 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Deep Reinforcement Learning
Jun 28, 2018
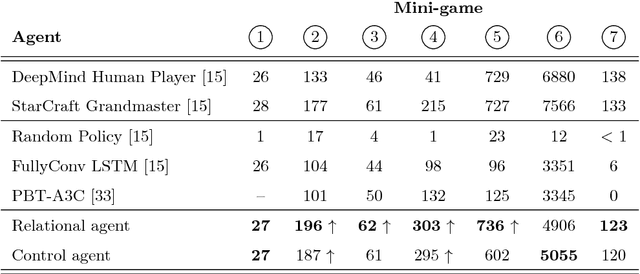
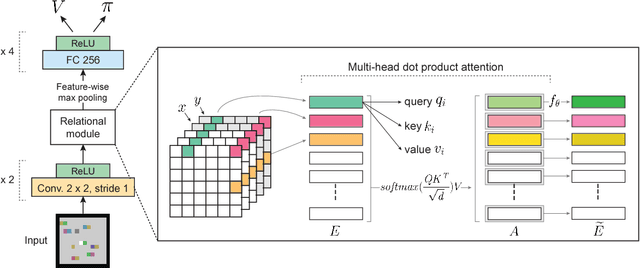
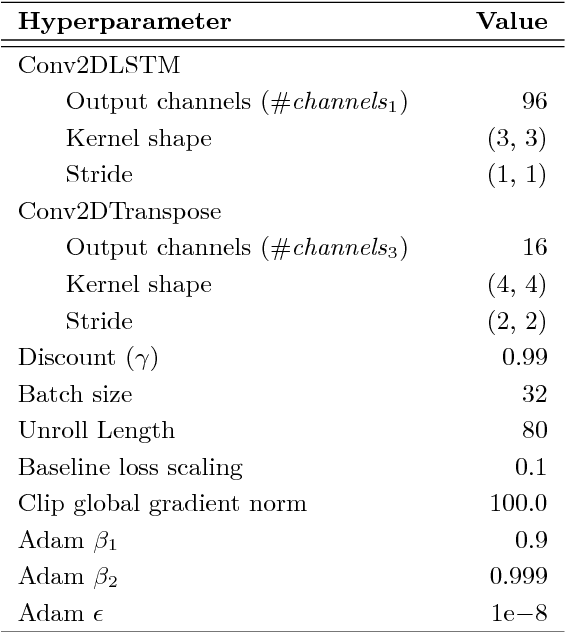
We introduce an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. Our results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance. In the StarCraft II Learning Environment, our agent achieves state-of-the-art performance on six mini-games -- surpassing human grandmaster performance on four. By considering architectural inductive biases, our work opens new directions for overcoming important, but stubborn, challenges in deep RL.
Hyperbolic Attention Networks
May 24, 2018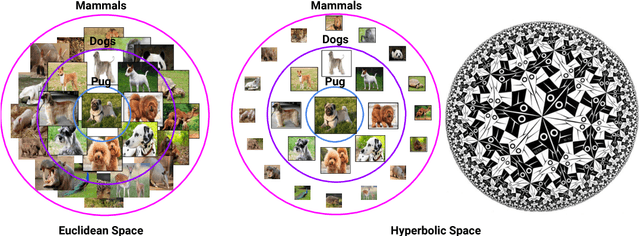
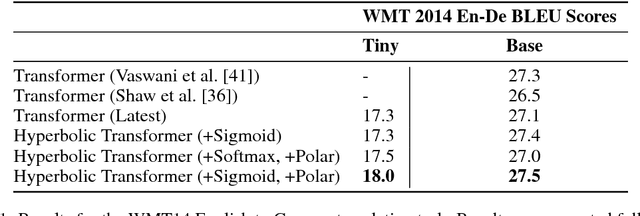
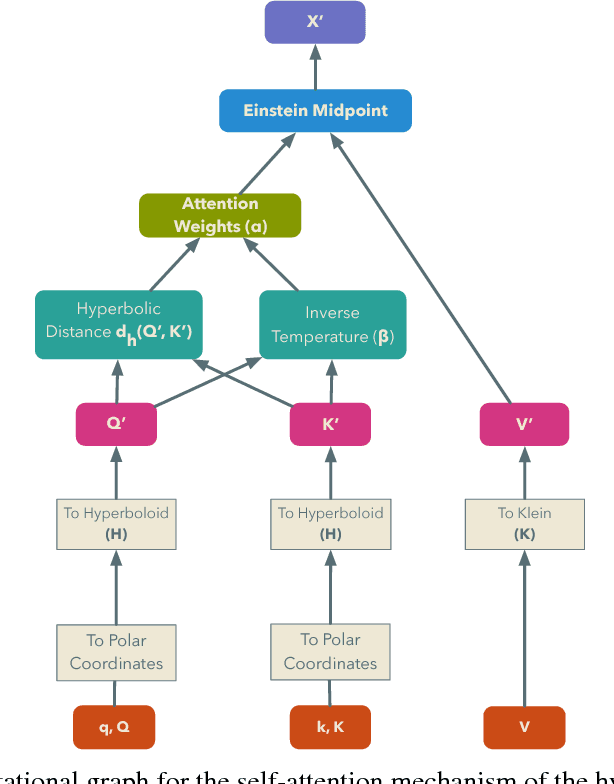
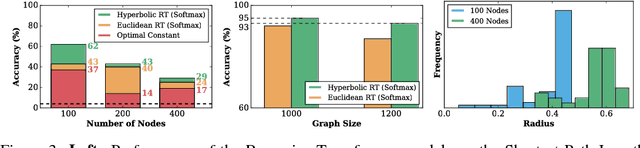
We introduce hyperbolic attention networks to endow neural networks with enough capacity to match the complexity of data with hierarchical and power-law structure. A few recent approaches have successfully demonstrated the benefits of imposing hyperbolic geometry on the parameters of shallow networks. We extend this line of work by imposing hyperbolic geometry on the activations of neural networks. This allows us to exploit hyperbolic geometry to reason about embeddings produced by deep networks. We achieve this by re-expressing the