 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm-hardware co-design of neuromorphic networks with dual memory pathways
Dec 11, 2025Spiking neural networks excel at event-driven sensing. Yet, maintaining task-relevant context over long timescales both algorithmically and in hardware, while respecting both tight energy and memory budgets, remains a core challenge in the field. We address this challenge through novel algorithm-hardware co-design effort. At the algorithm level, inspired by the cortical fast-slow organization in the brain, we introduce a neural network with an explicit slow memory pathway that, combined with fast spiking activity, enables a dual memory pathway (DMP) architecture in which each layer maintains a compact low-dimensional state that summarizes recent activity and modulates spiking dynamics. This explicit memory stabilizes learning while preserving event-driven sparsity, achieving competitive accuracy on long-sequence benchmarks with 40-60% fewer parameters than equivalent state-of-the-art spiking neural networks. At the hardware level, we introduce a near-memory-compute architecture that fully leverages the advantages of the DMP architecture by retaining its compact shared state while optimizing dataflow, across heterogeneous sparse-spike and dense-memory pathways. We show experimental results that demonstrate more than a 4x increase in throughput and over a 5x improvement in energy efficiency compared with state-of-the-art implementations. Together, these contributions demonstrate that biological principles can guide functional abstractions that are both algorithmically effective and hardware-efficient, establishing a scalable co-design paradigm for real-time neuromorphic computation and learning.
Exploiting heterogeneous delays for efficient computation in low-bit neural networks
Oct 31, 2025Neural networks rely on learning synaptic weights. However, this overlooks other neural parameters that can also be learned and may be utilized by the brain. One such parameter is the delay: the brain exhibits complex temporal dynamics with heterogeneous delays, where signals are transmitted asynchronously between neurons. It has been theorized that this delay heterogeneity, rather than a cost to be minimized, can be exploited in embodied contexts where task-relevant information naturally sits contextually in the time domain. We test this hypothesis by training spiking neural networks to modify not only their weights but also their delays at different levels of precision. We find that delay heterogeneity enables state-of-the-art performance on temporally complex neuromorphic problems and can be achieved even when weights are extremely imprecise (1.58-bit ternary precision: just positive, negative, or absent). By enabling high performance with extremely low-precision weights, delay heterogeneity allows memory-efficient solutions that maintain state-of-the-art accuracy even when weights are compressed over an order of magnitude more aggressively than typically studied weight-only networks. We show how delays and time-constants adaptively trade-off, and reveal through ablation that task performance depends on task-appropriate delay distributions, with temporally-complex tasks requiring longer delays. Our results suggest temporal heterogeneity is an important principle for efficient computation, particularly when task-relevant information is temporal - as in the physical world - with implications for embodied intelligent systems and neuromorphic hardware.
A Path to Universal Neural Cellular Automata
May 19, 2025



Cellular automata have long been celebrated for their ability to generate complex behaviors from simple, local rules, with well-known discrete models like Conway's Game of Life proven capable of universal computation. Recent advancements have extended cellular automata into continuous domains, raising the question of whether these systems retain the capacity for universal computation. In parallel, neural cellular automata have emerged as a powerful paradigm where rules are learned via gradient descent rather than manually designed. This work explores the potential of neural cellular automata to develop a continuous Universal Cellular Automaton through training by gradient descent. We introduce a cellular automaton model, objective functions and training strategies to guide neural cellular automata toward universal computation in a continuous setting. Our experiments demonstrate the successful training of fundamental computational primitives - such as matrix multiplication and transposition - culminating in the emulation of a neural network solving the MNIST digit classification task directly within the cellular automata state. These results represent a foundational step toward realizing analog general-purpose computers, with implications for understanding universal computation in continuous dynamics and advancing the automated discovery of complex cellular automata behaviors via machine learning.
Adapting to time: why nature evolved a diverse set of neurons
Apr 22, 2024Evolution has yielded a diverse set of neurons with varying morphologies and physiological properties that impact their processing of temporal information. In addition, it is known empirically that spike timing is a significant factor in neural computations. However, despite these two observations, most neural network models deal with spatially structured inputs with synchronous time steps, while restricting variation to parameters like weights and biases. In this study, we investigate the relevance of adapting temporal parameters, like time constants and delays, in feedforward networks that map spatio-temporal spike patterns. In this context, we show that networks with richer potential dynamics are able to more easily and robustly learn tasks with temporal structure. Indeed, when adaptation was restricted to weights, networks were unable to solve most problems. We also show strong interactions between the various parameters and the advantages of adapting temporal parameters when dealing with noise in inputs and weights, which might prove useful in neuromorphic hardware design.
Extreme sparsity gives rise to functional specialization
Jun 04, 2021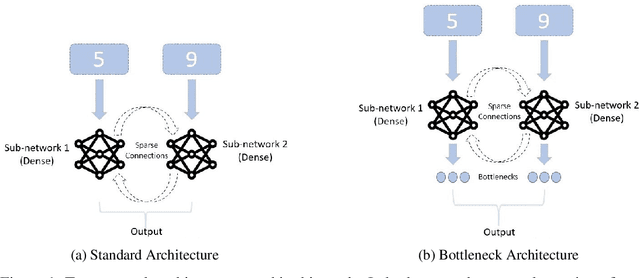


