 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABC: Attention with Bounded-memory Control
Oct 06, 2021
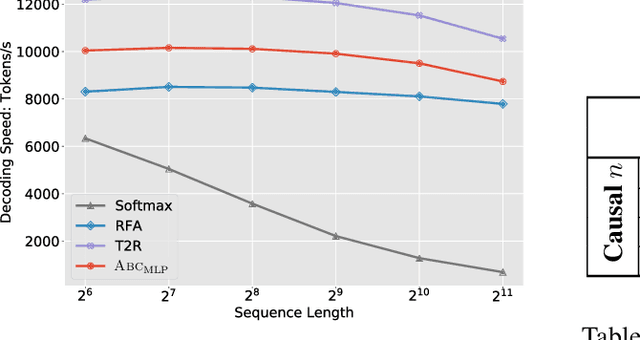
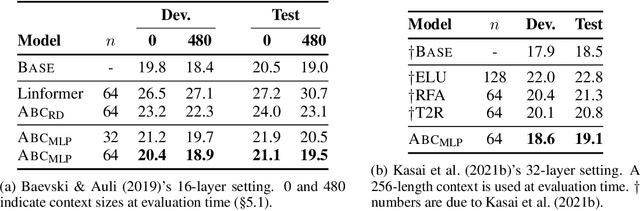
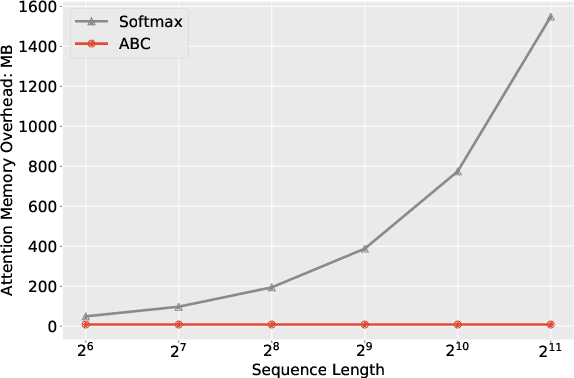
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
Sep 22, 2021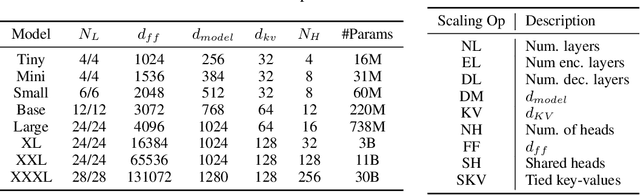
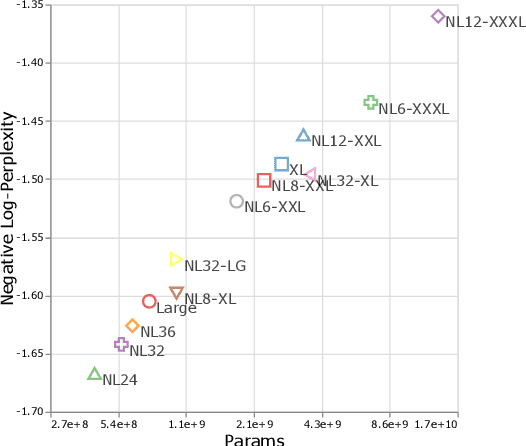
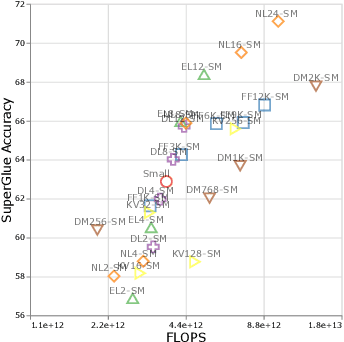
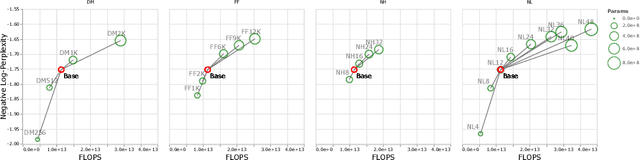
There remain many open questions pertaining to the scaling behaviour of Transformer architectures. These scaling decisions and findings can be critical, as training runs often come with an associated computational cost which have both financial and/or environmental impact. The goal of this paper is to present scaling insights from pretraining and finetuning Transformers. While Kaplan et al. presents a comprehensive study of the scaling behaviour of Transformer language models, the scope is only on the upstream (pretraining) loss. Therefore, it is still unclear if these set of findings transfer to downstream task within the context of the pretrain-finetune paradigm. The key findings of this paper are as follows: (1) we show that aside from only the model size, model shape matters for downstream fine-tuning, (2) scaling protocols operate differently at different compute regions, (3) widely adopted T5-base and T5-large sizes are Pareto-inefficient. To this end, we present improved scaling protocols whereby our redesigned models achieve similar downstream fine-tuning quality while having 50\% fewer parameters and training 40\% faster compared to the widely adopted T5-base model. We publicly release over 100 pretrained checkpoints of different T5 configurations to facilitate future research and analysis.
