 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA Therapy: Exploring Answer Differences by Visually Grounding Answers
Aug 24, 2023Visual question answering is a task of predicting the answer to a question about an image. Given that different people can provide different answers to a visual question, we aim to better understand why with answer groundings. We introduce the first dataset that visually grounds each unique answer to each visual question, which we call VQAAnswerTherapy. We then propose two novel problems of predicting whether a visual question has a single answer grounding and localizing all answer groundings. We benchmark modern algorithms for these novel problems to show where they succeed and struggle. The dataset and evaluation server can be found publicly at https://vizwiz.org/tasks-and-datasets/vqa-answer-therapy/.
Interactive Segmentation for Diverse Gesture Types Without Context
Jul 20, 2023Interactive segmentation entails a human marking an image to guide how a model either creates or edits a segmentation. Our work addresses limitations of existing methods: they either only support one gesture type for marking an image (e.g., either clicks or scribbles) or require knowledge of the gesture type being employed, and require specifying whether marked regions should be included versus excluded in the final segmentation. We instead propose a simplified interactive segmentation task where a user only must mark an image, where the input can be of any gesture type without specifying the gesture type. We support this new task by introducing the first interactive segmentation dataset with multiple gesture types as well as a new evaluation metric capable of holistically evaluating interactive segmentation algorithms. We then analyze numerous interactive segmentation algorithms, including ones adapted for our novel task. While we observe promising performance overall, we also highlight areas for future improvement. To facilitate further extensions of this work, we publicly share our new dataset at https://github.com/joshmyersdean/dig.
Helping Visually Impaired People Take Better Quality Pictures
May 14, 2023Perception-based image analysis technologies can be used to help visually impaired people take better quality pictures by providing automated guidance, thereby empowering them to interact more confidently on social media. The photographs taken by visually impaired users often suffer from one or both of two kinds of quality issues: technical quality (distortions), and semantic quality, such as framing and aesthetic composition. Here we develop tools to help them minimize occurrences of common technical distortions, such as blur, poor exposure, and noise. We do not address the complementary problems of semantic quality, leaving that aspect for future work. The problem of assessing and providing actionable feedback on the technical quality of pictures captured by visually impaired users is hard enough, owing to the severe, commingled distortions that often occur. To advance progress on the problem of analyzing and measuring the technical quality of visually impaired user-generated content (VI-UGC), we built a very large and unique subjective image quality and distortion dataset. This new perceptual resource, which we call the LIVE-Meta VI-UGC Database, contains $40$K real-world distorted VI-UGC images and $40$K patches, on which we recorded $2.7$M human perceptual quality judgments and $2.7$M distortion labels. Using this psychometric resource we also created an automatic blind picture quality and distortion predictor that learns local-to-global spatial quality relationships, achieving state-of-the-art prediction performance on VI-UGC pictures, significantly outperforming existing picture quality models on this unique class of distorted picture data. We also created a prototype feedback system that helps to guide users to mitigate quality issues and take better quality pictures, by creating a multi-task learning framework.
Salient Object Detection for Images Taken by People With Vision Impairments
Jan 12, 2023Salient object detection is the task of producing a binary mask for an image that deciphers which pixels belong to the foreground object versus background. We introduce a new salient object detection dataset using images taken by people who are visually impaired who were seeking to better understand their surroundings, which we call VizWiz-SalientObject. Compared to seven existing datasets, VizWiz-SalientObject is the largest (i.e., 32,000 human-annotated images) and contains unique characteristics including a higher prevalence of text in the salient objects (i.e., in 68\% of images) and salient objects that occupy a larger ratio of the images (i.e., on average, $\sim$50\% coverage). We benchmarked seven modern salient object detection methods on our dataset and found they struggle most with images featuring salient objects that are large, have less complex boundaries, and lack text as well as for lower quality images. We invite the broader community to work on our new dataset challenge by publicly sharing the dataset at https://vizwiz.org/tasks-and-datasets/salient-object .