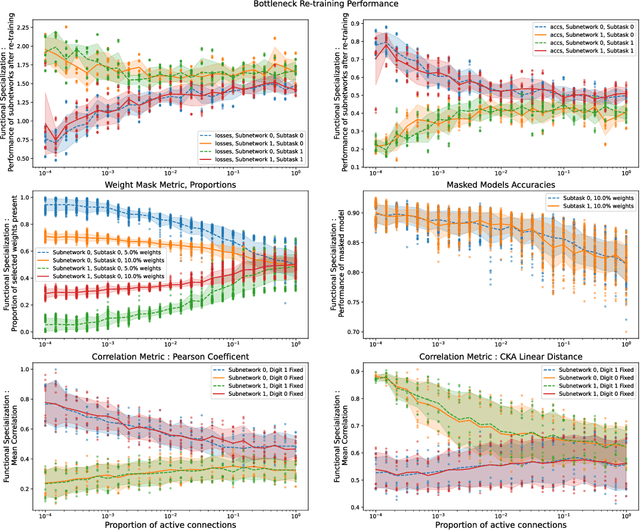
Modularity of neural networks -- both biological and artificial -- can be thought of either structurally or functionally, and the relationship between these is an open question. We show that enforcing structural modularity via sparse connectivity between two dense sub-networks which need to communicate to solve the task leads to functional specialization of the sub-networks, but only at extreme levels of sparsity. With even a moderate number of interconnections, the sub-networks become functionally entangled. Defining functional specialization is in itself a challenging problem without a universally agreed solution. To address this, we designed three different measures of specialization (based on weight masks, retraining and correlation) and found them to qualitatively agree. Our results have implications in both neuroscience and machine learning. For neuroscience, it shows that we cannot conclude that there is functional modularity simply by observing moderate levels of structural modularity: knowing the brain's connectome is not sufficient for understanding how it breaks down into functional modules. For machine learning, using structure to promote functional modularity -- which may be important for robustness and generalization -- may require extremely narrow bottlenecks between modules.
Sparse Spiking Gradient Descent
May 18, 2021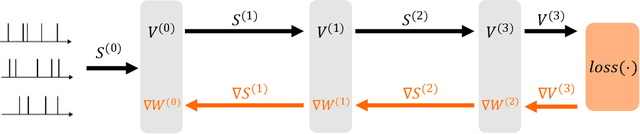
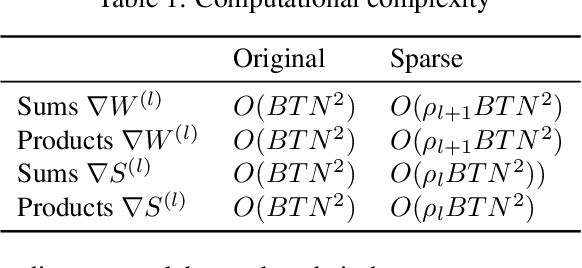
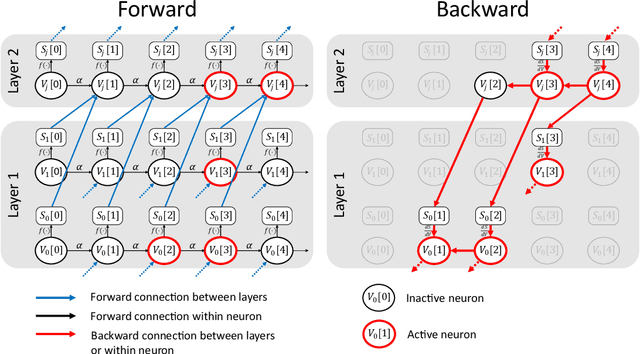

There is an increasing interest in emulating Spiking Neural Networks (SNNs) on neuromorphic computing devices due to their low energy consumption. Recent advances have allowed training SNNs to a point where they start to compete with traditional Artificial Neural Networks (ANNs) in terms of accuracy, while at the same time being energy efficient when run on neuromorphic hardware. However, the process of training SNNs is still based on dense tensor operations originally developed for ANNs which do not leverage the spatiotemporally sparse nature of SNNs. We present here the first sparse SNN backpropagation algorithm which achieves the same or better accuracy as current state of the art methods while being significantly faster and more memory efficient. We show the effectiveness of our method on real datasets of varying complexity (Fashion-MNIST, Neuromophic-MNIST and Spiking Heidelberg Digits) achieving a speedup in the backward pass of up to 70x, and 40% more memory efficient, without losing accuracy.
High-dimensional cluster analysis with the Masked EM Algorithm
Sep 11, 2013Cluster analysis faces two problems in high dimensions: first, the `curse of dimensionality' that can lead to overfitting and poor generalization performance; and second, the sheer time taken for conventional algorithms to process large amounts of high-dimensional data. In many applications, only a small subset of features provide information about the cluster membership of any one data point, however this informative feature subset may not be the same for all data points. Here we introduce a `Masked EM' algorithm for fitting mixture of Gaussians models in such cases. We show that the algorithm performs close to optimally on simulated Gaussian data, and in an application of `spike sorting' of high channel-count neuronal recordings.