail to capture the broad spectrum of emotions people experience and express in daily life. In order to engage in more empathetic interactions, future AI has to perform \textit{fine-grained} emotion recognition, distinguishing between many more varied emotions. Here, we focus on improving fine-grained emotion recognition by introducing external knowledge into a pre-trained self-attention model. We propose Knowledge-Embedded Attention (KEA) to use knowledge from emotion lexicons to augment the contextual representations from pre-trained ELECTRA and BERT models. Our results and error analyses outperform previous models on several datasets, and is better able to differentiate closely-confusable emotions, such as afraid and terrified.
An Ethical Framework for Guiding the Development of Affectively-Aware Artificial Intelligence
Jul 29, 2021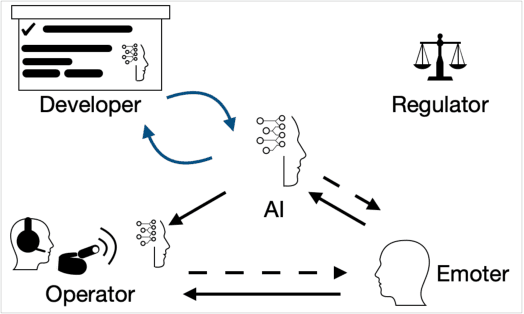
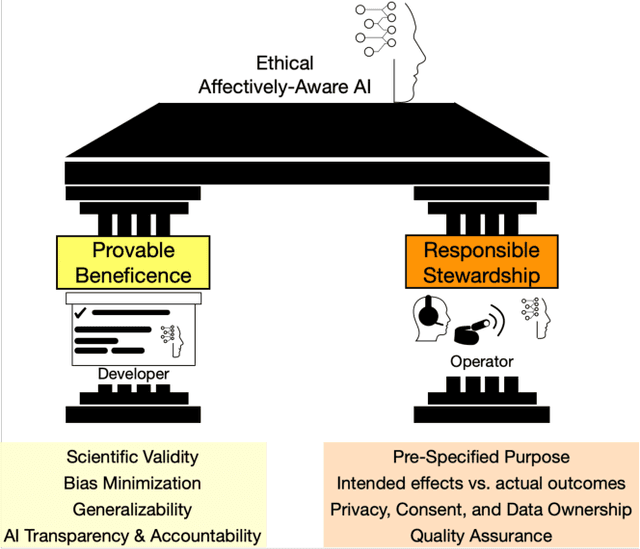
The recent rapid advancements in artificial intelligence research and deployment have sparked more discussion about the potential ramifications of socially- and emotionally-intelligent AI. The question is not if research can produce such affectively-aware AI, but when it will. What will it mean for society when machines -- and the corporations and governments they serve -- can "read" people's minds and emotions? What should developers and operators of such AI do, and what should they not do? The goal of this article is to pre-empt some of the potential implications of these developments, and propose a set of guidelines for evaluating the (moral and) ethical consequences of affectively-aware AI, in order to guide researchers, industry professionals, and policy-makers. We propose a multi-stakeholder analysis framework that separates the ethical responsibilities of AI Developers vis-\`a-vis the entities that deploy such AI -- which we term Operators. Our analysis produces two pillars that clarify the responsibilities of each of these stakeholders: Provable Beneficence, which rests on proving the effectiveness of the AI, and Responsible Stewardship, which governs responsible collection, use, and storage of data and the decisions made from such data. We end with recommendations for researchers, developers, operators, as well as regulators and law-makers.
