 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Population Posterior and Bayesian Inference on Streams
Jul 21, 2015


Many modern data analysis problems involve inferences from streaming data. However, streaming data is not easily amenable to the standard probabilistic modeling approaches, which assume that we condition on finite data. We develop population variational Bayes, a new approach for using Bayesian modeling to analyze streams of data. It approximates a new type of distribution, the population posterior, which combines the notion of a population distribution of the data with Bayesian inference in a probabilistic model. We study our method with latent Dirichlet allocation and Dirichlet process mixtures on several large-scale data sets.
Objective Variables for Probabilistic Revenue Maximization in Second-Price Auctions with Reserve
Jun 24, 2015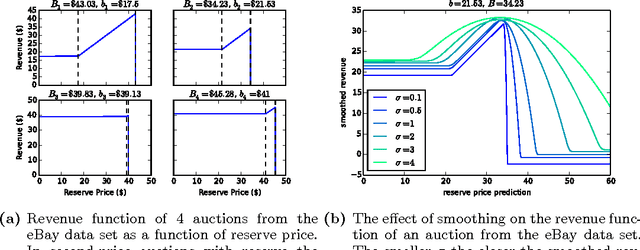

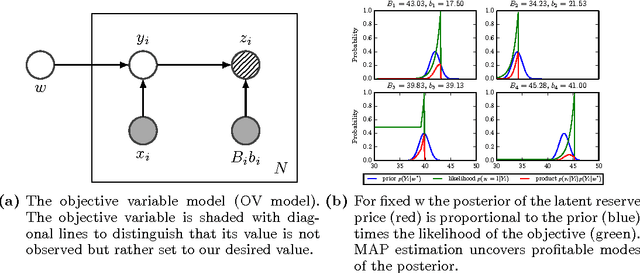
Many online companies sell advertisement space in second-price auctions with reserve. In this paper, we develop a probabilistic method to learn a profitable strategy to set the reserve price. We use historical auction data with features to fit a predictor of the best reserve price. This problem is delicate - the structure of the auction is such that a reserve price set too high is much worse than a reserve price set too low. To address this we develop objective variables, a new framework for combining probabilistic modeling with optimal decision-making. Objective variables are "hallucinated observations" that transform the revenue maximization task into a regularized maximum likelihood estimation problem, which we solve with an EM algorithm. This framework enables a variety of prediction mechanisms to set the reserve price. As examples, we study objective variable methods with regression, kernelized regression, and neural networks on simulated and real data. Our methods outperform previous approaches both in terms of scalability and profit.
Automatic Variational Inference in Stan
Jun 12, 2015

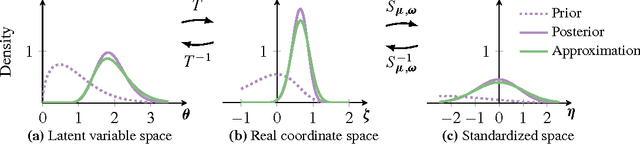
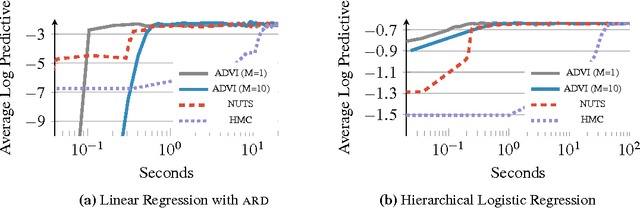
Variational inference is a scalable technique for approximate Bayesian inference. Deriving variational inference algorithms requires tedious model-specific calculations; this makes it difficult to automate. We propose an automatic variational inference algorithm, automatic differentiation variational inference (ADVI). The user only provides a Bayesian model and a dataset; nothing else. We make no conjugacy assumptions and support a broad class of models. The algorithm automatically determines an appropriate variational family and optimizes the variational objective. We implement ADVI in Stan (code available now), a probabilistic programming framework. We compare ADVI to MCMC sampling across hierarchical generalized linear models, nonconjugate matrix factorization, and a mixture model. We train the mixture model on a quarter million images. With ADVI we can use variational inference on any model we write in Stan.
