 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeBlocks: Foundational and Continual Time-Series Blockbase -- Extended Version
Jun 01, 2026The ongoing digitization has led to a proliferation of time-series data streams that monitor a variety of processes, from which valuable insights may be obtained. Further, the emergence of successful foundational language models begs the question of whether it is possible to achieve time-series models with the foundational properties of handling multiple tasks, while being sufficiently lightweight to allow real-time data stream processing. Existing foundational time-series models are often large and only effective in offline settings without stringent time and computational constraints, and where repeated model calibration is not needed. However, when applied to data streams, these models are ineffective due to their size and lack of support for continual calibration, which compromise their ability to deliver accurate real-time responses, their durability, and their deployability in hardware-limited settings. We propose TimeBlocks to enable versatile time-series processing by facilitating the efficient building of lightweight models suitable for multiple tasks under variable conditions. In particular, the method maintains a pool of interchangeable and modular model blocks that can be used to construct new time-series models. When presented with specific time-series data, a routing strategy iteratively selects the most suitable blocks to construct a lightweight and accurate model for the data. We equip TimeBlocks with a method called StreamCore to build a representative small subset of the data stream, which preserves a guaranteed approximation of the stream over time, enabling continual model calibration. An experimental study on multiple data sets and covering multiple tasks shows that TimeBlocks enables to build models capable of outperforming existing baselines.
Estimation of Psychosocial Work Environment Exposures Through Video Object Detection. Proof of Concept Using CCTV Footage
Nov 06, 2024



This paper examines the use of computer vision algorithms to estimate aspects of the psychosocial work environment using CCTV footage. We present a proof of concept for a methodology that detects and tracks people in video footage and estimates interactions between customers and employees by estimating their poses and calculating the duration of their encounters. We propose a pipeline that combines existing object detection and tracking algorithms (YOLOv8 and DeepSORT) with pose estimation algorithms (BlazePose) to estimate the number of customers and employees in the footage as well as the duration of their encounters. We use a simple rule-based approach to classify the interactions as positive, neutral or negative based on three different criteria: distance, duration and pose. The proposed methodology is tested on a small dataset of CCTV footage. While the data is quite limited in particular with respect to the quality of the footage, we have chosen this case as it represents a typical setting where the method could be applied. The results show that the object detection and tracking part of the pipeline has a reasonable performance on the dataset with a high degree of recall and reasonable accuracy. At this stage, the pose estimation is still limited to fully detect the type of interactions due to difficulties in tracking employees in the footage. We conclude that the method is a promising alternative to self-reported measures of the psychosocial work environment and could be used in future studies to obtain external observations of the work environment.
QCore: Data-Efficient, On-Device Continual Calibration for Quantized Models -- Extended Version
Apr 22, 2024



We are witnessing an increasing availability of streaming data that may contain valuable information on the underlying processes. It is thus attractive to be able to deploy machine learning models on edge devices near sensors such that decisions can be made instantaneously, rather than first having to transmit incoming data to servers. To enable deployment on edge devices with limited storage and computational capabilities, the full-precision parameters in standard models can be quantized to use fewer bits. The resulting quantized models are then calibrated using back-propagation and full training data to ensure accuracy. This one-time calibration works for deployments in static environments. However, model deployment in dynamic edge environments call for continual calibration to adaptively adjust quantized models to fit new incoming data, which may have different distributions. The first difficulty in enabling continual calibration on the edge is that the full training data may be too large and thus not always available on edge devices. The second difficulty is that the use of back-propagation on the edge for repeated calibration is too expensive. We propose QCore to enable continual calibration on the edge. First, it compresses the full training data into a small subset to enable effective calibration of quantized models with different bit-widths. We also propose means of updating the subset when new streaming data arrives to reflect changes in the environment, while not forgetting earlier training data. Second, we propose a small bit-flipping network that works with the subset to update quantized model parameters, thus enabling efficient continual calibration without back-propagation. An experimental study, conducted with real-world data in a continual learning setting, offers insight into the properties of QCore and shows that it is capable of outperforming strong baseline methods.
