 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Effective Method To Eliminate the Self Language Bias in Multilingual Representations
Sep 10, 2021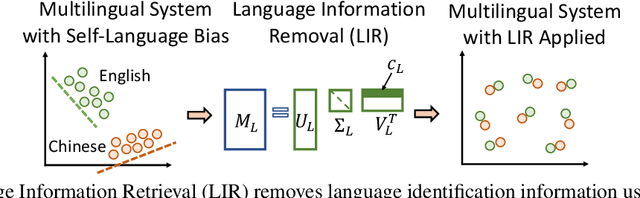
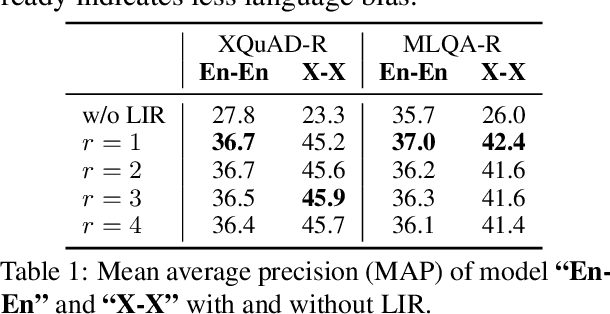
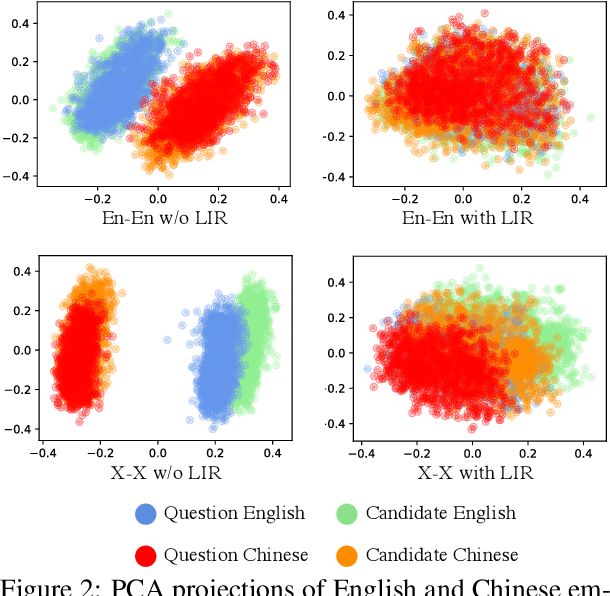
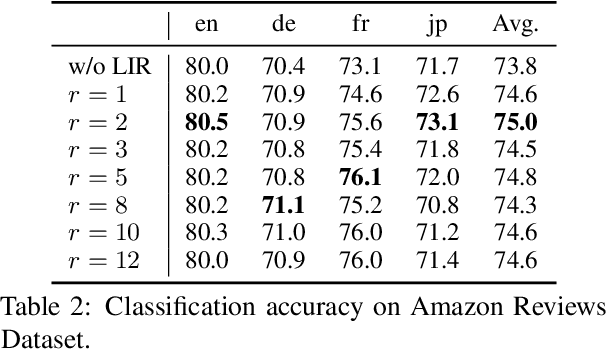
Language agnostic and semantic-language information isolation is an emerging research direction for multilingual representations models. We explore this problem from a novel angle of geometric algebra and semantic space. A simple but highly effective method "Language Information Removal (LIR)" factors out language identity information from semantic related components in multilingual representations pre-trained on multi-monolingual data. A post-training and model-agnostic method, LIR only uses simple linear operations, e.g. matrix factorization and orthogonal projection. LIR reveals that for weak-alignment multilingual systems, the principal components of semantic spaces primarily encodes language identity information. We first evaluate the LIR on a cross-lingual question answer retrieval task (LAReQA), which requires the strong alignment for the multilingual embedding space. Experiment shows that LIR is highly effectively on this task, yielding almost 100% relative improvement in MAP for weak-alignment models. We then evaluate the LIR on Amazon Reviews and XEVAL dataset, with the observation that removing language information is able to improve the cross-lingual transfer performance.
