 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStuck in the Quicksand of Numeracy, Far from AGI Summit: Evaluating LLMs' Mathematical Competency through Ontology-guided Perturbations
Jan 17, 2024Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness, in mathematical reasoning tasks, remains an open question. In response, we develop (i) an ontology of perturbations of maths questions, (ii) a semi-automatic method of perturbation, and (iii) a dataset of perturbed maths questions to probe the limits of LLM capabilities in mathematical reasoning tasks. These controlled perturbations span across multiple fine dimensions of the structural and representational aspects of maths questions. Using GPT-4, we generated the MORE dataset by perturbing randomly selected five seed questions from GSM8K. This process was guided by our ontology and involved a thorough automatic and manual filtering process, yielding a set of 216 maths problems. We conducted comprehensive evaluation of both closed-source and open-source LLMs on MORE. The results show a significant performance drop across all the models against the perturbed questions. This strongly suggests that current LLMs lack robust mathematical skills and deep reasoning abilities. This research not only identifies multiple gaps in the capabilities of current models, but also highlights multiple potential directions for future development. Our dataset will be made publicly available at https://huggingface.co/datasets/declare-lab/GSM8k_MORE.
Mustango: Toward Controllable Text-to-Music Generation
Nov 14, 2023



With recent advancements in text-to-audio and text-to-music based on latent diffusion models, the quality of generated content has been reaching new heights. The controllability of musical aspects, however, has not been explicitly explored in text-to-music systems yet. In this paper, we present Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion, that expands the Tango text-to-audio model. Mustango aims to control the generated music, not only with general text captions, but from more rich captions that could include specific instructions related to chords, beats, tempo, and key. As part of Mustango, we propose MuNet, a Music-Domain-Knowledge-Informed UNet sub-module to integrate these music-specific features, which we predict from the text prompt, as well as the general text embedding, into the diffusion denoising process. To overcome the limited availability of open datasets of music with text captions, we propose a novel data augmentation method that includes altering the harmonic, rhythmic, and dynamic aspects of music audio and using state-of-the-art Music Information Retrieval methods to extract the music features which will then be appended to the existing descriptions in text format. We release the resulting MusicBench dataset which contains over 52K instances and includes music-theory-based descriptions in the caption text. Through extensive experiments, we show that the quality of the music generated by Mustango is state-of-the-art, and the controllability through music-specific text prompts greatly outperforms other models in terms of desired chords, beat, key, and tempo, on multiple datasets.
Language Guided Visual Question Answering: Elevate Your Multimodal Language Model Using Knowledge-Enriched Prompts
Oct 31, 2023Visual question answering (VQA) is the task of answering questions about an image. The task assumes an understanding of both the image and the question to provide a natural language answer. VQA has gained popularity in recent years due to its potential applications in a wide range of fields, including robotics, education, and healthcare. In this paper, we focus on knowledge-augmented VQA, where answering the question requires commonsense knowledge, world knowledge, and reasoning about ideas and concepts not present in the image. We propose a multimodal framework that uses language guidance (LG) in the form of rationales, image captions, scene graphs, etc to answer questions more accurately. We benchmark our method on the multi-choice question-answering task of the A-OKVQA, Science-QA, VSR, and IconQA datasets using CLIP and BLIP models. We show that the use of language guidance is a simple but powerful and effective strategy for visual question answering. Our language guidance improves the performance of CLIP by 7.6% and BLIP-2 by 4.8% in the challenging A-OKVQA dataset. We also observe consistent improvement in performance on the Science-QA, VSR, and IconQA datasets when using the proposed language guidances. The implementation of LG-VQA is publicly available at https:// github.com/declare-lab/LG-VQA.
Flacuna: Unleashing the Problem Solving Power of Vicuna using FLAN Fine-Tuning
Jul 05, 2023Recently, the release of INSTRUCTEVAL has provided valuable insights into the performance of large language models (LLMs) that utilize encoder-decoder or decoder-only architecture. Interestingly, despite being introduced four years ago, T5-based LLMs, such as FLAN-T5, continue to outperform the latest decoder-based LLMs, such as LLAMA and VICUNA, on tasks that require general problem-solving skills. This performance discrepancy can be attributed to three key factors: (1) Pre-training data, (2) Backbone architecture, and (3) Instruction dataset. In this technical report, our main focus is on investigating the impact of the third factor by leveraging VICUNA, a large language model based on LLAMA, which has undergone fine-tuning on ChatGPT conversations. To achieve this objective, we fine-tuned VICUNA using a customized instruction dataset collection called FLANMINI. This collection includes a subset of the large-scale instruction dataset known as FLAN, as well as various code-related datasets and conversational datasets derived from ChatGPT/GPT-4. This dataset comprises a large number of tasks that demand problem-solving skills. Our experimental findings strongly indicate that the enhanced problem-solving abilities of our model, FLACUNA, are obtained through fine-tuning VICUNA on the FLAN dataset, leading to significant improvements across numerous benchmark datasets in INSTRUCTEVAL. FLACUNA is publicly available at https://huggingface.co/declare-lab/flacuna-13b-v1.0.