ubiquitous mechanism of soft attention in terms of operations defined for hyperboloid and Klein models. Our method shows improvements in terms of generalization on neural machine translation, learning on graphs and visual question answering tasks while keeping the neural representations compact.
A simple neural network module for relational reasoning
Jun 05, 2017
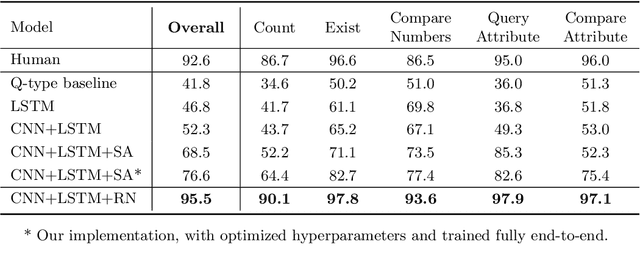
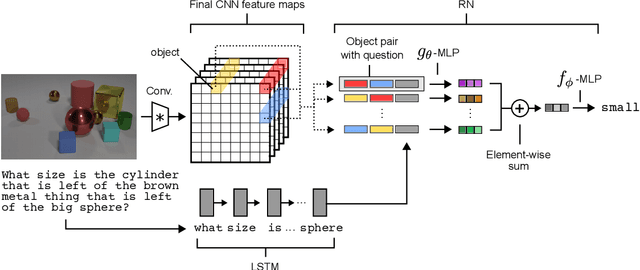

Relational reasoning is a central component of generally intelligent behavior, but has proven difficult for neural networks to learn. In this paper we describe how to use Relation Networks (RNs) as a simple plug-and-play module to solve problems that fundamentally hinge on relational reasoning. We tested RN-augmented networks on three tasks: visual question answering using a challenging dataset called CLEVR, on which we achieve state-of-the-art, super-human performance; text-based question answering using the bAbI suite of tasks; and complex reasoning about dynamic physical systems. Then, using a curated dataset called Sort-of-CLEVR we show that powerful convolutional networks do not have a general capacity to solve relational questions, but can gain this capacity when augmented with RNs. Our work shows how a deep learning architecture equipped with an RN module can implicitly discover and learn to reason about entities and their relations.