Line Search-Based Feature Transformation for Fast, Stable, and Tunable Content-Style Control in Photorealistic Style Transfer
Oct 12, 2022
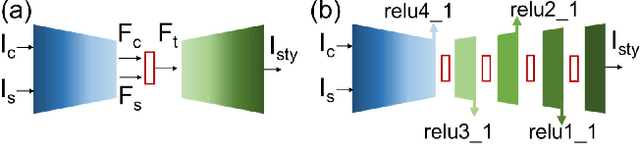
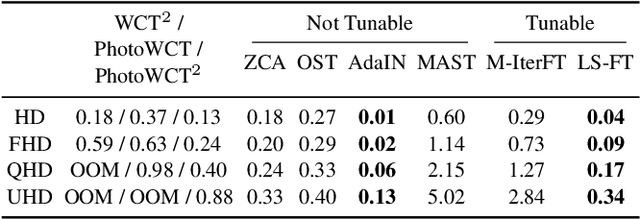

Photorealistic style transfer is the task of synthesizing a realistic-looking image when adapting the content from one image to appear in the style of another image. Modern models commonly embed a transformation that fuses features describing the content image and style image and then decodes the resulting feature into a stylized image. We introduce a general-purpose transformation that enables controlling the balance between how much content is preserved and the strength of the infused style. We offer the first experiments that demonstrate the performance of existing transformations across different style transfer models and demonstrate how our transformation performs better in its ability to simultaneously run fast, produce consistently reasonable results, and control the balance between content and style in different models. To support reproducing our method and models, we share the code at https://github.com/chiutaiyin/LS-FT.
VizWiz-FewShot: Locating Objects in Images Taken by People With Visual Impairments
Jul 24, 2022
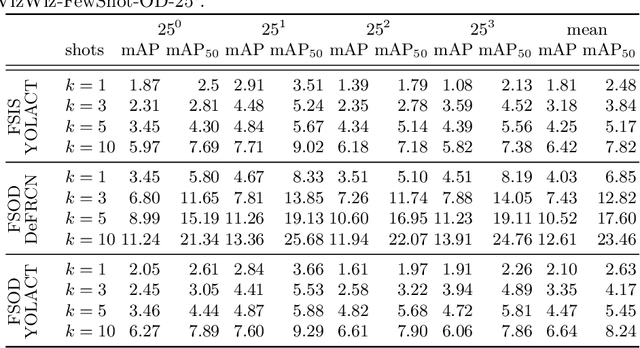
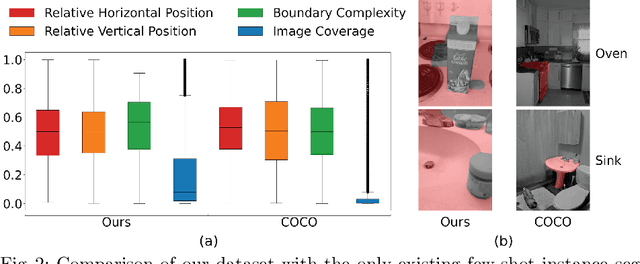
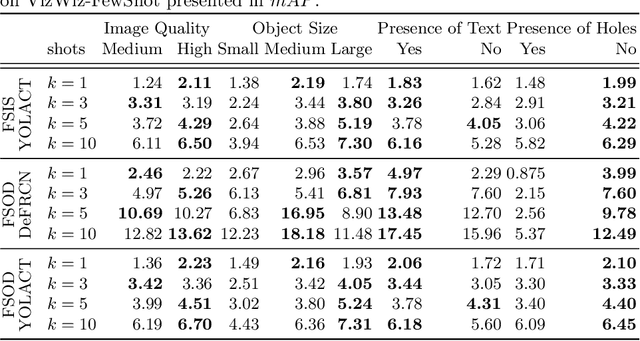
We introduce a few-shot localization dataset originating from photographers who authentically were trying to learn about the visual content in the images they took. It includes nearly 10,000 segmentations of 100 categories in over 4,500 images that were taken by people with visual impairments. Compared to existing few-shot object detection and instance segmentation datasets, our dataset is the first to locate holes in objects (e.g., found in 12.3\% of our segmentations), it shows objects that occupy a much larger range of sizes relative to the images, and text is over five times more common in our objects (e.g., found in 22.4\% of our segmentations). Analysis of three modern few-shot localization algorithms demonstrates that they generalize poorly to our new dataset. The algorithms commonly struggle to locate objects with holes, very small and very large objects, and objects lacking text. To encourage a larger community to work on these unsolved challenges, we publicly share our annotated few-shot dataset at https://vizwiz.org .
