 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversation Group Detection With Spatio-Temporal Context
Jun 02, 2022
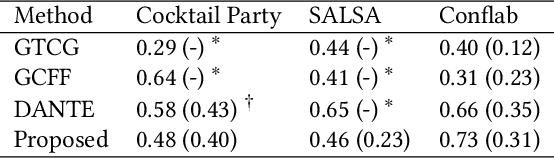

In this work, we propose an approach for detecting conversation groups in social scenarios like cocktail parties and networking events, from overhead camera recordings. We posit the detection of conversation groups as a learning problem that could benefit from leveraging the spatial context of the surroundings, and the inherent temporal context in interpersonal dynamics which is reflected in the temporal dynamics in human behavior signals, an aspect that has not been addressed in recent prior works. This motivates our approach which consists of a dynamic LSTM-based deep learning model that predicts continuous pairwise affinity values indicating how likely two people are in the same conversation group. These affinity values are also continuous in time, since relationships and group membership do not occur instantaneously, even though the ground truths of group membership are binary. Using the predicted affinity values, we apply a graph clustering method based on Dominant Set extraction to identify the conversation groups. We benchmark the proposed method against established methods on multiple social interaction datasets. Our results showed that the proposed method improves group detection performance in data that has more temporal granularity in conversation group labels. Additionally, we provide an analysis in the predicted affinity values in relation to the conversation group detection. Finally, we demonstrate the usability of the predicted affinity values in a forecasting framework to predict group membership for a given forecast horizon.
Neural network relief: a pruning algorithm based on neural activity
Sep 22, 2021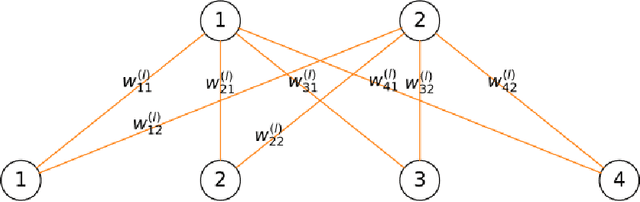
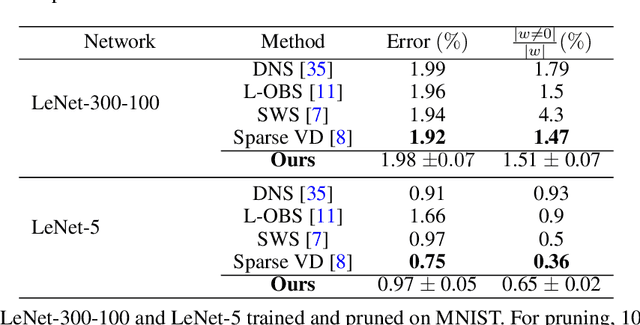

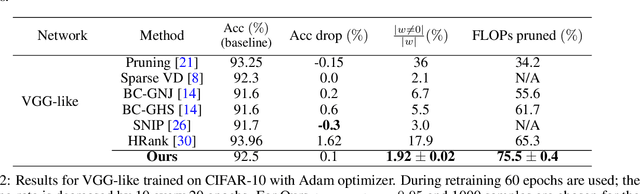
Current deep neural networks (DNNs) are overparameterized and use most of their neuronal connections during inference for each task. The human brain, however, developed specialized regions for different tasks and performs inference with a small fraction of its neuronal connections. We propose an iterative pruning strategy introducing a simple importance-score metric that deactivates unimportant connections, tackling overparameterization in DNNs and modulating the firing patterns. The aim is to find the smallest number of connections that is still capable of solving a given task with comparable accuracy, i.e. a simpler subnetwork. We achieve comparable performance for LeNet architectures on MNIST, and significantly higher parameter compression than state-of-the-art algorithms for VGG and ResNet architectures on CIFAR-10/100 and Tiny-ImageNet. Our approach also performs well for the two different optimizers considered -- Adam and SGD. The algorithm is not designed to minimize FLOPs when considering current hardware and software implementations, although it performs reasonably when compared to the state of the art.
