 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArithmetic with Language Models: from Memorization to Computation
Aug 02, 2023A better understanding of the emergent computation and problem-solving capabilities of recent large language models is of paramount importance to further improve them and broaden their applicability. This work investigates how a language model, trained to predict the next token, can perform arithmetic computations generalizing beyond training data. Binary addition and multiplication constitute a good testbed for this purpose, since they require a very small vocabulary and exhibit relevant input/output discontinuities making smooth input interpolation ineffective for novel data. We successfully trained a light language model to learn these tasks and ran a number of experiments to investigate the extrapolation capabilities and internal information processing. Our findings support the hypotheses that the language model works as an Encoding-Regression-Decoding machine where the computation takes place in the value space once the input token representation is mapped to an appropriate internal representation.
Detecting Morphing Attacks via Continual Incremental Training
Jul 27, 2023



Scenarios in which restrictions in data transfer and storage limit the possibility to compose a single dataset -- also exploiting different data sources -- to perform a batch-based training procedure, make the development of robust models particularly challenging. We hypothesize that the recent Continual Learning (CL) paradigm may represent an effective solution to enable incremental training, even through multiple sites. Indeed, a basic assumption of CL is that once a model has been trained, old data can no longer be used in successive training iterations and in principle can be deleted. Therefore, in this paper, we investigate the performance of different Continual Learning methods in this scenario, simulating a learning model that is updated every time a new chunk of data, even of variable size, is available. Experimental results reveal that a particular CL method, namely Learning without Forgetting (LwF), is one of the best-performing algorithms. Then, we investigate its usage and parametrization in Morphing Attack Detection and Object Classification tasks, specifically with respect to the amount of new training data that became available.
Input Layer Binarization with Bit-Plane Encoding
May 04, 2023Binary Neural Networks (BNNs) use 1-bit weights and activations to efficiently execute deep convolutional neural networks on edge devices. Nevertheless, the binarization of the first layer is conventionally excluded, as it leads to a large accuracy loss. The few works addressing the first layer binarization, typically increase the number of input channels to enhance data representation; such data expansion raises the amount of operations needed and it is feasible only on systems with enough computational resources. In this work, we present a new method to binarize the first layer using directly the 8-bit representation of input data; we exploit the standard bit-planes encoding to extract features bit-wise (using depth-wise convolutions); after a re-weighting stage, features are fused again. The resulting model is fully binarized and our first layer binarization approach is model independent. The concept is evaluated on three classification datasets (CIFAR10, SVHN and CIFAR100) for different model architectures (VGG and ResNet) and, the proposed technique outperforms state of the art methods both in accuracy and BMACs reduction.
Region Prediction for Efficient Robot Localization on Large Maps
Mar 01, 2023Recognizing already explored places (a.k.a. place recognition) is a fundamental task in Simultaneous Localization and Mapping (SLAM) to enable robot relocalization and loop closure detection. In topological SLAM the recognition takes place by comparing a signature (or feature vector) associated to the current node with the signatures of the nodes in the known map. However, as the number of nodes increases, matching the current node signature against all the existing ones becomes inefficient and thwarts real-time navigation. In this paper we propose a novel approach to pre-select a subset of map nodes for place recognition. The map nodes are clustered during exploration and each cluster is associated with a region. The region labels become the prediction targets of a deep neural network and, during navigation, only the nodes associated with the regions predicted with high probability are considered for matching. While the proposed technique can be integrated in different SLAM approaches, in this work we describe an effective integration with RTAB-Map (a popular framework for real-time topological SLAM) which allowed us to design and run several experiments to demonstrate its effectiveness. All the code and material from the experiments will be available online at https://github.com/MI-BioLab/region-learner.
On the challenges to learn from Natural Data Streams
Jan 09, 2023



In real-world contexts, sometimes data are available in form of Natural Data Streams, i.e. data characterized by a streaming nature, unbalanced distribution, data drift over a long time frame and strong correlation of samples in short time ranges. Moreover, a clear separation between the traditional training and deployment phases is usually lacking. This data organization and fruition represents an interesting and challenging scenario for both traditional Machine and Deep Learning algorithms and incremental learning agents, i.e. agents that have the ability to incrementally improve their knowledge through the past experience. In this paper, we investigate the classification performance of a variety of algorithms that belong to various research field, i.e. Continual, Streaming and Online Learning, that receives as training input Natural Data Streams. The experimental validation is carried out on three different datasets, expressly organized to replicate this challenging setting.
Architect, Regularize and Replay (ARR): a Flexible Hybrid Approach for Continual Learning
Jan 06, 2023



In recent years we have witnessed a renewed interest in machine learning methodologies, especially for deep representation learning, that could overcome basic i.i.d. assumptions and tackle non-stationary environments subject to various distributional shifts or sample selection biases. Within this context, several computational approaches based on architectural priors, regularizers and replay policies have been proposed with different degrees of success depending on the specific scenario in which they were developed and assessed. However, designing comprehensive hybrid solutions that can flexibly and generally be applied with tunable efficiency-effectiveness trade-offs still seems a distant goal. In this paper, we propose "Architect, Regularize and Replay" (ARR), an hybrid generalization of the renowned AR1 algorithm and its variants, that can achieve state-of-the-art results in classic scenarios (e.g. class-incremental learning) but also generalize to arbitrary data streams generated from real-world datasets such as CIFAR-100, CORe50 and ImageNet-1000.