PCA-Based Knowledge Distillation Towards Lightweight and Content-Style Balanced Photorealistic Style Transfer Models
Mar 25, 2022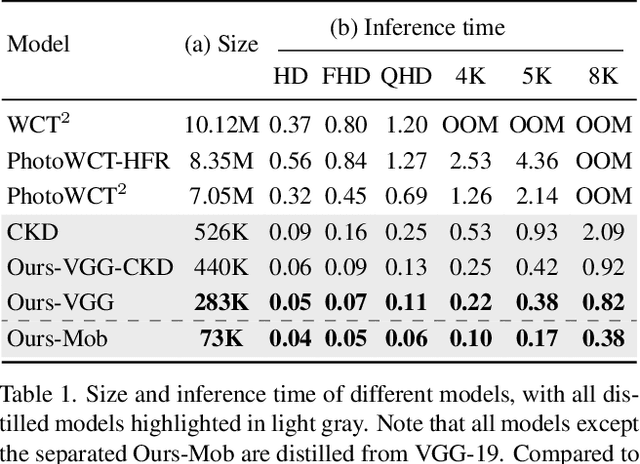
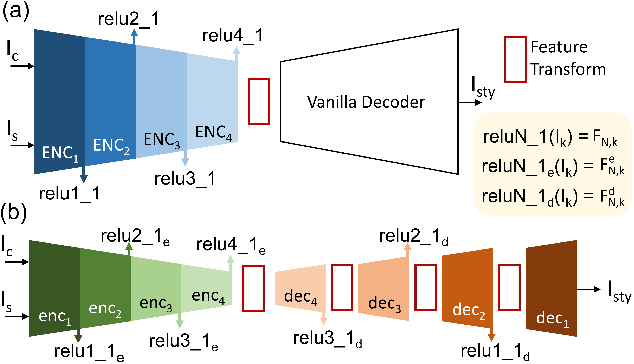
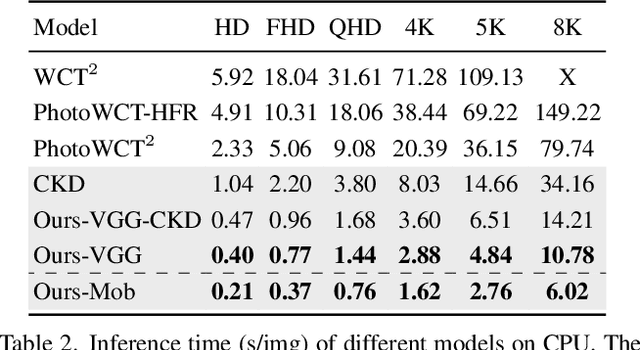
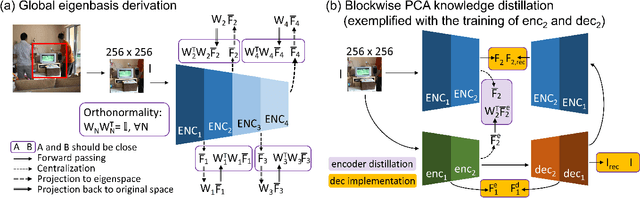
Photorealistic style transfer entails transferring the style of a reference image to another image so the result seems like a plausible photo. Our work is inspired by the observation that existing models are slow due to their large sizes. We introduce PCA-based knowledge distillation to distill lightweight models and show it is motivated by theory. To our knowledge, this is the first knowledge distillation method for photorealistic style transfer. Our experiments demonstrate its versatility for use with different backbone architectures, VGG and MobileNet, across six image resolutions. Compared to existing models, our top-performing model runs at speeds 5-20x faster using at most 1\% of the parameters. Additionally, our distilled models achieve a better balance between stylization strength and content preservation than existing models. To support reproducing our method and models, we share the code at \textit{https://github.com/chiutaiyin/PCA-Knowledge-Distillation}.