A Brief Prehistory of Double Descent
Apr 07, 2020In their thought-provoking paper [1], Belkin et al. illustrate and discuss the shape of risk curves in the context of modern high-complexity learners. Given a fixed training sample size $n$, such curves show the risk of a learner as a function of some (approximate) measure of its complexity $N$. With $N$ the number of features, these curves are also referred to as feature curves. A salient observation in [1] is that these curves can display, what they call, double descent: with increasing $N$, the risk initially decreases, attains a minimum, and then increases until $N$ equals $n$, where the training data is fitted perfectly. Increasing $N$ even further, the risk decreases a second and final time, creating a peak at $N=n$. This twofold descent may come as a surprise, but as opposed to what [1] reports, it has not been overlooked historically. Our letter draws attention to some original, earlier findings, of interest to contemporary machine learning.
Characterizing multiple instance datasets
Jun 21, 2018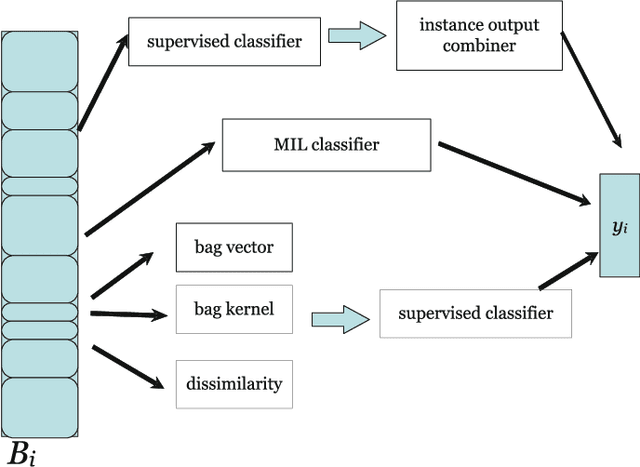
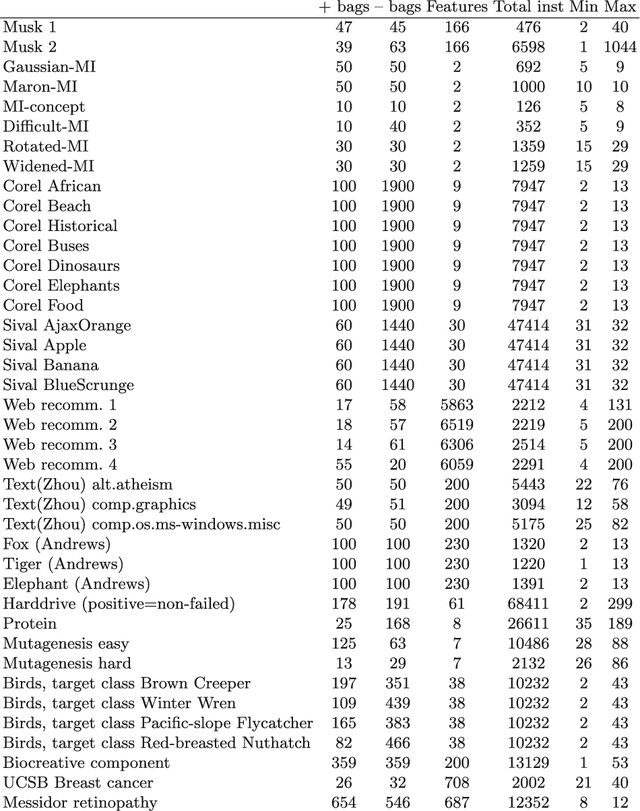
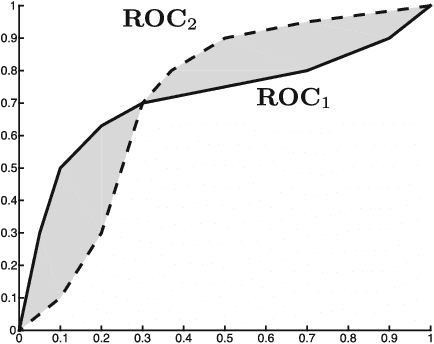
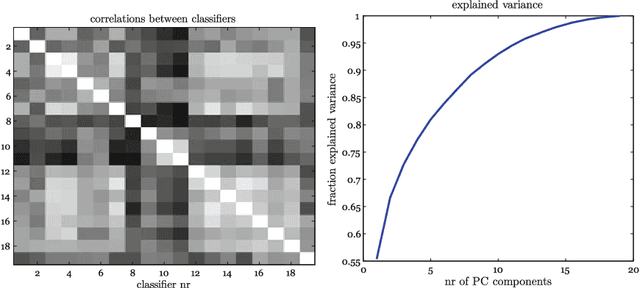
In many pattern recognition problems, a single feature vector is not sufficient to describe an object. In multiple instance learning (MIL), objects are represented by sets (\emph{bags}) of feature vectors (\emph{instances}). This requires an adaptation of standard supervised classifiers in order to train and evaluate on these bags of instances. Like for supervised classification, several benchmark datasets and numerous classifiers are available for MIL. When performing a comparison of different MIL classifiers, it is important to understand the differences of the datasets, used in the comparison. Seemingly different (based on factors such as dimensionality) datasets may elicit very similar behaviour in