End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering
Jun 09, 2021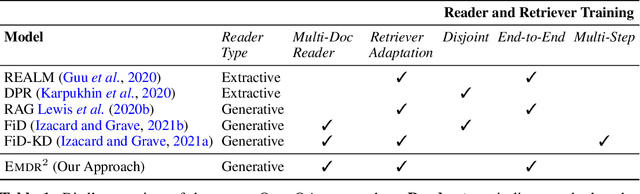
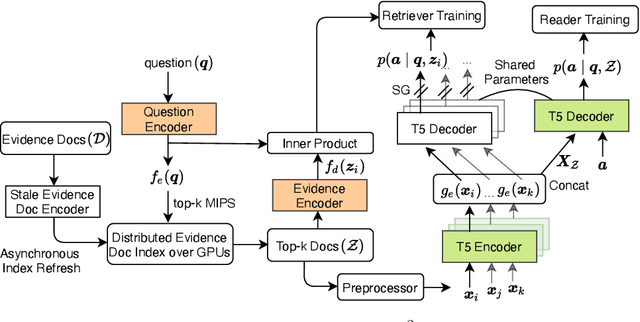
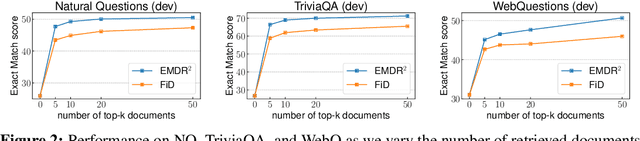
We present an end-to-end differentiable training method for retrieval-augmented open-domain question answering systems that combine information from multiple retrieved documents when generating answers. We model retrieval decisions as latent variables over sets of relevant documents. Since marginalizing over sets of retrieved documents is computationally hard, we approximate this using an expectation-maximization algorithm. We iteratively estimate the value of our latent variable (the set of relevant documents for a given question) and then use this estimate to update the retriever and reader parameters. We hypothesize that such end-to-end training allows training signals to flow to the reader and then to the retriever better than staged-wise training. This results in a retriever that is able to select more relevant documents for a question and a reader that is trained on more accurate documents to generate an answer. Experiments on three benchmark datasets demonstrate that our proposed method outperforms all existing approaches of comparable size by 2-3% absolute exact match points, achieving new state-of-the-art results. Our results also demonstrate the feasibility of learning to retrieve to improve answer generation without explicit supervision of retrieval decisions.