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
Aug 26, 2021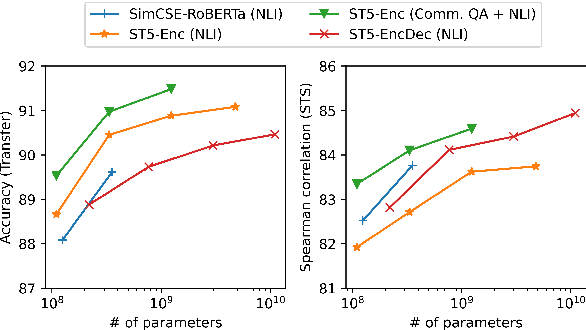
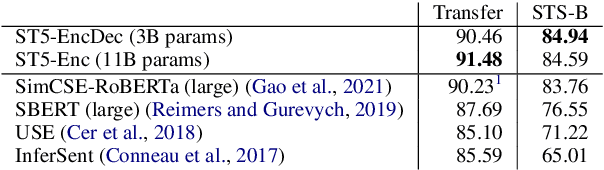
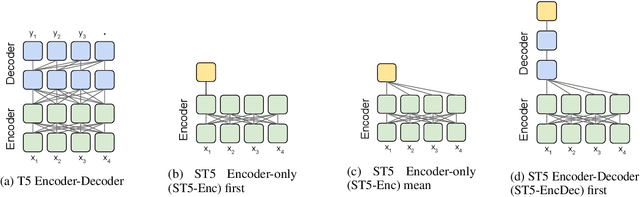
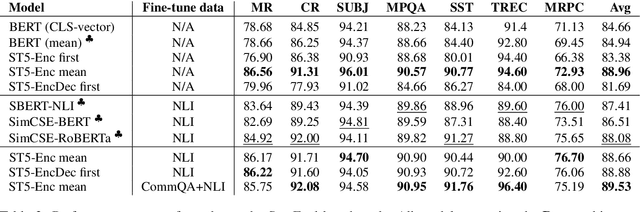
We provide the first exploration of text-to-text transformers (T5) sentence embeddings. Sentence embeddings are broadly useful for language processing tasks. While T5 achieves impressive performance on language tasks cast as sequence-to-sequence mapping problems, it is unclear how to produce sentence embeddings from encoder-decoder models. We investigate three methods for extracting T5 sentence embeddings: two utilize only the T5 encoder and one uses the full T5 encoder-decoder model. Our encoder-only models outperforms BERT-based sentence embeddings on both transfer tasks and semantic textual similarity (STS). Our encoder-decoder method achieves further improvement on STS. Scaling up T5 from millions to billions of parameters is found to produce consistent improvements on downstream tasks. Finally, we introduce a two-stage contrastive learning approach that achieves a new state-of-art on STS using sentence embeddings, outperforming both Sentence BERT and SimCSE.
NT5?! Training T5 to Perform Numerical Reasoning
Apr 15, 2021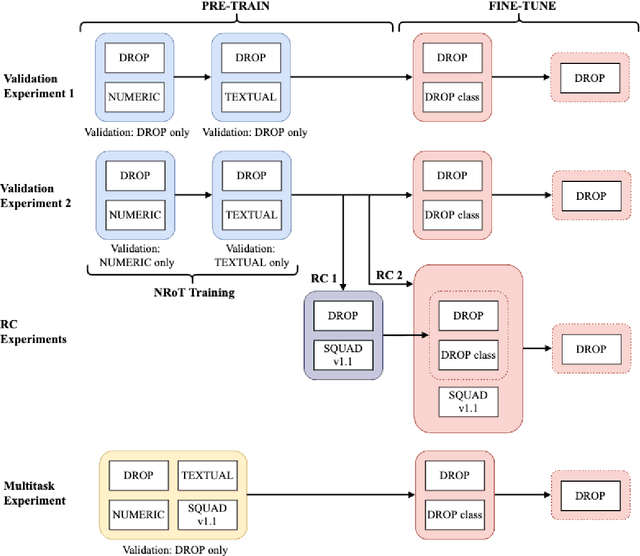

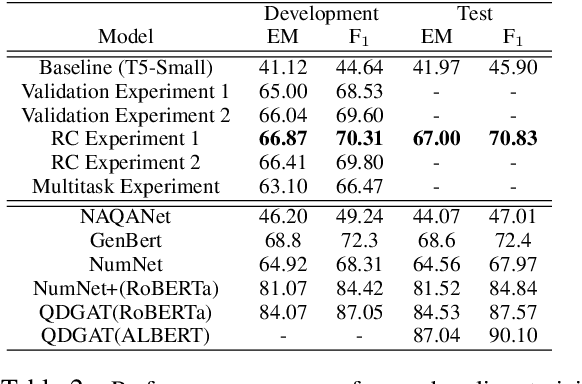

Numerical reasoning over text (NRoT) presents unique challenges that are not well addressed by existing pre-training objectives. We explore five sequential training schedules that adapt a pre-trained T5 model for NRoT. Our final model is adapted from T5, but further pre-trained on three datasets designed to strengthen skills necessary for NRoT and general reading comprehension before being fine-tuned on the Discrete Reasoning over Text (DROP) dataset. The training improves DROP's adjusted F1 performance (a numeracy-focused score) from 45.90 to 70.83. Our model closes in on GenBERT (72.4), a custom BERT-Base model using the same datasets with significantly more parameters. We show that training the T5 multitasking framework with multiple numerical reasoning datasets of increasing difficulty, good performance on DROP can be achieved without manually engineering partitioned functionality between distributed and symbol modules.
