 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-of-Service Aware LLM Routing for Edge Computing with Multiple Experts
Aug 01, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities, leading to a significant increase in user demand for LLM services. However, cloud-based LLM services often suffer from high latency, unstable responsiveness, and privacy concerns. Therefore, multiple LLMs are usually deployed at the network edge to boost real-time responsiveness and protect data privacy, particularly for many emerging smart mobile and IoT applications. Given the varying response quality and latency of LLM services, a critical issue is how to route user requests from mobile and IoT devices to an appropriate LLM service (i.e., edge LLM expert) to ensure acceptable quality-of-service (QoS). Existing routing algorithms fail to simultaneously address the heterogeneity of LLM services, the interference among requests, and the dynamic workloads necessary for maintaining long-term stable QoS. To meet these challenges, in this paper we propose a novel deep reinforcement learning (DRL)-based QoS-aware LLM routing framework for sustained high-quality LLM services. Due to the dynamic nature of the global state, we propose a dynamic state abstraction technique to compactly represent global state features with a heterogeneous graph attention network (HAN). Additionally, we introduce an action impact estimator and a tailored reward function to guide the DRL agent in maximizing QoS and preventing latency violations. Extensive experiments on both Poisson and real-world workloads demonstrate that our proposed algorithm significantly improves average QoS and computing resource efficiency compared to existing baselines.
Accelerating Deep Neural Network Training via Distributed Hybrid Order Optimization
May 02, 2025



Scaling deep neural network (DNN) training to more devices can reduce time-to-solution. However, it is impractical for users with limited computing resources. FOSI, as a hybrid order optimizer, converges faster than conventional optimizers by taking advantage of both gradient information and curvature information when updating the DNN model. Therefore, it provides a new chance for accelerating DNN training in the resource-constrained setting. In this paper, we explore its distributed design, namely DHO$_2$, including distributed calculation of curvature information and model update with partial curvature information to accelerate DNN training with a low memory burden. To further reduce the training time, we design a novel strategy to parallelize the calculation of curvature information and the model update on different devices. Experimentally, our distributed design can achieve an approximate linear reduction of memory burden on each device with the increase of the device number. Meanwhile, it achieves $1.4\times\sim2.1\times$ speedup in the total training time compared with other distributed designs based on conventional first- and second-order optimizers.
TACO: Tackling Over-correction in Federated Learning with Tailored Adaptive Correction
Apr 24, 2025Non-independent and identically distributed (Non-IID) data across edge clients have long posed significant challenges to federated learning (FL) training in edge computing environments. Prior works have proposed various methods to mitigate this statistical heterogeneity. While these works can achieve good theoretical performance, in this work we provide the first investigation into a hidden over-correction phenomenon brought by the uniform model correction coefficients across clients adopted by existing methods. Such over-correction could degrade model performance and even cause failures in model convergence. To address this, we propose TACO, a novel algorithm that addresses the non-IID nature of clients' data by implementing fine-grained, client-specific gradient correction and model aggregation, steering local models towards a more accurate global optimum. Moreover, we verify that leading FL algorithms generally have better model accuracy in terms of communication rounds rather than wall-clock time, resulting from their extra computation overhead imposed on clients. To enhance the training efficiency, TACO deploys a lightweight model correction and tailored aggregation approach that requires minimum computation overhead and no extra information beyond the synchronized model parameters. To validate TACO's effectiveness, we present the first FL convergence analysis that reveals the root cause of over-correction. Extensive experiments across various datasets confirm TACO's superior and stable performance in practice.
Analytic Personalized Federated Meta-Learning
Feb 10, 2025



Analytic federated learning (AFL) which updates model weights only once by using closed-form least-square (LS) solutions can reduce abundant training time in gradient-free federated learning (FL). The current AFL framework cannot support deep neural network (DNN) training, which hinders its implementation on complex machine learning tasks. Meanwhile, it overlooks the heterogeneous data distribution problem that restricts the single global model from performing well on each client's task. To overcome the first challenge, we propose an AFL framework, namely FedACnnL, in which we resort to a novel local analytic learning method (ACnnL) and model the training of each layer as a distributed LS problem. For the second challenge, we propose an analytic personalized federated meta-learning framework, namely pFedACnnL, which is inherited from FedACnnL. In pFedACnnL, clients with similar data distribution share a common robust global model for fast adapting it to local tasks in an analytic manner. FedACnnL is theoretically proven to require significantly shorter training time than the conventional zeroth-order (i.e. gradient-free) FL frameworks on DNN training while the reduction ratio is $98\%$ in the experiment. Meanwhile, pFedACnnL achieves state-of-the-art (SOTA) model performance in most cases of convex and non-convex settings, compared with the previous SOTA frameworks.
FedMoE-DA: Federated Mixture of Experts via Domain Aware Fine-grained Aggregation
Nov 04, 2024