A Systematic Evaluation of Domain Adaptation in Facial Expression Recognition
Jun 29, 2021
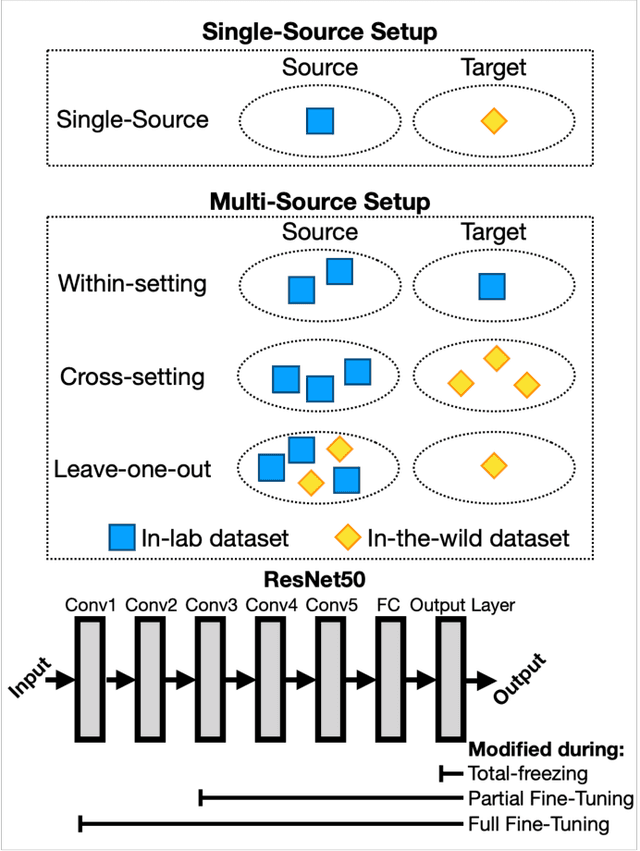

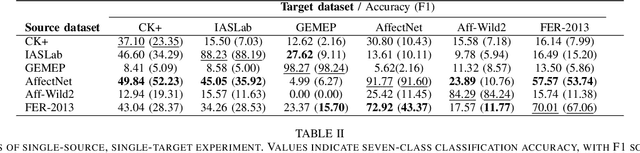
Facial Expression Recognition is a commercially important application, but one common limitation is that applications often require making predictions on out-of-sample distributions, where target images may have very different properties from the images that the model was trained on. How well, or badly, do these models do on unseen target domains? In this paper, we provide a systematic evaluation of domain adaptation in facial expression recognition. Using state-of-the-art transfer learning techniques and six commonly-used facial expression datasets (three collected in the lab and three "in-the-wild"), we conduct extensive round-robin experiments to examine the classification accuracies for a state-of-the-art CNN model. We also perform multi-source experiments where we examine a model's ability to transfer from multiple source datasets, including (i) within-setting (e.g., lab to lab), (ii) cross-setting (e.g., in-the-wild to lab), (iii) mixed-setting (e.g., lab and wild to lab) transfer learning experiments. We find sobering results that the accuracy of transfer learning is not high, and varies idiosyncratically with the target dataset, and to a lesser extent the source dataset. Generally, the best settings for transfer include fine-tuning the weights of a pre-trained model, and we find that training with more datasets, regardless of setting, improves transfer performance. We end with a discussion of the need for more -- and regular -- systematic investigations into the generalizability of FER models, especially for deployed applications.
On Explaining Your Explanations of BERT: An Empirical Study with Sequence Classification
Jan 01, 2021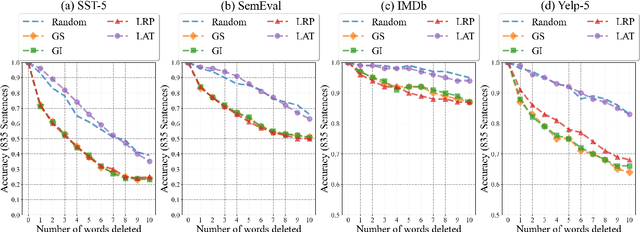
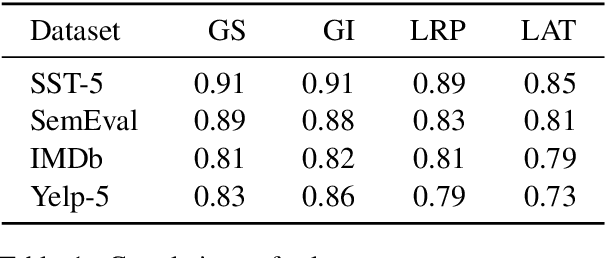
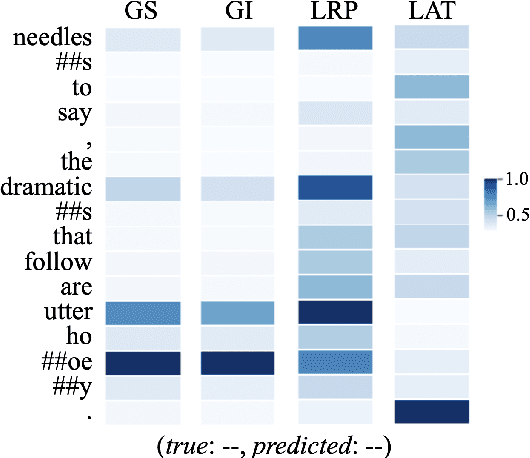

BERT, as one of the pretrianed language models, attracts the most attention in recent years for creating new benchmarks across GLUE tasks via fine-tuning. One pressing issue is to open up the blackbox and explain the decision makings of BERT. A number of attribution techniques have been proposed to explain BERT models, but are often limited to sequence to sequence tasks. In this paper, we adapt existing attribution methods on explaining decision makings of BERT in sequence classification tasks. We conduct extensive analyses of four existing attribution methods by applying them to four different datasets in sentiment analysis. We compare the reliability and robustness of each method via various ablation studies. Furthermore, we test whether attribution methods explain generalized semantics across semantically similar tasks. Our work provides solid guidance for using attribution methods to explain decision makings of BERT for downstream classification tasks.
