 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferrable Representations of Career Trajectories for Economic Prediction
Mar 10, 2022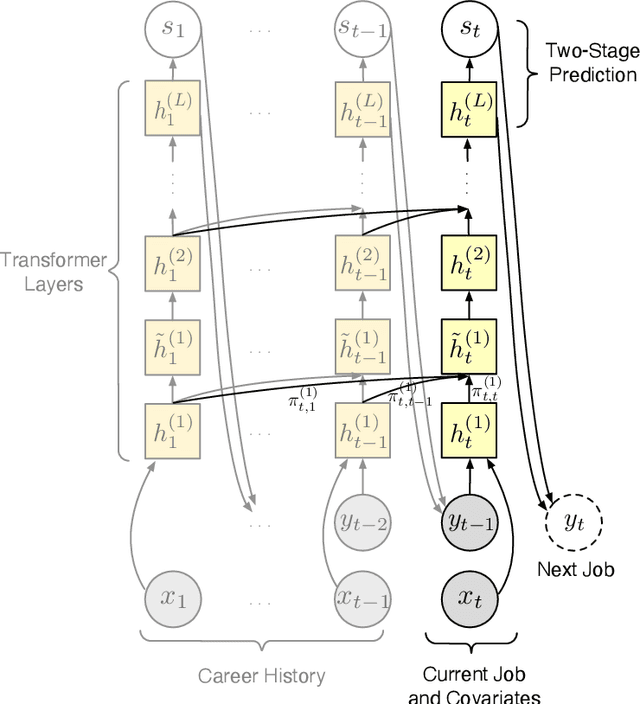
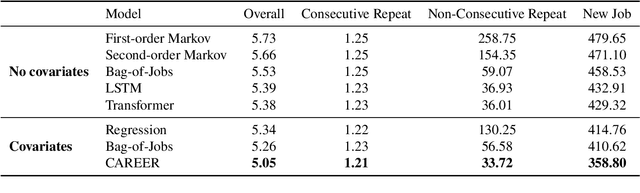

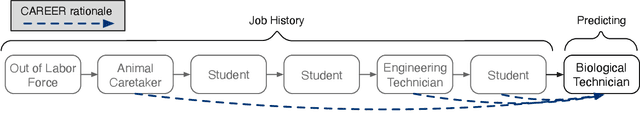
Understanding career trajectories -- the sequences of jobs that individuals hold over their working lives -- is important to economists for studying labor markets. In the past, economists have estimated relevant quantities by fitting predictive models to small surveys, but in recent years large datasets of online resumes have also become available. These new datasets provide job sequences of many more individuals, but they are too large and complex for standard econometric modeling. To this end, we adapt ideas from modern language modeling to the analysis of large-scale job sequence data. We develop CAREER, a transformer-based model that learns a low-dimensional representation of an individual's job history. This representation can be used to predict jobs directly on a large dataset, or can be "transferred" to represent jobs in smaller and better-curated datasets. We fit the model to a large dataset of resumes, 24 million people who are involved in more than a thousand unique occupations. It forms accurate predictions on held-out data, and it learns useful career representations that can be fine-tuned to make accurate predictions on common economics datasets.