STOAT: Structured Data to Analytical Text With Controls
May 19, 2023Recent language models have made tremendous progress in the structured data to text generation task. However, these models still give sub-optimal performance where logical inference is required to generate the descriptions. In this work, we specifically focus on analytical text generation from structured data such as tables. Building on the taxonomy proposed in (Gupta et al., 2020) we focus on controllable table to text generation for the following reasoning categories: numerical reasoning, commonsense reasoning, temporal reasoning, table knowledge, and entity knowledge. We propose STOAT model, which is table and reasoning aware, with vector-quantization to infuse the given reasoning categories in the output. We observe that our model provides 10.19%, 1.13% improvement on the PARENT metric in iToTTo and Infotabs for the analytical sentence task. We also found that our model generates 15.3% more faithful and analytical descriptions as compared to the baseline models in human evaluation. We curate and release two reasoning category annotated table-to-interesting text generation datasets based on the ToTTo (Parikh et al., 2020) and InfoTabs datasets (Gupta et al.,2020).
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
Apr 24, 2023The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
Two is Better than Many? Binary Classification as an Effective Approach to Multi-Choice Question Answering
Oct 29, 2022We propose a simple refactoring of multi-choice question answering (MCQA) tasks as a series of binary classifications. The MCQA task is generally performed by scoring each (question, answer) pair normalized over all the pairs, and then selecting the answer from the pair that yield the highest score. For n answer choices, this is equivalent to an n-class classification setup where only one class (true answer) is correct. We instead show that classifying (question, true answer) as positive instances and (question, false answer) as negative instances is significantly more effective across various models and datasets. We show the efficacy of our proposed approach in different tasks -- abductive reasoning, commonsense question answering, science question answering, and sentence completion. Our DeBERTa binary classification model reaches the top or close to the top performance on public leaderboards for these tasks. The source code of the proposed approach is available at https://github.com/declare-lab/TEAM.
Multiview Contextual Commonsense Inference: A New Dataset and Task
Oct 06, 2022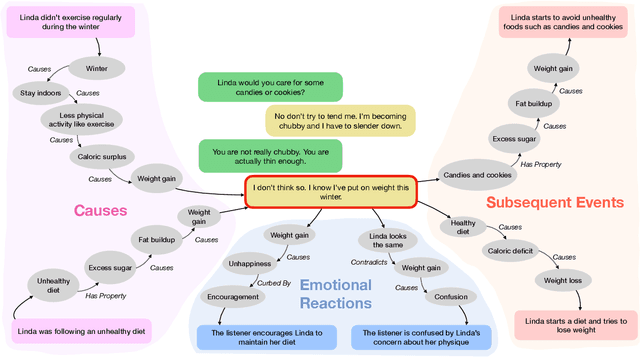
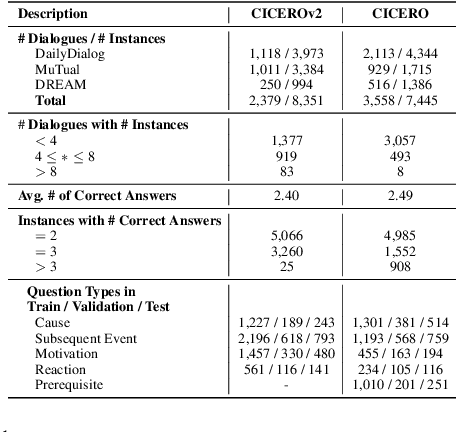

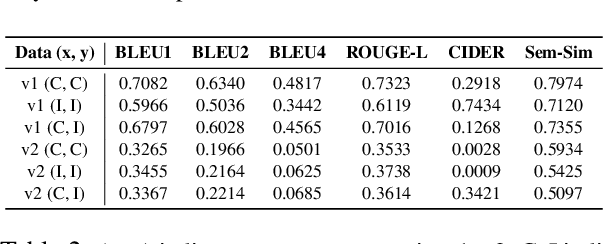
Contextual commonsense inference is the task of generating various types of explanations around the events in a dyadic dialogue, including cause, motivation, emotional reaction, and others. Producing a coherent and non-trivial explanation requires awareness of the dialogue's structure and of how an event is grounded in the context. In this work, we create CICEROv2, a dataset consisting of 8,351 instances from 2,379 dialogues, containing multiple human-written answers for each contextual commonsense inference question, representing a type of explanation on cause, subsequent event, motivation, and emotional reaction. We show that the inferences in CICEROv2 are more semantically diverse than other contextual commonsense inference datasets. To solve the inference task, we propose a collection of pre-training objectives, including concept denoising and utterance sorting to prepare a pre-trained model for the downstream contextual commonsense inference task. Our results show that the proposed pre-training objectives are effective at adapting the pre-trained T5-Large model for the contextual commonsense inference task.