Finetuning Pretrained Transformers into RNNs
Mar 24, 2021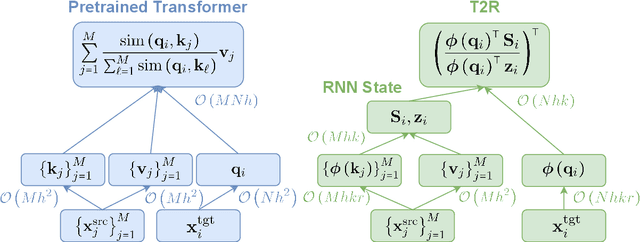
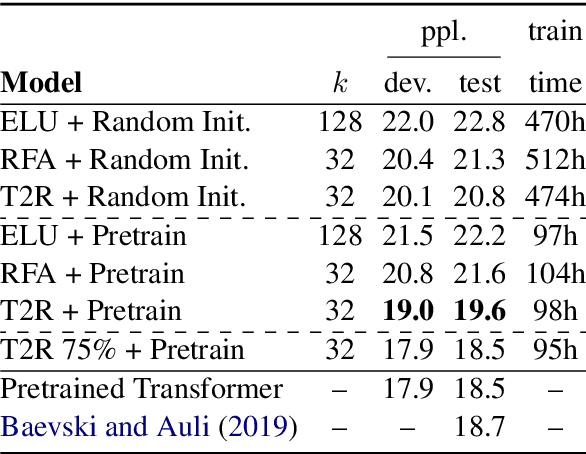
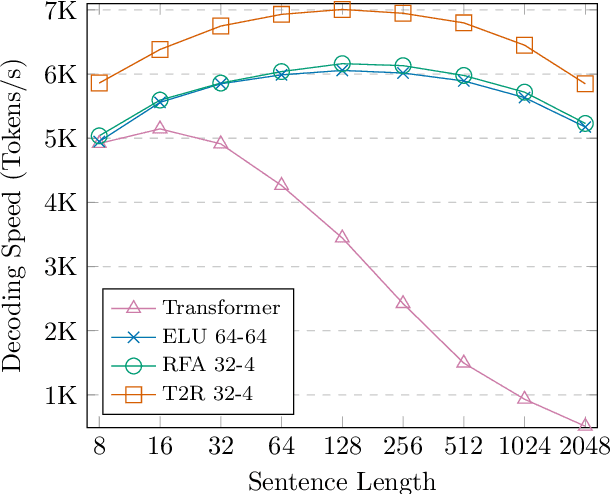
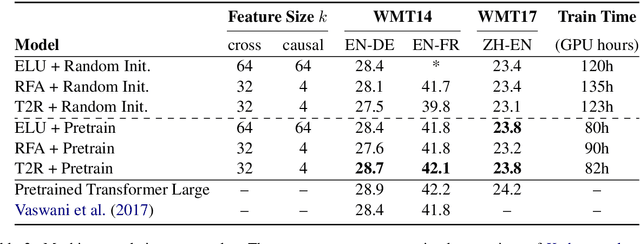
Transformers have outperformed recurrent neural networks (RNNs) in natural language generation. This comes with a significant computational overhead, as the attention mechanism scales with a quadratic complexity in sequence length. Efficient transformer variants have received increasing interest from recent works. Among them, a linear-complexity recurrent variant has proven well suited for autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps, but can be difficult to train or yield suboptimal accuracy. This work aims to convert a pretrained transformer into its efficient recurrent counterpart, improving the efficiency while retaining the accuracy. Specifically, we propose a swap-then-finetune procedure: in an off-the-shelf pretrained transformer, we replace the softmax attention with its linear-complexity recurrent alternative and then finetune. With a learned feature map, our approach provides an improved tradeoff between efficiency and accuracy over the standard transformer and other recurrent variants. We also show that the finetuning process needs lower training cost than training these recurrent variants from scratch. As many recent models for natural language tasks are increasingly dependent on large-scale pretrained transformers, this work presents a viable approach to improving inference efficiency without repeating the expensive pretraining process.