Transport Score Climbing: Variational Inference Using Forward KL and Adaptive Neural Transport
Feb 07, 2022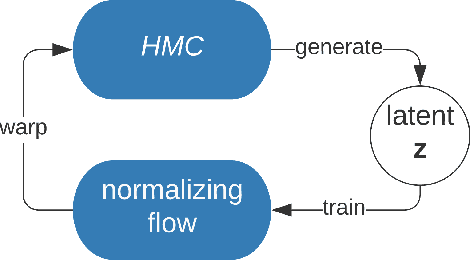
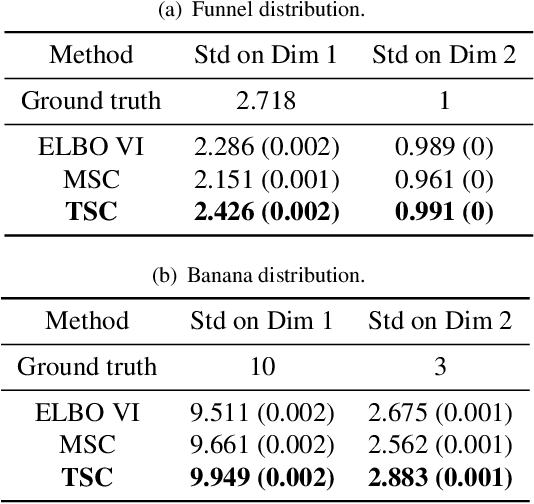
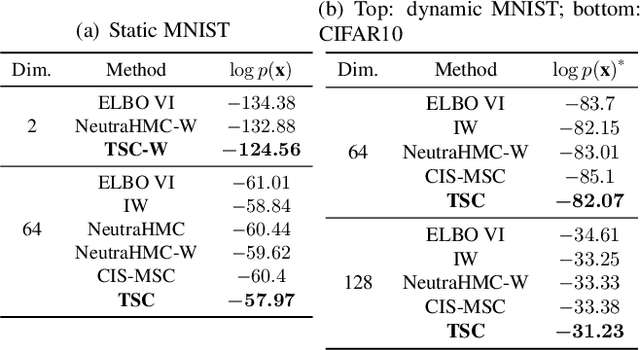
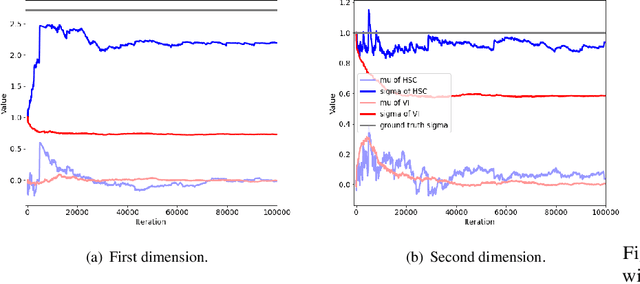
Variational inference often minimizes the "reverse" Kullbeck-Leibler (KL) KL(q||p) from the approximate distribution q to the posterior p. Recent work studies the "forward" KL KL(p||q), which unlike reverse KL does not lead to variational approximations that underestimate uncertainty. This paper introduces Transport Score Climbing (TSC), a method that optimizes KL(p||q) by using Hamiltonian Monte Carlo (HMC) and a novel adaptive transport map. The transport map improves the trajectory of HMC by acting as a change of variable between the latent variable space and a warped space. TSC uses HMC samples to dynamically train the transport map while optimizing KL(p||q). TSC leverages synergies, where better transport maps lead to better HMC sampling, which then leads to better transport maps. We demonstrate TSC on synthetic and real data. We find that TSC achieves competitive performance when training variational autoencoders on large-scale data.
Unsupervised Representation Learning via Neural Activation Coding
Dec 07, 2021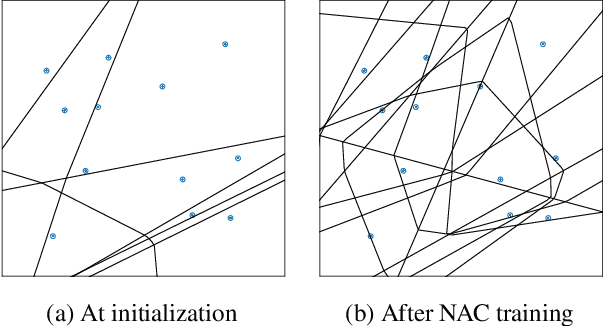
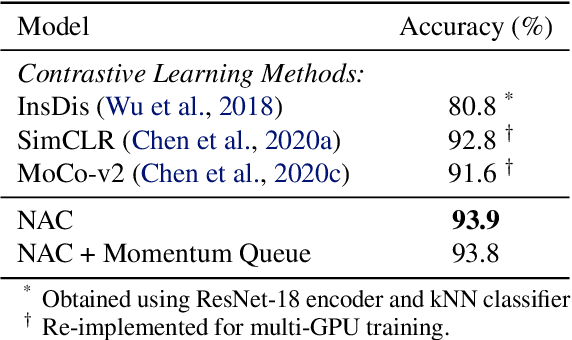
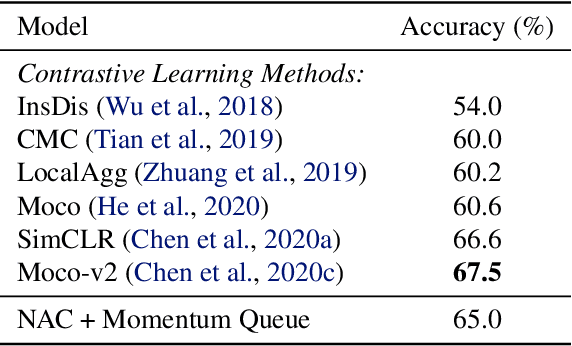
We present neural activation coding (NAC) as a novel approach for learning deep representations from unlabeled data for downstream applications. We argue that the deep encoder should maximize its nonlinear expressivity on the data for downstream predictors to take full advantage of its representation power. To this end, NAC maximizes the mutual information between activation patterns of the encoder and the data over a noisy communication channel. We show that learning for a noise-robust activation code increases the number of distinct linear regions of ReLU encoders, hence the maximum nonlinear expressivity. More