Morphing Attack Potential
Apr 28, 2022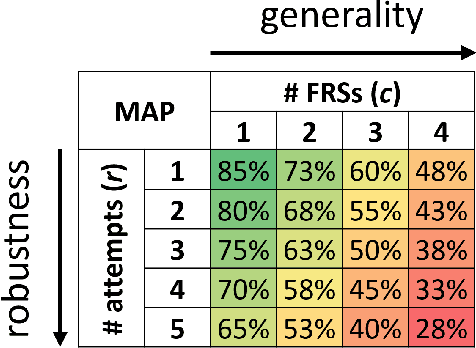
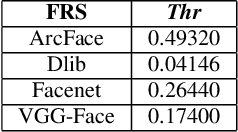
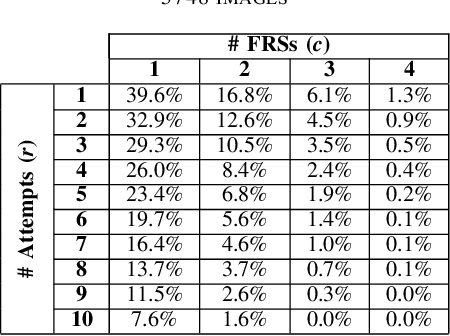
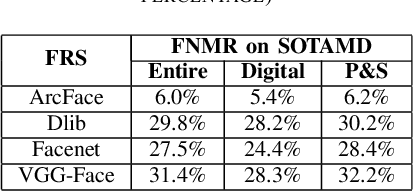
In security systems the risk assessment in the sense of common criteria testing is a very relevant topic; this requires quantifying the attack potential in terms of the expertise of the attacker, his knowledge about the target and access to equipment. Contrary to those attacks, the recently revealed morphing attacks against Face Recognition Systems (FRSs) can not be assessed by any of the above criteria. But not all morphing techniques pose the same risk for an operational face recognition system. This paper introduces with the Morphing Attack Potential (MAP) a consistent methodology, that can quantify the risk, which a certain morphing attack creates.
Generative Negative Replay for Continual Learning
Apr 12, 2022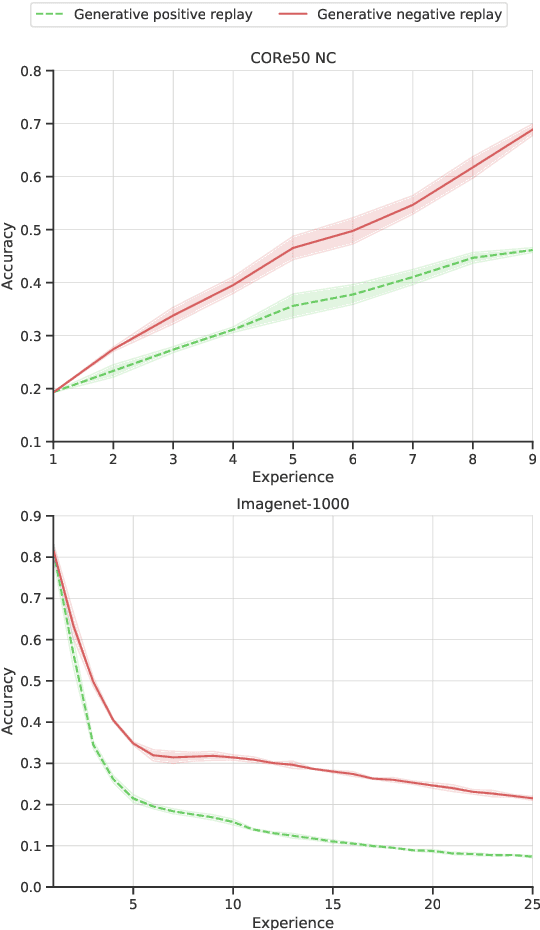
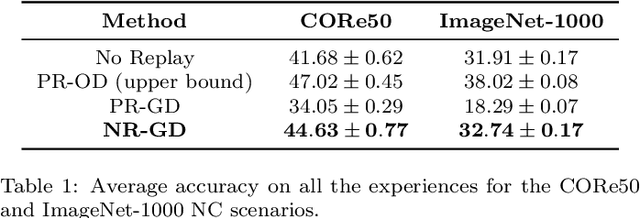

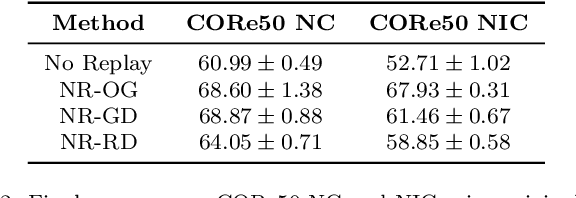
Learning continually is a key aspect of intelligence and a necessary ability to solve many real-life problems. One of the most effective strategies to control catastrophic forgetting, the Achilles' heel of continual learning, is storing part of the old data and replaying them interleaved with new experiences (also known as the replay approach). Generative replay, which is using generative models to provide replay patterns on demand, is particularly intriguing, however, it was shown to be effective mainly under simplified assumptions, such as simple scenarios and low-dimensional data. In this paper, we show that, while the generated data are usually not able to improve the classification accuracy for the old classes, they can be effective as negative examples (or antagonists) to better learn the new classes, especially when the learning experiences are small and contain examples of just one or few classes. The proposed approach is validated on complex class-incremental and data-incremental continual learning scenarios (CORe50 and ImageNet-1000) composed of high-dimensional data and a large number of training experiences: a setup where existing generative replay approaches usually fail.