Discovering objects and their relations from entangled scene representations
Feb 16, 2017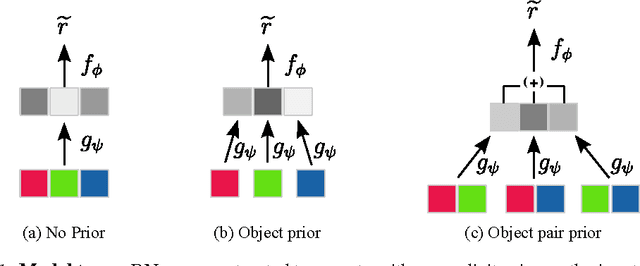
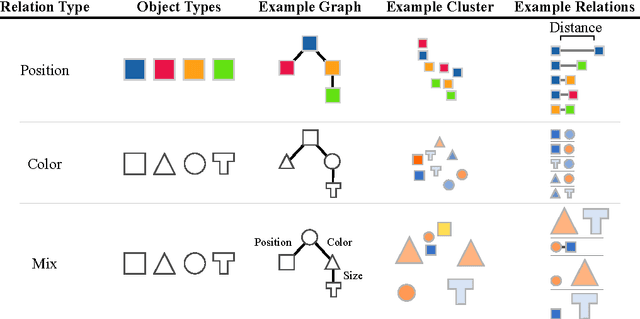
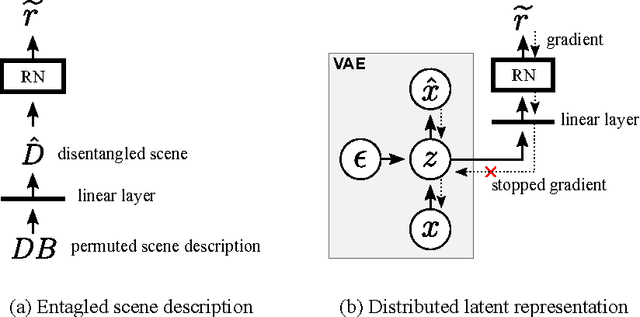
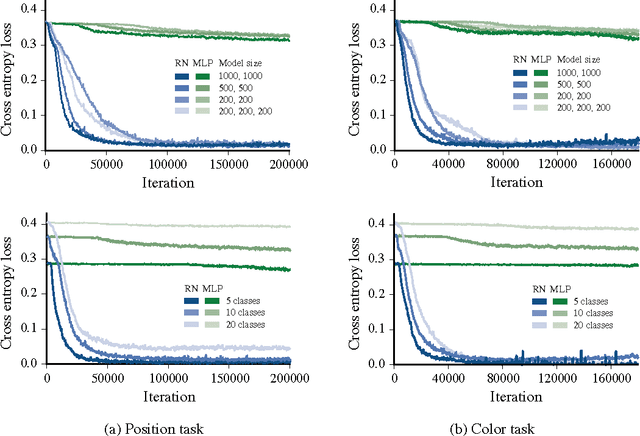
Our world can be succinctly and compactly described as structured scenes of objects and relations. A typical room, for example, contains salient objects such as tables, chairs and books, and these objects typically relate to each other by their underlying causes and semantics. This gives rise to correlated features, such as position, function and shape. Humans exploit knowledge of objects and their relations for learning a wide spectrum of tasks, and more generally when learning the structure underlying observed data. In this work, we introduce relation networks (RNs) - a general purpose neural network architecture for object-relation reasoning. We show that RNs are capable of learning object relations from scene description data. Furthermore, we show that RNs can act as a bottleneck that induces the factorization of objects from entangled scene description inputs, and from distributed deep representations of scene images provided by a variational autoencoder. The model can also be used in conjunction with differentiable memory mechanisms for implicit relation discovery in one-shot learning tasks. Our results suggest that relation networks are a potentially powerful architecture for solving a variety of problems that require object relation reasoning.