Random Feature Attention
Mar 19, 2021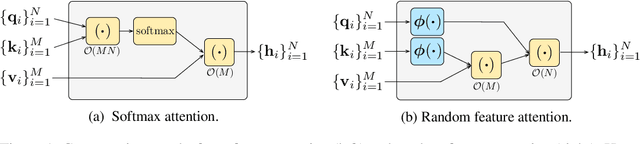
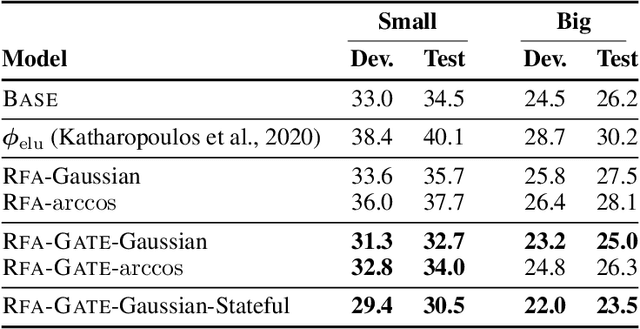
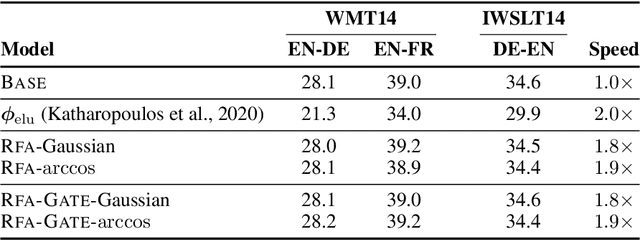
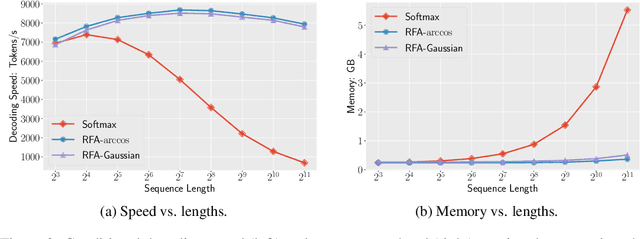
Transformers are state-of-the-art models for a variety of sequence modeling tasks. At their core is an attention function which models pairwise interactions between the inputs at every timestep. While attention is powerful, it does not scale efficiently to long sequences due to its quadratic time and space complexity in the sequence length. We propose RFA, a linear time and space attention that uses random feature methods to approximate the softmax function, and explore its application in transformers. RFA can be used as a drop-in replacement for conventional softmax attention and offers a straightforward way of learning with recency bias through an optional gating mechanism. Experiments on language modeling and machine translation demonstrate that RFA achieves similar or better performance compared to strong transformer baselines. In the machine translation experiment, RFA decodes twice as fast as a vanilla transformer. Compared to existing efficient transformer variants, RFA is competitive in terms of both accuracy and efficiency on three long text classification datasets. Our analysis shows that RFA's efficiency gains are especially notable on long sequences, suggesting that RFA will be particularly useful in tasks that require working with large inputs, fast decoding speed, or low memory footprints.
Adaptive Semiparametric Language Models
Feb 04, 2021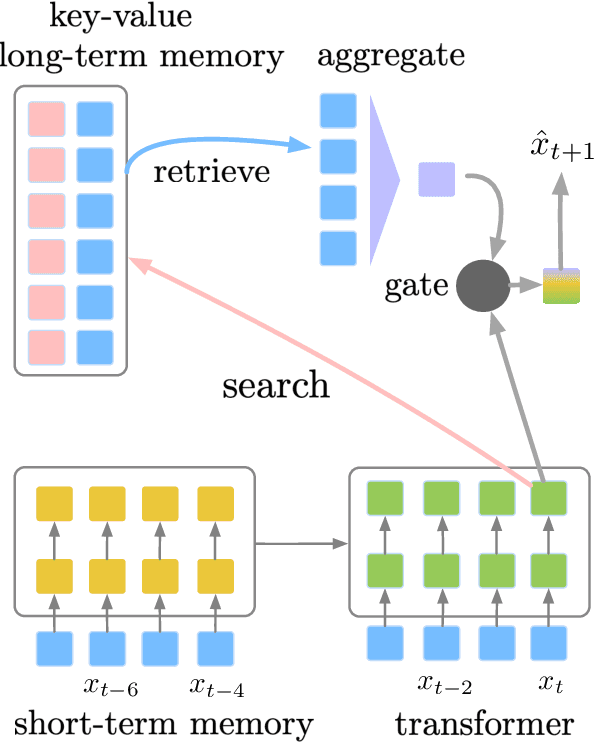
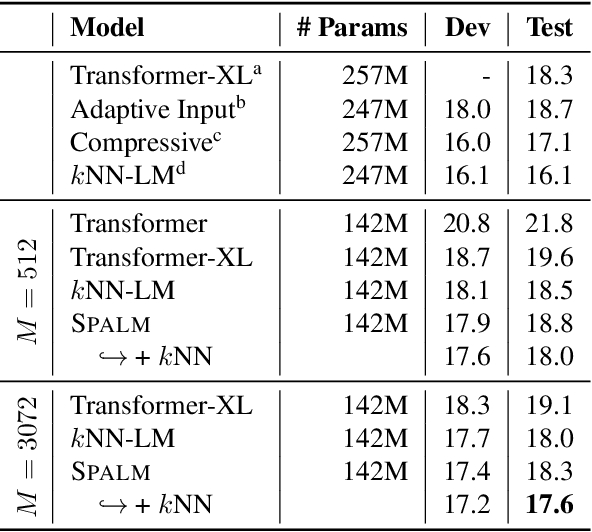
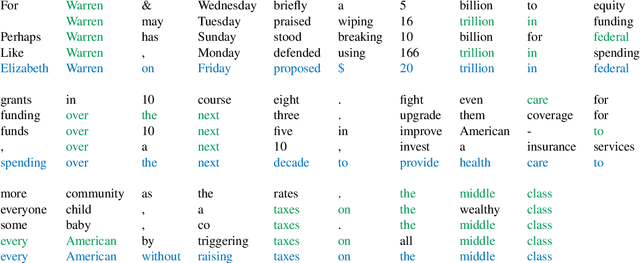