Bayesian Poisson Tensor Factorization for Inferring Multilateral Relations from Sparse Dyadic Event Counts
Jun 10, 2015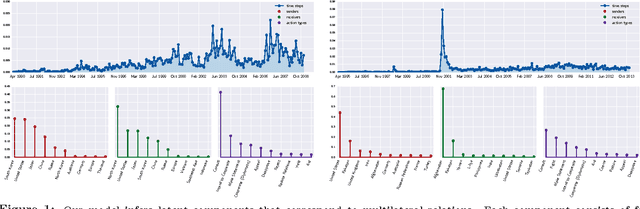
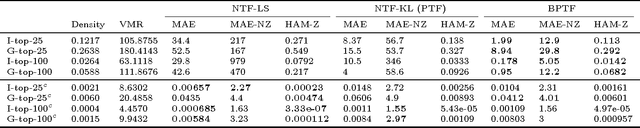
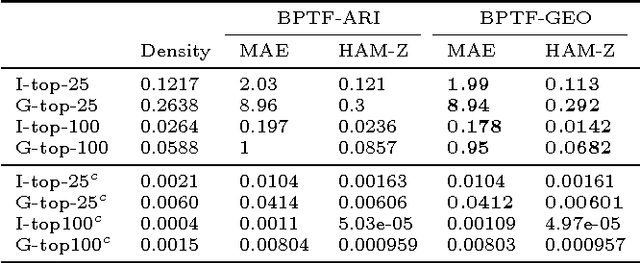
We present a Bayesian tensor factorization model for inferring latent group structures from dynamic pairwise interaction patterns. For decades, political scientists have collected and analyzed records of the form "country $i$ took action $a$ toward country $j$ at time $t$"---known as dyadic events---in order to form and test theories of international relations. We represent these event data as a tensor of counts and develop Bayesian Poisson tensor factorization to infer a low-dimensional, interpretable representation of their salient patterns. We demonstrate that our model's predictive performance is better than that of standard non-negative tensor factorization methods. We also provide a comparison of our variational updates to their maximum likelihood counterparts. In doing so, we identify a better way to form point estimates of the latent factors than that typically used in Bayesian Poisson matrix factorization. Finally, we showcase our model as an exploratory analysis tool for political scientists. We show that the inferred latent factor matrices capture interpretable multilateral relations that both conform to and inform our knowledge of international affairs.
Population Empirical Bayes
Jun 08, 2015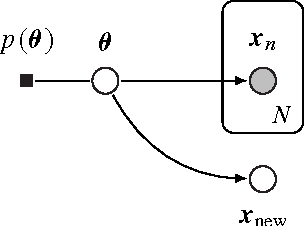
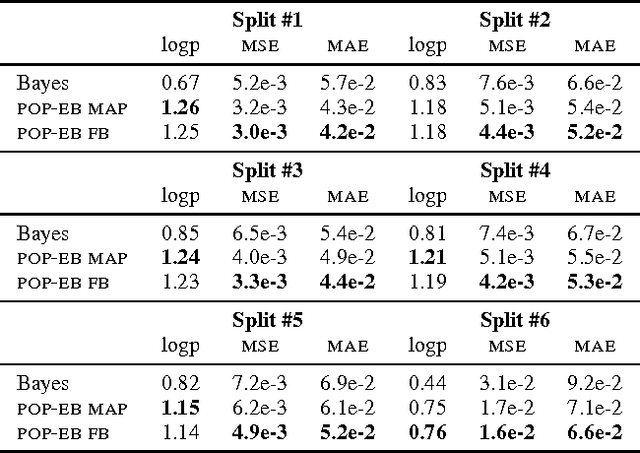
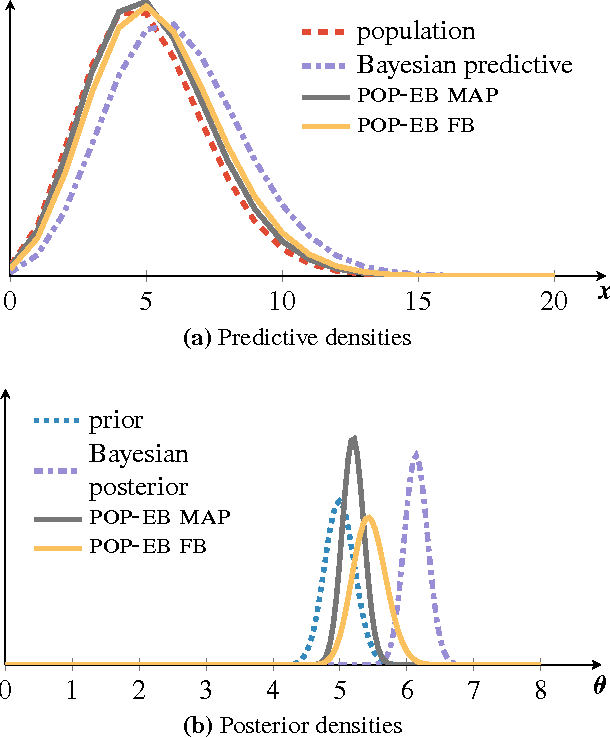
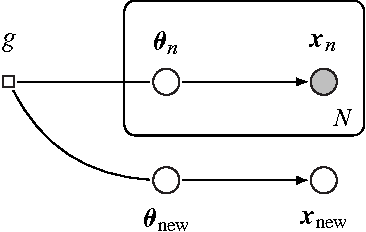
Bayesian predictive inference analyzes a dataset to make predictions about new observations. When a model does not match the data, predictive accuracy suffers. We develop population empirical Bayes (POP-EB), a hierarchical framework that explicitly models the empirical population distribution as part of Bayesian analysis. We introduce a new concept, the latent dataset, as a hierarchical variable and set the empirical population as its prior. This leads to a new predictive density that mitigates model mismatch. We efficiently apply this method to complex models by proposing a stochastic variational inference algorithm, called bumping variational inference (BUMP-VI). We demonstrate improved predictive accuracy over classical Bayesian inference in three models: a linear regression model of health data, a Bayesian mixture model of natural images, and a latent Dirichlet allocation topic model of scientific documents.
