 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Invariant Adversarial Attack for Evaluating and Enhancing Adversarial Defenses
Jan 29, 2022



Efficient and effective attacks are crucial for reliable evaluation of defenses, and also for developing robust models. Projected Gradient Descent (PGD) attack has been demonstrated to be one of the most successful adversarial attacks. However, the effect of the standard PGD attack can be easily weakened by rescaling the logits, while the original decision of every input will not be changed. To mitigate this issue, in this paper, we propose Scale-Invariant Adversarial Attack (SI-PGD), which utilizes the angle between the features in the penultimate layer and the weights in the softmax layer to guide the generation of adversaries. The cosine angle matrix is used to learn angularly discriminative representation and will not be changed with the rescaling of logits, thus making SI-PGD attack to be stable and effective. We evaluate our attack against multiple defenses and show improved performance when compared with existing attacks. Further, we propose Scale-Invariant (SI) adversarial defense mechanism based on the cosine angle matrix, which can be embedded into the popular adversarial defenses. The experimental results show the defense method with our SI mechanism achieves state-of-the-art performance among multi-step and single-step defenses.
MedRDF: A Robust and Retrain-Less Diagnostic Framework for Medical Pretrained Models Against Adversarial Attack
Nov 29, 2021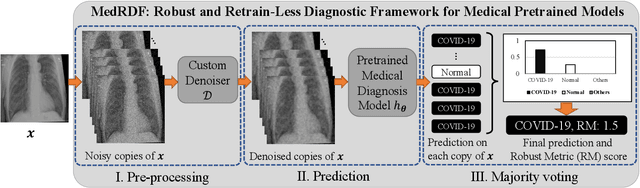
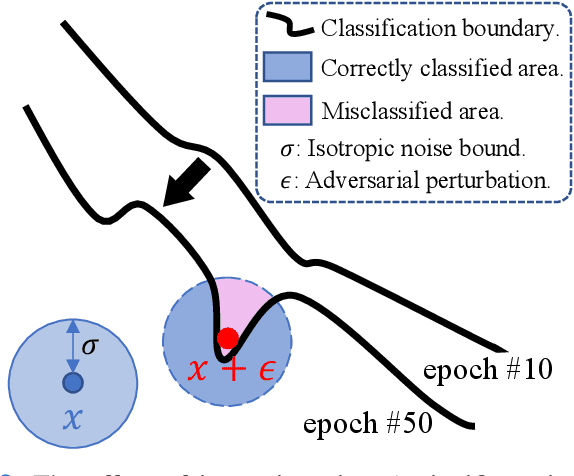
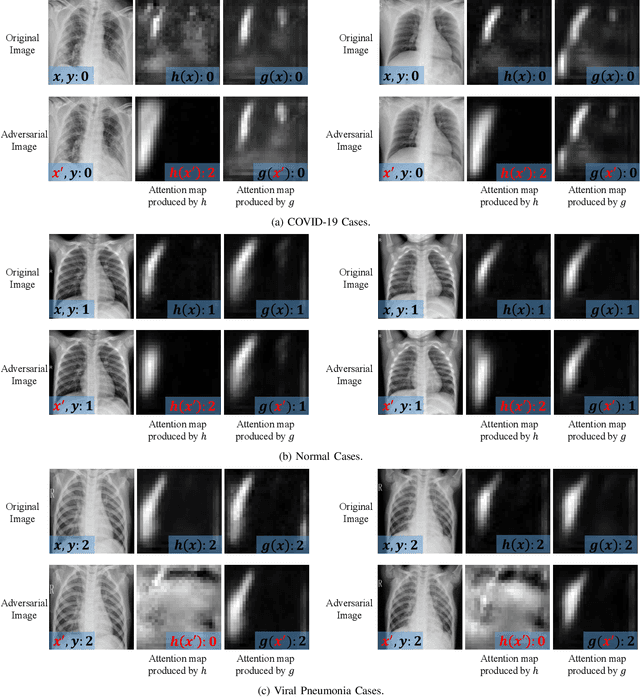
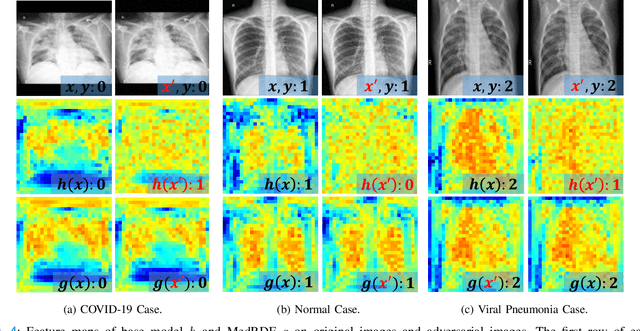
Deep neural networks are discovered to be non-robust when attacked by imperceptible adversarial examples, which is dangerous for it applied into medical diagnostic system that requires high reliability. However, the defense methods that have good effect in natural images may not be suitable for medical diagnostic tasks. The preprocessing methods (e.g., random resizing, compression) may lead to the loss of the small lesions feature in the medical image. Retraining the network on the augmented data set is also not practical for medical models that have already been deployed online. Accordingly, it is necessary to design an easy-to-deploy and effective defense framework for medical diagnostic tasks. In this paper, we propose a Robust and Retrain-Less Diagnostic Framework for Medical pretrained models against adversarial attack (i.e., MedRDF). It acts on the inference