classifiers, and vice versa. This has implications for what kind of conclusions may be drawn from the comparison results. We aim to give an overview of the variability of available benchmark datasets and some popular MIL classifiers. We use a dataset dissimilarity measure, based on the differences between the ROC-curves obtained by different classifiers, and embed this dataset dissimilarity matrix into a low-dimensional space. Our results show that conceptually similar datasets can behave very differently. We therefore recommend examining such dataset characteristics when making comparisons between existing and new MIL classifiers. The datasets are available via Figshare at \url{https://bit.ly/2K9iTja}.
Unsupervised Learning of Sequence Representations by Autoencoders
Apr 26, 2018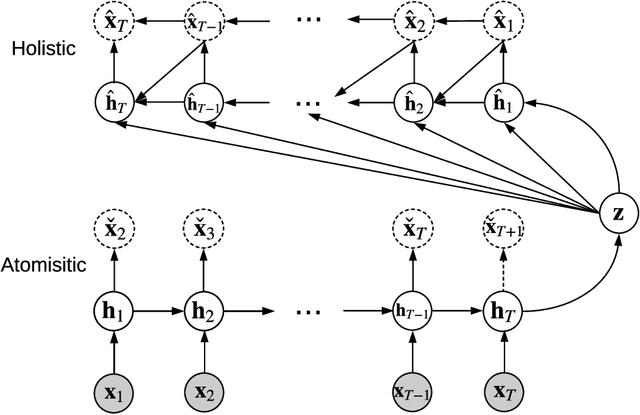
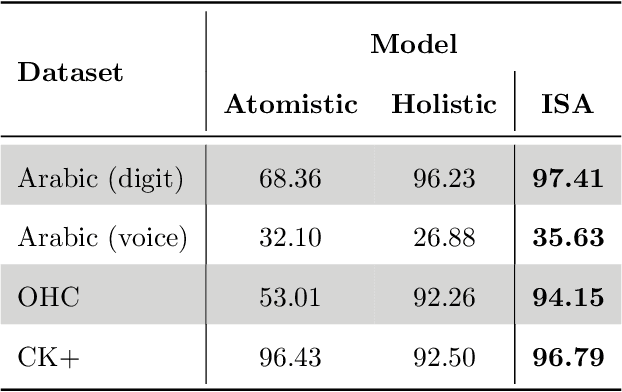
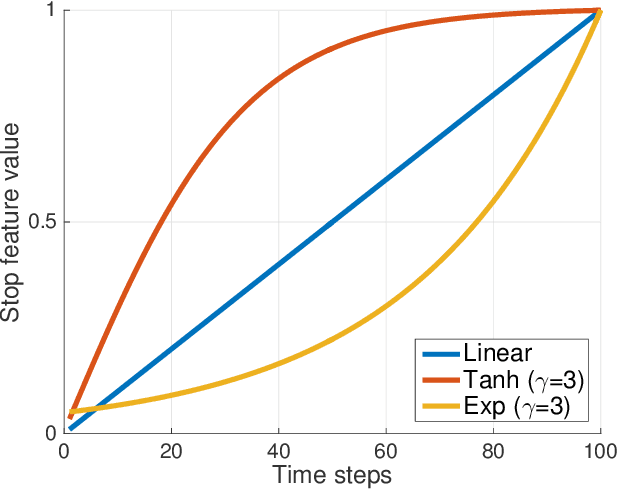
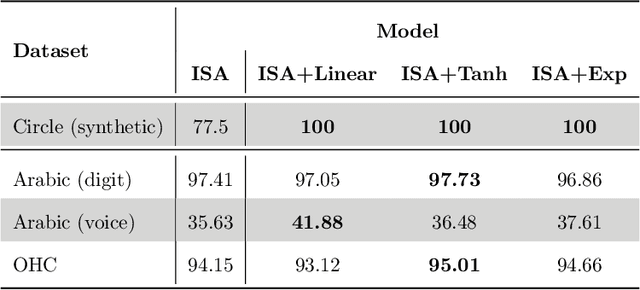
Sequence data is challenging for machine learning approaches, because the lengths of the sequences may vary between samples. In this paper, we present an unsupervised learning model for sequence data, called the Integrated Sequence Autoencoder (ISA), to learn a fixed-length vectorial representation by minimizing the reconstruction error. Specifically, we propose to integrate two classical mechanisms for sequence reconstruction which takes into account both the global silhouette information and the local temporal dependencies. Furthermore, we propose a stop feature that serves as a temporal stamp to guide the reconstruction process, which results in a higher-quality representation. The learned representation is able to effectively summarize not only the apparent features, but also the underlying and high-level style information. Take for example a speech sequence sample: our ISA model can not only recognize the spoken text (apparent feature), but can also discriminate the speaker