interestingly, NAC learns both continuous and discrete representations of data, which we respectively evaluate on two downstream tasks: (i) linear classification on CIFAR-10 and ImageNet-1K and (ii) nearest neighbor retrieval on CIFAR-10 and FLICKR-25K. Empirical results show that NAC attains better or comparable performance on both tasks over recent baselines including SimCLR and DistillHash. In addition, NAC pretraining provides significant benefits to the training of deep generative models. Our code is available at https://github.com/yookoon/nac.
Identifiable Variational Autoencoders via Sparse Decoding
Oct 20, 2021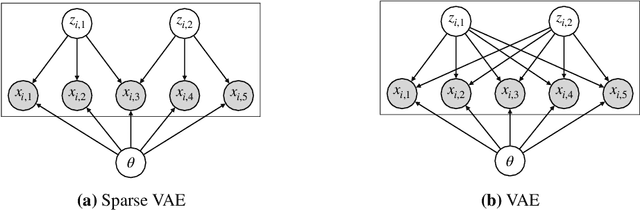
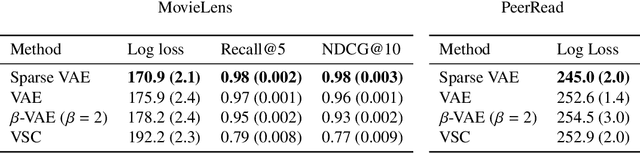
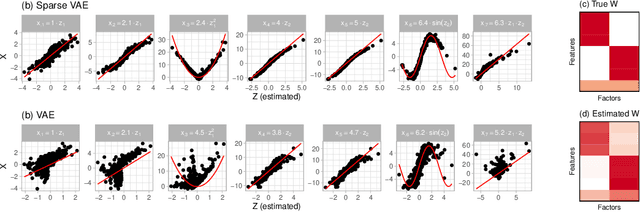
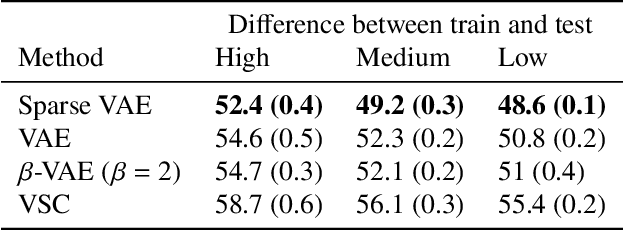
We develop the Sparse VAE, a deep generative model for unsupervised representation learning on high-dimensional data. Given a dataset of observations, the Sparse VAE learns a set of latent factors that captures its distribution. The model is sparse in the sense that each feature of the dataset (i.e., each dimension) depends on a small subset of the latent factors. As examples, in ratings data each movie is only described by a few genres; in text data each word is only applicable to a few topics; in genomics, each gene is active in only a few biological processes. We first show that the Sparse VAE is identifiable: given data drawn from the model, there exists a uniquely optimal set of factors. (In contrast, most VAE-based models are not identifiable.) The key assumption behind Sparse-VAE identifiability is the existence of "anchor features", where for each factor there exists a feature that depends only on that factor. Importantly, the anchor features do not need to be known in advance. We then show how to fit the Sparse VAE with variational EM. Finally, we empirically study the Sparse VAE with both simulated and real data. We find that it recovers meaningful latent factors and has smaller heldout reconstruction error than related methods.