time of the pertained medical model. Specifically, for each test image, MedRDF firstly creates a large number of noisy copies of it, and obtains the output labels of these copies from the pretrained medical diagnostic model. Then, based on the labels of these copies, MedRDF outputs the final robust diagnostic result by majority voting. In addition to the diagnostic result, MedRDF produces the Robust Metric (RM) as the confidence of the result. Therefore, it is convenient and reliable to utilize MedRDF to convert pre-trained non-robust diagnostic models into robust ones. The experimental results on COVID-19 and DermaMNIST datasets verify the effectiveness of our MedRDF in improving the robustness of medical diagnostic models.
Towards Evaluating the Robustness of Deep Diagnostic Models by Adversarial Attack
Mar 05, 2021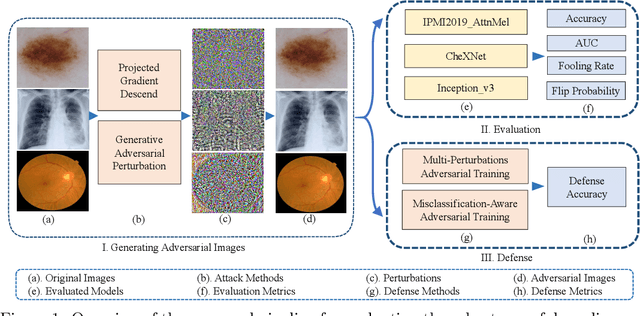
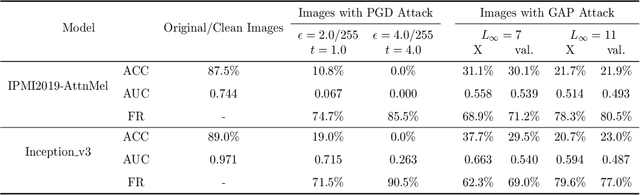
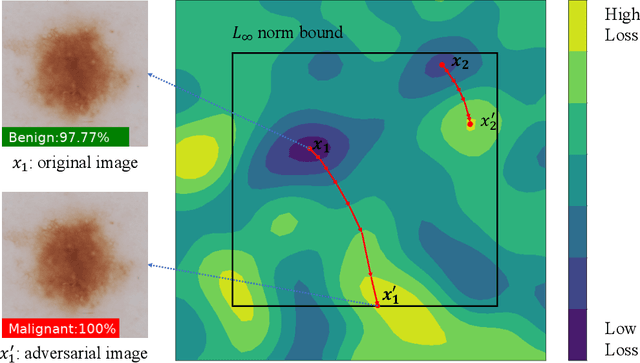
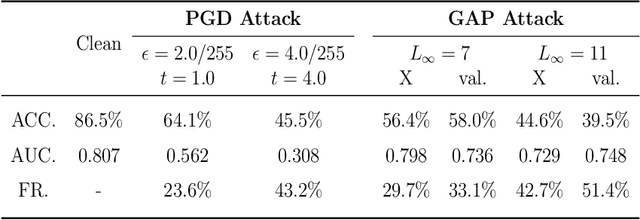
Deep learning models (with neural networks) have been widely used in challenging tasks such as computer-aided disease diagnosis based on medical images. Recent studies have shown deep diagnostic models may not be robust in the inference process and may pose severe security concerns in clinical practice. Among all the factors that make the model not robust, the most serious one is adversarial examples. The so-called "adversarial example" is a well-designed perturbation that is not easily perceived by humans but results in a false output of deep diagnostic models with high confidence. In this paper, we evaluate the robustness of deep diagnostic models by adversarial attack. Specifically, we have performed two types of adversarial attacks to three deep diagnostic models in both single-label and multi-label classification tasks, and found that these models are not reliable when attacked by adversarial example. We have further explored how adversarial examples attack the models, by analyzing their quantitative classification results, intermediate features, discriminability of features and correlation of estimated labels for both original/clean images and those adversarial ones. We have also designed two new defense methods to handle adversarial examples in deep diagnostic models, i.e., Multi-Perturbations Adversarial Training (MPAdvT) and Misclassification-Aware Adversarial Training (MAAdvT). The experimental results have shown that the use of defense methods can significantly improve the robustness of deep diagnostic models against adversarial attacks.