who utters the audio (more high-level style). One promising application of the ISA model is that it can be readily used in the semi-supervised learning scenario, in which a large amount of unlabeled data is leveraged to extract high-quality sequence representations and thus to improve the performance of the subsequent supervised learning tasks on limited labeled data.
Attended End-to-end Architecture for Age Estimation from Facial Expression Videos
Nov 23, 2017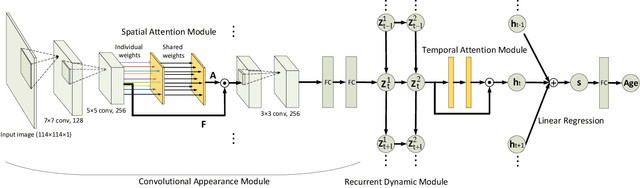
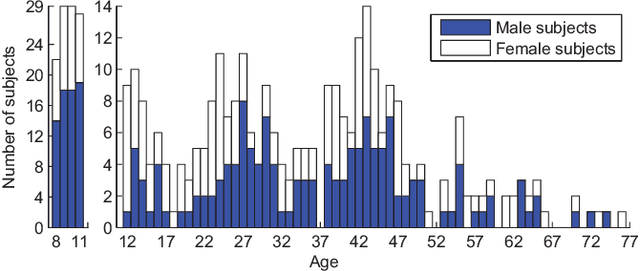
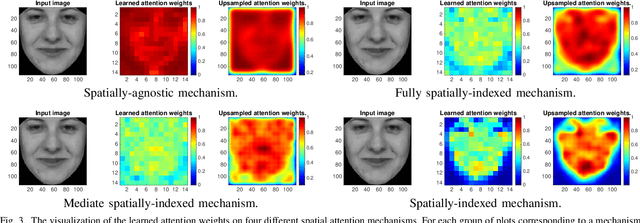
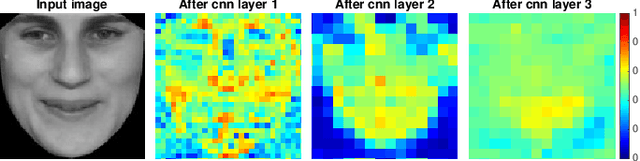
The main challenges of age estimation from facial expression videos lie not only in the modeling of the static facial appearance, but also in the capturing of the temporal facial dynamics. Traditional techniques to this problem focus on constructing handcrafted features to explore the discriminative information contained in facial appearance and dynamics separately. This relies on sophisticated feature-refinement and framework-design. In this paper, we present an end-to-end architecture for age estimation which is able to simultaneously learn both the appearance and dynamics of age from raw videos of facial expressions. Specifically, we employ convolutional neural networks to extract effective latent appearance representations and feed them into recurrent networks to model the temporal dynamics. More importantly, we propose to leverage attention models for salience detection in both the spatial domain for each single image and the temporal domain for the whole video as well. We design a specific spatially-indexed attention mechanism among the convolutional layers to extract the salient facial regions in each individual image, and a temporal attention layer to assign attention weights to each frame. This two-pronged approach not only improves the performance by allowing the model to focus on informative