We present a language model that combines a large parametric neural network (i.e., a transformer) with a non-parametric episodic memory component in an integrated architecture. Our model uses extended short-term context by caching local hidden states -- similar to transformer-XL -- and global long-term memory by retrieving a set of nearest neighbor tokens at each timestep. We design a gating function to adaptively combine multiple information sources to make a prediction. This mechanism allows the model to use either local context, short-term memory, or long-term memory (or any combination of them) on an ad hoc basis depending on the context. Experiments on word-based and character-based language modeling datasets demonstrate the efficacy of our proposed method compared to strong baselines.
Pitfalls of Static Language Modelling
Feb 03, 2021
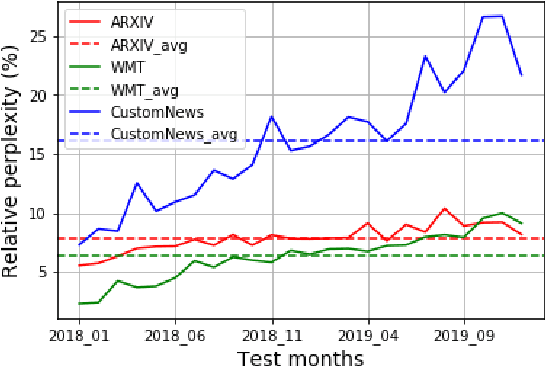
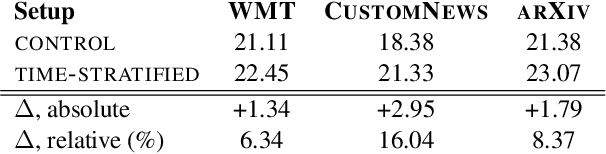
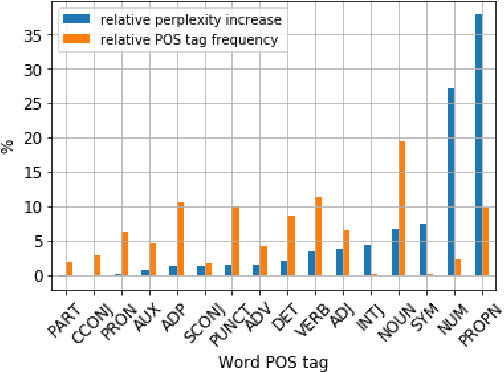
Our world is open-ended, non-stationary and constantly evolving; thus what we talk about and how we talk about it changes over time. This inherent dynamic nature of language comes in stark contrast to the current static language modelling paradigm, which constructs training and evaluation sets from overlapping time periods. Despite recent progress, we demonstrate that state-of-the-art Transformer models perform worse in the realistic setup of predicting future utterances from beyond their training period -- a consistent pattern across three datasets from two domains. We find that, while increasing model size alone -- a key driver behind recent progress -- does not provide a solution for the temporal generalization problem, having models that continually update their knowledge with new information can indeed slow down the degradation over time. Hence, given the compilation of ever-larger language modelling training datasets, combined with the growing list of language-model-based NLP applications that require up-to-date knowledge about the world, we argue that now is the right time to rethink our static language modelling evaluation protocol, and develop adaptive language models that can remain up-to-date with respect to our ever-changing and non-stationary world.
