 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfTune: Metrically Scaled Monocular Depth Estimation through Self-Supervised Learning
Mar 10, 2022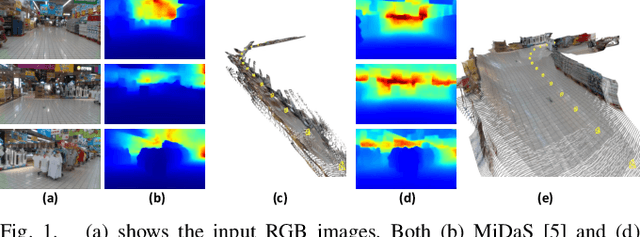
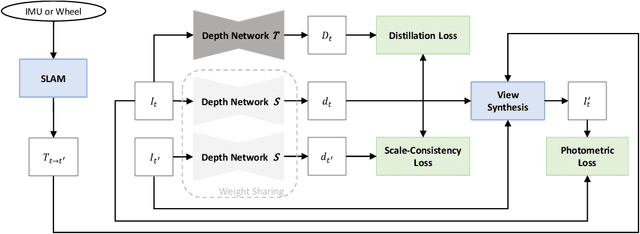
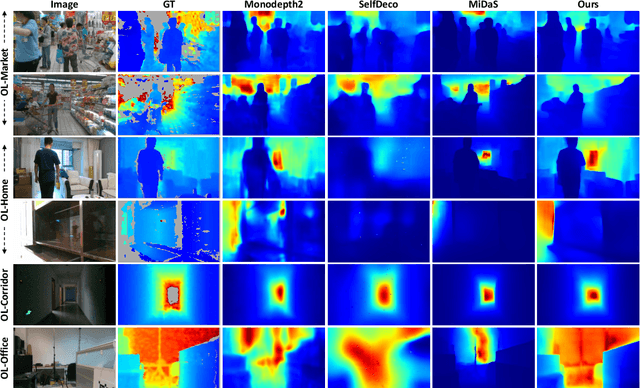
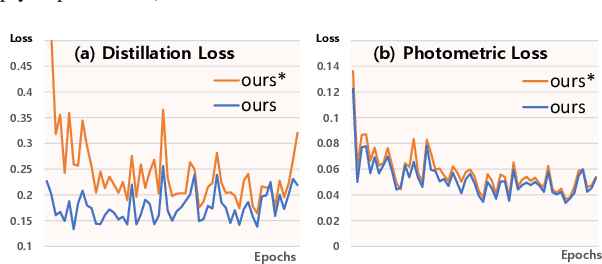
Monocular depth estimation in the wild inherently predicts depth up to an unknown scale. To resolve scale ambiguity issue, we present a learning algorithm that leverages monocular simultaneous localization and mapping (SLAM) with proprioceptive sensors. Such monocular SLAM systems can provide metrically scaled camera poses. Given these metric poses and monocular sequences, we propose a self-supervised learning method for the pre-trained supervised monocular depth networks to enable metrically scaled depth estimation. Our approach is based on a teacher-student formulation which guides our network to predict high-quality depths. We demonstrate that our approach is useful for various applications such as mobile robot navigation and is applicable to diverse environments. Our full system shows improvements over recent self-supervised depth estimation and completion methods on EuRoC, OpenLORIS, and ScanNet datasets.
DnD: Dense Depth Estimation in Crowded Dynamic Indoor Scenes
Aug 12, 2021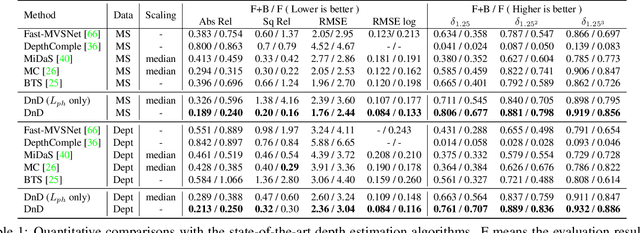
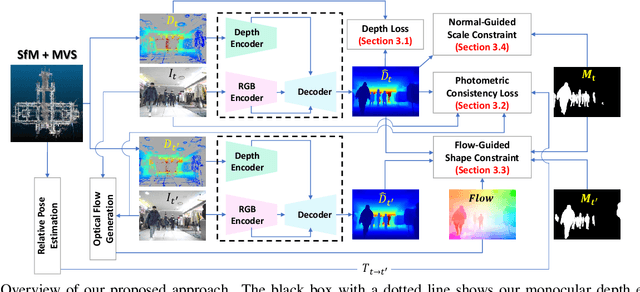
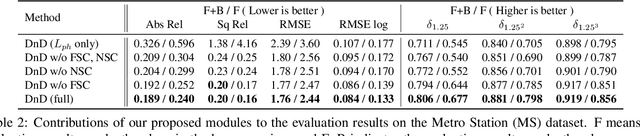
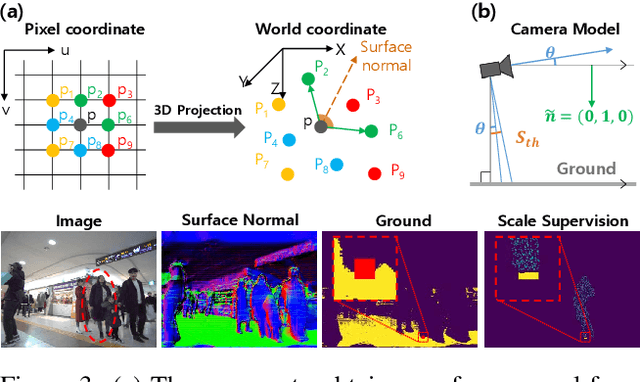
We present a novel approach for estimating depth from a monocular camera as it moves through complex and crowded indoor environments, e.g., a department store or a metro station. Our approach predicts absolute scale depth maps over the entire scene consisting of a static background and multiple moving people, by training on dynamic scenes. Since it is difficult to collect dense depth maps from crowded indoor environments, we design our training framework without requiring depths produced from depth sensing devices. Our network leverages RGB images and sparse depth maps generated from traditional 3D reconstruction methods to estimate dense depth maps. We use two constraints to handle depth for non-rigidly moving people without tracking their motion explicitly. We demonstrate that our approach offers consistent improvements over recent depth estimation methods on the NAVERLABS dataset, which includes complex and crowded scenes.