frames and facial areas, but it also offers an interpretable correspondence between the spatial facial regions as well as temporal frames, and the task of age estimation. We demonstrate the strong performance of our model in experiments on a large, gender-balanced database with 400 subjects with ages spanning from 8 to 76 years. Experiments reveal that our model exhibits significant superiority over the state-of-the-art methods given sufficient training data.
Interacting Attention-gated Recurrent Networks for Recommendation
Sep 07, 2017
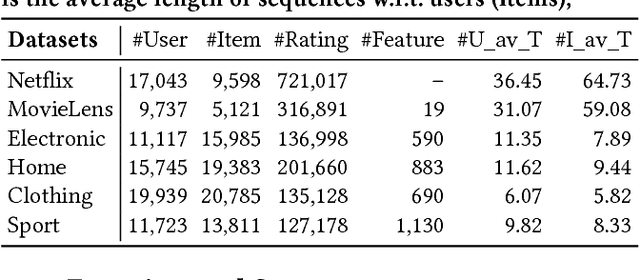
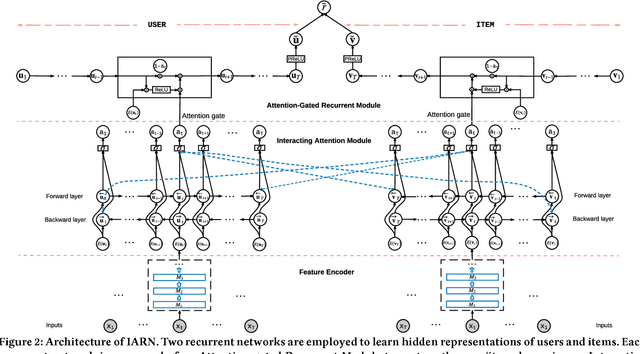
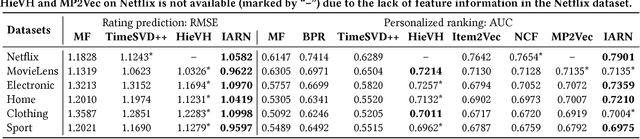
Capturing the temporal dynamics of user preferences over items is important for recommendation. Existing methods mainly assume that all time steps in user-item interaction history are equally relevant to recommendation, which however does not apply in real-world scenarios where user-item interactions can often happen accidentally. More importantly, they learn user and item dynamics separately, thus failing to capture their joint effects on user-item interactions. To better model user and item dynamics, we present the Interacting Attention-gated Recurrent Network (IARN) which adopts the attention model to measure the relevance of each time step. In particular, we propose a novel attention scheme to learn the attention scores of user and item history in an interacting way, thus to account for the dependencies between user and item dynamics in shaping user-item interactions. By doing so, IARN can selectively memorize different time steps of a user's history when predicting her preferences over different items. Our model can therefore provide meaningful interpretations for recommendation results, which could be further enhanced by auxiliary features. Extensive validation on real-world datasets shows that IARN consistently outperforms state-of-the-art methods.