Syntactic Structure Distillation Pretraining For Bidirectional Encoders
May 27, 2020
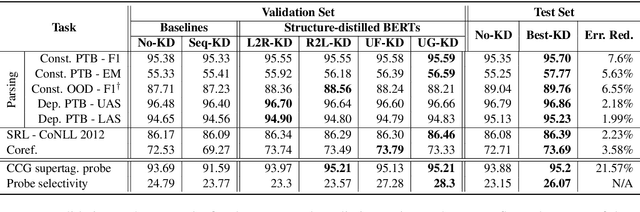
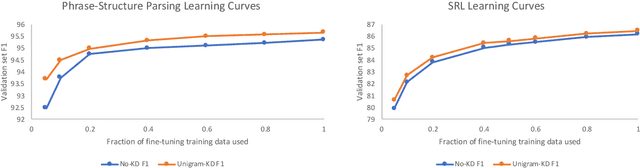
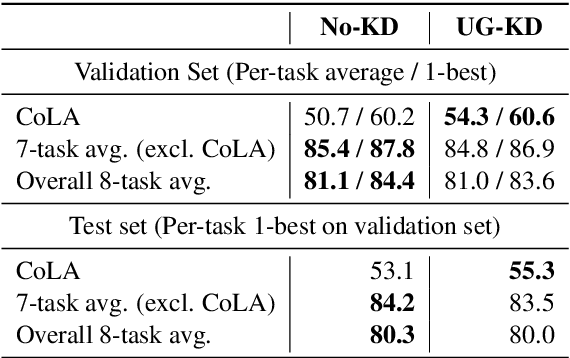
Textual representation learners trained on large amounts of data have achieved notable success on downstream tasks; intriguingly, they have also performed well on challenging tests of syntactic competence. Given this success, it remains an open question whether scalable learners like BERT can become fully proficient in the syntax of natural language by virtue of data scale alone, or whether they still benefit from more explicit syntactic biases. To answer this question, we introduce a knowledge distillation strategy for injecting syntactic biases into BERT pretraining, by distilling the syntactically informative predictions of a hierarchical---albeit harder to scale---syntactic language model. Since BERT models masked words in bidirectional context, we propose to distill the approximate marginal distribution over words in context from the syntactic LM. Our approach reduces relative error by 2-21% on a diverse set of structured prediction tasks, although we obtain mixed results on the GLUE benchmark. Our findings demonstrate the benefits of syntactic biases, even in representation learners that exploit large amounts of data, and contribute to a better understanding of where syntactic biases are most helpful in benchmarks of natural language understanding.