Context-Guided BERT for Targeted Aspect-Based Sentiment Analysis
Oct 15, 2020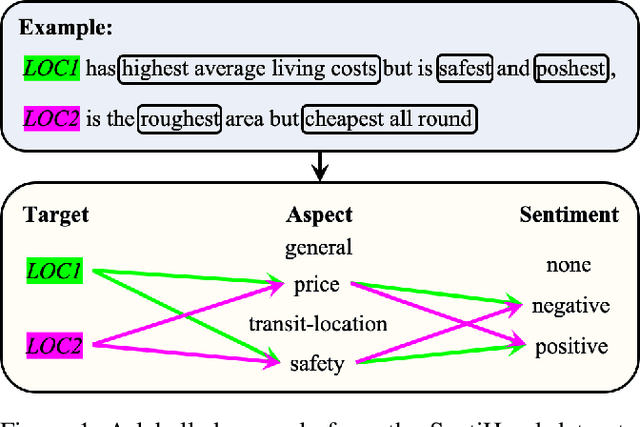
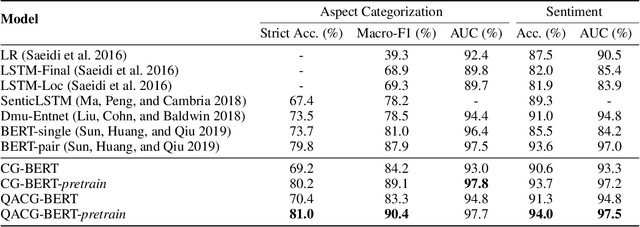
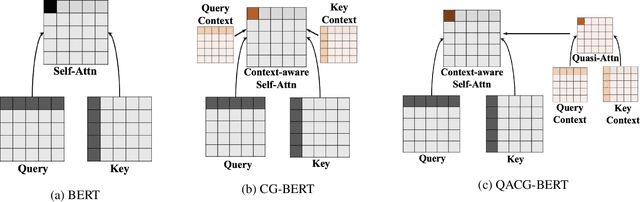
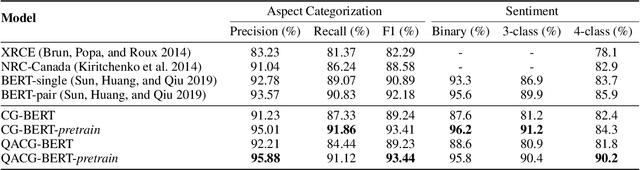
Aspect-based sentiment analysis (ABSA) and Targeted ASBA (TABSA) allow finer-grained inferences about sentiment to be drawn from the same text, depending on context. For example, a given text can have different targets (e.g., neighborhoods) and different aspects (e.g., price or safety), with different sentiment associated with each target-aspect pair. In this paper, we investigate whether adding context to self-attention models improves performance on (T)ABSA. We propose two variants of Context-Guided BERT (CG-BERT) that learn to distribute attention under different contexts. We first adapt a context-aware Transformer to produce a CG-BERT that uses context-guided softmax-attention. Next, we propose an improved Quasi-Attention CG-BERT model that learns a compositional attention that supports subtractive attention. We train both models with pretrained BERT on two (T)ABSA datasets: SentiHood and SemEval-2014 (Task 4). Both models achieve new state-of-the-art results with our QACG-BERT model having the best performance. Furthermore, we provide analyses of the impact of context in the our proposed models. Our work provides more evidence for the utility of adding context-dependencies to pretrained self-attention-based language models for context-based natural language tasks.