 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRU4D-SLAM: Reweighting Uncertainty in Gaussian Splatting SLAM for 4D Scene Reconstruction
Feb 24, 2026Combining 3D Gaussian splatting with Simultaneous Localization and Mapping (SLAM) has gained popularity as it enables continuous 3D environment reconstruction during motion. However, existing methods struggle in dynamic environments, particularly moving objects complicate 3D reconstruction and, in turn, hinder reliable tracking. The emergence of 4D reconstruction, especially 4D Gaussian splatting, offers a promising direction for addressing these challenges, yet its potential for 4D-aware SLAM remains largely underexplored. Along this direction, we propose a robust and efficient framework, namely Reweighting Uncertainty in Gaussian Splatting SLAM (RU4D-SLAM) for 4D scene reconstruction, that introduces temporal factors into spatial 3D representation while incorporating uncertainty-aware perception of scene changes, blurred image synthesis, and dynamic scene reconstruction. We enhance dynamic scene representation by integrating motion blur rendering, and improve uncertainty-aware tracking by extending per-pixel uncertainty modeling, which is originally designed for static scenarios, to handle blurred images. Furthermore, we propose a semantic-guided reweighting mechanism for per-pixel uncertainty estimation in dynamic scenes, and introduce a learnable opacity weight to support adaptive 4D mapping. Extensive experiments on standard benchmarks demonstrate that our method substantially outperforms state-of-the-art approaches in both trajectory accuracy and 4D scene reconstruction, particularly in dynamic environments with moving objects and low-quality inputs. Code available: https://ru4d-slam.github.io
Neuromorphic Wireless Split Computing with Multi-Level Spikes
Nov 07, 2024



Inspired by biological processes, neuromorphic computing utilizes spiking neural networks (SNNs) to perform inference tasks, offering significant efficiency gains for workloads involving sequential data. Recent advances in hardware and software have demonstrated that embedding a few bits of payload in each spike exchanged between the spiking neurons can further enhance inference accuracy. In a split computing architecture, where the SNN is divided across two separate devices, the device storing the first layers must share information about the spikes generated by the local output neurons with the other device. Consequently, the advantages of multi-level spikes must be balanced against the challenges of transmitting additional bits between the two devices. This paper addresses these challenges by investigating a wireless neuromorphic split computing architecture employing multi-level SNNs. For this system, we present the design of digital and analog modulation schemes optimized for an orthogonal frequency division multiplexing (OFDM) radio interface. Simulation and experimental results using software-defined radios provide insights into the performance gains of multi-level SNN models and the optimal payload size as a function of the quality of the connection between a transmitter and receiver.
Direct Training Needs Regularisation: Anytime Optimal Inference Spiking Neural Network
Apr 15, 2024



Spiking Neural Network (SNN) is acknowledged as the next generation of Artificial Neural Network (ANN) and hold great promise in effectively processing spatial-temporal information. However, the choice of timestep becomes crucial as it significantly impacts the accuracy of the neural network training. Specifically, a smaller timestep indicates better performance in efficient computing, resulting in reduced latency and operations. While, using a small timestep may lead to low accuracy due to insufficient information presentation with few spikes. This observation motivates us to develop an SNN that is more reliable for adaptive timestep by introducing a novel regularisation technique, namely Spatial-Temporal Regulariser (STR). Our approach regulates the ratio between the strength of spikes and membrane potential at each timestep. This effectively balances spatial and temporal performance during training, ultimately resulting in an Anytime Optimal Inference (AOI) SNN. Through extensive experiments on frame-based and event-based datasets, our method, in combination with cutoff based on softmax output, achieves state-of-the-art performance in terms of both latency and accuracy. Notably, with STR and cutoff, SNN achieves 2.14 to 2.89 faster in inference compared to the pre-configured timestep with near-zero accuracy drop of 0.50% to 0.64% over the event-based datasets. Code available: https://github.com/Dengyu-Wu/AOI-SNN-Regularisation
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
May 19, 2023



Large Language Models (LLMs) have exploded a new heatwave of AI, for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities of the LLMs, categorising them into inherent issues, intended attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and ethical use. Considering the fast development of LLMs, this survey does not intend to be complete (although it includes 300 references), especially when it comes to the applications of LLMs in various domains, but rather a collection of organised literature reviews and discussions to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V.
Randomized Adversarial Training via Taylor Expansion
Mar 19, 2023