Large-scale Localization Datasets in Crowded Indoor Spaces
May 19, 2021
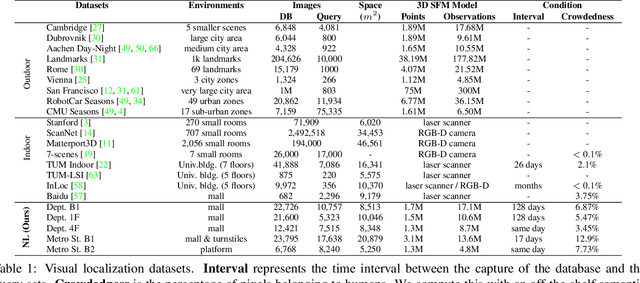


Estimating the precise location of a camera using visual localization enables interesting applications such as augmented reality or robot navigation. This is particularly useful in indoor environments where other localization technologies, such as GNSS, fail. Indoor spaces impose interesting challenges on visual localization algorithms: occlusions due to people, textureless surfaces, large viewpoint changes, low light, repetitive textures, etc. Existing indoor datasets are either comparably small or do only cover a subset of the mentioned challenges. In this paper, we introduce 5 new indoor datasets for visual localization in challenging real-world environments. They were captured in a large shopping mall and a large metro station in Seoul, South Korea, using a dedicated mapping platform consisting of 10 cameras and 2 laser scanners. In order to obtain accurate ground truth camera poses, we developed a robust LiDAR SLAM which provides initial poses that are then refined using a novel structure-from-motion based optimization. We present a benchmark of modern visual localization algorithms on these challenging datasets showing superior performance of structure-based methods using robust image features. The datasets are available at: https://naverlabs.com/datasets
SelfDeco: Self-Supervised Monocular Depth Completion in Challenging Indoor Environments
Nov 10, 2020
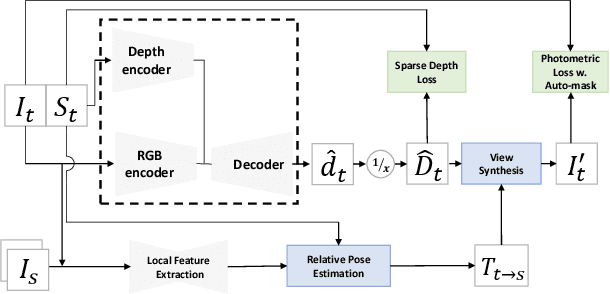

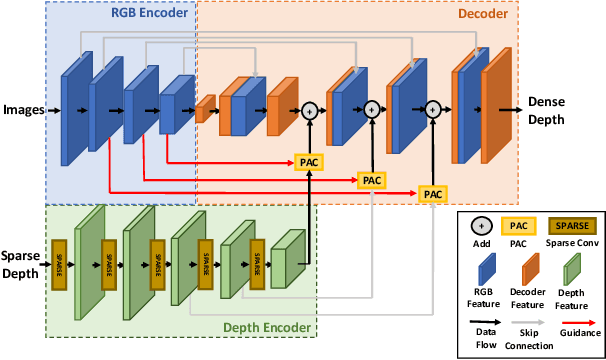
We present a novel algorithm for self-supervised monocular depth completion. Our approach is based on training a neural network that requires only sparse depth measurements and corresponding monocular video sequences without dense depth labels. Our self-supervised algorithm is designed for challenging indoor environments with textureless regions, glossy and transparent surface, non-Lambertian surfaces, moving people, longer and diverse depth ranges and scenes captured by complex ego-motions. Our novel architecture leverages both deep stacks of sparse convolution blocks to extract sparse depth features and pixel-adaptive convolutions to fuse image and depth features. We compare with existing approaches in NYUv2, KITTI and NAVERLABS indoor datasets, and observe 5\:-\:34 \% improvements in root-means-square error (RMSE) reduction.