 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Equilibria in Networked Public Goods Games through Network Structure Modification
Feb 25, 2020
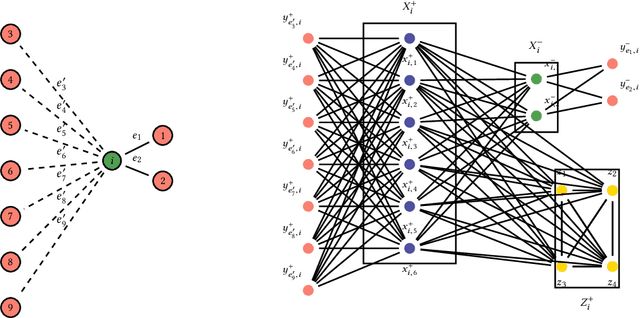
Networked public goods games model scenarios in which self-interested agents decide whether or how much to invest in an action that benefits not only themselves, but also their network neighbors. Examples include vaccination, security investment, and crime reporting. While every agent's utility is increasing in their neighbors' joint investment, the specific form can vary widely depending on the scenario. A principal, such as a policymaker, may wish to induce large investment from the agents. Besides direct incentives, an important lever here is the network structure itself: by adding and removing edges, for example, through community meetings, the principal can change the nature of the utility functions, resulting in different, and perhaps socially preferable, equilibrium outcomes. We initiate an algorithmic study of targeted network modifications with the goal of inducing equilibria of a particular form. We study this question for a variety of equilibrium forms (induce all agents to invest, at least a given set $S$, exactly a given set $S$, at least $k$ agents), and for a variety of utility functions. While we show that the problem is NP-complete for a number of these scenarios, we exhibit a broad array of scenarios in which the problem can be solved in polynomial time by non-trivial reductions to (minimum-cost) matching problems.
The Complexity of Interactively Learning a Stable Matching by Trial and Error
Feb 18, 2020In a stable matching setting, we consider a query model that allows for an interactive learning algorithm to make precisely one type of query: proposing a matching, the response to which is either that the proposed matching is stable, or a blocking pair (chosen adversarially) indicating that this matching is unstable. For one-to-one matching markets, our main result is an essentially tight upper bound of $O(n^2\log n)$ on the deterministic query complexity of interactively learning a stable matching in this coarse query model, along with an efficient randomized algorithm that achieves this query complexity with high probability. For many-to-many matching markets in which participants have responsive preferences, we first give an interactive learning algorithm whose query complexity and running time are polynomial in the size of the market if the maximum quota of each agent is bounded; our main result for many-to-many markets is that the deterministic query complexity can be made polynomial (more specifically, $O(n^3 \log n)$) in the size of the market even for arbitrary (e.g., linear in the market size) quotas.
On the Distortion of Voting with Multiple Representative Candidates
Nov 21, 2017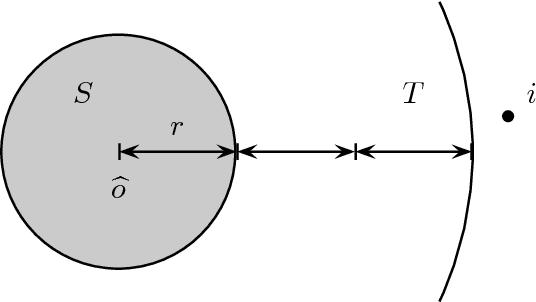
We study positional voting rules when candidates and voters are embedded in a common metric space, and cardinal preferences are naturally given by distances in the metric space. In a positional voting rule, each candidate receives a score from each ballot based on the ballot's rank order; the candidate with the highest total score wins the election. The cost of a candidate is his sum of distances to all voters, and the distortion of an election is the ratio between the cost of the elected candidate and the cost of the optimum candidate. We consider the case when candidates are representative of the population, in the sense that they are drawn i.i.d. from the population of the voters, and analyze the expected distortion of positional voting rules. Our main result is a clean and tight characterization of positional voting rules that have constant expected distortion (independent of the number of candidates and the metric space). Our characterization result immediately implies constant expected distortion for Borda Count and elections in which each voter approves a constant fraction of all candidates. On the other hand, we obtain super-constant expected distortion for Plurality, Veto, and approving a constant number of candidates. These results contrast with previous results on voting with metric preferences: When the candidates are chosen adversarially, all of the preceding voting rules have distortion linear in the number of candidates or voters. Thus, the model of representative candidates allows us to distinguish voting rules which seem equally bad in the worst case.
