 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable-by-design Semi-Supervised Representation Learning for COVID-19 Diagnosis from CT Imaging
Dec 02, 2020
Our motivating application is a real-world problem: COVID-19 classification from CT imaging, for which we present an explainable Deep Learning approach based on a semi-supervised classification pipeline that employs variational autoencoders to extract efficient feature embedding. We have optimized the architecture of two different networks for CT images: (i) a novel conditional variational autoencoder (CVAE) with a specific architecture that integrates the class labels inside the encoder layers and uses side information with shared attention layers for the encoder, which make the most of the contextual clues for representation learning, and (ii) a downstream convolutional neural network for supervised classification using the encoder structure of the CVAE. With the explainable classification results, the proposed diagnosis system is very effective for COVID-19 classification. Based on the promising results obtained qualitatively and quantitatively, we envisage a wide deployment of our developed technique in large-scale clinical studies.Code is available at https://git.etrovub.be/AVSP/ct-based-covid-19-diagnostic-tool.git.
Unsupervised 3D Brain Anomaly Detection
Oct 09, 2020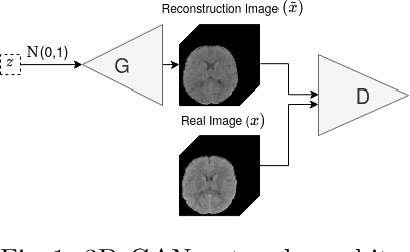
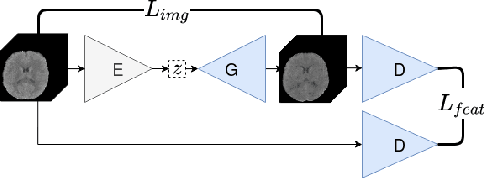
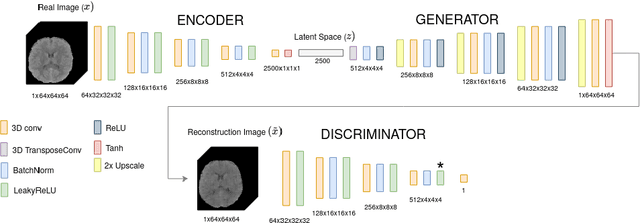
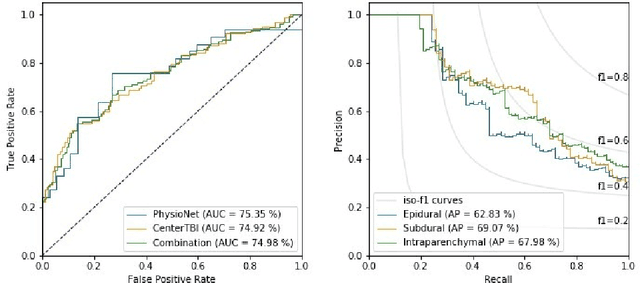
Anomaly detection (AD) is the identification of data samples that do not fit a learned data distribution. As such, AD systems can help physicians to determine the presence, severity, and extension of a pathology. Deep generative models, such as Generative Adversarial Networks (GANs), can be exploited to capture anatomical variability. Consequently, any outlier (i.e., sample falling outside of the learned distribution) can be detected as an abnormality in an unsupervised fashion. By using this method, we can not only detect expected or known lesions, but we can even unveil previously unrecognized biomarkers. To the best of our knowledge, this study exemplifies the first AD approach that can efficiently handle volumetric data and detect 3D brain anomalies in one single model. Our proposal is a volumetric and high-detail extension of the 2D f-AnoGAN model obtained by combining a state-of-the-art 3D GAN with refinement training steps. In experiments using non-contrast computed tomography images from traumatic brain injury (TBI) patients, the model detects and localizes TBI abnormalities with an area under the ROC curve of ~75%. Moreover, we test the potential of the method for detecting other anomalies such as low quality images, preprocessing inaccuracies, artifacts, and even the presence of post-operative signs (such as a craniectomy or a brain shunt). The method has potential for rapidly labeling abnormalities in massive imaging datasets, as well as identifying new biomarkers.