Is Class-Incremental Enough for Continual Learning?
Dec 06, 2021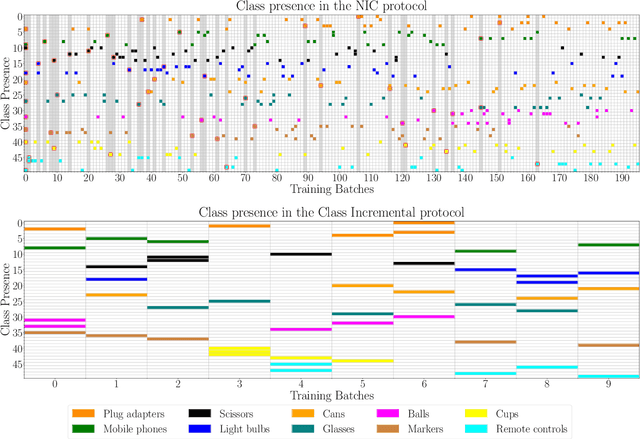
The ability of a model to learn continually can be empirically assessed in different continual learning scenarios. Each scenario defines the constraints and the opportunities of the learning environment. Here, we challenge the current trend in the continual learning literature to experiment mainly on class-incremental scenarios, where classes present in one experience are never revisited. We posit that an excessive focus on this setting may be limiting for future research on continual learning, since class-incremental scenarios artificially exacerbate catastrophic forgetting, at the expense of other important objectives like forward transfer and computational efficiency. In many real-world environments, in fact, repetition of previously encountered concepts occurs naturally and contributes to softening the disruption of previous knowledge. We advocate for a more in-depth study of alternative continual learning scenarios, in which repetition is integrated by design in the stream of incoming information. Starting from already existing proposals, we describe the advantages such class-incremental with repetition scenarios could offer for a more comprehensive assessment of continual learning models.
Continual Learning at the Edge: Real-Time Training on Smartphone Devices
May 24, 2021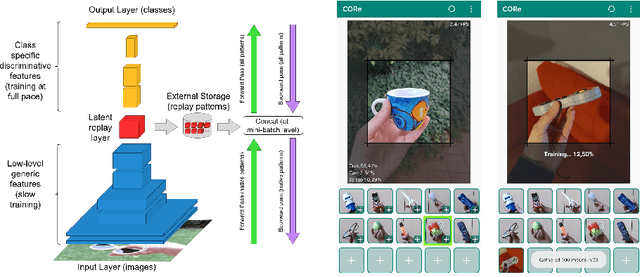
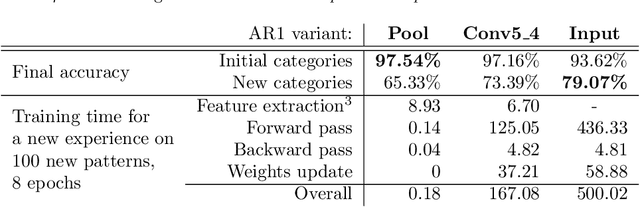
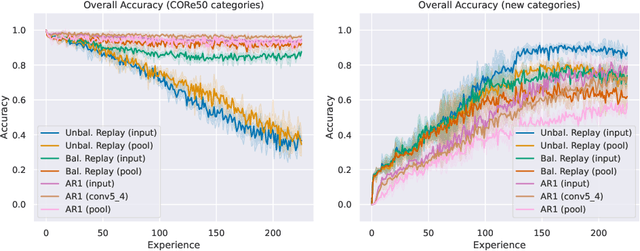
On-device training for personalized learning is a challenging research problem. Being able to quickly adapt deep prediction models at the edge is necessary to better suit personal user needs. However, adaptation on the edge poses some questions on both the efficiency and sustainability of the learning process and on the ability to work under shifting data distributions. Indeed, naively fine-tuning a prediction model only on the newly available data results in catastrophic forgetting, a sudden erasure of previously acquired knowledge. In this paper, we detail the implementation and deployment of a hybrid continual learning strategy (AR1*) on a native Android application for real-time on-device personalization without forgetting. Our benchmark, based on an extension of the CORe50 dataset, shows the efficiency and effectiveness of our solution.