 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA LongFormer-Based Framework for Accurate and Efficient Medical Text Summarization
Mar 10, 2025This paper proposes a medical text summarization method based on LongFormer, aimed at addressing the challenges faced by existing models when processing long medical texts. Traditional summarization methods are often limited by short-term memory, leading to information loss or reduced summary quality in long texts. LongFormer, by introducing long-range self-attention, effectively captures long-range dependencies in the text, retaining more key information and improving the accuracy and information retention of summaries. Experimental results show that the LongFormer-based model outperforms traditional models, such as RNN, T5, and BERT in automatic evaluation metrics like ROUGE. It also receives high scores in expert evaluations, particularly excelling in information retention and grammatical accuracy. However, there is still room for improvement in terms of conciseness and readability. Some experts noted that the generated summaries contain redundant information, which affects conciseness. Future research will focus on further optimizing the model structure to enhance conciseness and fluency, achieving more efficient medical text summarization. As medical data continues to grow, automated summarization technology will play an increasingly important role in fields such as medical research, clinical decision support, and knowledge management.
Enhancing Deep Learning with Optimized Gradient Descent: Bridging Numerical Methods and Neural Network Training
Sep 07, 2024



Optimization theory serves as a pivotal scientific instrument for achieving optimal system performance, with its origins in economic applications to identify the best investment strategies for maximizing benefits. Over the centuries, from the geometric inquiries of ancient Greece to the calculus contributions by Newton and Leibniz, optimization theory has significantly advanced. The persistent work of scientists like Lagrange, Cauchy, and von Neumann has fortified its progress. The modern era has seen an unprecedented expansion of optimization theory applications, particularly with the growth of computer science, enabling more sophisticated computational practices and widespread utilization across engineering, decision analysis, and operations research. This paper delves into the profound relationship between optimization theory and deep learning, highlighting the omnipresence of optimization problems in the latter. We explore the gradient descent algorithm and its variants, which are the cornerstone of optimizing neural networks. The chapter introduces an enhancement to the SGD optimizer, drawing inspiration from numerical optimization methods, aiming to enhance interpretability and accuracy. Our experiments on diverse deep learning tasks substantiate the improved algorithm's efficacy. The paper concludes by emphasizing the continuous development of optimization theory and its expanding role in solving intricate problems, enhancing computational capabilities, and informing better policy decisions.
Research on Optimization of Natural Language Processing Model Based on Multimodal Deep Learning
Jun 13, 2024



This project intends to study the image representation based on attention mechanism and multimodal data. By adding multiple pattern layers to the attribute model, the semantic and hidden layers of image content are integrated. The word vector is quantified by the Word2Vec method and then evaluated by a word embedding convolutional neural network. The published experimental results of the two groups were tested. The experimental results show that this method can convert discrete features into continuous characters, thus reducing the complexity of feature preprocessing. Word2Vec and natural language processing technology are integrated to achieve the goal of direct evaluation of missing image features. The robustness of the image feature evaluation model is improved by using the excellent feature analysis characteristics of a convolutional neural network. This project intends to improve the existing image feature identification methods and eliminate the subjective influence in the evaluation process. The findings from the simulation indicate that the novel approach has developed is viable, effectively augmenting the features within the produced representations.
Research on Deep Learning Model of Feature Extraction Based on Convolutional Neural Network
Jun 13, 2024Neural networks with relatively shallow layers and simple structures may have limited ability in accurately identifying pneumonia. In addition, deep neural networks also have a large demand for computing resources, which may cause convolutional neural networks to be unable to be implemented on terminals. Therefore, this paper will carry out the optimal classification of convolutional neural networks. Firstly, according to the characteristics of pneumonia images, AlexNet and InceptionV3 were selected to obtain better image recognition results. Combining the features of medical images, the forward neural network with deeper and more complex structure is learned. Finally, knowledge extraction technology is used to extract the obtained data into the AlexNet model to achieve the purpose of improving computing efficiency and reducing computing costs. The results showed that the prediction accuracy, specificity, and sensitivity of the trained AlexNet model increased by 4.25 percentage points, 7.85 percentage points, and 2.32 percentage points, respectively. The graphics processing usage has decreased by 51% compared to the InceptionV3 mode.
Theoretical Analysis of Meta Reinforcement Learning: Generalization Bounds and Convergence Guarantees
May 22, 2024