* This version was accepted in the journal Medical Image Analysis (MedIA)
Improving the Certified Robustness of Neural Networks via Consistency Regularization
Jan 20, 2021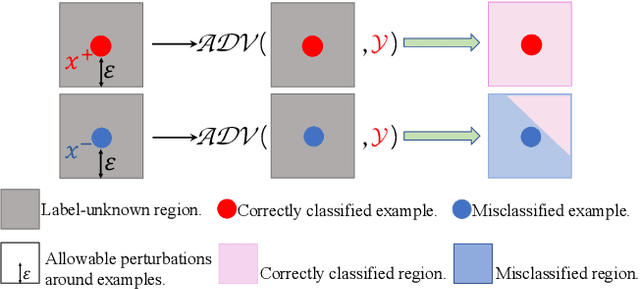
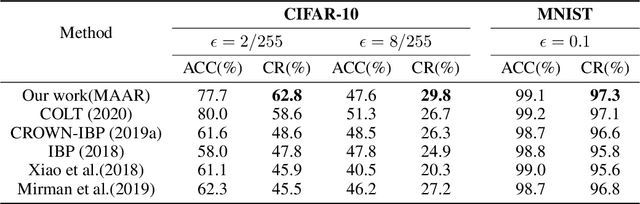
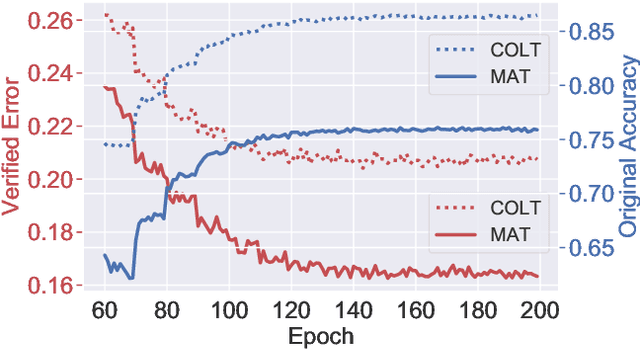
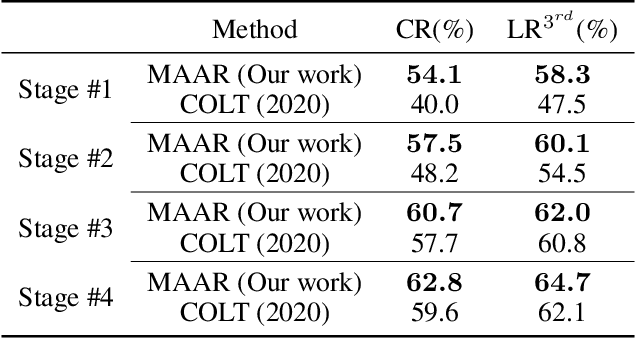
A range of defense methods have been proposed to improve the robustness of neural networks on adversarial examples, among which provable defense methods have been demonstrated to be effective to train neural networks that are certifiably robust to the attacker. However, most of these provable defense methods treat all examples equally during training process, which ignore the inconsistent constraint of certified robustness between correctly classified (natural) and misclassified examples. In this paper, we explore this inconsistency caused by misclassified examples and add a novel consistency regularization term to make better use of the misclassified examples. Specifically, we identified that the certified robustness of network can be significantly improved if the constraint of certified robustness on misclassified examples and correctly classified examples is consistent. Motivated by this discovery, we design a new defense regularization term called Misclassification Aware Adversarial Regularization (MAAR), which constrains the output probability distributions of all examples in the certified region of the misclassified example. Experimental results show that our proposed MAAR achieves the best certified robustness and comparable accuracy on CIFAR-10 and MNIST datasets in comparison with several state-of-the-art methods.