Generating Intermediate Steps for NLI with Next-Step Supervision
Aug 31, 2022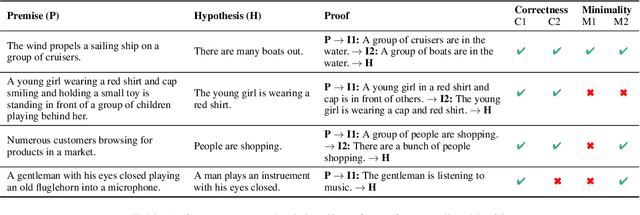
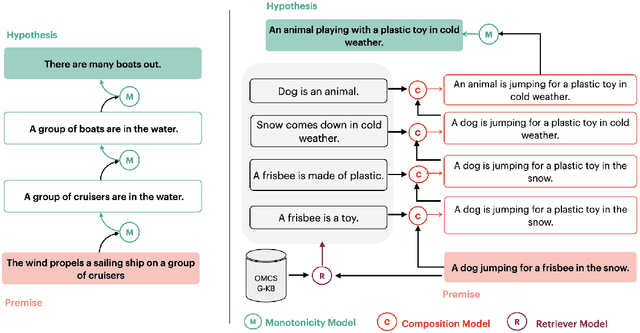
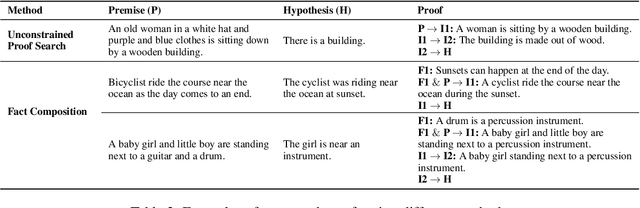
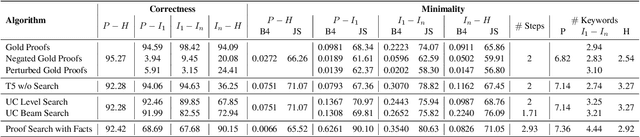
The Natural Language Inference (NLI) task often requires reasoning over multiple steps to reach the conclusion. While the necessity of generating such intermediate steps (instead of a summary explanation) has gained popular support, it is unclear how to generate such steps without complete end-to-end supervision and how such generated steps can be further utilized. In this work, we train a sequence-to-sequence model to generate only the next step given an NLI premise and hypothesis pair (and previous steps); then enhance it with external knowledge and symbolic search to generate intermediate steps with only next-step supervision. We show the correctness of such generated steps through automated and human verification. Furthermore, we show that such generated steps can help improve end-to-end NLI task performance using simple data augmentation strategies, across multiple public NLI datasets.
CICERO: A Dataset for Contextualized Commonsense Inference in Dialogues
Apr 07, 2022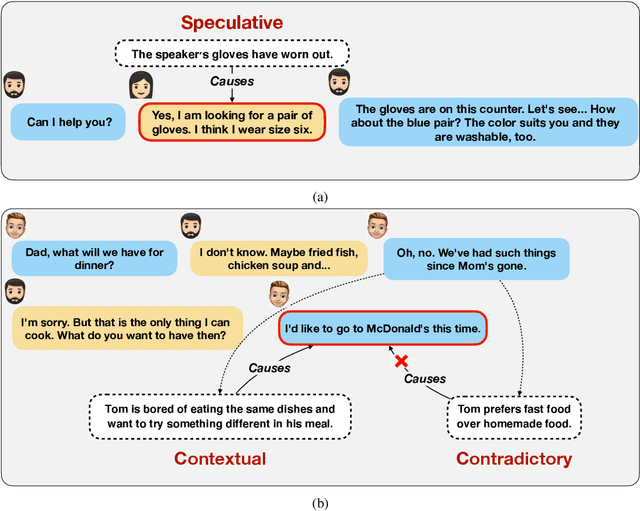


This paper addresses the problem of dialogue reasoning with contextualized commonsense inference. We curate CICERO, a dataset of dyadic conversations with five types of utterance-level reasoning-based inferences: cause, subsequent event, prerequisite, motivation, and emotional reaction. The dataset contains 53,105 of such inferences from 5,672 dialogues. We use this dataset to solve relevant generative and discriminative tasks: generation of cause and subsequent event; generation of prerequisite, motivation, and listener's emotional reaction; and selection of plausible alternatives. Our results ascertain the value of such dialogue-centric commonsense knowledge datasets. It is our hope that CICERO will open new research avenues into commonsense-based dialogue reasoning.