 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe future of cosmological likelihood-based inference: accelerated high-dimensional parameter estimation and model comparison
May 21, 2024We advocate for a new paradigm of cosmological likelihood-based inference, leveraging recent developments in machine learning and its underlying technology, to accelerate Bayesian inference in high-dimensional settings. Specifically, we combine (i) emulation, where a machine learning model is trained to mimic cosmological observables, e.g. CosmoPower-JAX; (ii) differentiable and probabilistic programming, e.g. JAX and NumPyro, respectively; (iii) scalable Markov chain Monte Carlo (MCMC) sampling techniques that exploit gradients, e.g. Hamiltonian Monte Carlo; and (iv) decoupled and scalable Bayesian model selection techniques that compute the Bayesian evidence purely from posterior samples, e.g. the learned harmonic mean implemented in harmonic. This paradigm allows us to carry out a complete Bayesian analysis, including both parameter estimation and model selection, in a fraction of the time of traditional approaches. First, we demonstrate the application of this paradigm on a simulated cosmic shear analysis for a Stage IV survey in 37- and 39-dimensional parameter spaces, comparing $\Lambda$CDM and a dynamical dark energy model ($w_0w_a$CDM). We recover posterior contours and evidence estimates that are in excellent agreement with those computed by the traditional nested sampling approach while reducing the computational cost from 8 months on 48 CPU cores to 2 days on 12 GPUs. Second, we consider a joint analysis between three simulated next-generation surveys, each performing a 3x2pt analysis, resulting in 157- and 159-dimensional parameter spaces. Standard nested sampling techniques are simply not feasible in this high-dimensional setting, requiring a projected 12 years of compute time on 48 CPU cores; on the other hand, the proposed approach only requires 8 days of compute time on 24 GPUs. All packages used in our analyses are publicly available.
Differentiable and accelerated wavelet transforms on the sphere and ball
Feb 02, 2024Directional wavelet dictionaries are hierarchical representations which efficiently capture and segment information across scale, location and orientation. Such representations demonstrate a particular affinity to physical signals, which often exhibit highly anisotropic, localised multiscale structure. Many physically important signals are observed over spherical domains, such as the celestial sky in cosmology. Leveraging recent advances in computational harmonic analysis, we design new highly distributable and automatically differentiable directional wavelet transforms on the $2$-dimensional sphere $\mathbb{S}^2$ and $3$-dimensional ball $\mathbb{B}^3 = \mathbb{R}^+ \times \mathbb{S}^2$ (the space formed by augmenting the sphere with the radial half-line). We observe up to a $300$-fold and $21800$-fold acceleration for signals on the sphere and ball, respectively, compared to existing software, whilst maintaining 64-bit machine precision. Not only do these algorithms dramatically accelerate existing spherical wavelet transforms, the gradient information afforded by automatic differentiation unlocks many data-driven analysis techniques previously not possible for these spaces. We publicly release both S2WAV and S2BALL, open-sourced JAX libraries for our transforms that are automatically differentiable and readily deployable both on and over clusters of hardware accelerators (e.g. GPUs & TPUs).
Scalable Bayesian uncertainty quantification with data-driven priors for radio interferometric imaging
Nov 30, 2023



Next-generation radio interferometers like the Square Kilometer Array have the potential to unlock scientific discoveries thanks to their unprecedented angular resolution and sensitivity. One key to unlocking their potential resides in handling the deluge and complexity of incoming data. This challenge requires building radio interferometric imaging methods that can cope with the massive data sizes and provide high-quality image reconstructions with uncertainty quantification (UQ). This work proposes a method coined QuantifAI to address UQ in radio-interferometric imaging with data-driven (learned) priors for high-dimensional settings. Our model, rooted in the Bayesian framework, uses a physically motivated model for the likelihood. The model exploits a data-driven convex prior, which can encode complex information learned implicitly from simulations and guarantee the log-concavity of the posterior. We leverage probability concentration phenomena of high-dimensional log-concave posteriors that let us obtain information about the posterior, avoiding MCMC sampling techniques. We rely on convex optimisation methods to compute the MAP estimation, which is known to be faster and better scale with dimension than MCMC sampling strategies. Our method allows us to compute local credible intervals, i.e., Bayesian error bars, and perform hypothesis testing of structure on the reconstructed image. In addition, we propose a novel blazing-fast method to compute pixel-wise uncertainties at different scales. We demonstrate our method by reconstructing radio-interferometric images in a simulated setting and carrying out fast and scalable UQ, which we validate with MCMC sampling. Our method shows an improved image quality and more meaningful uncertainties than the benchmark method based on a sparsity-promoting prior. QuantifAI's source code: https://github.com/astro-informatics/QuantifAI.