Universal Sentence Representation Learning with Conditional Masked Language Model
Dec 29, 2020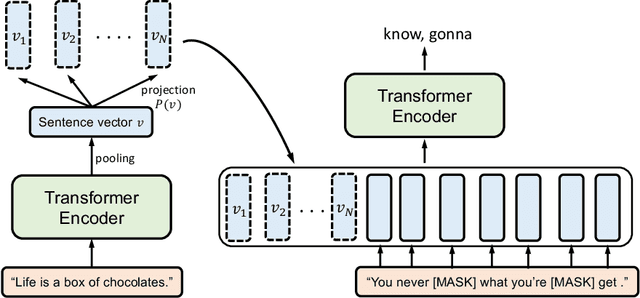
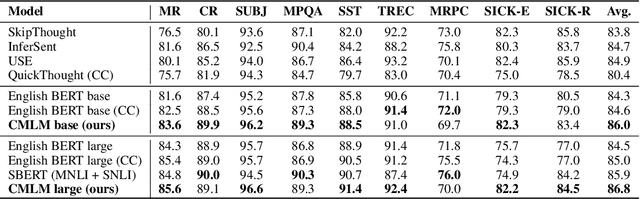

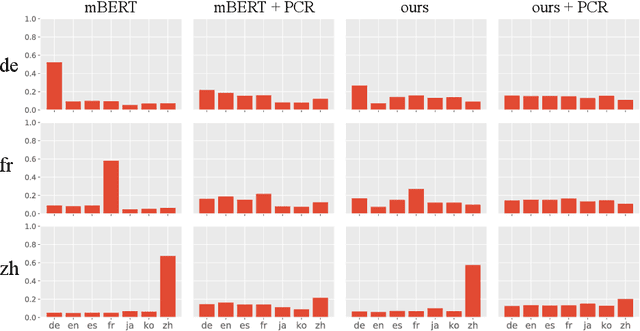
This paper presents a novel training method, Conditional Masked Language Modeling (CMLM), to effectively learn sentence representations on large scale unlabeled corpora. CMLM integrates sentence representation learning into MLM training by conditioning on the encoded vectors of adjacent sentences. Our English CMLM model achieves state-of-the-art performance on SentEval, even outperforming models learned using (semi-)supervised signals. As a fully unsupervised learning method, CMLM can be conveniently extended to a broad range of languages and domains. We find that a multilingual CMLM model co-trained with bitext retrieval~(BR) and natural language inference~(NLI) tasks outperforms the previous state-of-the-art multilingual models by a large margin. We explore the same language bias of the learned representations, and propose a principle component based approach to remove the language identifying information from the representation while still retaining sentence semantics.