Optimization-based Causal Estimation from Heterogenous Environments
Sep 24, 2021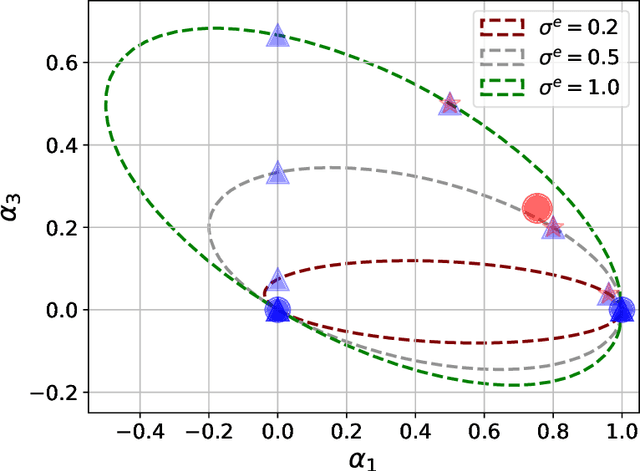
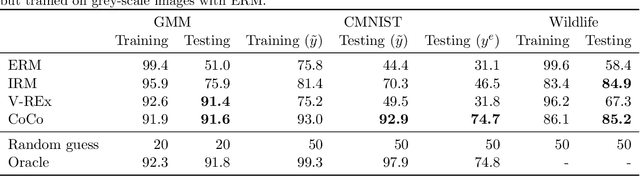
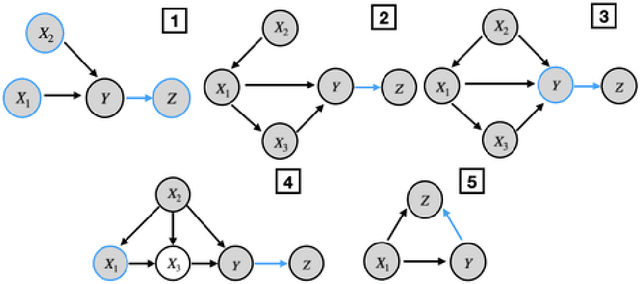

This paper presents a new optimization approach to causal estimation. Given data that contains covariates and an outcome, which covariates are causes of the outcome, and what is the strength of the causality? In classical machine learning (ML), the goal of optimization is to maximize predictive accuracy. However, some covariates might exhibit a non-causal association to the outcome. Such spurious associations provide predictive power for classical ML, but they prevent us from causally interpreting the result. This paper proposes CoCo, an optimization algorithm that bridges the gap between pure prediction and causal inference. CoCo leverages the recently-proposed idea of environments, datasets of covariates/response where the causal relationships remain invariant but where the distribution of the covariates changes from environment to environment. Given datasets from multiple environments -- and ones that exhibit sufficient heterogeneity -- CoCo maximizes an objective for which the only solution is the causal solution. We describe the theoretical foundations of this approach and demonstrate its effectiveness on simulated and real datasets. Compared to classical ML and existing methods, CoCo provides more accurate estimates of the causal model.