Transport based Graph Kernels
Nov 02, 2020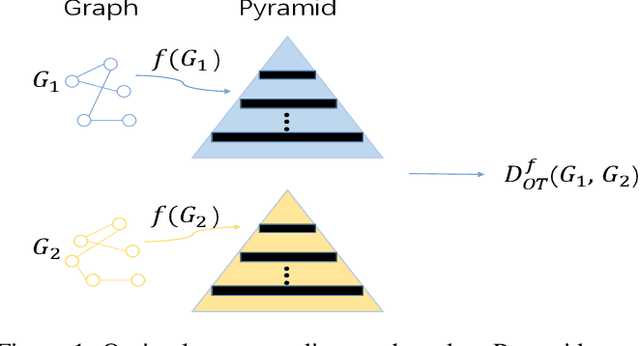
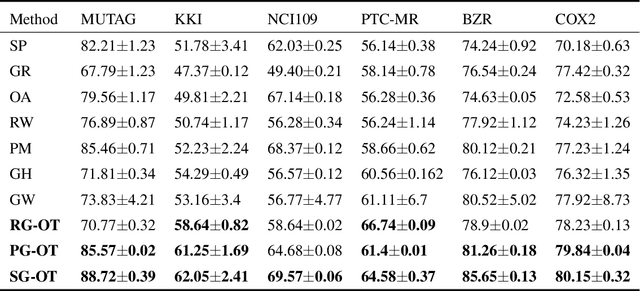
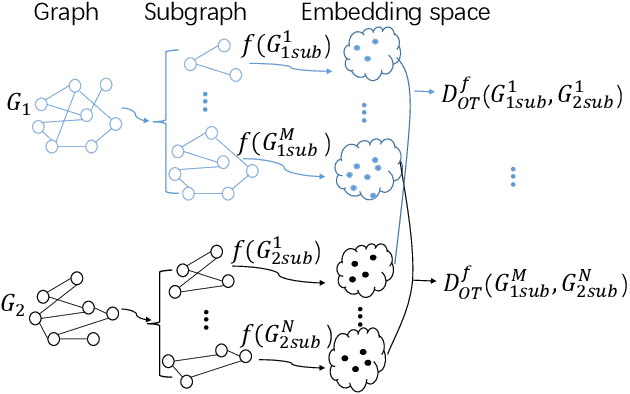
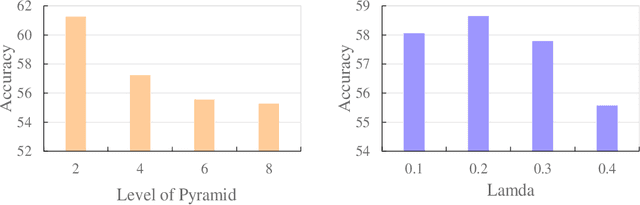
Graph kernel is a powerful tool measuring the similarity between graphs. Most of the existing graph kernels focused on node labels or attributes and ignored graph hierarchical structure information. In order to effectively utilize graph hierarchical structure information, we propose pyramid graph kernel based on optimal transport (OT). Each graph is embedded into hierarchical structures of the pyramid. Then, the OT distance is utilized to measure the similarity between graphs in hierarchical structures. We also utilize the OT distance to measure the similarity between subgraphs and propose subgraph kernel based on OT. The positive semidefinite (p.s.d) of graph kernels based on optimal transport distance is not necessarily possible. We further propose regularized graph kernel based on OT where we add the kernel regularization to the original optimal transport distance to obtain p.s.d kernel matrix. We evaluate the proposed graph kernels on several benchmark classification tasks and compare their performance with the existing state-of-the-art graph kernels. In most cases, our proposed graph kernel algorithms outperform the competing methods.
