 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mutual Information Maximization Perspective of Language Representation Learning
Nov 26, 2019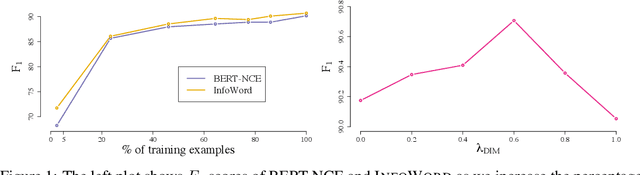
We show state-of-the-art word representation learning methods maximize an objective function that is a lower bound on the mutual information between different parts of a word sequence (i.e., a sentence). Our formulation provides an alternative perspective that unifies classical word embedding models (e.g., Skip-gram) and modern contextual embeddings (e.g., BERT, XLNet). In addition to enhancing our theoretical understanding of these methods, our derivation leads to a principled framework that can be used to construct new self-supervised tasks. We provide an example by drawing inspirations from related methods based on mutual information maximization that have been successful in computer vision, and introduce a simple self-supervised objective that maximizes the mutual information between a global sentence representation and n-grams in the sentence. Our analysis offers a holistic view of representation learning methods to transfer knowledge and translate progress across multiple domains (e.g., natural language processing, computer vision, audio processing).
Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019
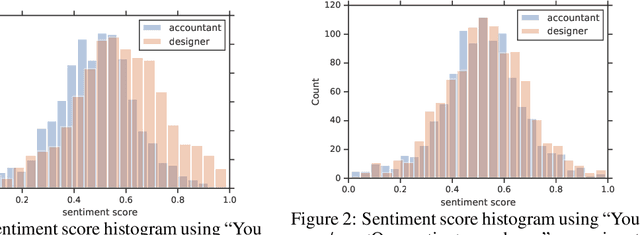
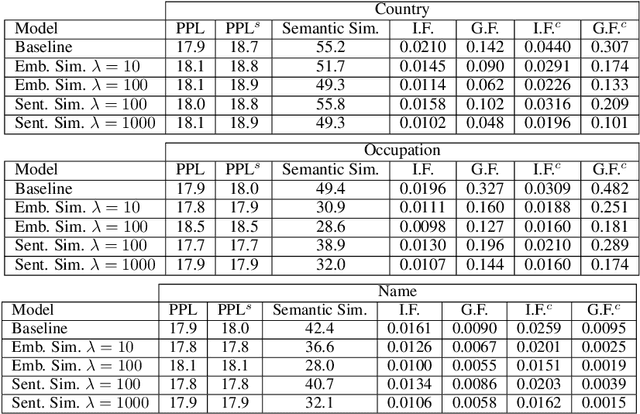
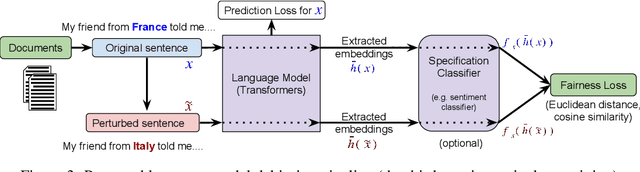
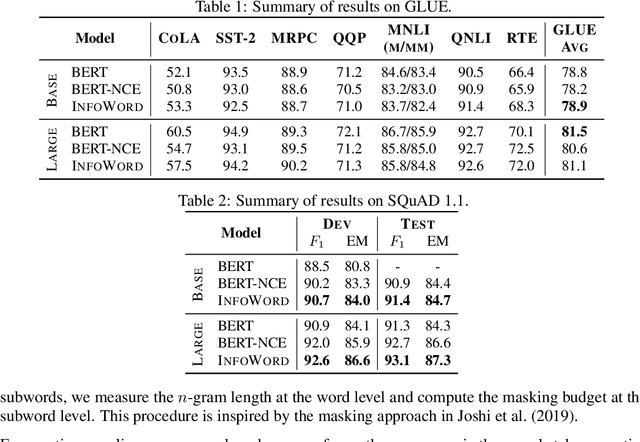
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
On the Cross-lingual Transferability of Monolingual Representations