Temporal Attention-Gated Model for Robust Sequence Classification
Apr 15, 2017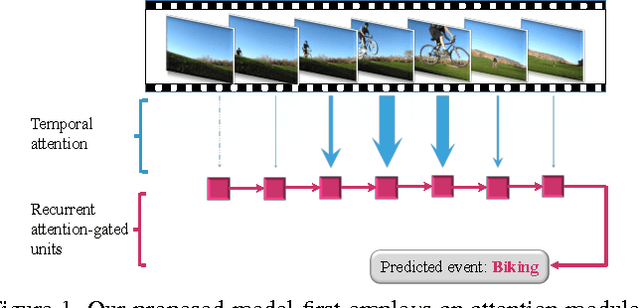
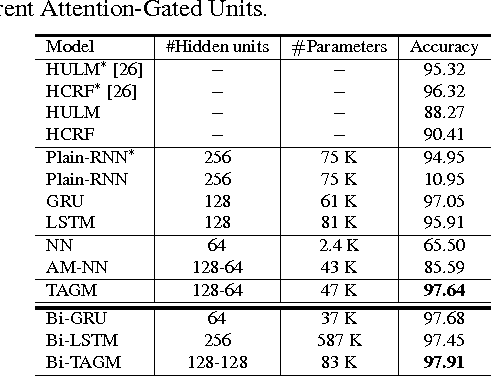
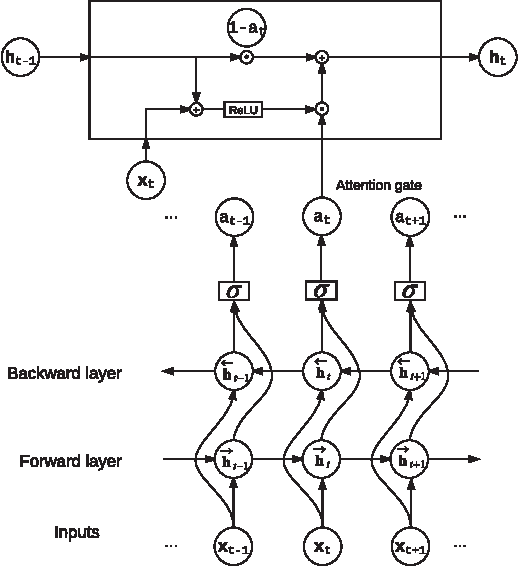

Typical techniques for sequence classification are designed for well-segmented sequences which have been edited to remove noisy or irrelevant parts. Therefore, such methods cannot be easily applied on noisy sequences expected in real-world applications. In this paper, we present the Temporal Attention-Gated Model (TAGM) which integrates ideas from attention models and gated recurrent networks to better deal with noisy or unsegmented sequences. Specifically, we extend the concept of attention model to measure the relevance of each observation (time step) of a sequence. We then use a novel gated recurrent network to learn the hidden representation for the final prediction. An important advantage of our approach is interpretability since the temporal attention weights provide a meaningful value for the salience of each time step in the sequence. We demonstrate the merits of our TAGM approach, both for prediction accuracy and interpretability, on three different tasks: spoken digit recognition, text-based sentiment analysis and visual event recognition.