This research delves deeply into Meta Reinforcement Learning (Meta RL) through a exploration focusing on defining generalization limits and ensuring convergence. By employing a approach this article introduces an innovative theoretical framework to meticulously assess the effectiveness and performance of Meta RL algorithms. We present an explanation of generalization limits measuring how well these algorithms can adapt to learning tasks while maintaining consistent results. Our analysis delves into the factors that impact the adaptability of Meta RL revealing the relationship, between algorithm design and task complexity. Additionally we establish convergence assurances by proving conditions under which Meta RL strategies are guaranteed to converge towards solutions. We examine the convergence behaviors of Meta RL algorithms across scenarios providing a comprehensive understanding of the driving forces behind their long term performance. This exploration covers both convergence and real time efficiency offering a perspective, on the capabilities of these algorithms.
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Apr 07, 2024



The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
An Evolution Kernel Method for Graph Classification through Heat Diffusion Dynamics
Jun 26, 2023



Autonomous individuals establish a structural complex system through pairwise connections and interactions. Notably, the evolution reflects the dynamic nature of each complex system since it recodes a series of temporal changes from the past, the present into the future. Different systems follow distinct evolutionary trajectories, which can serve as distinguishing traits for system classification. However, modeling a complex system's evolution is challenging for the graph model because the graph is typically a snapshot of the static status of a system, and thereby hard to manifest the long-term evolutionary traits of a system entirely. To address this challenge, we suggest utilizing a heat-driven method to generate temporal graph augmentation. This approach incorporates the physics-based heat kernel and DropNode technique to transform each static graph into a sequence of temporal ones. This approach effectively describes the evolutional behaviours of the system, including the retention or disappearance of elements at each time point based on the distributed heat on each node. Additionally, we propose a dynamic time-wrapping distance GDTW to quantitatively measure the distance between pairwise evolutionary systems through optimal matching. The resulting approach, called the Evolution Kernel method, has been successfully applied to classification problems in real-world structural graph datasets. The results yield significant improvements in supervised classification accuracy over a series of baseline methods.
Metric Distribution to Vector: Constructing Data Representation via Broad-Scale Discrepancies
Oct 02, 2022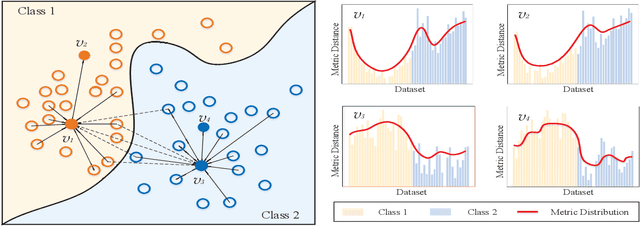
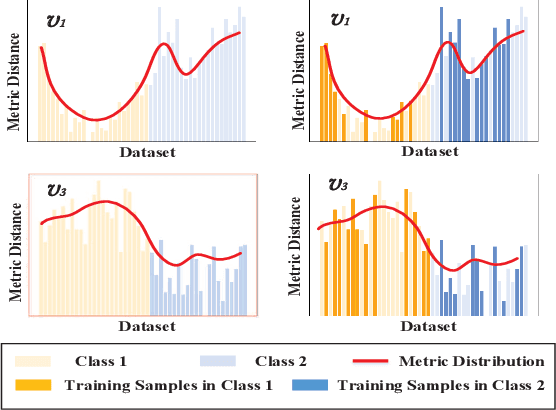