Shared Space Transfer Learning for analyzing multi-site fMRI data
Oct 24, 2020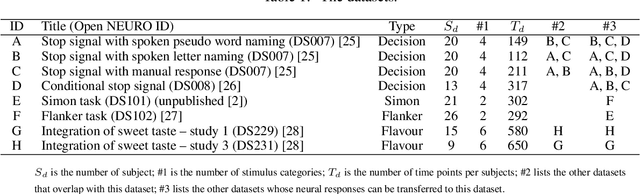
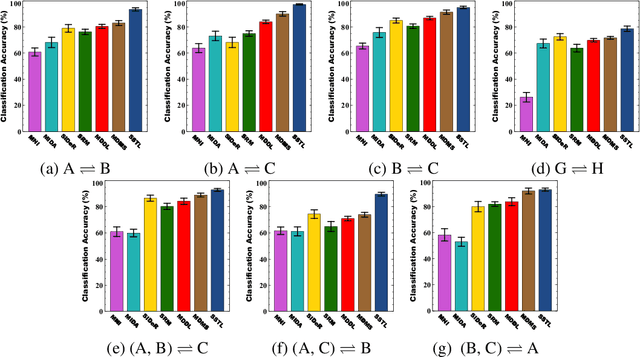
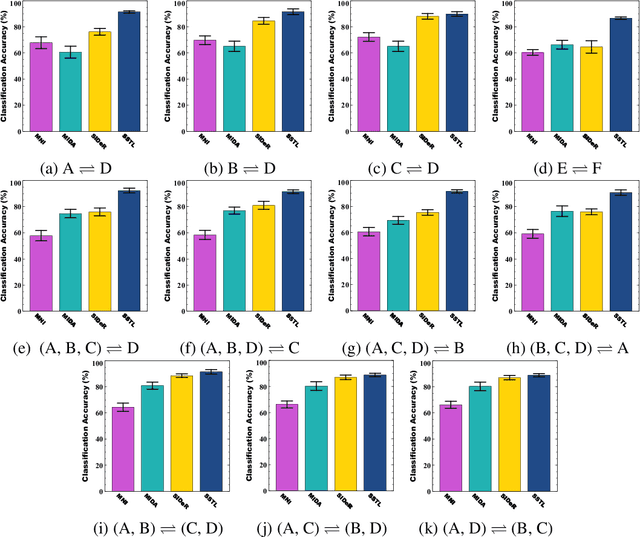
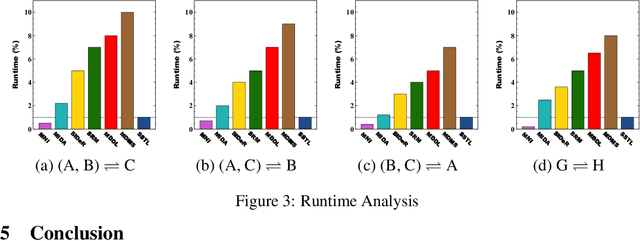
Multi-voxel pattern analysis (MVPA) learns predictive models from task-based functional magnetic resonance imaging (fMRI) data, for distinguishing when subjects are performing different cognitive tasks -- e.g., watching movies or making decisions. MVPA works best with a well-designed feature set and an adequate sample size. However, most fMRI datasets are noisy, high-dimensional, expensive to collect, and with small sample sizes. Further, training a robust, generalized predictive model that can analyze homogeneous cognitive tasks provided by multi-site fMRI datasets has additional challenges. This paper proposes the Shared Space Transfer Learning (SSTL) as a novel transfer learning (TL) approach that can functionally align homogeneous multi-site fMRI datasets, and so improve the prediction performance in every site. SSTL first extracts a set of common features for all subjects in each site. It then uses TL to map these site-specific features to a site-independent shared space in order to improve the performance of the MVPA. SSTL uses a scalable optimization procedure that works effectively for high-dimensional fMRI datasets. The optimization procedure extracts the common features for each site by using a single-iteration algorithm and maps these site-specific common features to the site-independent shared space. We evaluate the effectiveness of the proposed method for transferring between various cognitive tasks. Our comprehensive experiments validate that SSTL achieves superior performance to other state-of-the-art analysis techniques.
