 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Motion Diffusion
Feb 12, 2023



Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at https://sinmdm.github.io/SinMDM-page.
TEXTure: Text-Guided Texturing of 3D Shapes
Feb 03, 2023In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing.
Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
Jan 31, 2023Recent text-to-image generative models have demonstrated an unparalleled ability to generate diverse and creative imagery guided by a target text prompt. While revolutionary, current state-of-the-art diffusion models may still fail in generating images that fully convey the semantics in the given text prompt. We analyze the publicly available Stable Diffusion model and assess the existence of catastrophic neglect, where the model fails to generate one or more of the subjects from the input prompt. Moreover, we find that in some cases the model also fails to correctly bind attributes (e.g., colors) to their corresponding subjects. To help mitigate these failure cases, we introduce the concept of Generative Semantic Nursing (GSN), where we seek to intervene in the generative process on the fly during inference time to improve the faithfulness of the generated images. Using an attention-based formulation of GSN, dubbed Attend-and-Excite, we guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen - or excite - their activations, encouraging the model to generate all subjects described in the text prompt. We compare our approach to alternative approaches and demonstrate that it conveys the desired concepts more faithfully across a range of text prompts.
Domain Expansion of Image Generators
Jan 12, 2023Can one inject new concepts into an already trained generative model, while respecting its existing structure and knowledge? We propose a new task - domain expansion - to address this. Given a pretrained generator and novel (but related) domains, we expand the generator to jointly model all domains, old and new, harmoniously. First, we note the generator contains a meaningful, pretrained latent space. Is it possible to minimally perturb this hard-earned representation, while maximally representing the new domains? Interestingly, we find that the latent space offers unused, "dormant" directions, which do not affect the output. This provides an opportunity: By "repurposing" these directions, we can represent new domains without perturbing the original representation. In fact, we find that pretrained generators have the capacity to add several - even hundreds - of new domains! Using our expansion method, one "expanded" model can supersede numerous domain-specific models, without expanding the model size. Additionally, a single expanded generator natively supports smooth transitions between domains, as well as composition of domains. Code and project page available at https://yotamnitzan.github.io/domain-expansion/.
CLIPascene: Scene Sketching with Different Types and Levels of Abstraction
Nov 30, 2022In this paper, we present a method for converting a given scene image into a sketch using different types and multiple levels of abstraction. We distinguish between two types of abstraction. The first considers the fidelity of the sketch, varying its representation from a more precise portrayal of the input to a looser depiction. The second is defined by the visual simplicity of the sketch, moving from a detailed depiction to a sparse sketch. Using an explicit disentanglement into two abstraction axes -- and multiple levels for each one -- provides users additional control over selecting the desired sketch based on their personal goals and preferences. To form a sketch at a given level of fidelity and simplification, we train two MLP networks. The first network learns the desired placement of strokes, while the second network learns to gradually remove strokes from the sketch without harming its recognizability and semantics. Our approach is able to generate sketches of complex scenes including those with complex backgrounds (e.g., natural and urban settings) and subjects (e.g., animals and people) while depicting gradual abstractions of the input scene in terms of fidelity and simplicity.