AIFNet: Automatic Vascular Function Estimation for Perfusion Analysis Using Deep Learning
Oct 04, 2020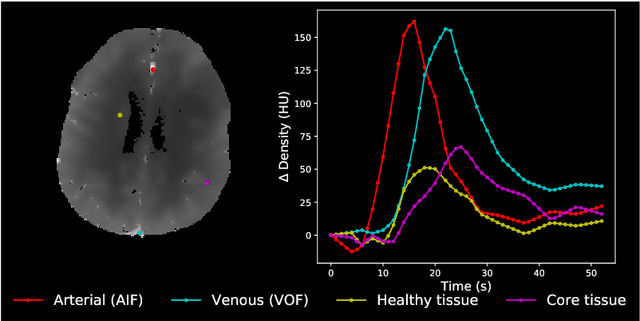

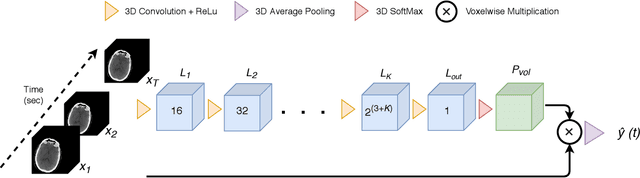
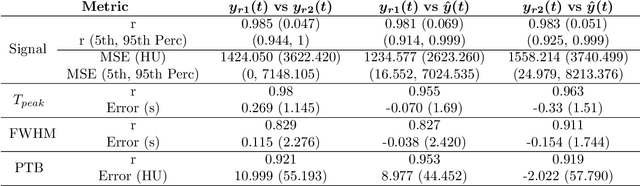
Perfusion imaging is crucial in acute ischemic stroke for quantifying the salvageable penumbra and irreversibly damaged core lesions. As such, it helps clinicians to decide on the optimal reperfusion treatment. In perfusion CT imaging, deconvolution methods are used to obtain clinically interpretable perfusion parameters that allow identifying brain tissue abnormalities. Deconvolution methods require the selection of two reference vascular functions as inputs to the model: the arterial input function (AIF) and the venous output function, with the AIF as the most critical model input. When manually performed, the vascular function selection is time demanding, suffers from poor reproducibility and is subject to the professionals' experience. This leads to potentially unreliable quantification of the penumbra and core lesions and, hence, might harm the treatment decision process. In this work we automatize the perfusion analysis with AIFNet, a fully automatic and end-to-end trainable deep learning approach for estimating the vascular functions. Unlike previous methods using clustering or segmentation techniques to select vascular voxels, AIFNet is directly optimized at the vascular function estimation, which allows to better recognise the time-curve profiles. Validation on the public ISLES18 stroke database shows that AIFNet reaches inter-rater performance for the vascular function estimation and, subsequently, for the parameter maps and core lesion quantification obtained through deconvolution. We conclude that AIFNet has potential for clinical transfer and could be incorporated in perfusion deconvolution software.