ASMFS: Adaptive-Similarity-based Multi-modality Feature Selection for Classification of Alzheimer's Disease
Oct 16, 2020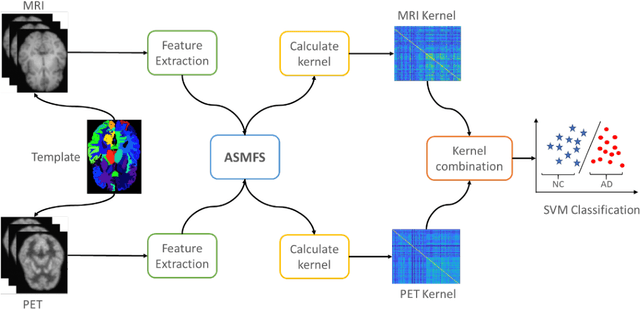
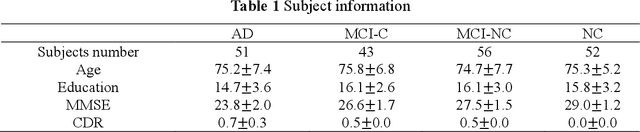
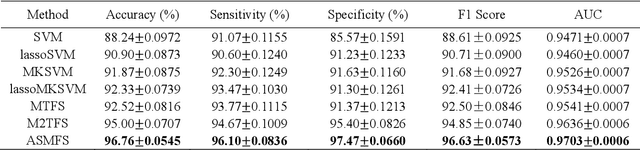
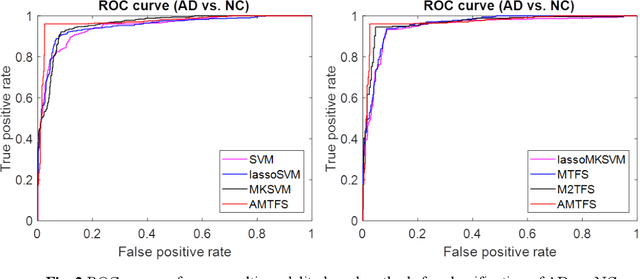
With the increasing amounts of high-dimensional heterogeneous data to be processed, multi-modality feature selection has become an important research direction in medical image analysis. Traditional methods usually depict the data structure using fixed and predefined similarity matrix for each modality separately, without considering the potential relationship structure across different modalities. In this paper, we propose a novel multi-modality feature selection method, which performs feature selection and local similarity learning simultaniously. Specially, a similarity matrix is learned by jointly considering different imaging modalities. And at the same time, feature selection is conducted by imposing sparse l_{2, 1} norm constraint. The effectiveness of our proposed joint learning method can be well demonstrated by the experimental results on Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, which outperforms existing the state-of-the-art multi-modality approaches.
Deep Representational Similarity Learning for analyzing neural signatures in task-based fMRI dataset
Sep 28, 2020
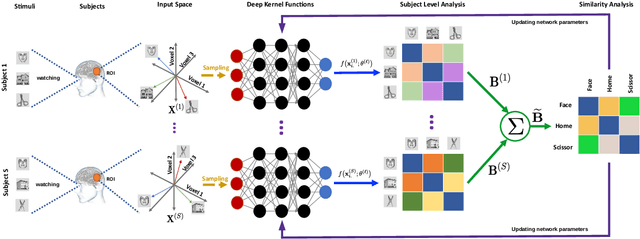
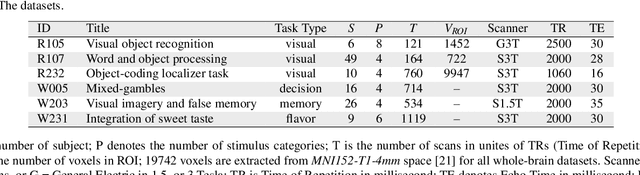
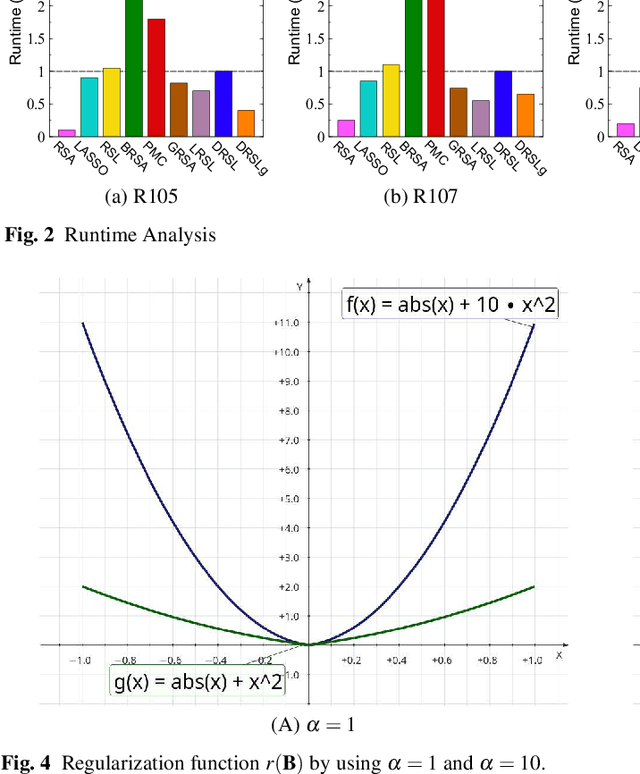
Similarity analysis is one of the crucial steps in most fMRI studies. Representational Similarity Analysis (RSA) can measure similarities of neural signatures generated by different cognitive states. This paper develops Deep Representational Similarity Learning (DRSL), a deep extension of RSA that is appropriate for analyzing similarities between various cognitive tasks in fMRI datasets with a large number of subjects, and high-dimensionality -- such as whole-brain images. Unlike the previous methods, DRSL is not limited by a linear transformation or a restricted fixed nonlinear kernel function -- such as Gaussian kernel. DRSL utilizes a multi-layer neural network for mapping neural responses to linear space, where this network can implement a customized nonlinear transformation for each subject separately. Furthermore, utilizing a gradient-based optimization in DRSL can significantly reduce runtime of analysis on large datasets because it uses a batch of samples in each iteration rather than all neural responses to find an optimal solution. Empirical studies on multi-subject fMRI datasets with various tasks -- including visual stimuli, decision making, flavor, and working memory -- confirm that the proposed method achieves superior performance to other state-of-the-art RSA algorithms.