Sketch-Guided Text-to-Image Diffusion Models
Nov 24, 2022Text-to-Image models have introduced a remarkable leap in the evolution of machine learning, demonstrating high-quality synthesis of images from a given text-prompt. However, these powerful pretrained models still lack control handles that can guide spatial properties of the synthesized images. In this work, we introduce a universal approach to guide a pretrained text-to-image diffusion model, with a spatial map from another domain (e.g., sketch) during inference time. Unlike previous works, our method does not require to train a dedicated model or a specialized encoder for the task. Our key idea is to train a Latent Guidance Predictor (LGP) - a small, per-pixel, Multi-Layer Perceptron (MLP) that maps latent features of noisy images to spatial maps, where the deep features are extracted from the core Denoising Diffusion Probabilistic Model (DDPM) network. The LGP is trained only on a few thousand images and constitutes a differential guiding map predictor, over which the loss is computed and propagated back to push the intermediate images to agree with the spatial map. The per-pixel training offers flexibility and locality which allows the technique to perform well on out-of-domain sketches, including free-hand style drawings. We take a particular focus on the sketch-to-image translation task, revealing a robust and expressive way to generate images that follow the guidance of a sketch of arbitrary style or domain. Project page: sketch-guided-diffusion.github.io
Null-text Inversion for Editing Real Images using Guided Diffusion Models
Nov 17, 2022



Recent text-guided diffusion models provide powerful image generation capabilities. Currently, a massive effort is given to enable the modification of these images using text only as means to offer intuitive and versatile editing. To edit a real image using these state-of-the-art tools, one must first invert the image with a meaningful text prompt into the pretrained model's domain. In this paper, we introduce an accurate inversion technique and thus facilitate an intuitive text-based modification of the image. Our proposed inversion consists of two novel key components: (i) Pivotal inversion for diffusion models. While current methods aim at mapping random noise samples to a single input image, we use a single pivotal noise vector for each timestamp and optimize around it. We demonstrate that a direct inversion is inadequate on its own, but does provide a good anchor for our optimization. (ii) NULL-text optimization, where we only modify the unconditional textual embedding that is used for classifier-free guidance, rather than the input text embedding. This allows for keeping both the model weights and the conditional embedding intact and hence enables applying prompt-based editing while avoiding the cumbersome tuning of the model's weights. Our Null-text inversion, based on the publicly available Stable Diffusion model, is extensively evaluated on a variety of images and prompt editing, showing high-fidelity editing of real images.
Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures
Nov 14, 2022Text-guided image generation has progressed rapidly in recent years, inspiring major breakthroughs in text-guided shape generation. Recently, it has been shown that using score distillation, one can successfully text-guide a NeRF model to generate a 3D object. We adapt the score distillation to the publicly available, and computationally efficient, Latent Diffusion Models, which apply the entire diffusion process in a compact latent space of a pretrained autoencoder. As NeRFs operate in image space, a naive solution for guiding them with latent score distillation would require encoding to the latent space at each guidance step. Instead, we propose to bring the NeRF to the latent space, resulting in a Latent-NeRF. Analyzing our Latent-NeRF, we show that while Text-to-3D models can generate impressive results, they are inherently unconstrained and may lack the ability to guide or enforce a specific 3D structure. To assist and direct the 3D generation, we propose to guide our Latent-NeRF using a Sketch-Shape: an abstract geometry that defines the coarse structure of the desired object. Then, we present means to integrate such a constraint directly into a Latent-NeRF. This unique combination of text and shape guidance allows for increased control over the generation process. We also show that latent score distillation can be successfully applied directly on 3D meshes. This allows for generating high-quality textures on a given geometry. Our experiments validate the power of our different forms of guidance and the efficiency of using latent rendering. Implementation is available at https://github.com/eladrich/latent-nerf
Human Motion Diffusion Model
Oct 03, 2022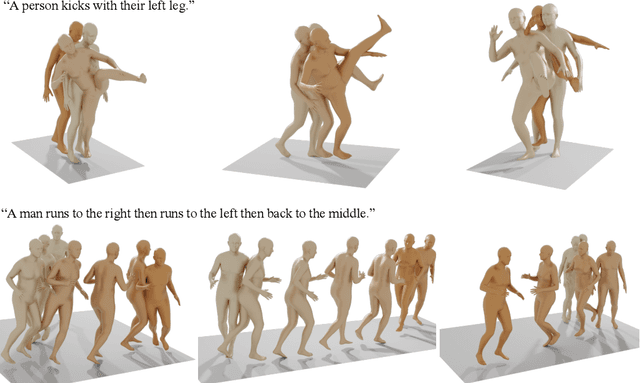
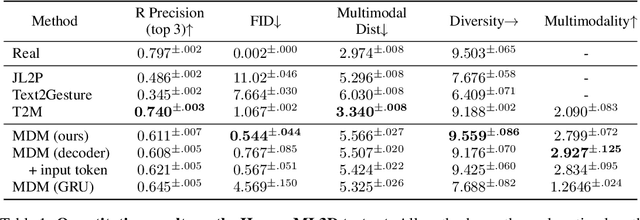
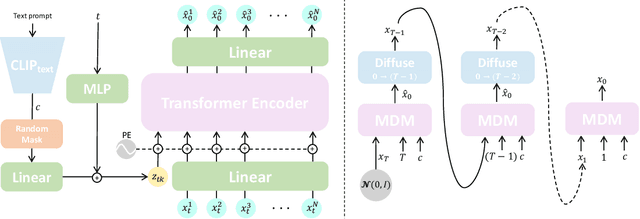
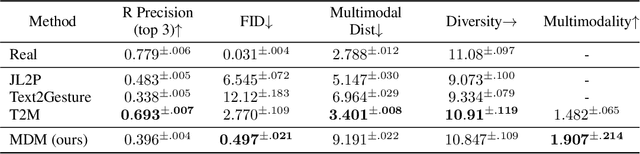
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, current generative solutions are either low-quality or limited in expressiveness. Diffusion models, which have already shown remarkable generative capabilities in other domains, are promising candidates for human motion due to their many-to-many nature, but they tend to be resource hungry and hard to control. In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain. MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion. https://guytevet.github.io/mdm-page/ .
Prompt-to-Prompt Image Editing with Cross Attention Control
Aug 02, 2022

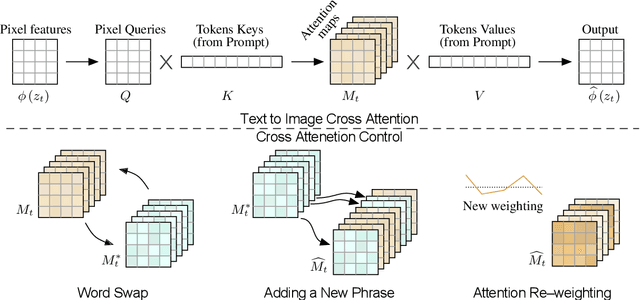
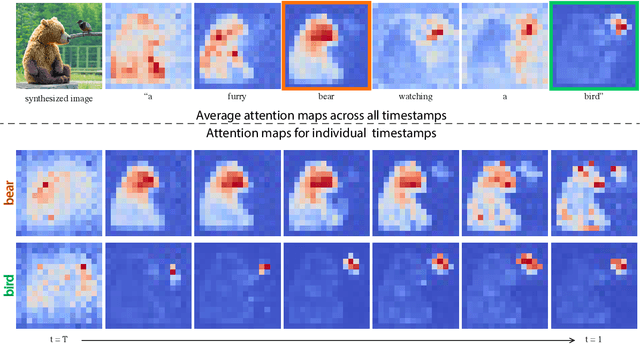
Recent large-scale text-driven synthesis models have attracted much attention thanks to their remarkable capabilities of generating highly diverse images that follow given text prompts. Such text-based synthesis methods are particularly appealing to humans who are used to verbally describe their intent. Therefore, it is only natural to extend the text-driven image synthesis to text-driven image editing. Editing is challenging for these generative models, since an innate property of an editing technique is to preserve most of the original image, while in the text-based models, even a small modification of the text prompt often leads to a completely different outcome. State-of-the-art methods mitigate this by requiring the users to provide a spatial mask to localize the edit, hence, ignoring the original structure and content within the masked region. In this paper, we pursue an intuitive prompt-to-prompt editing framework, where the edits are controlled by text only. To this end, we analyze a text-conditioned model in depth and observe that the cross-attention layers are the key to controlling the relation between the spatial layout of the image to each word in the prompt. With this observation, we present several applications which monitor the image synthesis by editing the textual prompt only. This includes localized editing by replacing a word, global editing by adding a specification, and even delicately controlling the extent to which a word is reflected in the image. We present our results over diverse images and prompts, demonstrating high-quality synthesis and fidelity to the edited prompts.