Comparative study of deep learning methods for the automatic segmentation of lung, lesion and lesion type in CT scans of COVID-19 patients
Aug 21, 2020
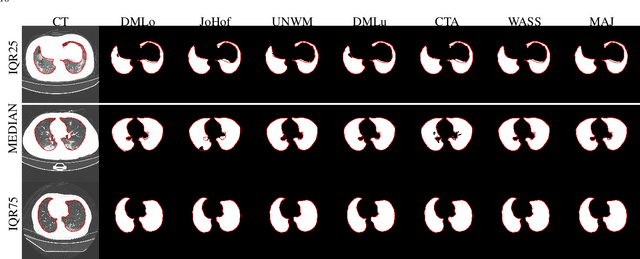
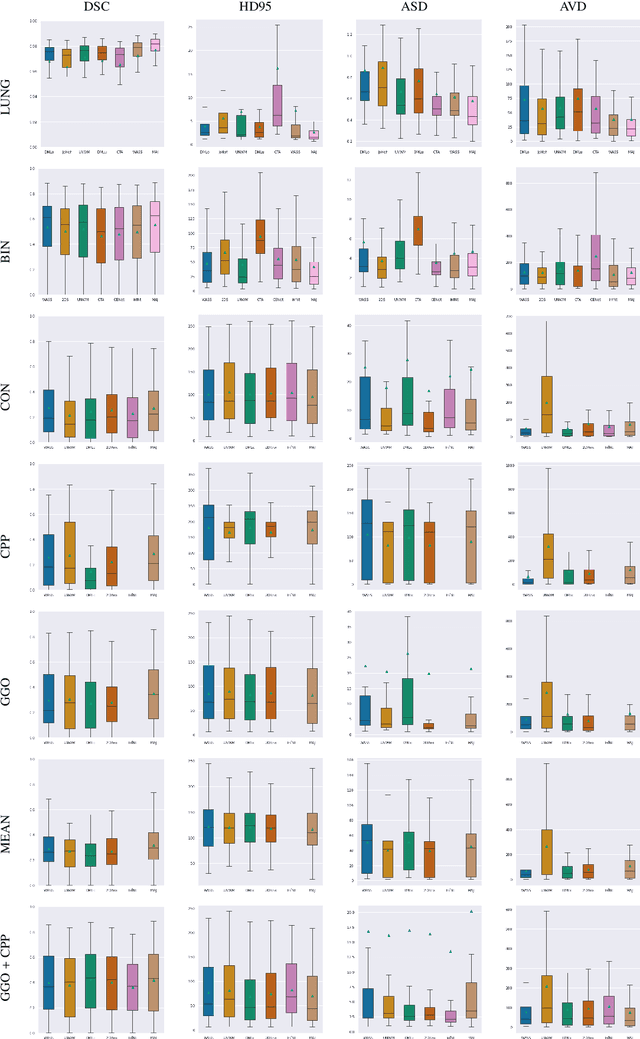
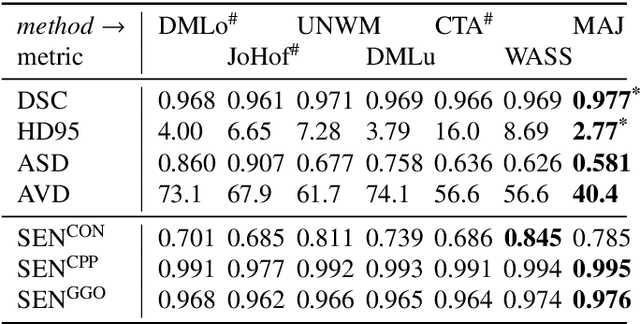
Recent research on COVID-19 suggests that CT imaging provides useful information to assess disease progression and assist diagnosis, in addition to help understanding the disease. There is an increasing number of studies that propose to use deep learning to provide fast and accurate quantification of COVID-19 using chest CT scans. The main tasks of interest are the automatic segmentation of lung and lung lesions in chest CT scans of confirmed or suspected COVID-19 patients. In this study, we compare twelve deep learning algorithms using a multi-center dataset, including both open-source and in-house developed algorithms. Results show that ensembling different methods can boost the overall test set performance for lung segmentation, binary lesion segmentation and multiclass lesion segmentation, resulting in mean Dice scores of 0.982, 0.724 and 0.469, respectively. The resulting binary lesions were segmented with a mean absolute volume error of 91.3 ml. In general, the task of distinguishing different lesion types was more difficult, with a mean absolute volume difference of 152 ml and mean Dice scores of 0.369 and 0.523 for consolidation and ground glass opacity, respectively. All methods perform binary lesion segmentation with an average volume error that is better than visual assessment by human raters, suggesting these methods are mature enough for a large-scale evaluation for use in clinical practice.