SeqGenSQL -- A Robust Sequence Generation Model for Structured Query Language
Nov 07, 2020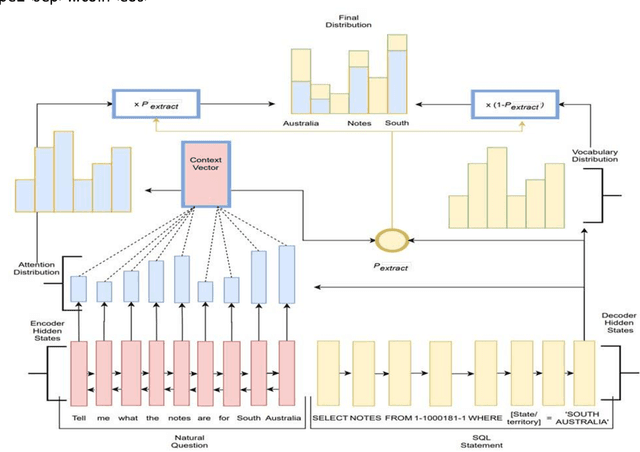
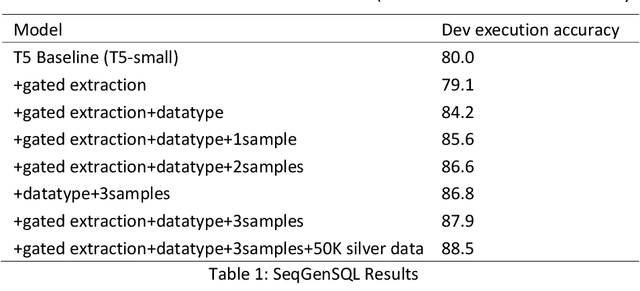
We explore using T5 (Raffel et al. (2019)) to directly translate natural language questions into SQL statements. General purpose natural language that interfaces to information stored within databases requires flexibly translating natural language questions into database queries. The best performing text-to-SQL systems approach this task by first converting questions into an intermediate logical form (LF) (Lyu et al. (2020)). While LFs provide a convenient intermediate representation and simplify query generation, they introduce an additional layer of complexity and annotation requirements. However, weakly supervised modeling that directly converts questions to SQL statements has proven more difficult without the scaffolding provided by LFs (Min et al. (2019)). We approach direct conversion of questions to SQL statements using T5 (Raffel et al. (2019)), a pre-trained textto-text generation model, modified to support pointer-generator style decoding (See et al. (2017)). We explore using question augmentation with table schema information and the use of automatically generated silver training data. The resulting model achieves 90.5% execution accuracy on the WikiSQL (Zhong et al. (2017)) test data set, a new state-of-the-art on weakly supervised SQL generation. The performance improvement is 6.6% absolute over the prior state-of-the-art (Min et al. (2019)) and approaches the performance of state-ofthe-art systems making use of LFs.
Neural Retrieval for Question Answering with Cross-Attention Supervised Data Augmentation
Sep 29, 2020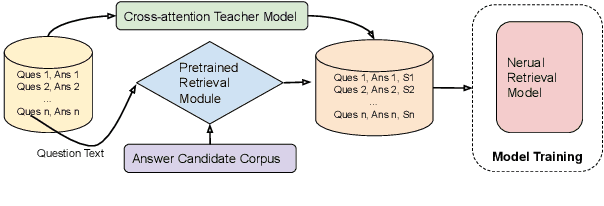
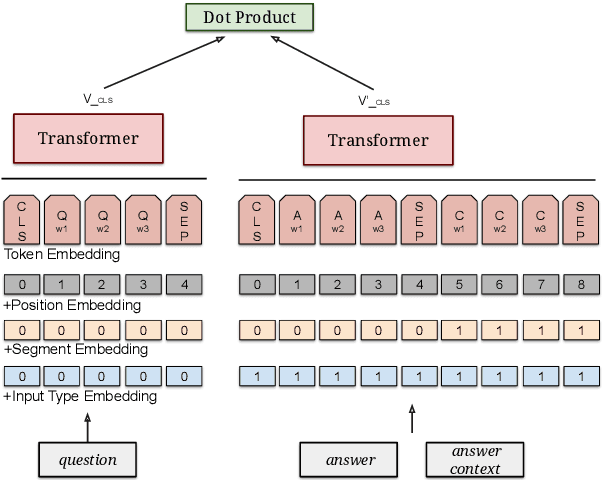
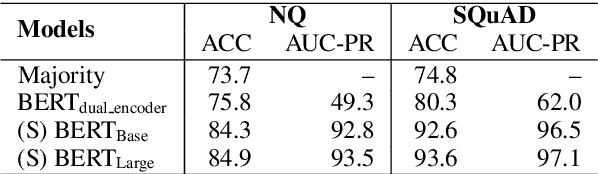
Neural models that independently project questions and answers into a shared embedding space allow for efficient continuous space retrieval from large corpora. Independently computing embeddings for questions and answers results in late fusion of information related to matching questions to their answers. While critical for efficient retrieval, late fusion underperforms models that make use of early fusion (e.g., a BERT based classifier with cross-attention between question-answer pairs). We present a supervised data mining method using an accurate early fusion model to improve the training of an efficient late fusion retrieval model. We first train an accurate classification model with cross-attention between questions and answers. The accurate cross-attention model is then used to annotate additional passages in order to generate weighted training examples for a neural retrieval model. The resulting retrieval model with additional data significantly outperforms retrieval models directly trained with gold annotations on Precision at $N$ (P@N) and Mean Reciprocal Rank (MRR).