Grounding Answers for Visual Questions Asked by Visually Impaired People
Feb 04, 2022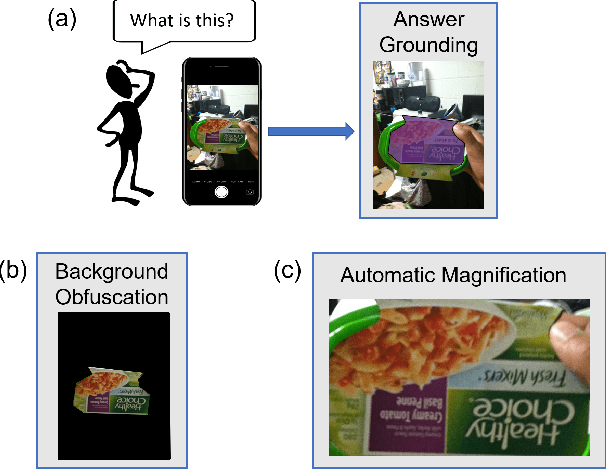
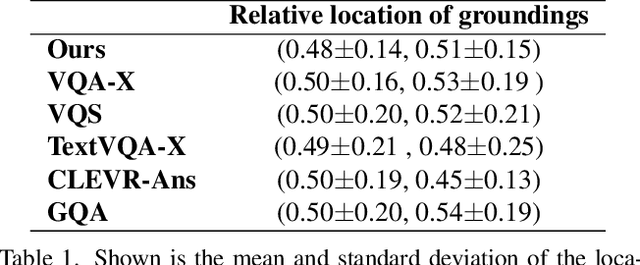
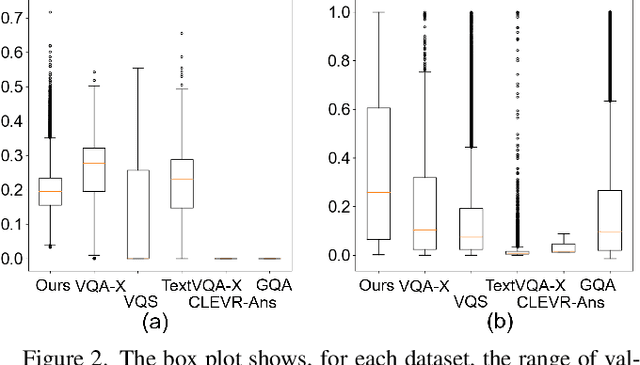

Visual question answering is the task of answering questions about images. We introduce the VizWiz-VQA-Grounding dataset, the first dataset that visually grounds answers to visual questions asked by people with visual impairments. We analyze our dataset and compare it with five VQA-Grounding datasets to demonstrate what makes it similar and different. We then evaluate the SOTA VQA and VQA-Grounding models and demonstrate that current SOTA algorithms often fail to identify the correct visual evidence where the answer is located. These models regularly struggle when the visual evidence occupies a small fraction of the image, for images that are higher quality, as well as for visual questions that require skills in text recognition. The dataset, evaluation server, and leaderboard all can be found at the following link: https://vizwiz.org/tasks-and-datasets/answer-grounding-for-vqa/.