In recent years, there has been an explosion of research into developing more robust deep neural networks against adversarial examples. Adversarial training appears as one of the most successful methods. To deal with both the robustness against adversarial examples and the accuracy over clean examples, many works develop enhanced adversarial training methods to achieve various trade-offs between them. Leveraging over the studies that smoothed update on weights during training may help find flat minima and improve generalization, we suggest reconciling the robustness-accuracy trade-off from another perspective, i.e., by adding random noise into deterministic weights. The randomized weights enable our design of a novel adversarial training method via Taylor expansion of a small Gaussian noise, and we show that the new adversarial training method can flatten loss landscape and find flat minima. With PGD, CW, and Auto Attacks, an extensive set of experiments demonstrate that our method enhances the state-of-the-art adversarial training methods, boosting both robustness and clean accuracy. The code is available at https://github.com/Alexkael/Randomized-Adversarial-Training.
Optimising Event-Driven Spiking Neural Network with Regularisation and Cutoff
Jan 23, 2023



Spiking neural networks (SNNs), a variant of artificial neural networks (ANNs) with the benefit of energy efficiency, have achieved the accuracy close to its ANN counterparts, on benchmark datasets such as CIFAR10/100 and ImageNet. However, comparing with frame-based input (e.g., images), event-based inputs from e.g., Dynamic Vision Sensor (DVS) can make a better use of SNNs thanks to the SNNs' asynchronous working mechanism. In this paper, we strengthen the marriage between SNNs and event-based inputs with a proposal to consider anytime optimal inference SNNs, or AOI-SNNs, which can terminate anytime during the inference to achieve optimal inference result. Two novel optimisation techniques are presented to achieve AOI-SNNs: a regularisation and a cutoff. The regularisation enables the training and construction of SNNs with optimised performance, and the cutoff technique optimises the inference of SNNs on event-driven inputs. We conduct an extensive set of experiments on multiple benchmark event-based datasets, including CIFAR10-DVS, N-Caltech101 and DVS128 Gesture. The experimental results demonstrate that our techniques are superior to the state-of-the-art with respect to the accuracy and latency.
A Little Energy Goes a Long Way: Energy-Efficient, Accurate Conversion from Convolutional Neural Networks to Spiking Neural Networks
Mar 06, 2021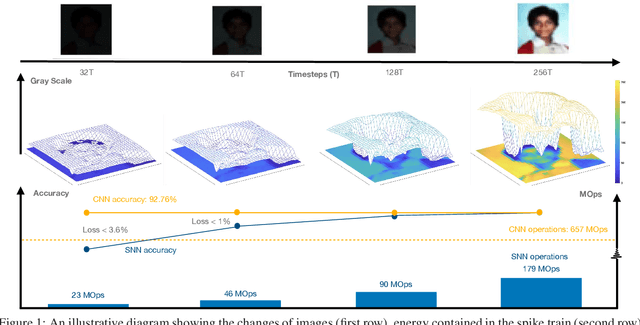
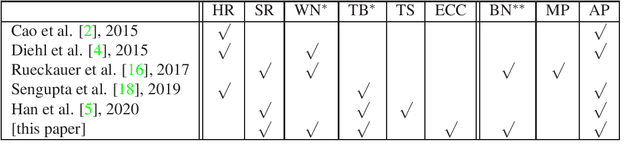
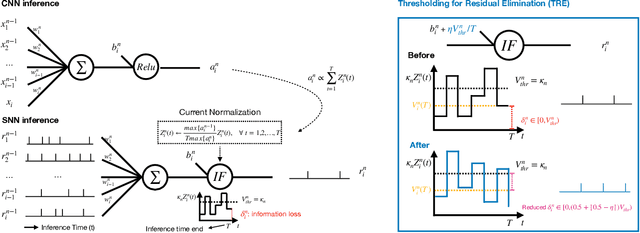

Spiking neural networks (SNNs) offer an inherent ability to process spatial-temporal data, or in other words, realworld sensory data, but suffer from the difficulty of training high accuracy models. A major thread of research on SNNs is on converting a pre-trained convolutional neural network (CNN) to an SNN of the same structure. State-of-the-art conversion methods are approaching the accuracy limit, i.e., the near-zero accuracy loss of SNN against the original CNN. However, we note that this is made possible only when significantly more energy is consumed to process an input. In this paper, we argue that this trend of "energy for accuracy" is not necessary -- a little energy can go a long way to achieve the near-zero accuracy loss. Specifically, we propose a novel CNN-to-SNN conversion method that is able to use a reasonably short spike train (e.g., 256 timesteps for CIFAR10 images) to achieve the near-zero accuracy loss. The new conversion method, named as explicit current control (ECC), contains three techniques (current normalisation, thresholding for residual elimination, and consistency maintenance for batch-normalisation), in order to explicitly control the currents flowing through the SNN when processing inputs. We implement ECC into a tool nicknamed SpKeras, which can conveniently import Keras CNN models and convert them into SNNs. We conduct an extensive set of experiments with the tool -- working with VGG16 and various datasets such as CIFAR10 and CIFAR100 -- and compare with state-of-the-art conversion methods. Results show that ECC is a promising method that can optimise over energy consumption and accuracy loss simultaneously.