Graph embedding provides a feasible methodology to conduct pattern classification for graph-structured data by mapping each data into the vectorial space. Various pioneering works are essentially coding method that concentrates on a vectorial representation about the inner properties of a graph in terms of the topological constitution, node attributions, link relations, etc. However, the classification for each targeted data is a qualitative issue based on understanding the overall discrepancies within the dataset scale. From the statistical point of view, these discrepancies manifest a metric distribution over the dataset scale if the distance metric is adopted to measure the pairwise similarity or dissimilarity. Therefore, we present a novel embedding strategy named $\mathbf{MetricDistribution2vec}$ to extract such distribution characteristics into the vectorial representation for each data. We demonstrate the application and effectiveness of our representation method in the supervised prediction tasks on extensive real-world structural graph datasets. The results have gained some unexpected increases compared with a surge of baselines on all the datasets, even if we take the lightweight models as classifiers. Moreover, the proposed methods also conducted experiments in Few-Shot classification scenarios, and the results still show attractive discrimination in rare training samples based inference.
A Graph Data Augmentation Strategy with Entropy Preserving
Jul 13, 2021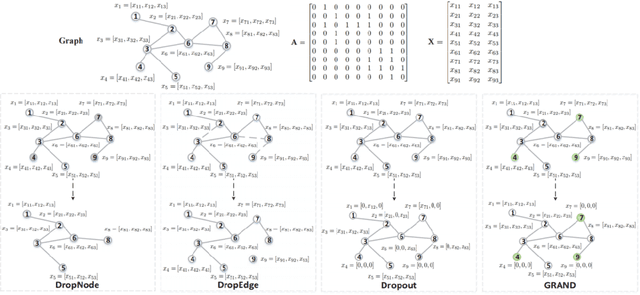
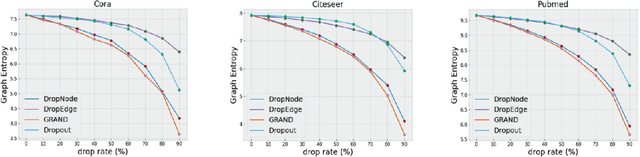
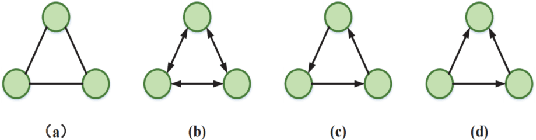
The Graph Convolutional Networks (GCNs) proposed by Kipf and Welling are effective models for semi-supervised learning, but facing the obstacle of over-smoothing, which will weaken the representation ability of GCNs. Recently some works are proposed to tackle with above limitation by randomly perturbing graph topology or feature matrix to generate data augmentations as input for training. However, these operations have to pay the price of information structure integrity breaking, and inevitably sacrifice information stochastically from original graph. In this paper, we introduce a novel graph entropy definition as an quantitative index to evaluate feature information diffusion among a graph. Under considerations of preserving graph entropy, we propose an effective strategy to generate perturbed training data using a stochastic mechanism but guaranteeing graph topology integrity and with only a small amount of graph entropy decaying. Extensive experiments have been conducted on real-world datasets and the results verify the effectiveness of our proposed method in improving semi-supervised node classification accuracy compared with a surge of baselines. Beyond that, our proposed approach significantly enhances the robustness and generalization ability of GCNs during the training process.
Graph Classification Based on Skeleton and Component Features
Feb 02, 2021
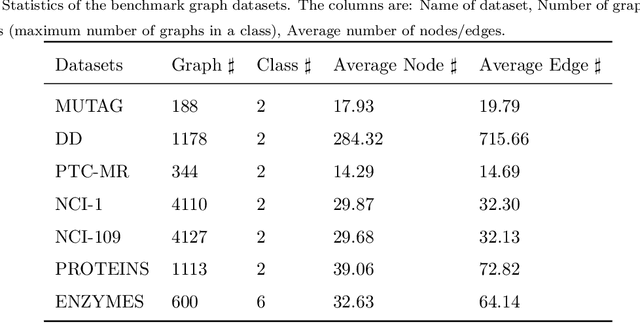
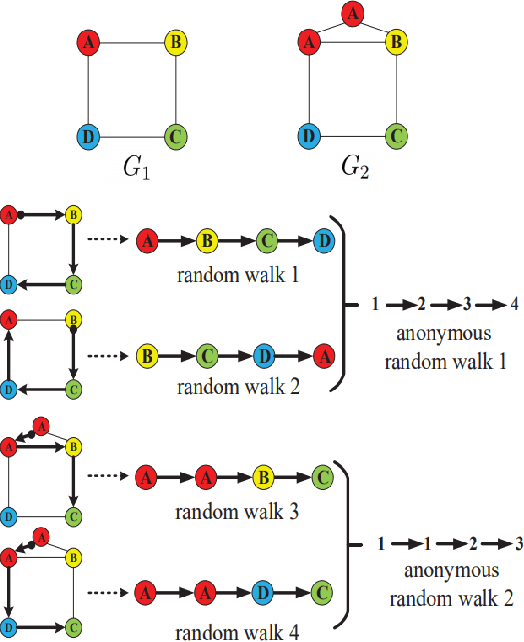
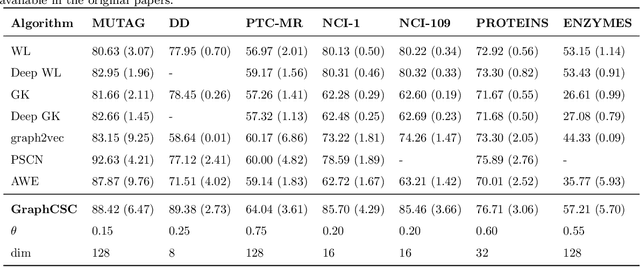
Most existing popular methods for learning graph embedding only consider fixed-order global structural features and lack structures hierarchical representation. To address this weakness, we propose a novel graph embedding algorithm named GraphCSC that realizes classification based on skeleton information using fixed-order structures learned in anonymous random walks manner, and component information using different size subgraphs. Two graphs are similar if their skeletons and components are both similar, thus in our model, we integrate both of them together into embeddings as graph homogeneity characterization. We demonstrate our model on different datasets in comparison with a comprehensive list of up-to-date state-of-the-art baselines, and experiments show that our work is superior in real-world graph classification tasks.