Ordinal Pattern Kernel for Brain Connectivity Network Classification
Aug 18, 2020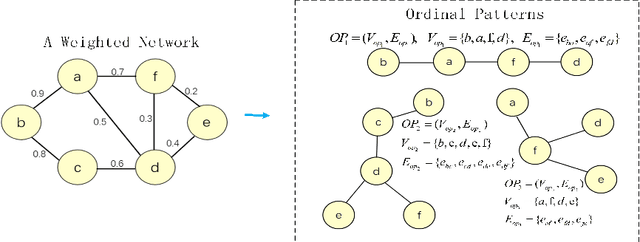
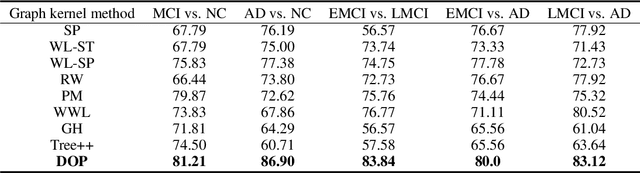
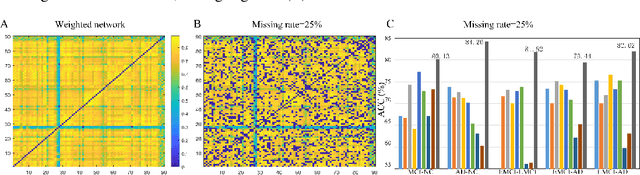
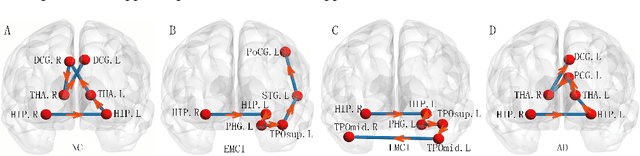
Brain connectivity networks, which characterize the functional or structural interaction of brain regions, has been widely used for brain disease classification. Kernel-based method, such as graph kernel (i.e., kernel defined on graphs), has been proposed for measuring the similarity of brain networks, and yields the promising classification performance. However, most of graph kernels are built on unweighted graph (i.e., network) with edge present or not, and neglecting the valuable weight information of edges in brain connectivity network, with edge weights conveying the strengths of temporal correlation or fiber connection between brain regions. Accordingly, in this paper, we present an ordinal pattern kernel for brain connectivity network classification. Different with existing graph kernels that measures the topological similarity of unweighted graphs, the proposed ordinal pattern kernels calculate the similarity of weighted networks by comparing ordinal patterns from weighted networks. To evaluate the effectiveness of the proposed ordinal kernel, we further develop a depth-first-based ordinal pattern kernel, and perform extensive experiments in a real dataset of brain disease from ADNI database. The results demonstrate that our proposed ordinal pattern kernel can achieve better classification performance compared with state-of-the-art graph kernels.