Differentiable and accelerated spherical harmonic and Wigner transforms
Nov 24, 2023Many areas of science and engineering encounter data defined on spherical manifolds. Modelling and analysis of spherical data often necessitates spherical harmonic transforms, at high degrees, and increasingly requires efficient computation of gradients for machine learning or other differentiable programming tasks. We develop novel algorithmic structures for accelerated and differentiable computation of generalised Fourier transforms on the sphere $\mathbb{S}^2$ and rotation group $\text{SO}(3)$, i.e. spherical harmonic and Wigner transforms, respectively. We present a recursive algorithm for the calculation of Wigner $d$-functions that is both stable to high harmonic degrees and extremely parallelisable. By tightly coupling this with separable spherical transforms, we obtain algorithms that exhibit an extremely parallelisable structure that is well-suited for the high throughput computing of modern hardware accelerators (e.g. GPUs). We also develop a hybrid automatic and manual differentiation approach so that gradients can be computed efficiently. Our algorithms are implemented within the JAX differentiable programming framework in the S2FFT software code. Numerous samplings of the sphere are supported, including equiangular and HEALPix sampling. Computational errors are at the order of machine precision for spherical samplings that admit a sampling theorem. When benchmarked against alternative C codes we observe up to a 400-fold acceleration. Furthermore, when distributing over multiple GPUs we achieve very close to optimal linear scaling with increasing number of GPUs due to the highly parallelised and balanced nature of our algorithms. Provided access to sufficiently many GPUs our transforms thus exhibit an unprecedented effective linear time complexity.
Learned harmonic mean estimation of the marginal likelihood with normalizing flows
Jun 30, 2023



Computing the marginal likelihood (also called the Bayesian model evidence) is an important task in Bayesian model selection, providing a principled quantitative way to compare models. The learned harmonic mean estimator solves the exploding variance problem of the original harmonic mean estimation of the marginal likelihood. The learned harmonic mean estimator learns an importance sampling target distribution that approximates the optimal distribution. While the approximation need not be highly accurate, it is critical that the probability mass of the learned distribution is contained within the posterior in order to avoid the exploding variance problem. In previous work a bespoke optimization problem is introduced when training models in order to ensure this property is satisfied. In the current article we introduce the use of normalizing flows to represent the importance sampling target distribution. A flow-based model is trained on samples from the posterior by maximum likelihood estimation. Then, the probability density of the flow is concentrated by lowering the variance of the base distribution, i.e. by lowering its "temperature", ensuring its probability mass is contained within the posterior. This approach avoids the need for a bespoke optimisation problem and careful fine tuning of parameters, resulting in a more robust method. Moreover, the use of normalizing flows has the potential to scale to high dimensional settings. We present preliminary experiments demonstrating the effectiveness of the use of flows for the learned harmonic mean estimator. The harmonic code implementing the learned harmonic mean, which is publicly available, has been updated to now support normalizing flows.