Oct 25, 2019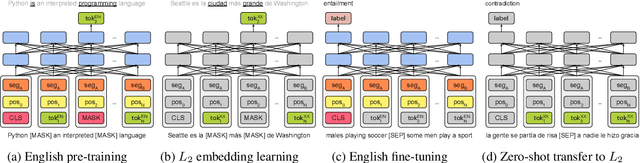
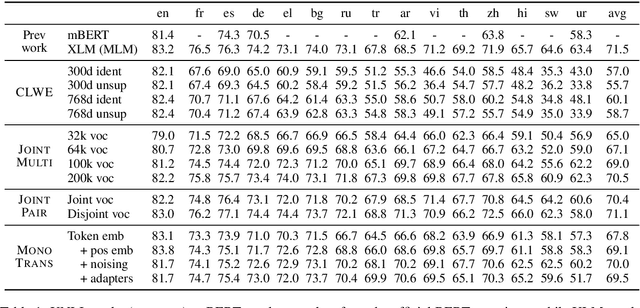
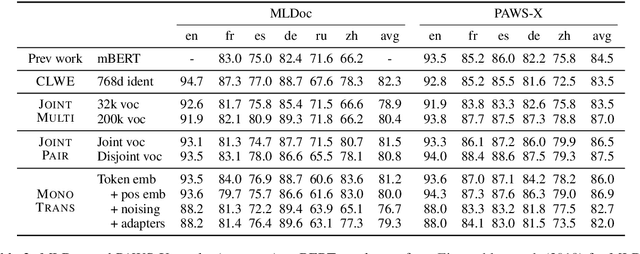
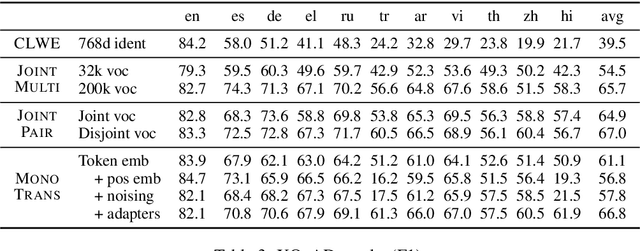
State-of-the-art unsupervised multilingual models (e.g., multilingual BERT) have been shown to generalize in a zero-shot cross-lingual setting. This generalization ability has been attributed to the use of a shared subword vocabulary and joint training across multiple languages giving rise to deep multilingual abstractions. We evaluate this hypothesis by designing an alternative approach that transfers a monolingual model to new languages at the lexical level. More concretely, we first train a transformer-based masked language model on one language, and transfer it to a new language by learning a new embedding matrix with the same masked language modeling objective -freezing parameters of all other layers. This approach does not rely on a shared vocabulary or joint training. However, we show that it is competitive with multilingual BERT on standard cross-lingual classification benchmarks and on a new Cross-lingual Question Answering Dataset (XQuAD). Our results contradict common beliefs of the basis of the generalization ability of multilingual models and suggest that deep monolingual models learn some abstractions that generalize across languages. We also release XQuAD as a more comprehensive cross-lingual benchmark, which comprises 240 paragraphs and 1190 question-answer pairs from SQuAD v1.1 translated into ten languages by professional translators.
