 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Learning to Detect Touches on Cluttered Tables
Apr 10, 2023
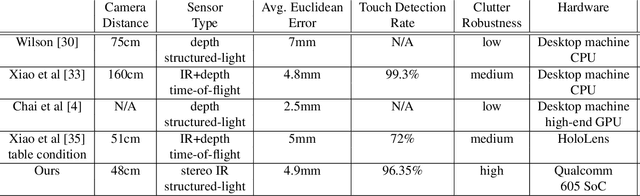

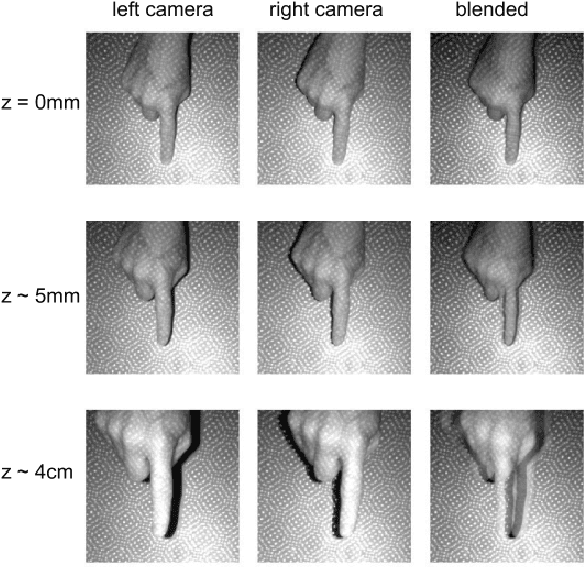
We present a novel self-contained camera-projector tabletop system with a lamp form-factor that brings digital intelligence to our tables. We propose a real-time, on-device, learning-based touch detection algorithm that makes any tabletop interactive. The top-down configuration and learning-based algorithm makes our method robust to the presence of clutter, a main limitation of existing camera-projector tabletop systems. Our research prototype enables a set of experiences that combine hand interactions and objects present on the table. A video can be found at https://youtu.be/hElC_c25Fg8.