Improved inter-scanner MS lesion segmentation by adversarial training on longitudinal data
Feb 03, 2020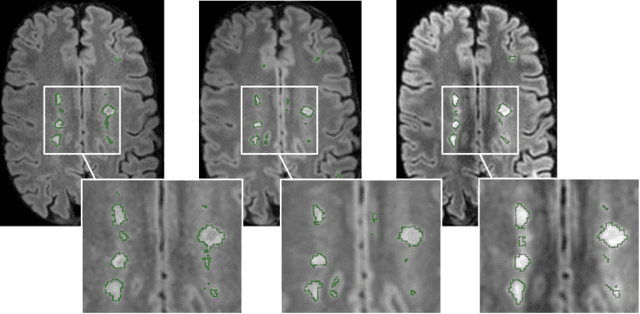
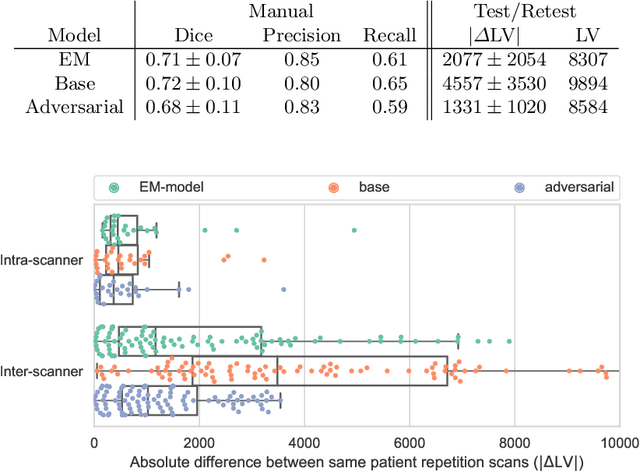
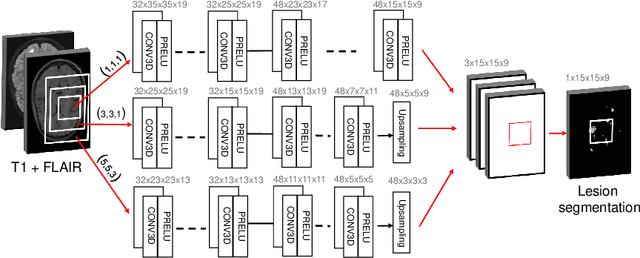
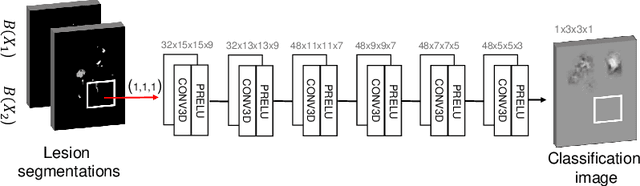
The evaluation of white matter lesion progression is an important biomarker in the follow-up of MS patients and plays a crucial role when deciding the course of treatment. Current automated lesion segmentation algorithms are susceptible to variability in image characteristics related to MRI scanner or protocol differences. We propose a model that improves the consistency of MS lesion segmentations in inter-scanner studies. First, we train a CNN base model to approximate the performance of icobrain, an FDA-approved clinically available lesion segmentation software. A discriminator model is then trained to predict if two lesion segmentations are based on scans acquired using the same scanner type or not, achieving a 78% accuracy in this task. Finally, the base model and the discriminator are trained adversarially on multi-scanner longitudinal data to improve the inter-scanner consistency of the base model. The performance of the models is evaluated on an unseen dataset containing manual delineations. The inter-scanner variability is evaluated on test-retest data, where the adversarial network produces improved results over the base model and the FDA-approved solution.
Optimization with soft Dice can lead to a volumetric bias
Nov 06, 2019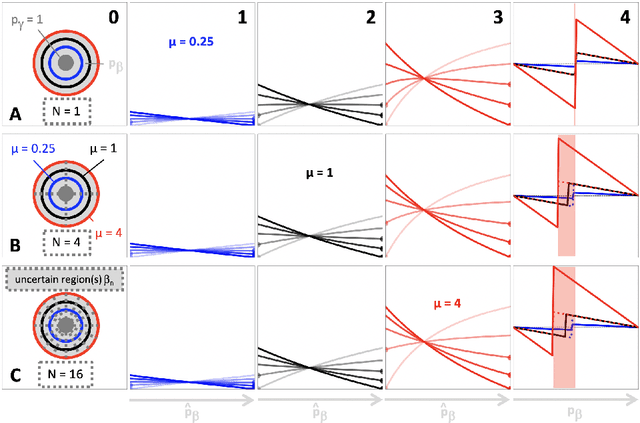

Segmentation is a fundamental task in medical image analysis. The clinical interest is often to measure the volume of a structure. To evaluate and compare segmentation methods, the similarity between a segmentation and a predefined ground truth is measured using metrics such as the Dice score. Recent segmentation methods based on convolutional neural networks use a differentiable surrogate of the Dice score, such as soft Dice, explicitly as the loss function during the learning phase. Even though this approach leads to improved Dice scores, we find that, both theoretically and empirically on four medical tasks, it can introduce a volumetric bias for tasks with high inherent uncertainty. As such, this may limit the method's clinical applicability.