Achieving Verified Robustness to Symbol Substitutions via Interval Bound Propagation
Sep 03, 2019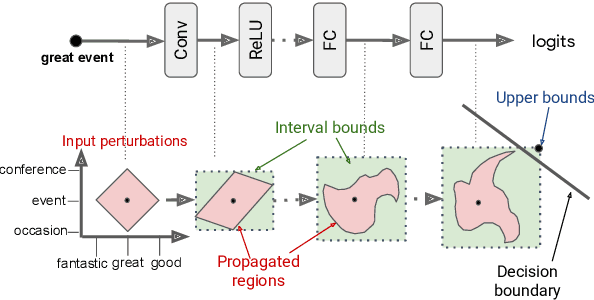


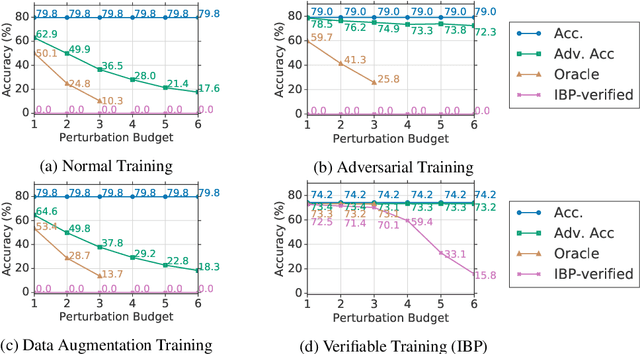
Neural networks are part of many contemporary NLP systems, yet their empirical successes come at the price of vulnerability to adversarial attacks. Previous work has used adversarial training and data augmentation to partially mitigate such brittleness, but these are unlikely to find worst-case adversaries due to the complexity of the search space arising from discrete text perturbations. In this work, we approach the problem from the opposite direction: to formally verify a system's robustness against a predefined class of adversarial attacks. We study text classification under synonym replacements or character flip perturbations. We propose modeling these input perturbations as a simplex and then using Interval Bound Propagation -- a formal model verification method. We modify the conventional log-likelihood training objective to train models that can be efficiently verified, which would otherwise come with exponential search complexity. The resulting models show only little difference in terms of nominal accuracy, but have much improved verified accuracy under perturbations and come with an efficiently computable formal guarantee on worst case adversaries.
Episodic Memory in Lifelong Language Learning
Jun 03, 2019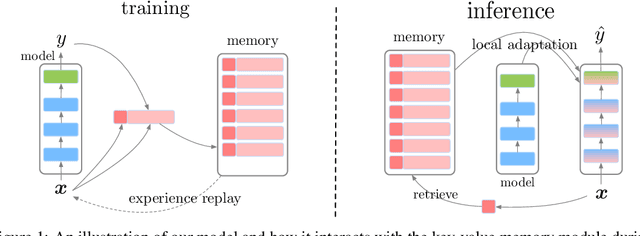
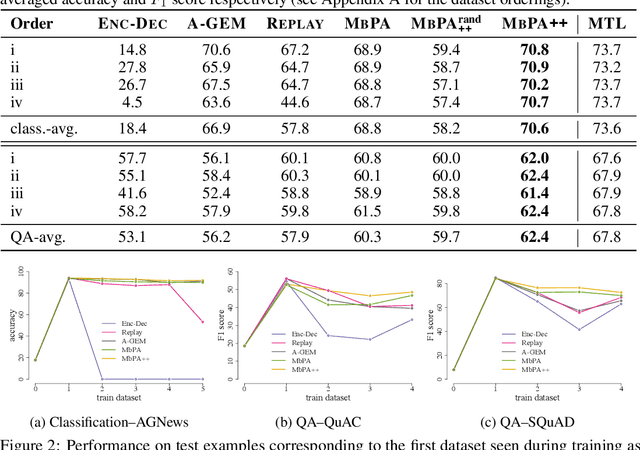

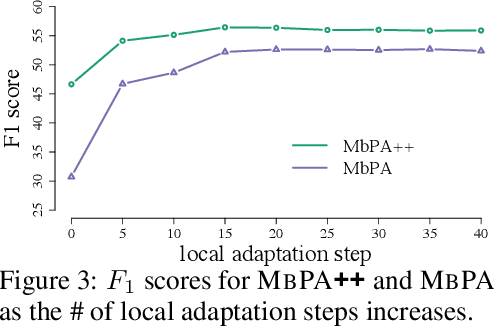
We introduce a lifelong language learning setup where a model needs to learn from a stream of text examples without any dataset identifier. We propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay and local adaptation to allow the model to continuously learn from new datasets. We also show that the space complexity of the episodic memory module can be reduced significantly (~50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. We consider an episodic memory component as a crucial building block of general linguistic intelligence and see our model as a first step in that direction.