Structured Stochastic Variational Inference
Nov 26, 2014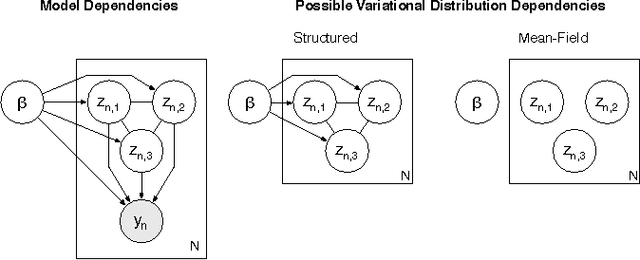
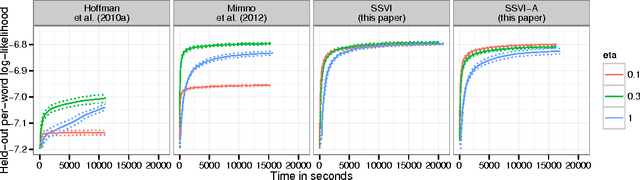
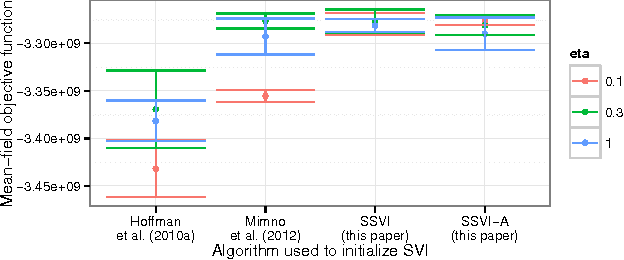
Stochastic variational inference makes it possible to approximate posterior distributions induced by large datasets quickly using stochastic optimization. The algorithm relies on the use of fully factorized variational distributions. However, this "mean-field" independence approximation limits the fidelity of the posterior approximation, and introduces local optima. We show how to relax the mean-field approximation to allow arbitrary dependencies between global parameters and local hidden variables, producing better parameter estimates by reducing bias, sensitivity to local optima, and sensitivity to hyperparameters.