Proximal nested sampling with data-driven priors for physical scientists
Jun 30, 2023



Proximal nested sampling was introduced recently to open up Bayesian model selection for high-dimensional problems such as computational imaging. The framework is suitable for models with a log-convex likelihood, which are ubiquitous in the imaging sciences. The purpose of this article is two-fold. First, we review proximal nested sampling in a pedagogical manner in an attempt to elucidate the framework for physical scientists. Second, we show how proximal nested sampling can be extended in an empirical Bayes setting to support data-driven priors, such as deep neural networks learned from training data.
Scalable and Equivariant Spherical CNNs by Discrete-Continuous (DISCO) Convolutions
Sep 27, 2022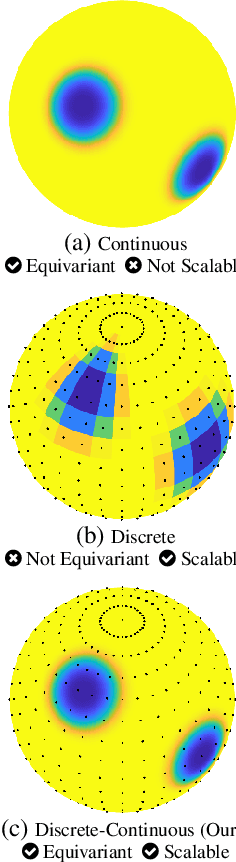
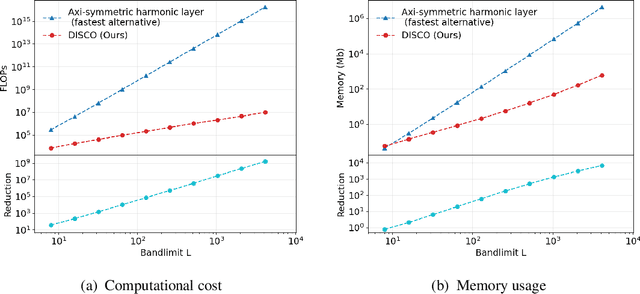
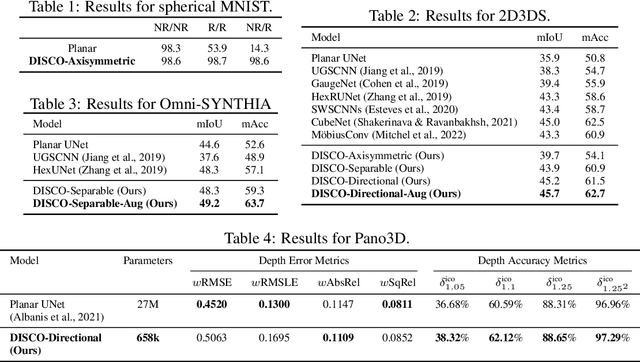
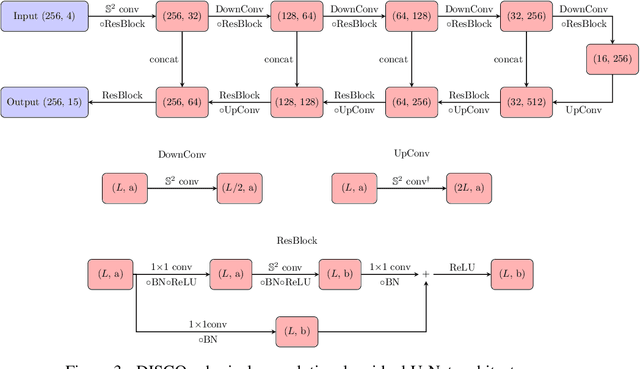
No existing spherical convolutional neural network (CNN) framework is both computationally scalable and rotationally equivariant. Continuous approaches capture rotational equivariance but are often prohibitively computationally demanding. Discrete approaches offer more favorable computational performance but at the cost of equivariance. We develop a hybrid discrete-continuous (DISCO) group convolution that is simultaneously equivariant and computationally scalable to high-resolution. While our framework can be applied to any compact group, we specialize to the sphere. Our DISCO spherical convolutions not only exhibit $\text{SO}(3)$ rotational equivariance but also a form of asymptotic $\text{SO}(3)/\text{SO}(2)$ rotational equivariance, which is more desirable for many applications (where $\text{SO}(n)$ is the special orthogonal group representing rotations in $n$-dimensions). Through a sparse tensor implementation we achieve linear scaling in number of pixels on the sphere for both computational cost and memory usage. For 4k spherical images we realize a saving of $10^9$ in computational cost and $10^4$ in memory usage when compared to the most efficient alternative equivariant spherical convolution. We apply the DISCO spherical CNN framework to a number of benchmark dense-prediction problems on the sphere, such as semantic segmentation and depth estimation, on all of which we achieve the state-of-the-art performance.
Efficient Generalized Spherical CNNs
Oct 23, 2020
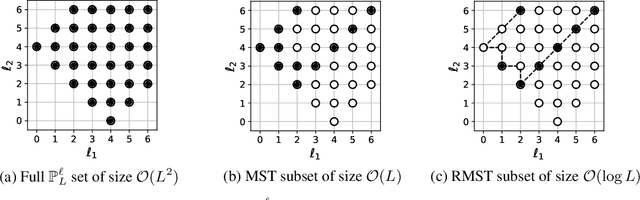
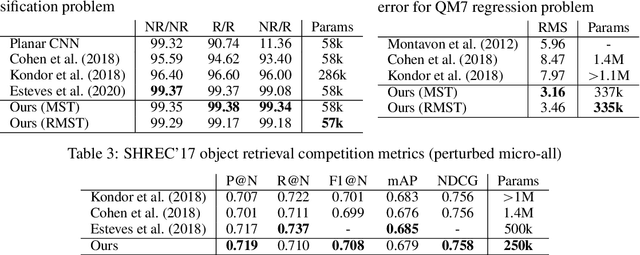
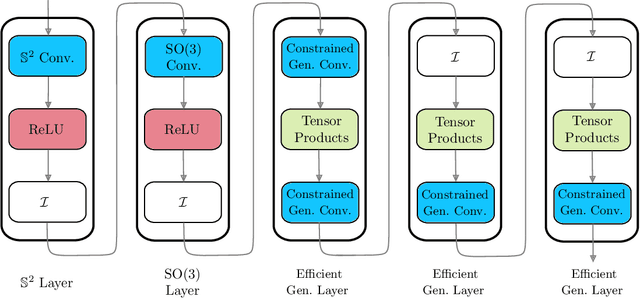
Many problems across computer vision and the natural sciences require the analysis of spherical data, for which representations may be learned efficiently by encoding equivariance to rotational symmetries. We present a generalized spherical CNN framework that encompasses various existing approaches and allows them to be leveraged alongside each other. The only existing non-linear spherical CNN layer that is strictly equivariant has complexity $\mathcal{O}(C^2L^5)$, where $C$ is a measure of representational capacity and $L$ the spherical harmonic bandlimit. Such a high computational cost often prohibits the use of strictly equivariant spherical CNNs. We develop two new strictly equivariant layers with reduced complexity $\mathcal{O}(CL^4)$ and $\mathcal{O}(CL^3 \log L)$, making larger, more expressive models computationally feasible. Moreover, we adopt efficient sampling theory to achieve further computational savings. We show that these developments allow the construction of more expressive hybrid models that achieve state-of-the-art accuracy and parameter efficiency on spherical benchmark problems.