A General Framework for Robust Interactive Learning
Oct 16, 2017We propose a general framework for interactively learning models, such as (binary or non-binary) classifiers, orderings/rankings of items, or clusterings of data points. Our framework is based on a generalization of Angluin's equivalence query model and Littlestone's online learning model: in each iteration, the algorithm proposes a model, and the user either accepts it or reveals a specific mistake in the proposal. The feedback is correct only with probability $p > 1/2$ (and adversarially incorrect with probability $1 - p$), i.e., the algorithm must be able to learn in the presence of arbitrary noise. The algorithm's goal is to learn the ground truth model using few iterations. Our general framework is based on a graph representation of the models and user feedback. To be able to learn efficiently, it is sufficient that there be a graph $G$ whose nodes are the models and (weighted) edges capture the user feedback, with the property that if $s, s^*$ are the proposed and target models, respectively, then any (correct) user feedback $s'$ must lie on a shortest $s$-$s^*$ path in $G$. Under this one assumption, there is a natural algorithm reminiscent of the Multiplicative Weights Update algorithm, which will efficiently learn $s^*$ even in the presence of noise in the user's feedback. From this general result, we rederive with barely any extra effort classic results on learning of classifiers and a recent result on interactive clustering; in addition, we easily obtain new interactive learning algorithms for ordering/ranking.
Of the People: Voting Is More Effective with Representative Candidates
Aug 26, 2017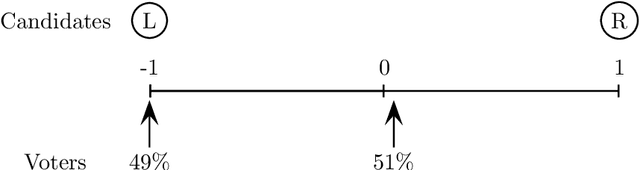

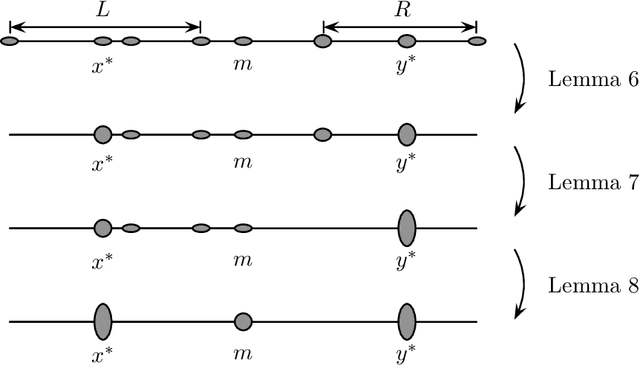
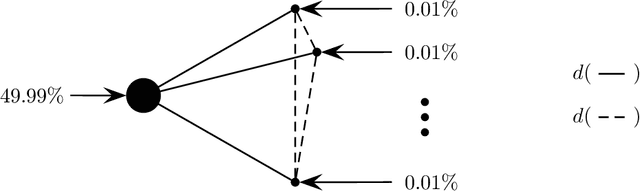
In light of the classic impossibility results of Arrow and Gibbard and Satterthwaite regarding voting with ordinal rules, there has been recent interest in characterizing how well common voting rules approximate the social optimum. In order to quantify the quality of approximation, it is natural to consider the candidates and voters as embedded within a common metric space, and to ask how much further the chosen candidate is from the population as compared to the socially optimal one. We use this metric preference model to explore a fundamental and timely question: does the social welfare of a population improve when candidates are representative of the population? If so, then by how much, and how does the answer depend on the complexity of the metric space? We restrict attention to the most fundamental and common social choice setting: a population of voters, two independently drawn candidates, and a majority rule election. When candidates are not representative of the population, it is known that the candidate selected by the majority rule can be thrice as far from the population as the socially optimal one. We examine how this ratio improves when candidates are drawn independently from the population of voters. Our results are two-fold: When the metric is a line, the ratio improves from $3$ to $4-2\sqrt{2}$, roughly $1.1716$; this bound is tight. When the metric is arbitrary, we show a lower bound of $1.5$ and a constant upper bound strictly better than $2$ on the approximation ratio of the majority rule. The positive result depends in part on the assumption that candidates are independent and identically distributed. However, we show that independence alone is not enough to achieve the upper bound: even when candidates are drawn independently, if the population of candidates can be different from the voters, then an upper bound of $2$ on the approximation is tight.