Rationales for Sequential Predictions
Sep 14, 2021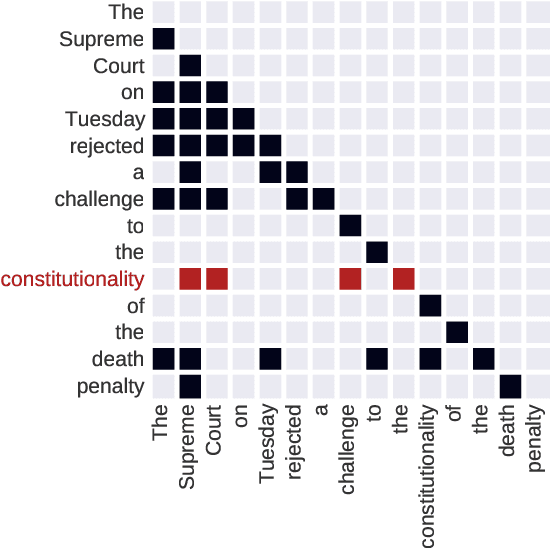
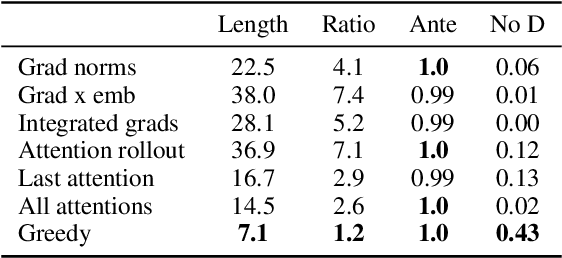
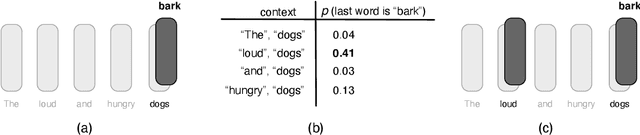
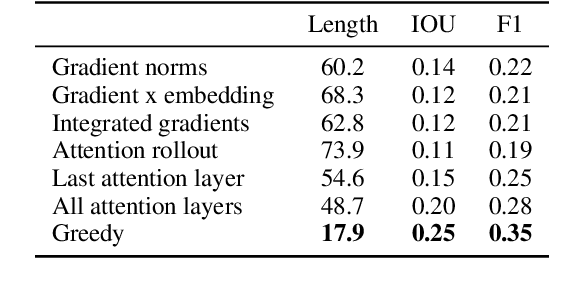
Sequence models are a critical component of modern NLP systems, but their predictions are difficult to explain. We consider model explanations though rationales, subsets of context that can explain individual model predictions. We find sequential rationales by solving a combinatorial optimization: the best rationale is the smallest subset of input tokens that would predict the same output as the full sequence. Enumerating all subsets is intractable, so we propose an efficient greedy algorithm to approximate this objective. The algorithm, which is called greedy rationalization, applies to any model. For this approach to be effective, the model should form compatible conditional distributions when making predictions on incomplete subsets of the context. This condition can be enforced with a short fine-tuning step. We study greedy rationalization on language modeling and machine translation. Compared to existing baselines, greedy rationalization is best at optimizing the combinatorial objective and provides the most faithful rationales. On a new dataset of annotated sequential rationales, greedy rationales are most similar to human rationales.
Text-Based Ideal Points
May 08, 2020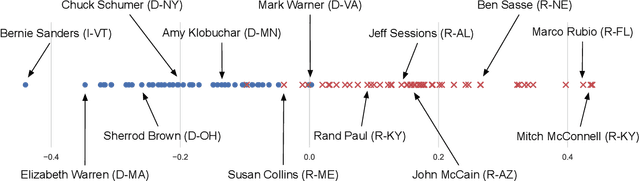

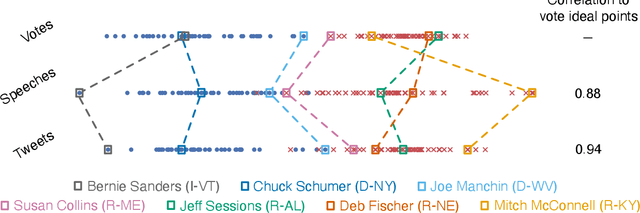
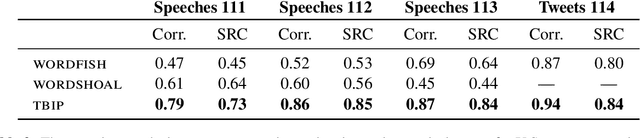
Ideal point models analyze lawmakers' votes to quantify their political positions, or ideal points. But votes are not the only way to express a political position. Lawmakers also give speeches, release press statements, and post tweets. In this paper, we introduce the text-based ideal point model (TBIP), an unsupervised probabilistic topic model that analyzes texts to quantify the political positions of its authors. We demonstrate the TBIP with two types of politicized text data: U.S. Senate speeches and senator tweets. Though the model does not analyze their votes or political affiliations, the TBIP separates lawmakers by party, learns interpretable politicized topics, and infers ideal points close to the classical vote-based ideal points. One benefit of analyzing texts, as opposed to votes, is that the TBIP can estimate ideal points of anyone who authors political texts, including non-voting actors. To this end, we use it to study tweets from the 2020 Democratic presidential candidates. Using only the texts of their tweets, it identifies them along an interpretable progressive-to-moderate spectrum.