A Call for More Rigor in Unsupervised Cross-lingual Learning
Apr 30, 2020
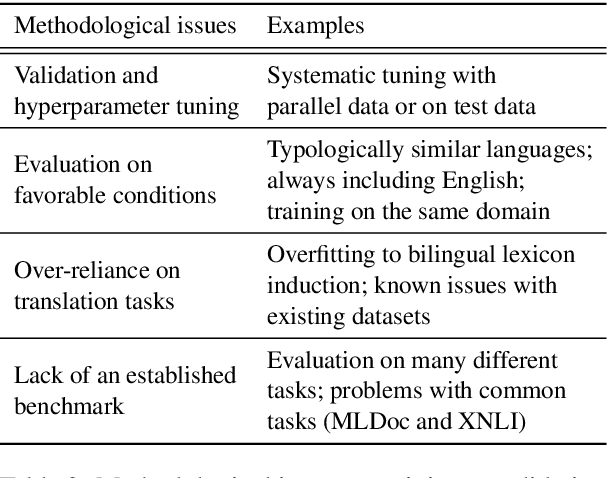
We review motivations, definition, approaches, and methodology for unsupervised cross-lingual learning and call for a more rigorous position in each of them. An existing rationale for such research is based on the lack of parallel data for many of the world's languages. However, we argue that a scenario without any parallel data and abundant monolingual data is unrealistic in practice. We also discuss different training signals that have been used in previous work, which depart from the pure unsupervised setting. We then describe common methodological issues in tuning and evaluation of unsupervised cross-lingual models and present best practices. Finally, we provide a unified outlook for different types of research in this area (i.e., cross-lingual word embeddings, deep multilingual pretraining, and unsupervised machine translation) and argue for comparable evaluation of these models.
Modelling Latent Skills for Multitask Language Generation
Feb 21, 2020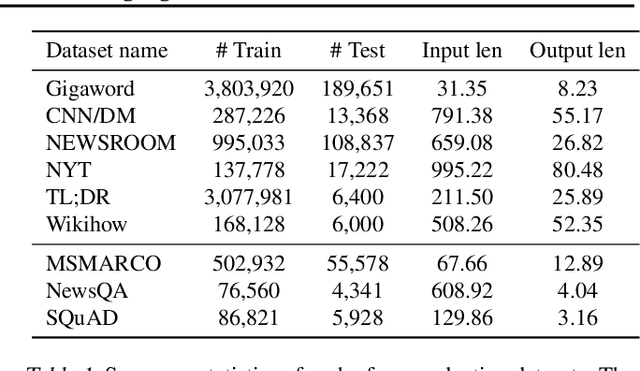

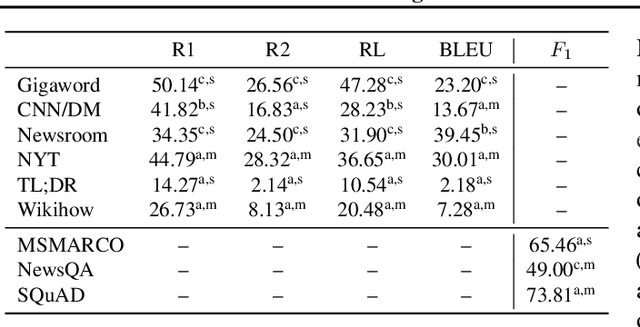
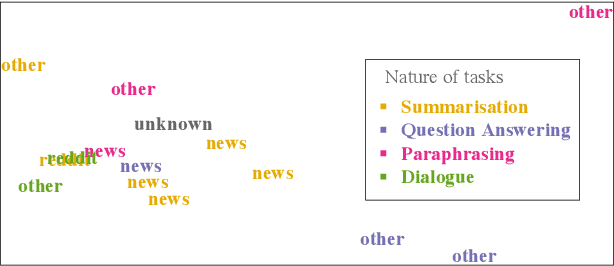
We present a generative model for multitask conditional language generation. Our guiding hypothesis is that a shared set of latent skills underlies many disparate language generation tasks, and that explicitly modelling these skills in a task embedding space can help with both positive transfer across tasks and with efficient adaptation to new tasks. We instantiate this task embedding space as a latent variable in a latent variable sequence-to-sequence model. We evaluate this hypothesis by curating a series of monolingual text-to-text language generation datasets - covering a broad range of tasks and domains - and comparing the performance of models both in the multitask and few-shot regimes. We show that our latent task variable model outperforms other sequence-to-sequence baselines on average across tasks in the multitask setting. In the few-shot learning setting on an unseen test dataset (i.e., a new task), we demonstrate that model adaptation based on inference in the latent task space is more robust than standard fine-tuning based parameter adaptation and performs comparably in terms of overall performance. Finally, we examine the latent task representations learnt by our model and show that they cluster tasks in a natural way.