Deep Exponential Families
Nov 10, 2014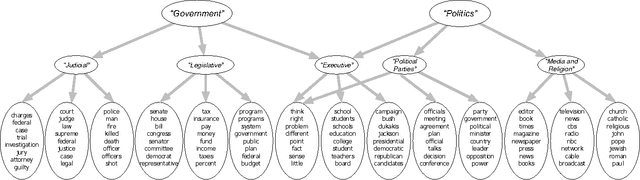

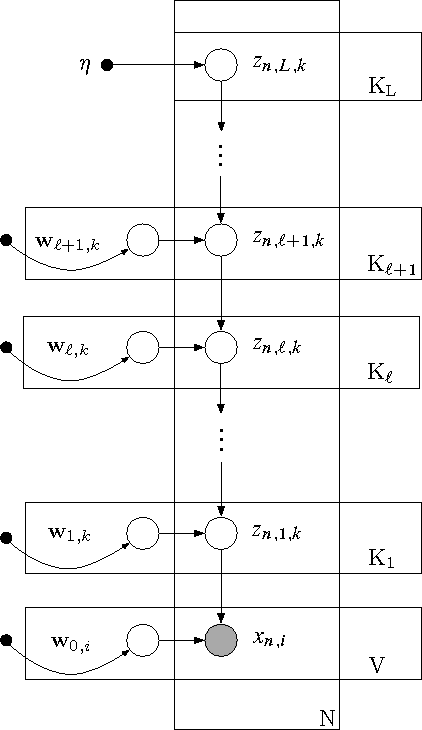
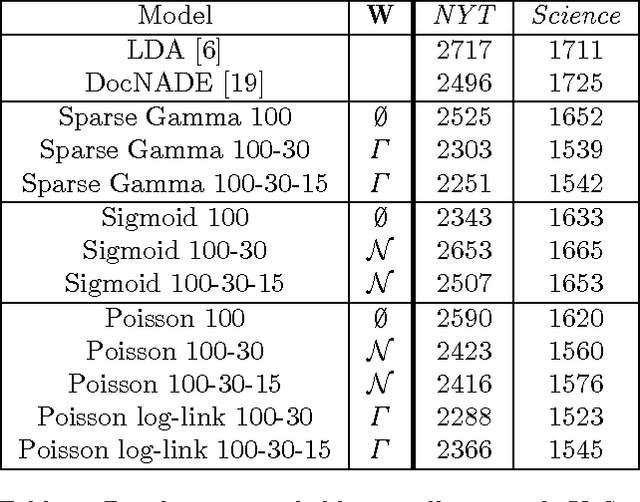
We describe \textit{deep exponential families} (DEFs), a class of latent variable models that are inspired by the hidden structures used in deep neural networks. DEFs capture a hierarchy of dependencies between latent variables, and are easily generalized to many settings through exponential families. We perform inference using recent "black box" variational inference techniques. We then evaluate various DEFs on text and combine multiple DEFs into a model for pairwise recommendation data. In an extensive study, we show that going beyond one layer improves predictions for DEFs. We demonstrate that DEFs find interesting exploratory structure in large data sets, and give better predictive performance than state-of-the-art models.
Scalable Recommendation with Poisson Factorization
May 20, 2014
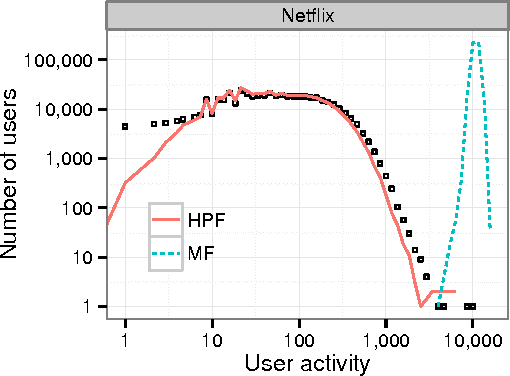

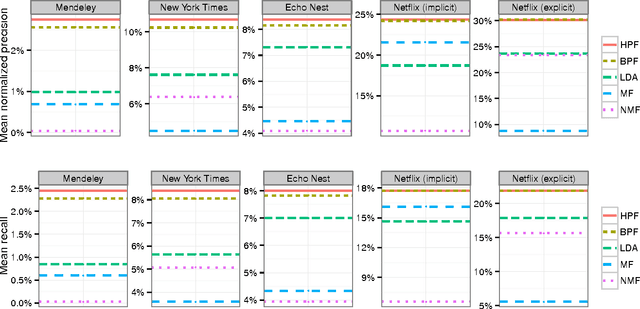
We develop a Bayesian Poisson matrix factorization model for forming recommendations from sparse user behavior data. These data are large user/item matrices where each user has provided feedback on only a small subset of items, either explicitly (e.g., through star ratings) or implicitly (e.g., through views or purchases). In contrast to traditional matrix factorization approaches, Poisson factorization implicitly models each user's limited attention to consume items. Moreover, because of the mathematical form of the Poisson likelihood, the model needs only to explicitly consider the observed entries in the matrix, leading to both scalable computation and good predictive performance. We develop a variational inference algorithm for approximate posterior inference that scales up to massive data sets. This is an efficient algorithm that iterates over the observed entries and adjusts an approximate posterior over the user/item representations. We apply our method to large real-world user data containing users rating movies, users listening to songs, and users reading scientific papers. In all these settings, Bayesian Poisson factorization outperforms state-of-the-art matrix factorization methods.