Learning and Evaluating General Linguistic Intelligence
Jan 31, 2019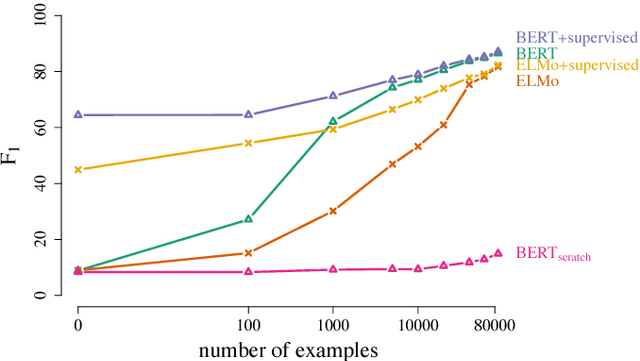
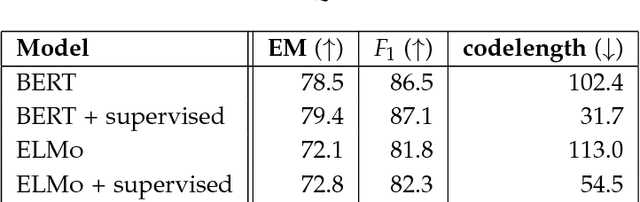
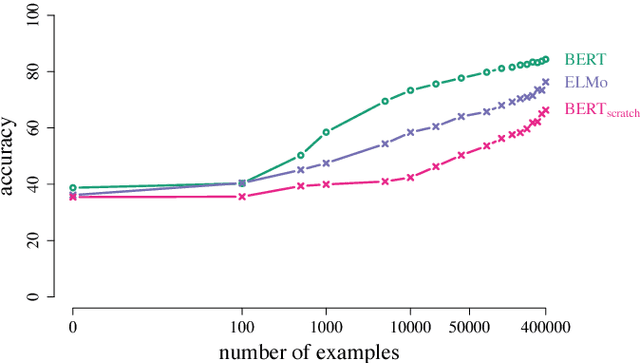

We define general linguistic intelligence as the ability to reuse previously acquired knowledge about a language's lexicon, syntax, semantics, and pragmatic conventions to adapt to new tasks quickly. Using this definition, we analyze state-of-the-art natural language understanding models and conduct an extensive empirical investigation to evaluate them against these criteria through a series of experiments that assess the task-independence of the knowledge being acquired by the learning process. In addition to task performance, we propose a new evaluation metric based on an online encoding of the test data that quantifies how quickly an existing agent (model) learns a new task. Our results show that while the field has made impressive progress in terms of model architectures that generalize to many tasks, these models still require a lot of in-domain training examples (e.g., for fine tuning, training task-specific modules), and are prone to catastrophic forgetting. Moreover, we find that far from solving general tasks (e.g., document question answering), our models are overfitting to the quirks of particular datasets (e.g., SQuAD). We discuss missing components and conjecture on how to make progress toward general linguistic intelligence.
Variational Smoothing in Recurrent Neural Network Language Models
Jan 27, 2019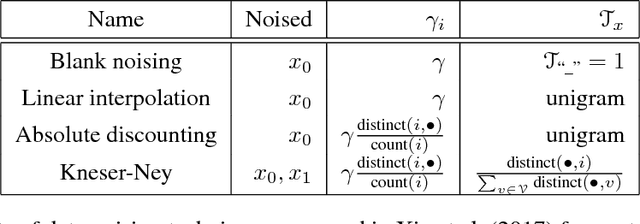
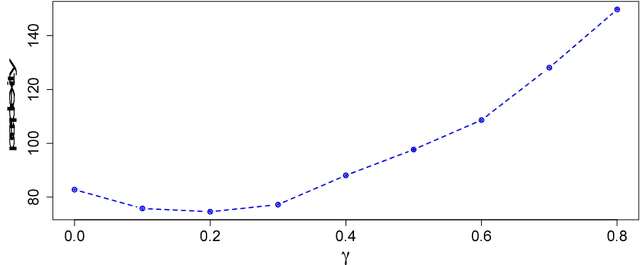
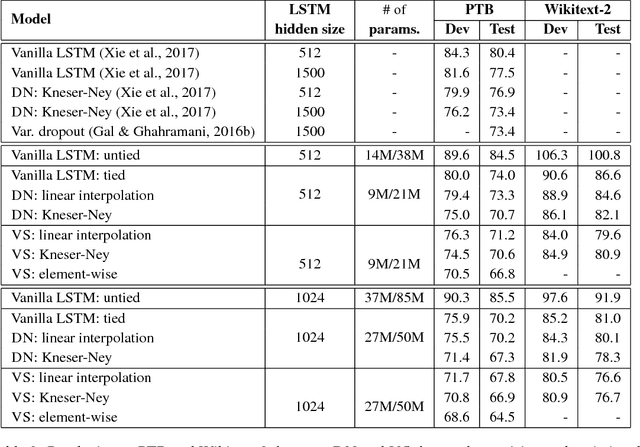
We present a new theoretical perspective of data noising in recurrent neural network language models (Xie et al., 2017). We show that each variant of data noising is an instance of Bayesian recurrent neural networks with a particular variational distribution (i.e., a mixture of Gaussians whose weights depend on statistics derived from the corpus such as the unigram distribution). We use this insight to propose a more principled method to apply at prediction time and propose natural extensions to data noising under the variational framework. In particular, we propose variational smoothing with tied input and output embedding matrices and an element-wise variational smoothing method. We empirically verify our analysis on two benchmark language modeling datasets and demonstrate performance improvements over existing data noising methods.