Detection of vertebral fractures in CT using 3D Convolutional Neural Networks
Nov 05, 2019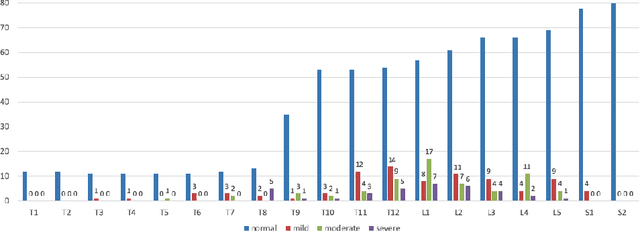
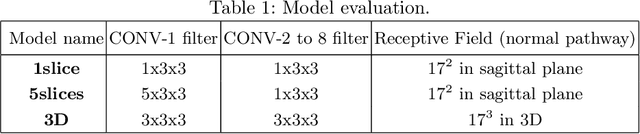
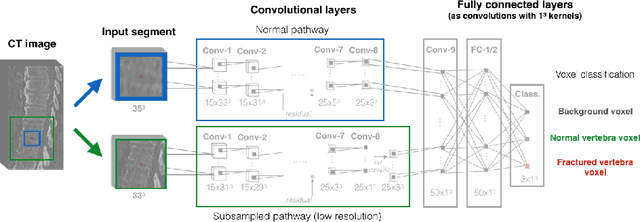
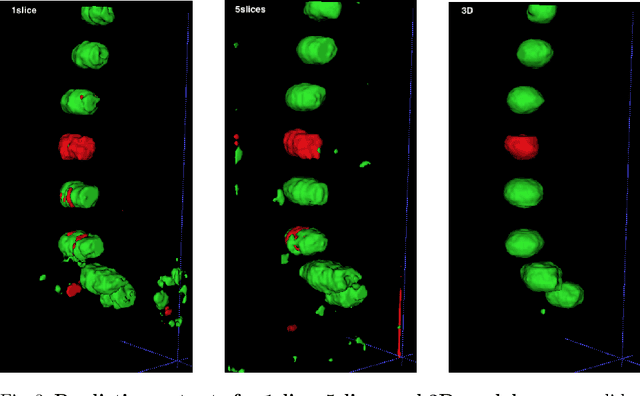
Osteoporosis induced fractures occur worldwide about every 3 seconds. Vertebral compression fractures are early signs of the disease and considered risk predictors for secondary osteoporotic fractures. We present a detection method to opportunistically screen spine-containing CT images for the presence of these vertebral fractures. Inspired by radiology practice, existing methods are based on 2D and 2.5D features but we present, to the best of our knowledge, the first method for detecting vertebral fractures in CT using automatically learned 3D feature maps. The presented method explicitly localizes these fractures allowing radiologists to interpret its results. We train a voxel-classification 3D Convolutional Neural Network (CNN) with a training database of 90 cases that has been semi-automatically generated using radiologist readings that are readily available in clinical practice. Our 3D method produces an Area Under the Curve (AUC) of 95% for patient-level fracture detection and an AUC of 93% for vertebra-level fracture detection in a five-fold cross-validation experiment.
Prediction of final infarct volume from native CT perfusion and treatment parameters using deep learning
Dec 06, 2018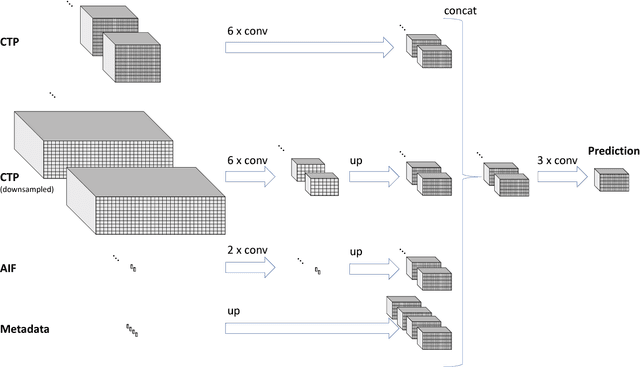
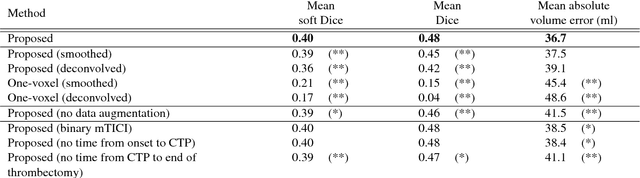
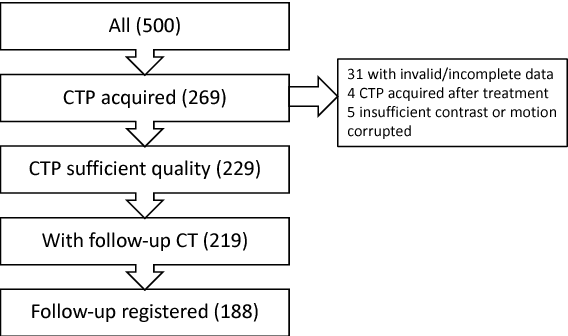
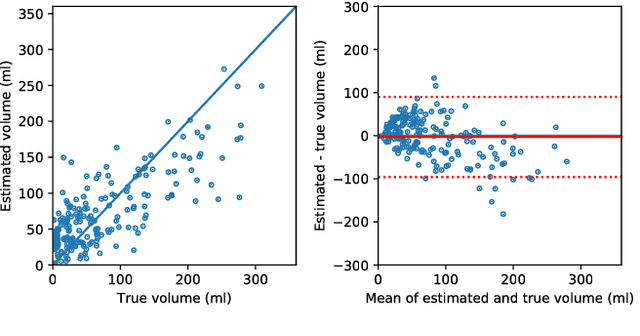