Label Stability in Multiple Instance Learning
Mar 15, 2017

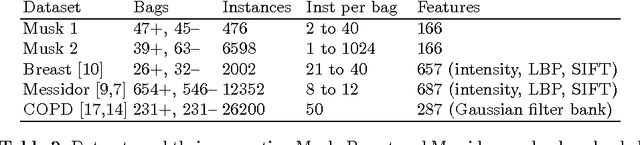
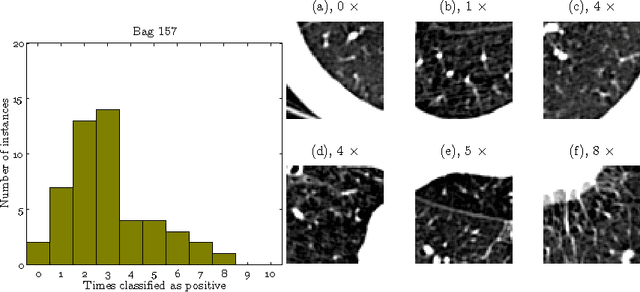
We address the problem of \emph{instance label stability} in multiple instance learning (MIL) classifiers. These classifiers are trained only on globally annotated images (bags), but often can provide fine-grained annotations for image pixels or patches (instances). This is interesting for computer aided diagnosis (CAD) and other medical image analysis tasks for which only a coarse labeling is provided. Unfortunately, the instance labels may be unstable. This means that a slight change in training data could potentially lead to abnormalities being detected in different parts of the image, which is undesirable from a CAD point of view. Despite MIL gaining popularity in the CAD literature, this issue has not yet been addressed. We investigate the stability of instance labels provided by several MIL classifiers on 5 different datasets, of which 3 are medical image datasets (breast histopathology, diabetic retinopathy and computed tomography lung images). We propose an unsupervised measure to evaluate instance stability, and demonstrate that a performance-stability trade-off can be made when comparing MIL classifiers.
Classification of COPD with Multiple Instance Learning
Mar 15, 2017

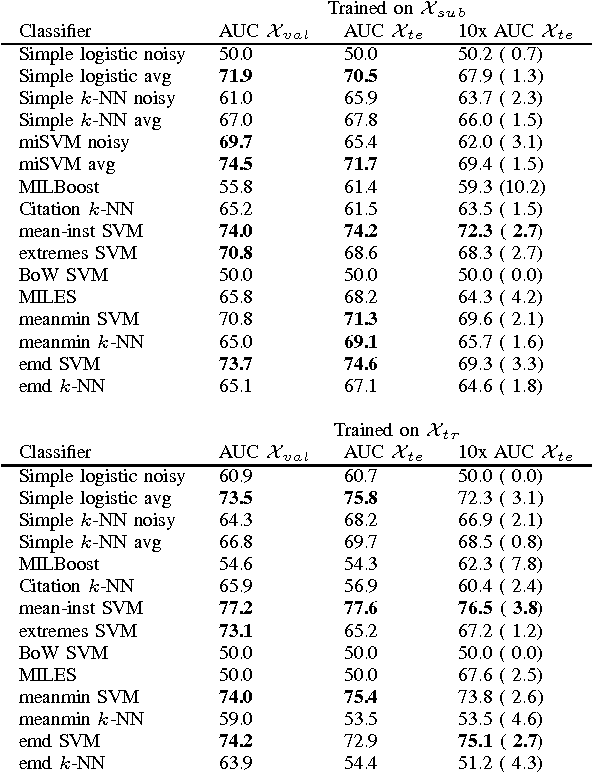
Chronic obstructive pulmonary disease (COPD) is a lung disease where early detection benefits the survival rate. COPD can be quantified by classifying patches of computed tomography images, and combining patch labels into an overall diagnosis for the image. As labeled patches are often not available, image labels are propagated to the patches, incorrectly labeling healthy patches in COPD patients as being affected by the disease. We approach quantification of COPD from lung images as a multiple instance learning (MIL) problem, which is more suitable for such weakly labeled data. We investigate various MIL assumptions in the context of COPD and show that although a concept region with COPD-related disease patterns is present, considering the whole distribution of lung tissue patches improves the performance. The best method is based on averaging instances and obtains an AUC of 0.742, which is higher than the previously reported best of 0.713 on the same dataset. Using the full training set further increases performance to 0.776, which is significantly higher (DeLong test) than previous results.