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
Oct 23, 2017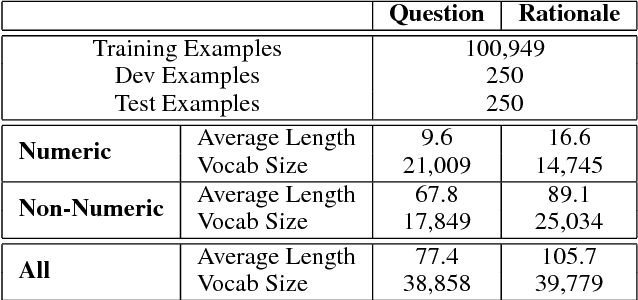
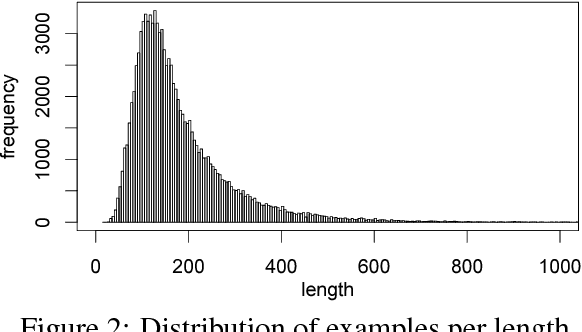
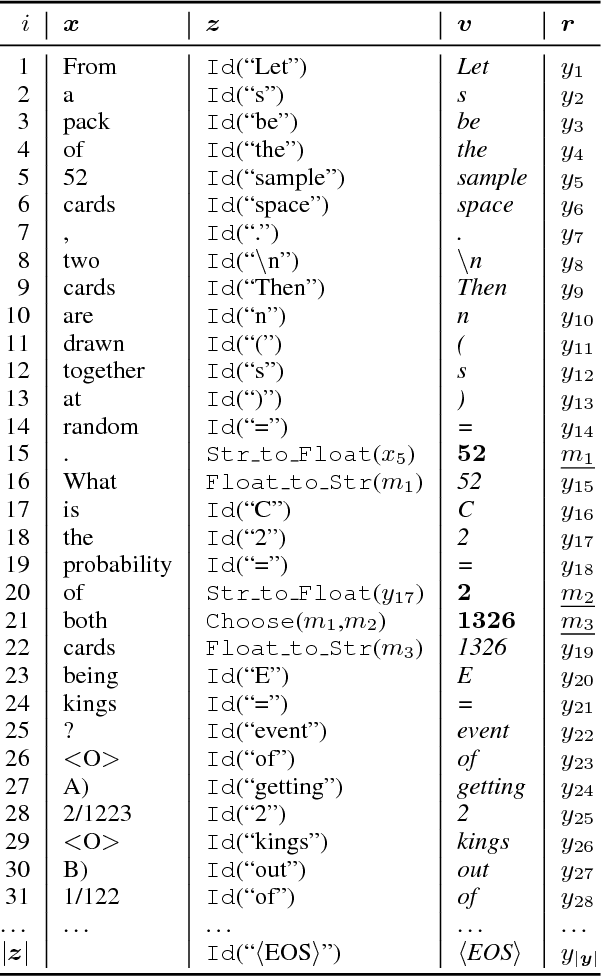
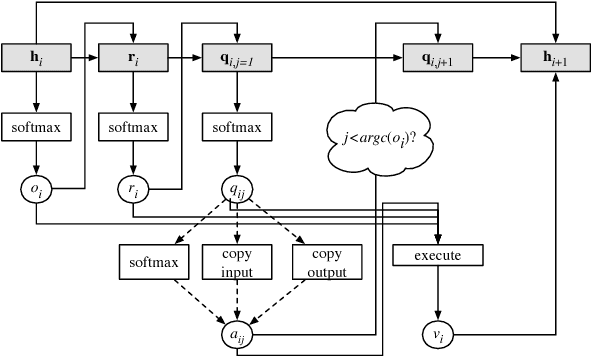
Solving algebraic word problems requires executing a series of arithmetic operations---a program---to obtain a final answer. However, since programs can be arbitrarily complicated, inducing them directly from question-answer pairs is a formidable challenge. To make this task more feasible, we solve these problems by generating answer rationales, sequences of natural language and human-readable mathematical expressions that derive the final answer through a series of small steps. Although rationales do not explicitly specify programs, they provide a scaffolding for their structure via intermediate milestones. To evaluate our approach, we have created a new 100,000-sample dataset of questions, answers and rationales. Experimental results show that indirect supervision of program learning via answer rationales is a promising strategy for inducing arithmetic programs.
Generative and Discriminative Text Classification with Recurrent Neural Networks