Learning Influence Functions from Incomplete Observations
Nov 07, 2016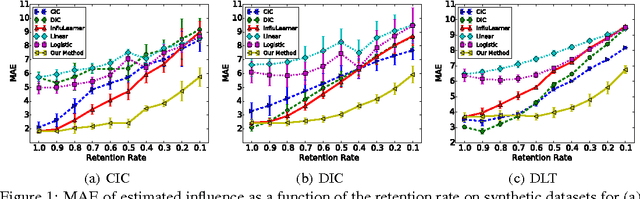
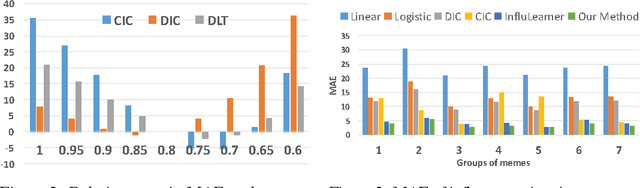
We study the problem of learning influence functions under incomplete observations of node activations. Incomplete observations are a major concern as most (online and real-world) social networks are not fully observable. We establish both proper and improper PAC learnability of influence functions under randomly missing observations. Proper PAC learnability under the Discrete-Time Linear Threshold (DLT) and Discrete-Time Independent Cascade (DIC) models is established by reducing incomplete observations to complete observations in a modified graph. Our improper PAC learnability result applies for the DLT and DIC models as well as the Continuous-Time Independent Cascade (CIC) model. It is based on a parametrization in terms of reachability features, and also gives rise to an efficient and practical heuristic. Experiments on synthetic and real-world datasets demonstrate the ability of our method to compensate even for a fairly large fraction of missing observations.
Submodular meets Spectral: Greedy Algorithms for Subset Selection, Sparse Approximation and Dictionary Selection
Feb 25, 2011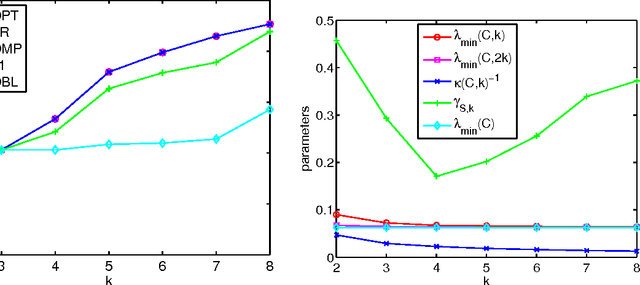

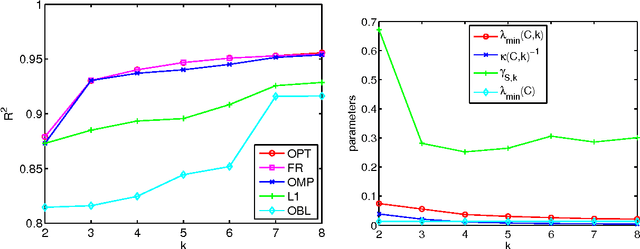
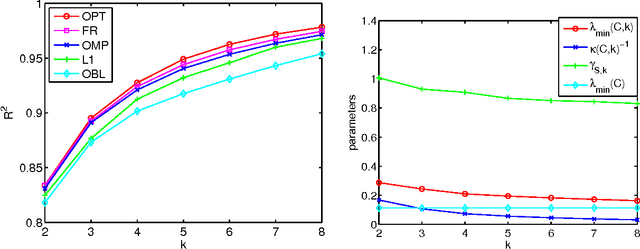
We study the problem of selecting a subset of k random variables from a large set, in order to obtain the best linear prediction of another variable of interest. This problem can be viewed in the context of both feature selection and sparse approximation. We analyze the performance of widely used greedy heuristics, using insights from the maximization of submodular functions and spectral analysis. We introduce the submodularity ratio as a key quantity to help understand why greedy algorithms perform well even when the variables are highly correlated. Using our techniques, we obtain the strongest known approximation guarantees for this problem, both in terms of the submodularity ratio and the smallest k-sparse eigenvalue of the covariance matrix. We further demonstrate the wide applicability of our techniques by analyzing greedy algorithms for the dictionary selection problem, and significantly improve the previously known guarantees. Our theoretical analysis is complemented by experiments on real-world and synthetic data sets; the experiments show that the submodularity ratio is a stronger predictor of the performance of greedy algorithms than other spectral parameters.