LightTS: Lightweight Time Series Classification with Adaptive Ensemble Distillation -- Extended Version
Feb 24, 2023Due to the sweeping digitalization of processes, increasingly vast amounts of time series data are being produced. Accurate classification of such time series facilitates decision making in multiple domains. State-of-the-art classification accuracy is often achieved by ensemble learning where results are synthesized from multiple base models. This characteristic implies that ensemble learning needs substantial computing resources, preventing their use in resource-limited environments, such as in edge devices. To extend the applicability of ensemble learning, we propose the LightTS framework that compresses large ensembles into lightweight models while ensuring competitive accuracy. First, we propose adaptive ensemble distillation that assigns adaptive weights to different base models such that their varying classification capabilities contribute purposefully to the training of the lightweight model. Second, we propose means of identifying Pareto optimal settings w.r.t. model accuracy and model size, thus enabling users with a space budget to select the most accurate lightweight model. We report on experiments using 128 real-world time series sets and different types of base models that justify key decisions in the design of LightTS and provide evidence that LightTS is able to outperform competitors.
Unsupervised Time Series Outlier Detection with Diversity-Driven Convolutional Ensembles -- Extended Version
Nov 22, 2021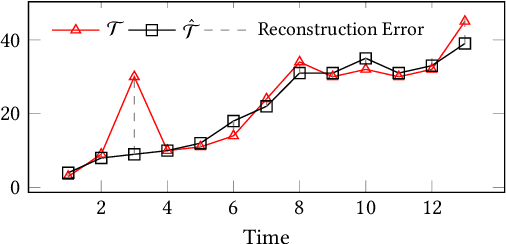
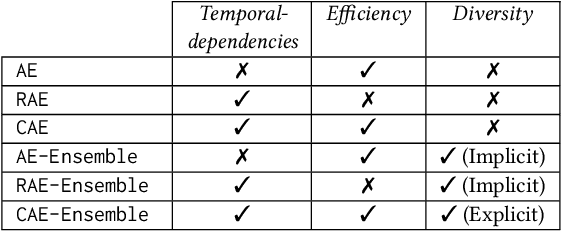
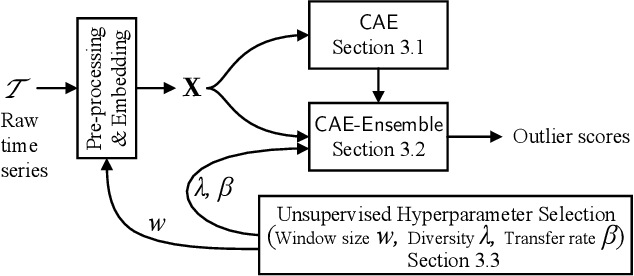
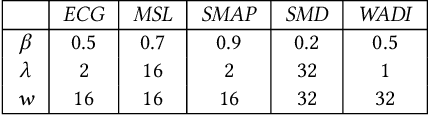
With the sweeping digitalization of societal, medical, industrial, and scientific processes, sensing technologies are being deployed that produce increasing volumes of time series data, thus fueling a plethora of new or improved applications. In this setting, outlier detection is frequently important, and while solutions based on neural networks exist, they leave room for improvement in terms of both accuracy and efficiency. With the objective of achieving such improvements, we propose a diversity-driven, convolutional ensemble. To improve accuracy, the ensemble employs multiple basic outlier detection models built on convolutional sequence-to-sequence autoencoders that can capture temporal dependencies in time series. Further, a novel diversity-driven training method maintains diversity among the basic models, with the aim of improving the ensemble's accuracy. To improve efficiency, the approach enables a high degree of parallelism during training. In addition, it is able to transfer some model parameters from one basic model to another, which reduces training time. We report on extensive experiments using real-world multivariate time series that offer insight into the design choices underlying the new approach and offer evidence that it is capable of improved accuracy and efficiency. This is an extended version of "Unsupervised Time Series Outlier Detection with Diversity-Driven Convolutional Ensembles", to appear in PVLDB 2022.