Generalized Few-Shot Semantic Segmentation: All You Need is Fine-Tuning
Dec 21, 2021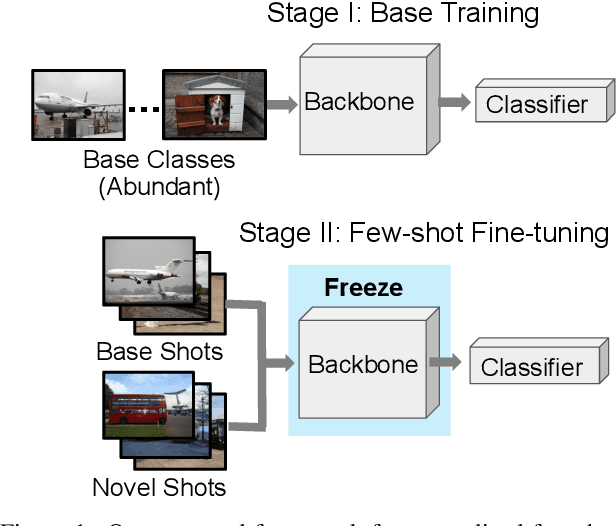
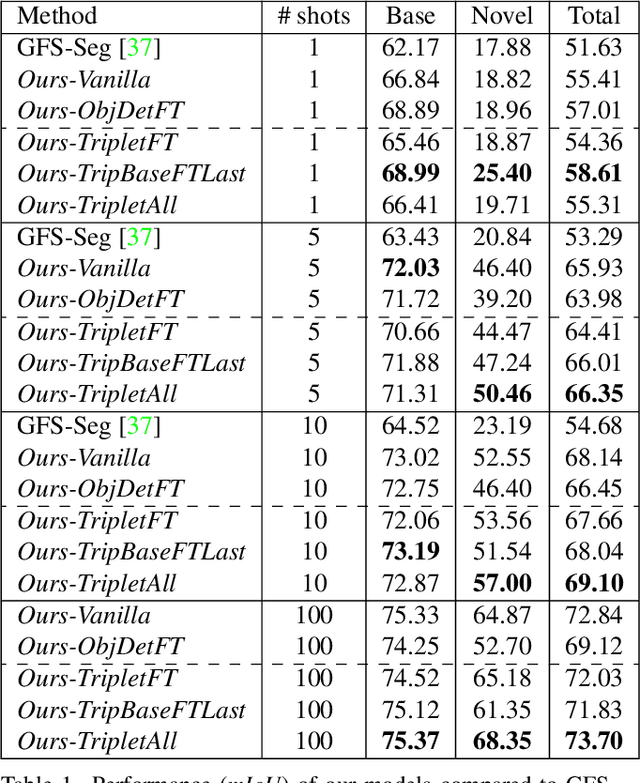
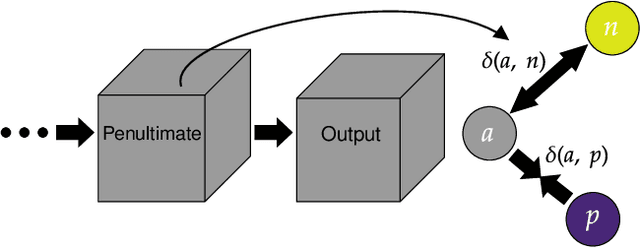
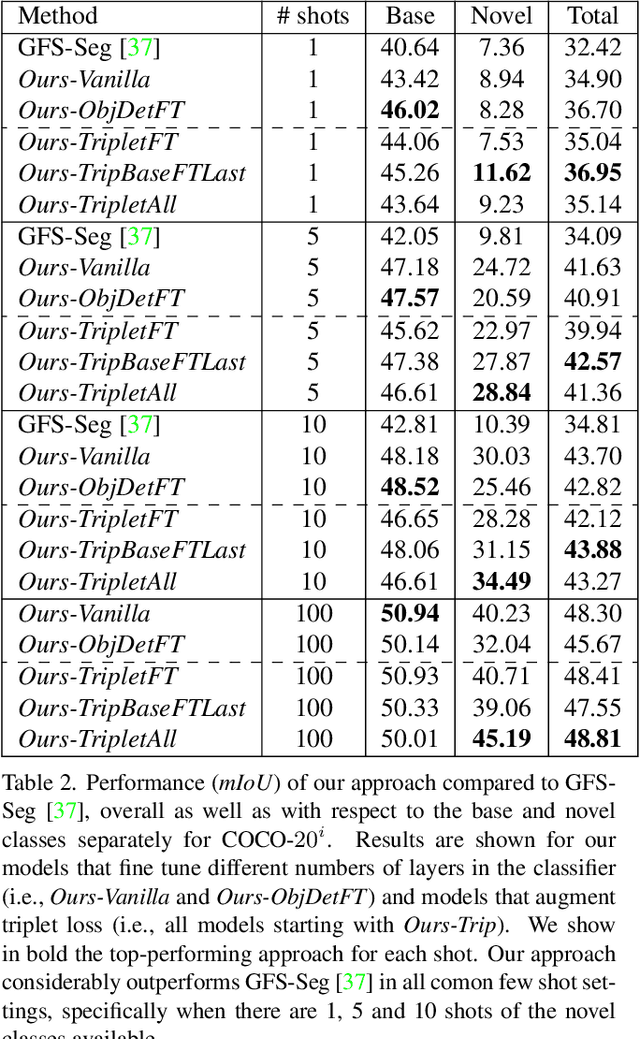
Generalized few-shot semantic segmentation was introduced to move beyond only evaluating few-shot segmentation models on novel classes to include testing their ability to remember base classes. While all approaches currently are based on meta-learning, they perform poorly and saturate in learning after observing only a few shots. We propose the first fine-tuning solution, and demonstrate that it addresses the saturation problem while achieving state-of-art results on two datasets, PASCAL-$5^i$ and COCO-$20^i$. We also show it outperforms existing methods whether fine-tuning multiple final layers or only the final layer. Finally, we present a triplet loss regularization that shows how to redistribute the balance of performance between novel and base categories so that there is a smaller gap between them.