Language-agnostic BERT Sentence Embedding
Jul 03, 2020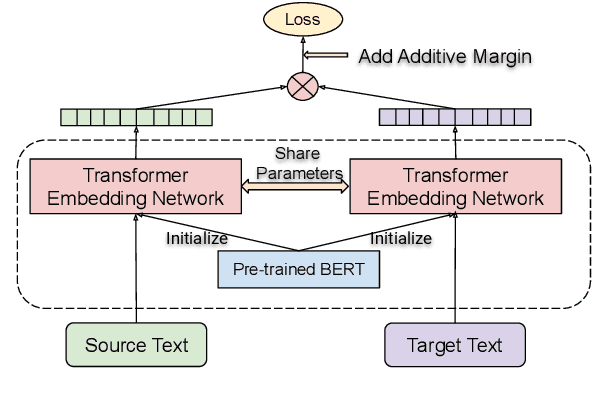
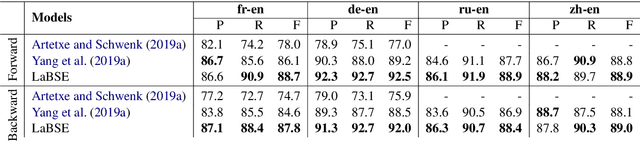
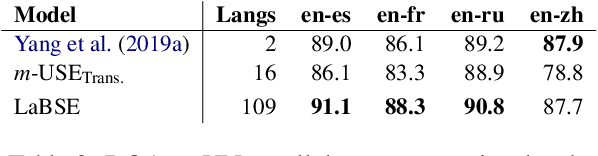
We adapt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages. %The state-of-the-art for numerous monolingual and multilingual NLP tasks is masked language model (MLM) pretraining followed by task specific fine-tuning. While English sentence embeddings have been obtained by fine-tuning a pretrained BERT model, such models have not been applied to multilingual sentence embeddings. Our model combines masked language model (MLM) and translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders. The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7%, well above the 65.5% achieved by the prior state-of-the-art on Tatoeba. Our sentence embeddings also establish new state-of-the-art results on BUCC and UN bi-text retrieval.
MultiReQA: A Cross-Domain Evaluation for Retrieval Question Answering Models
May 05, 2020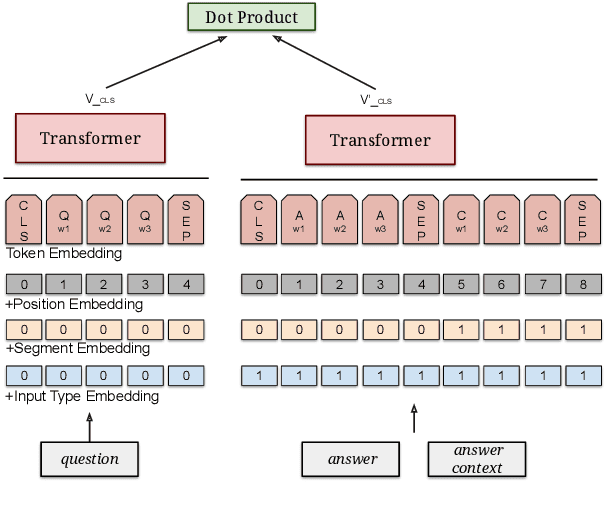

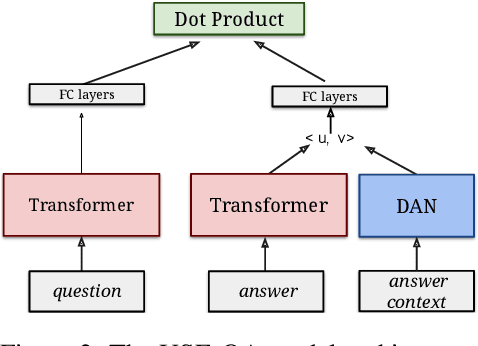
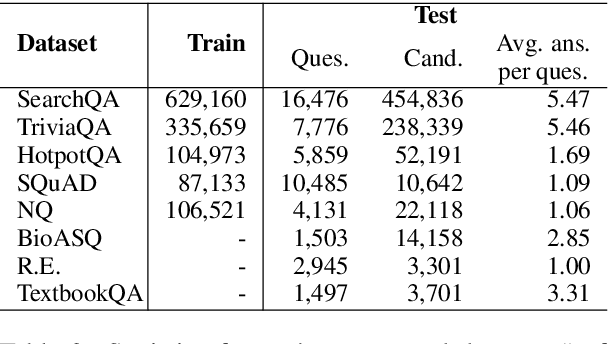
Retrieval question answering (ReQA) is the task of retrieving a sentence-level answer to a question from an open corpus (Ahmad et al.,2019).This paper presents MultiReQA, anew multi-domain ReQA evaluation suite com-posed of eight retrieval QA tasks drawn from publicly available QA datasets. We provide the first systematic retrieval based evaluation over these datasets using two supervised neural models, based on fine-tuning BERT andUSE-QA models respectively, as well as a surprisingly strong information retrieval baseline,BM25. Five of these tasks contain both train-ing and test data, while three contain test data only. Performance on the five tasks with train-ing data shows that while a general model covering all domains is achievable, the best performance is often obtained by training exclusively on in-domain data.