CT Perfusion (CTP) imaging has gained importance in the diagnosis of acute stroke. Conventional perfusion analysis performs a deconvolution of the measurements and thresholds the perfusion parameters to determine the tissue status. We pursue a data-driven and deconvolution-free approach, where a deep neural network learns to predict the final infarct volume directly from the native CTP images and metadata such as the time parameters and treatment. This would allow clinicians to simulate various treatments and gain insight into predicted tissue status over time. We demonstrate on a multicenter dataset that our approach is able to predict the final infarct and effectively uses the metadata. An ablation study shows that using the native CTP measurements instead of the deconvolved measurements improves the prediction.
Perfusion parameter estimation using neural networks and data augmentation
Oct 11, 2018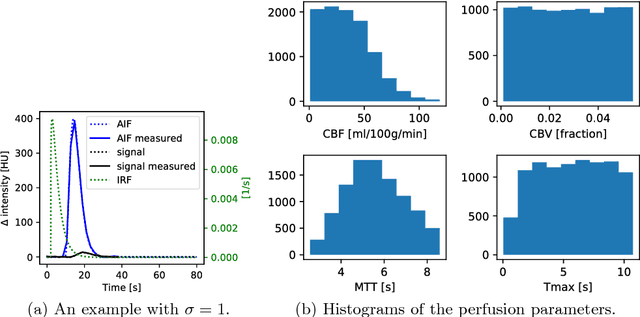
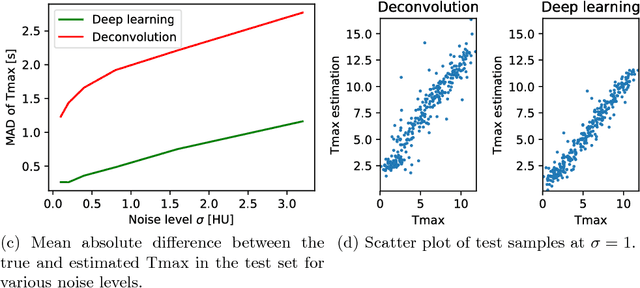
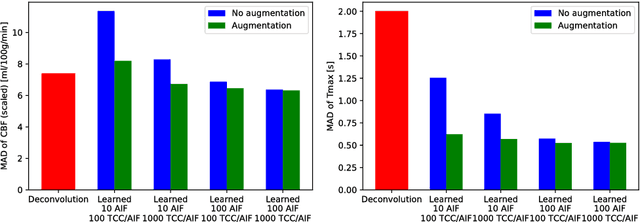
Perfusion imaging plays a crucial role in acute stroke diagnosis and treatment decision making. Current perfusion analysis relies on deconvolution of the measured signals, an operation that is mathematically ill-conditioned and requires strong regularization. We propose a neural network and a data augmentation approach to predict perfusion parameters directly from the native measurements. A comparison on simulated CT Perfusion data shows that the neural network provides better estimations for both CBF and Tmax than a state of the art deconvolution method, and this over a wide range of noise levels. The proposed data augmentation enables to achieve these results with less than 100 datasets.