PhotoWCT$^2$: Compact Autoencoder for Photorealistic Style Transfer Resulting from Blockwise Training and Skip Connections of High-Frequency Residuals
Oct 22, 2021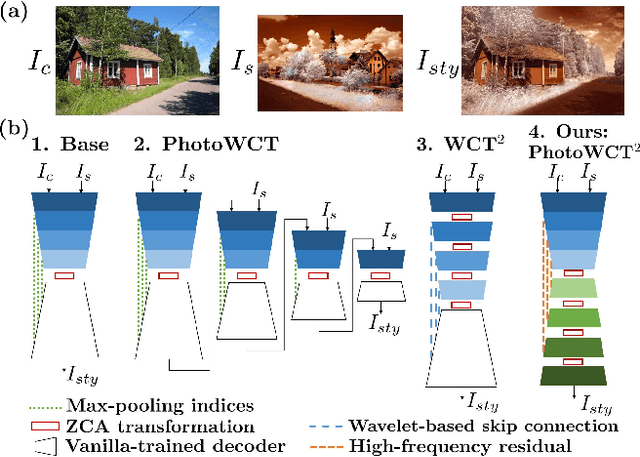

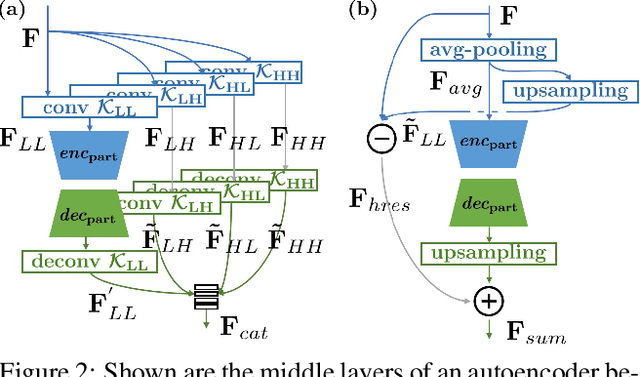
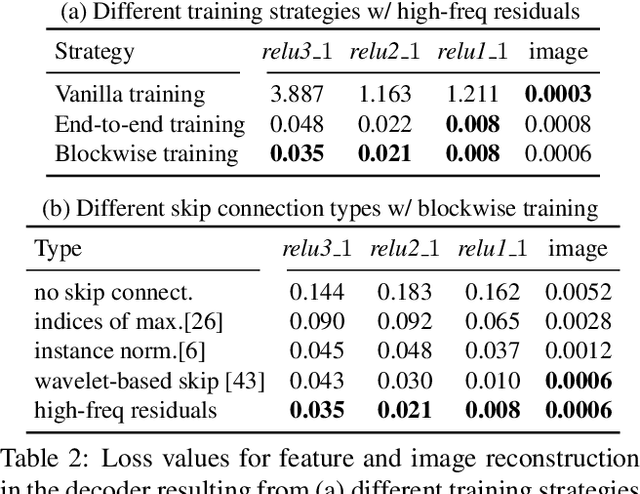
Photorealistic style transfer is an image editing task with the goal to modify an image to match the style of another image while ensuring the result looks like a real photograph. A limitation of existing models is that they have many parameters, which in turn prevents their use for larger image resolutions and leads to slower run-times. We introduce two mechanisms that enable our design of a more compact model that we call PhotoWCT$^2$, which preserves state-of-art stylization strength and photorealism. First, we introduce blockwise training to perform coarse-to-fine feature transformations that enable state-of-art stylization strength in a single autoencoder in place of the inefficient cascade of four autoencoders used in PhotoWCT. Second, we introduce skip connections of high-frequency residuals in order to preserve image quality when applying the sequential coarse-to-fine feature transformations. Our PhotoWCT$^2$ model requires fewer parameters (e.g., 30.3\% fewer) while supporting higher resolution images (e.g., 4K) and achieving faster stylization than existing models.