Federated learning (FL) is a collaborative machine learning approach that enables multiple clients to train models without sharing their private data. With the rise of deep learning, large-scale models have garnered significant attention due to their exceptional performance. However, a key challenge in FL is the limitation imposed by clients with constrained computational and communication resources, which hampers the deployment of these large models. The Mixture of Experts (MoE) architecture addresses this challenge with its sparse activation property, which reduces computational workload and communication demands during inference and updates. Additionally, MoE facilitates better personalization by allowing each expert to specialize in different subsets of the data distribution. To alleviate the communication burdens between the server and clients, we propose FedMoE-DA, a new FL model training framework that leverages the MoE architecture and incorporates a novel domain-aware, fine-grained aggregation strategy to enhance the robustness, personalizability, and communication efficiency simultaneously. Specifically, the correlation between both intra-client expert models and inter-client data heterogeneity is exploited. Moreover, we utilize peer-to-peer (P2P) communication between clients for selective expert model synchronization, thus significantly reducing the server-client transmissions. Experiments demonstrate that our FedMoE-DA achieves excellent performance while reducing the communication pressure on the server.
Deep Intellectual Property: A Survey
Apr 28, 2023With the widespread application in industrial manufacturing and commercial services, well-trained deep neural networks (DNNs) are becoming increasingly valuable and crucial assets due to the tremendous training cost and excellent generalization performance. These trained models can be utilized by users without much expert knowledge benefiting from the emerging ''Machine Learning as a Service'' (MLaaS) paradigm. However, this paradigm also exposes the expensive models to various potential threats like model stealing and abuse. As an urgent requirement to defend against these threats, Deep Intellectual Property (DeepIP), to protect private training data, painstakingly-tuned hyperparameters, or costly learned model weights, has been the consensus of both industry and academia. To this end, numerous approaches have been proposed to achieve this goal in recent years, especially to prevent or discover model stealing and unauthorized redistribution. Given this period of rapid evolution, the goal of this paper is to provide a comprehensive survey of the recent achievements in this field. More than 190 research contributions are included in this survey, covering many aspects of Deep IP Protection: challenges/threats, invasive solutions (watermarking), non-invasive solutions (fingerprinting), evaluation metrics, and performance. We finish the survey by identifying promising directions for future research.
FTBNN: Rethinking Non-linearity for 1-bit CNNs and Going Beyond
Oct 29, 2020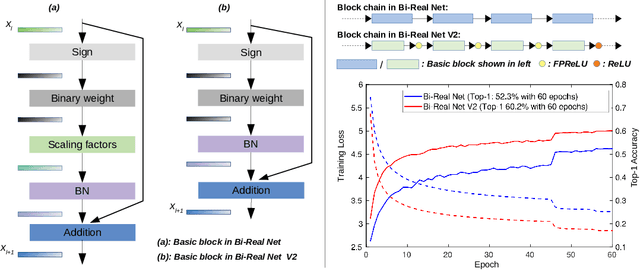


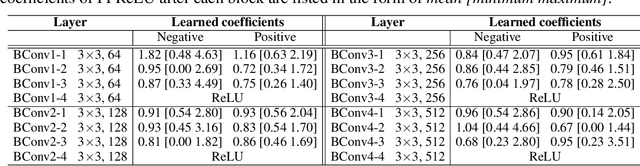
Binary neural networks (BNNs), where both weights and activations are binarized into 1 bit, have been widely studied in recent years due to its great benefit of highly accelerated computation and substantially reduced memory footprint that appeal to the development of resource constrained devices. In contrast to previous methods tending to reduce the quantization error for training BNN structures, we argue that the binarized convolution process owns an increasing linearity towards the target of minimizing such error, which in turn hampers BNN's discriminative ability. In this paper, we re-investigate and tune proper non-linear modules to fix that contradiction, leading to a strong baseline which achieves state-of-the-art performance on the large-scale ImageNet dataset in terms of accuracy and training efficiency. To go further, we find that the proposed BNN model still has much potential to be compressed by making a better use of the efficient binary operations, without losing accuracy. In addition, the limited capacity of the BNN model can also be increased with the help of group execution. Based on these insights, we are able to improve the baseline with an additional 4~5% top-1 accuracy gain even with less computational cost. Our code will be made public at https://github.com/zhuogege1943/ftbnn.
Simultaneous Clustering and Optimization for Evolving Datasets
Aug 04, 2019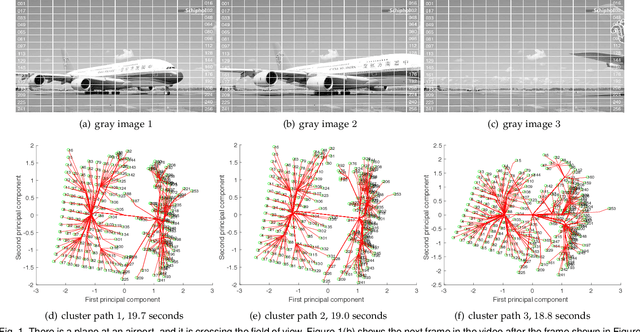


Simultaneous clustering and optimization (SCO) has recently drawn much attention due to its wide range of practical applications. Many methods have been previously proposed to solve this problem and obtain the optimal model. However, when a dataset evolves over time, those existing methods have to update the model frequently to guarantee accuracy; such updating is computationally infeasible. In this paper, we propose a new formulation of SCO to handle evolving datasets. Specifically, we propose a new variant of the alternating direction method of multipliers (ADMM) to solve this problem efficiently. The guarantee of model accuracy is analyzed theoretically for two specific tasks: ridge regression and convex clustering. Extensive empirical studies confirm the effectiveness of our method.