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
Apr 30, 2020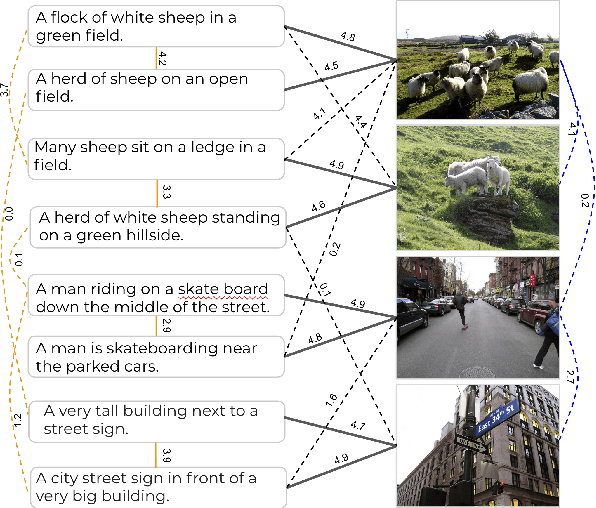



Image captioning datasets have proven useful for multimodal representation learning, and a common evaluation paradigm based on multimodal retrieval has emerged. Unfortunately, datasets have only limited cross-modal associations: images are not paired with others, captions are only paired with others that describe the same image, there are no negative associations and there are missing positive cross-modal associations. This undermines retrieval evaluation and limits research into how inter-modality learning impacts intra-modality tasks. To address this gap, we create the \textit{Crisscrossed Captions} (CxC) dataset, extending MS-COCO with new semantic similarity judgments for \textbf{247,315} intra- and inter-modality pairs. We provide baseline model performance results for both retrieval and correlations with human rankings, emphasizing both intra- and inter-modality learning.
ReQA: An Evaluation for End-to-End Answer Retrieval Models
Jul 10, 2019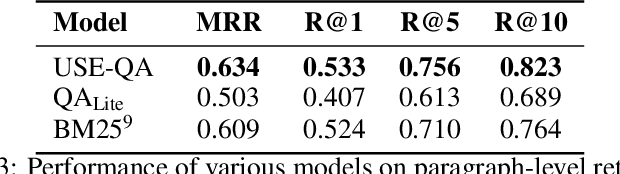
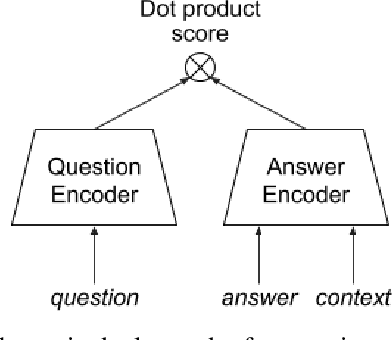
Popular QA benchmarks like SQuAD have driven progress on the task of identifying answer spans within a specific passage, with models now surpassing human performance. However, retrieving relevant answers from a huge corpus of documents is still a challenging problem, and places different requirements on the model architecture. There is growing interest in developing scalable answer retrieval models trained end-to-end, bypassing the typical document retrieval step. In this paper, we introduce Retrieval Question Answering (ReQA), a benchmark for evaluating large-scale sentence- and paragraph-level answer retrieval models. We establish baselines using both neural encoding models as well as classical information retrieval techniques. We release our evaluation code to encourage further work on this challenging task.