 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard to See, Hard to Label: Generative and Symbolic Acquisition for Subtle Visual Phenomena
Apr 28, 2026Subtle visual anomalies such as hairline cracks, sub-millimeter voids, and low-contrast inclusions are structurally atypical yet visually ambiguous, making them both difficult to annotate and easy to overlook during active learning. Standard acquisition heuristics based on discriminative uncertainty or feature diversity often overselect dominant patterns while underexploring sparse yet important regions of the data space. This failure mode is especially severe in industrial defect inspection, where anomalies may be both low-prevalence and difficult to distinguish from surrounding structure. To resolve this, we propose GSAL, an active learning framework for object detection that combines a diffusion-based difficulty signal with a hierarchical semantic coverage prior. The diffusion component scores images and proposals using reconstruction discrepancy and denoising variability, prioritizing visually atypical or ambiguous examples. However, diffusion alone does not prevent acquisition from repeatedly favoring hard samples within dominant semantic modes. The semantic component therefore organizes candidate samples in a three-level concept graph and promotes coverage of underrepresented semantic regions while providing interpretable acquisition rationales. By balancing visual difficulty with semantic coverage, GSAL improves retrieval of subtle and rare targets that are often missed by uncertainty-only selection. Experiments on a proprietary thin-film defect, Pascal VOC and MS COCO dataset show consistent gains in label efficiency and rare-class retrieval over uncertainty-, diversity-, and hybrid-based baselines
The Data Fusion Labeler (dFL): Challenges and Solutions to Data Harmonization, Labeling, and Provenance in Fusion Energy
Nov 12, 2025Fusion energy research increasingly depends on the ability to integrate heterogeneous, multimodal datasets from high-resolution diagnostics, control systems, and multiscale simulations. The sheer volume and complexity of these datasets demand the development of new tools capable of systematically harmonizing and extracting knowledge across diverse modalities. The Data Fusion Labeler (dFL) is introduced as a unified workflow instrument that performs uncertainty-aware data harmonization, schema-compliant data fusion, and provenance-rich manual and automated labeling at scale. By embedding alignment, normalization, and labeling within a reproducible, operator-order-aware framework, dFL reduces time-to-analysis by greater than 50X (e.g., enabling >200 shots/hour to be consistently labeled rather than a handful per day), enhances label (and subsequently training) quality, and enables cross-device comparability. Case studies from DIII-D demonstrate its application to automated ELM detection and confinement regime classification, illustrating its potential as a core component of data-driven discovery, model validation, and real-time control in future burning plasma devices.
OOWL500: Overcoming Dataset Collection Bias in the Wild
Aug 24, 2021
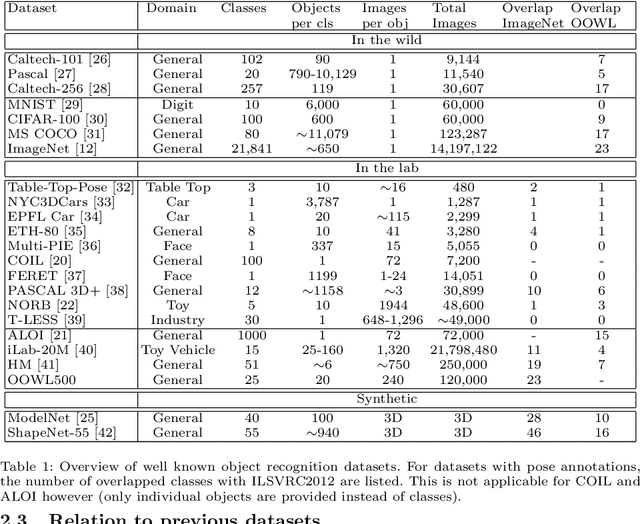

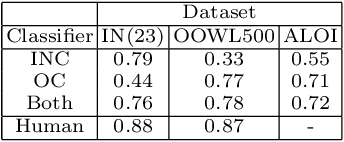
The hypothesis that image datasets gathered online "in the wild" can produce biased object recognizers, e.g. preferring professional photography or certain viewing angles, is studied. A new "in the lab" data collection infrastructure is proposed consisting of a drone which captures images as it circles around objects. Crucially, the control provided by this setup and the natural camera shake inherent to flight mitigate many biases. It's inexpensive and easily replicable nature may also potentially lead to a scalable data collection effort by the vision community. The procedure's usefulness is demonstrated by creating a dataset of Objects Obtained With fLight (OOWL). Denoted as OOWL500, it contains 120,000 images of 500 objects and is the largest "in the lab" image dataset available when both number of classes and objects per class are considered. Furthermore, it has enabled several of new insights on object recognition. First, a novel adversarial attack strategy is proposed, where image perturbations are defined in terms of semantic properties such as camera shake and pose. Indeed, experiments have shown that ImageNet has considerable amounts of pose and professional photography bias. Second, it is used to show that the augmentation of in the wild datasets, such as ImageNet, with in the lab data, such as OOWL500, can significantly decrease these biases, leading to object recognizers of improved generalization. Third, the dataset is used to study questions on "best procedures" for dataset collection. It is revealed that data augmentation with synthetic images does not suffice to eliminate in the wild datasets biases, and that camera shake and pose diversity play a more important role in object recognition robustness than previously thought.