Nested Hierarchical Dirichlet Processes
May 02, 2014


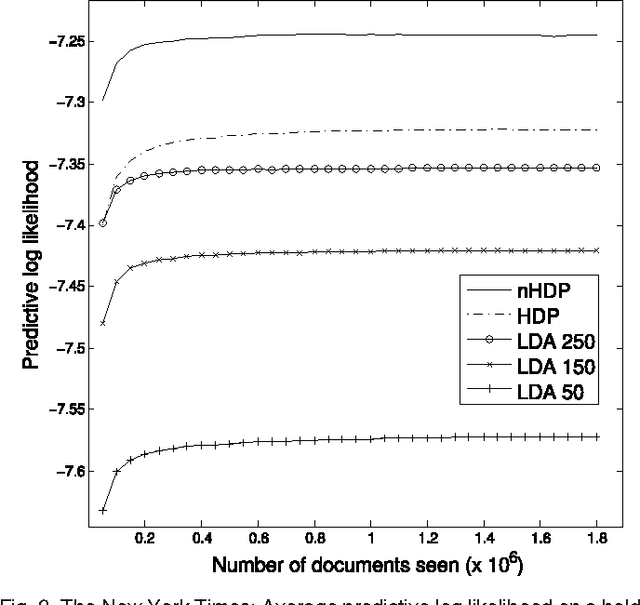
We develop a nested hierarchical Dirichlet process (nHDP) for hierarchical topic modeling. The nHDP is a generalization of the nested Chinese restaurant process (nCRP) that allows each word to follow its own path to a topic node according to a document-specific distribution on a shared tree. This alleviates the rigid, single-path formulation of the nCRP, allowing a document to more easily express thematic borrowings as a random effect. We derive a stochastic variational inference algorithm for the model, in addition to a greedy subtree selection method for each document, which allows for efficient inference using massive collections of text documents. We demonstrate our algorithm on 1.8 million documents from The New York Times and 3.3 million documents from Wikipedia.
Black Box Variational Inference
Dec 31, 2013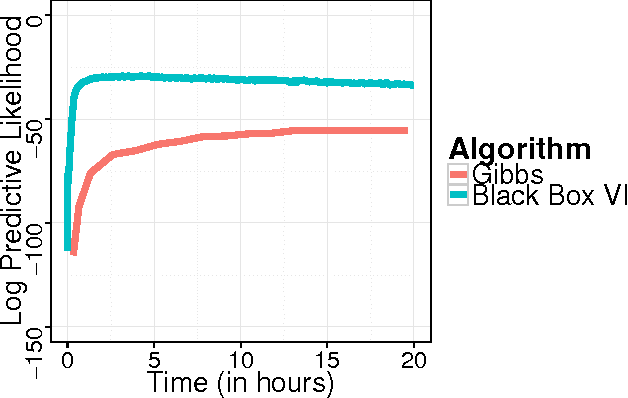
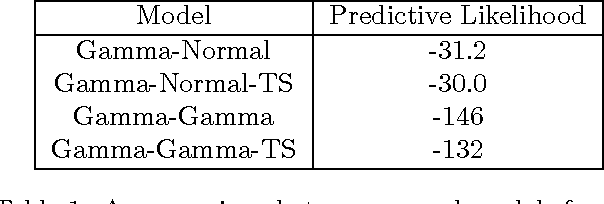
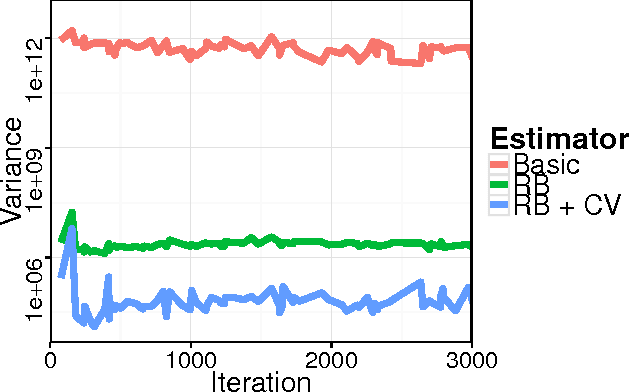
Variational inference has become a widely used method to approximate posteriors in complex latent variables models. However, deriving a variational inference algorithm generally requires significant model-specific analysis, and these efforts can hinder and deter us from quickly developing and exploring a variety of models for a problem at hand. In this paper, we present a "black box" variational inference algorithm, one that can be quickly applied to many models with little additional derivation. Our method is based on a stochastic optimization of the variational objective where the noisy gradient is computed from Monte Carlo samples from the variational distribution. We develop a number of methods to reduce the variance of the gradient, always maintaining the criterion that we want to avoid difficult model-based derivations. We evaluate our method against the corresponding black box sampling based methods. We find that our method reaches better predictive likelihoods much faster than sampling methods. Finally, we demonstrate that Black Box Variational Inference lets us easily explore a wide space of models by quickly constructing and evaluating several models of longitudinal healthcare data.