May 26, 2017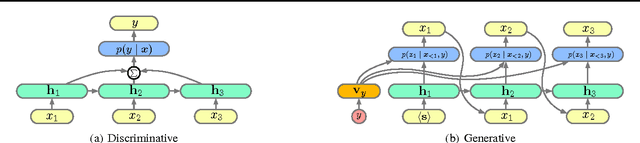
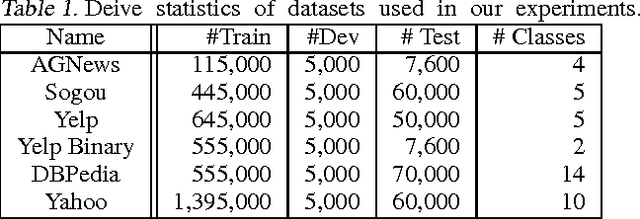
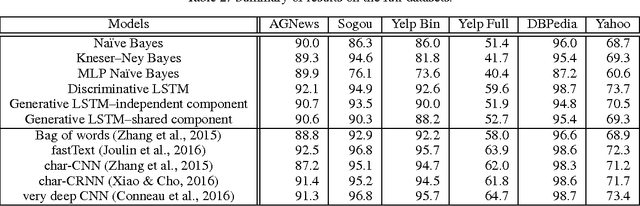
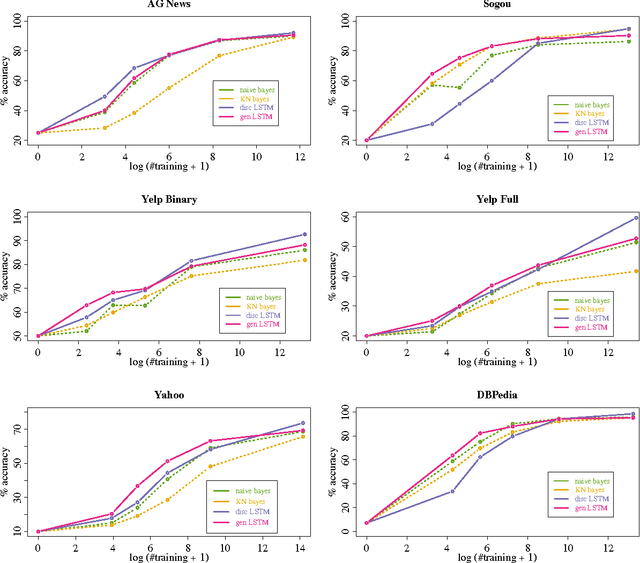
We empirically characterize the performance of discriminative and generative LSTM models for text classification. We find that although RNN-based generative models are more powerful than their bag-of-words ancestors (e.g., they account for conditional dependencies across words in a document), they have higher asymptotic error rates than discriminatively trained RNN models. However we also find that generative models approach their asymptotic error rate more rapidly than their discriminative counterparts---the same pattern that Ng & Jordan (2001) proved holds for linear classification models that make more naive conditional independence assumptions. Building on this finding, we hypothesize that RNN-based generative classification models will be more robust to shifts in the data distribution. This hypothesis is confirmed in a series of experiments in zero-shot and continual learning settings that show that generative models substantially outperform discriminative models.