An Explainable 3D Residual Self-Attention Deep Neural Network FOR Joint Atrophy Localization and Alzheimer's Disease Diagnosis using Structural MRI
Aug 10, 2020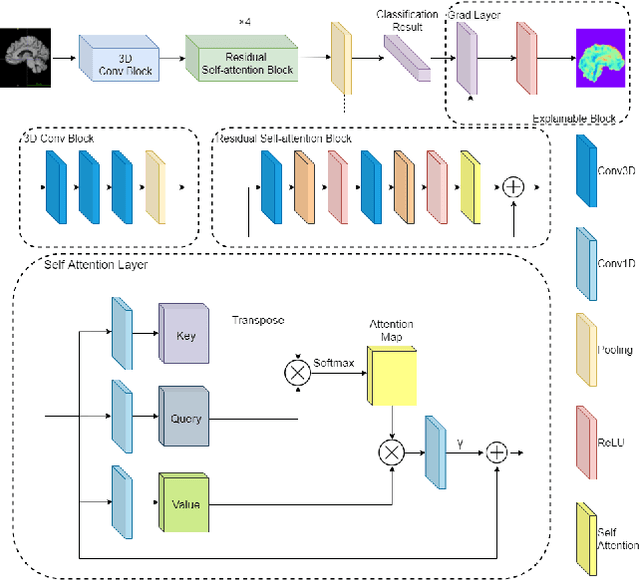
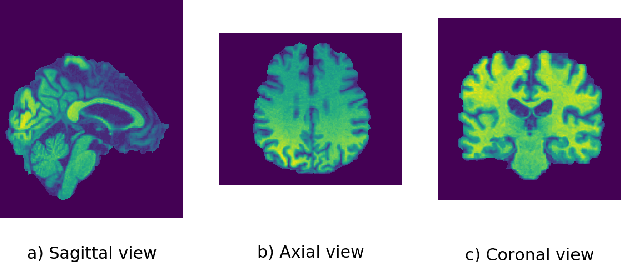
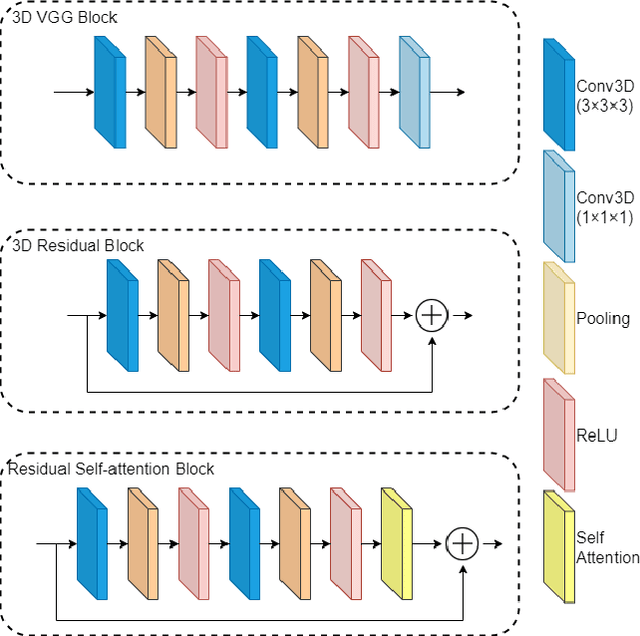
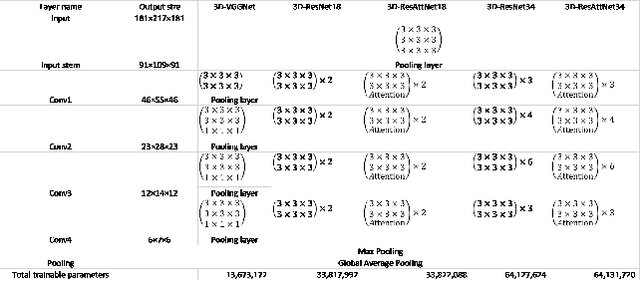
Computer-aided early diagnosis of Alzheimer's disease (AD) and its prodromal form mild cognitive impairment (MCI) based on structure Magnetic Resonance Imaging (sMRI) has provided a cost-effective and objective way for early prevention and treatment of disease progression, leading to improved patient care. In this work, we have proposed a novel computer-aided approach for early diagnosis of AD by introducing an explainable 3D Residual Attention Deep Neural Network (3D ResAttNet) for end-to-end learning from sMRI scans. Different from the existing approaches, the novelty of our approach is three-fold: 1) A Residual Self-Attention Deep Neural Network has been proposed to capture local, global and spatial information of MR images to improve diagnostic performance; 2) An explainable method using Gradient-based Localization Class Activation mapping (Grad-CAM) has been introduced to improve the explainable of the proposed method; 3) This work has provided a full end-to-end learning solution for automated disease diagnosis. Our proposed 3D ResAttNet method has been evaluated on a large cohort of subjects from real dataset for two changeling classification tasks (i.e. Alzheimer's disease (AD) vs. Normal cohort (NC) and progressive MCI (pMCI) vs. stable MCI (sMCI)). The experimental results show that the proposed approach outperforms the state-of-the-art models with significant performance improvement. The accuracy for AD vs. NC and sMCI vs. pMCI task are 97.1% and 84.1% respectively. The explainable mechanism in our approach regions is able to identify and highlight the contribution of the important brain parts (hippocampus, lateral ventricle and most parts of the cortex) for transparent decisions.