Towards Clarifying the Theory of the Deconfounder
Mar 10, 2020Wang and Blei (2019) studies multiple causal inference and proposes the deconfounder algorithm. The paper discusses theoretical requirements and presents empirical studies. Several refinements have been suggested around the theory of the deconfounder. Among these, Imai and Jiang clarified the assumption of "no unobserved single-cause confounders." Using their assumption, this paper clarifies the theory. Furthermore, Ogburn et al. (2020) proposes counterexamples to the theory. But the proposed counterexamples do not satisfy the required assumptions.
Poisson-Randomized Gamma Dynamical Systems
Oct 28, 2019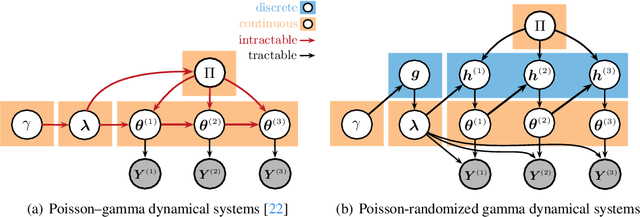
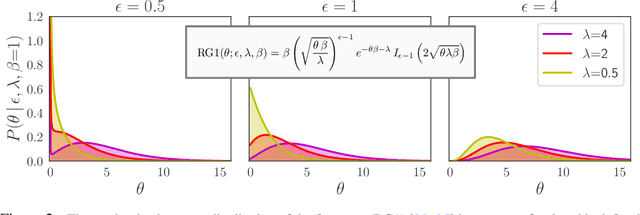
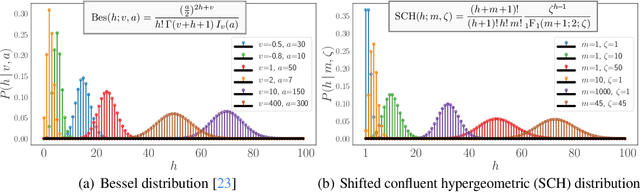
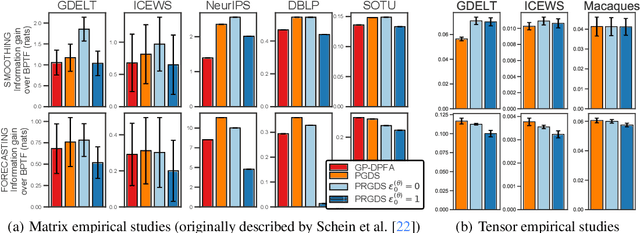
This paper presents the Poisson-randomized gamma dynamical system (PRGDS), a model for sequentially observed count tensors that encodes a strong inductive bias toward sparsity and burstiness. The PRGDS is based on a new motif in Bayesian latent variable modeling, an alternating chain of discrete Poisson and continuous gamma latent states that is analytically convenient and computationally tractable. This motif yields closed-form complete conditionals for all variables by way of the Bessel distribution and a novel discrete distribution that we call the shifted confluent hypergeometric distribution. We draw connections to closely related models and compare the PRGDS to these models in studies of real-world count data sets of text, international events, and neural spike trains. We find that a sparse variant of the PRGDS, which allows the continuous gamma latent states to take values of exactly zero, often obtains better predictive performance than other models and is uniquely capable of inferring latent structures that are highly localized in time.
The Blessings of Multiple Causes: A Reply to Ogburn et al.
Oct 17, 2019Ogburn et al. (2019, arXiv:1910.05438) discuss "The Blessings of Multiple Causes" (Wang and Blei, 2018, arXiv:1805.06826). Many of their remarks are interesting. But they also claim that the paper has "foundational errors" and that its "premise is...incorrect." These claims are not substantiated. We correct the record here.