Jointly Learning Sentence Embeddings and Syntax with Unsupervised Tree-LSTMs
May 25, 2017
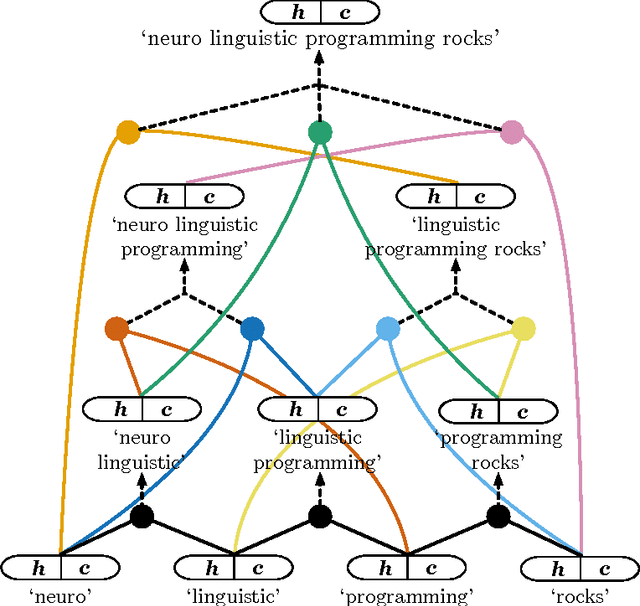
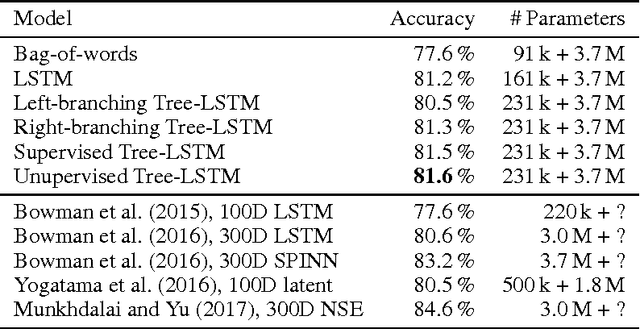
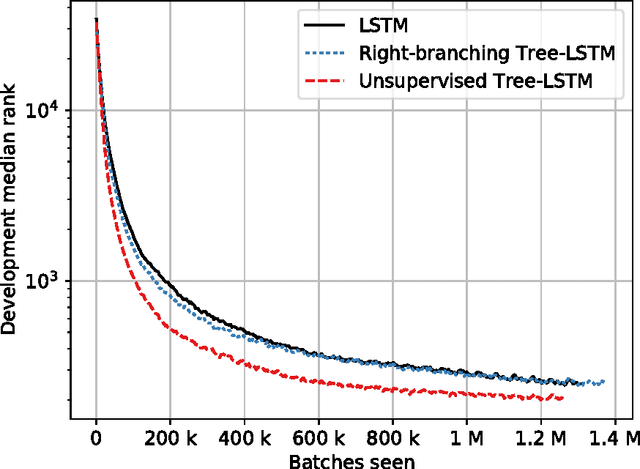
We introduce a neural network that represents sentences by composing their words according to induced binary parse trees. We use Tree-LSTM as our composition function, applied along a tree structure found by a fully differentiable natural language chart parser. Our model simultaneously optimises both the composition function and the parser, thus eliminating the need for externally-provided parse trees which are normally required for Tree-LSTM. It can therefore be seen as a tree-based RNN that is unsupervised with respect to the parse trees. As it is fully differentiable, our model is easily trained with an off-the-shelf gradient descent method and backpropagation. We demonstrate that it achieves better performance compared to various supervised Tree-LSTM architectures on a textual entailment task and a reverse dictionary task.