 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Temporal Feature Aggregation for Event Detection in Unstructured Sports Videos
Feb 19, 2020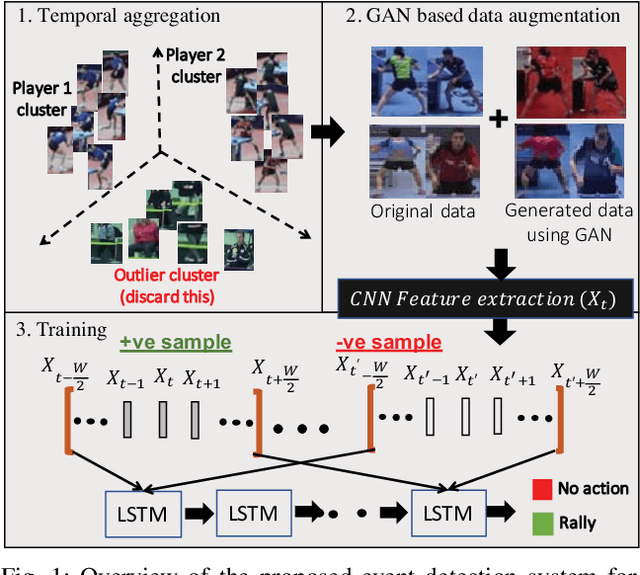



Image-based sports analytics enable automatic retrieval of key events in a game to speed up the analytics process for human experts. However, most existing methods focus on structured television broadcast video datasets with a straight and fixed camera having minimum variability in the capturing pose. In this paper, we study the case of event detection in sports videos for unstructured environments with arbitrary camera angles. The transition from structured to unstructured video analysis produces multiple challenges that we address in our paper. Specifically, we identify and solve two major problems: unsupervised identification of players in an unstructured setting and generalization of the trained models to pose variations due to arbitrary shooting angles. For the first problem, we propose a temporal feature aggregation algorithm using person re-identification features to obtain high player retrieval precision by boosting a weak heuristic scoring method. Additionally, we propose a data augmentation technique, based on multi-modal image translation model, to reduce bias in the appearance of training samples. Experimental evaluations show that our proposed method improves precision for player retrieval from 0.78 to 0.86 for obliquely angled videos. Additionally, we obtain an improvement in F1 score for rally detection in table tennis videos from 0.79 in case of global frame-level features to 0.89 using our proposed player-level features. Please see the supplementary video submission at https://ibm.biz/BdzeZA.
Spatially-weighted Anomaly Detection with Regression Model
Mar 28, 2019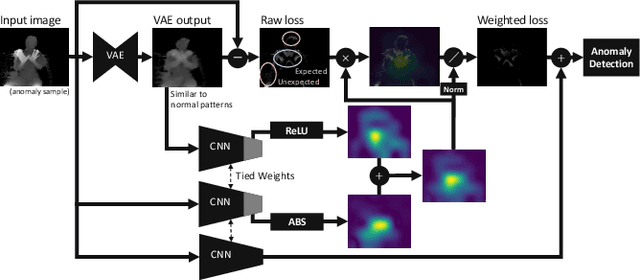
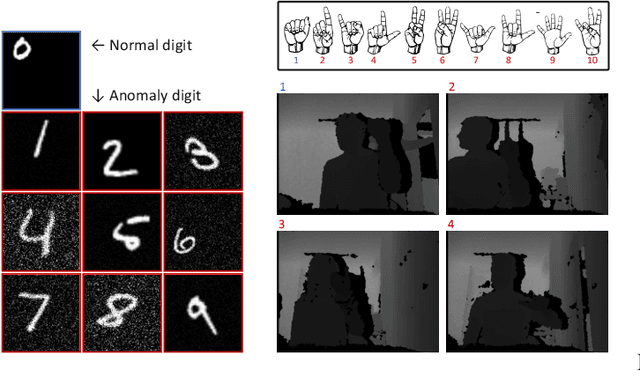
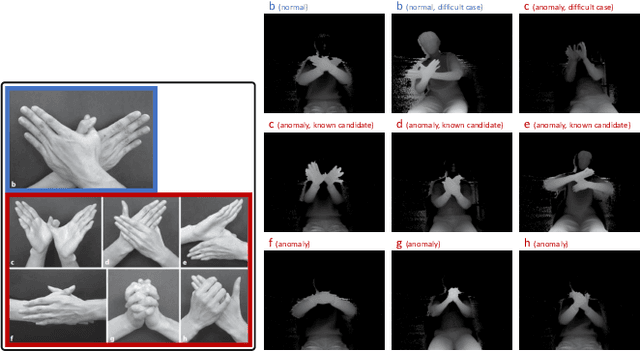
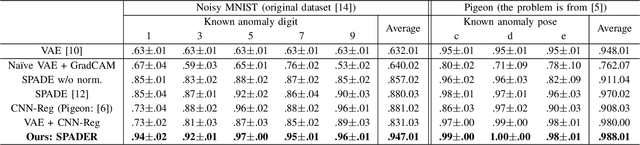
Visual anomaly detection is common in several applications including medical screening and production quality check. Although a definition of the anomaly is an unknown trend in data, in many cases some hints or samples of the anomaly class can be given in advance. Conventional methods cannot use the available anomaly data, and also do not have a robustness of noise. In this paper, we propose a novel spatially-weighted reconstruction-loss-based anomaly detection with a likelihood value from a regression model trained by all known data. The spatial weights are calculated by a region of interest generated from employing visualization of the regression model. We introduce some ways to combine with various strategies to propose a state-of-the-art method. Comparing with other methods on three different datasets, we empirically verify the proposed method performs better than the others.
Internal Model from Observations for Reward Shaping
Oct 14, 2018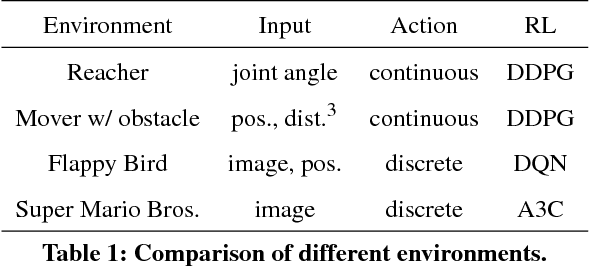
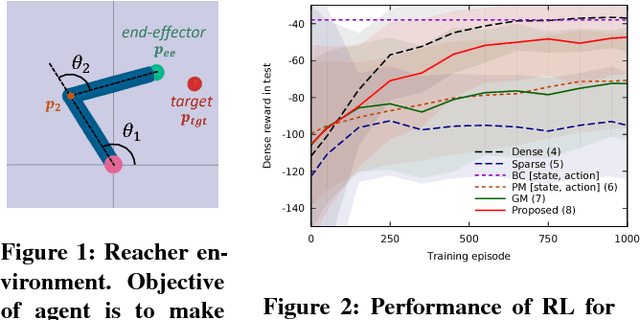
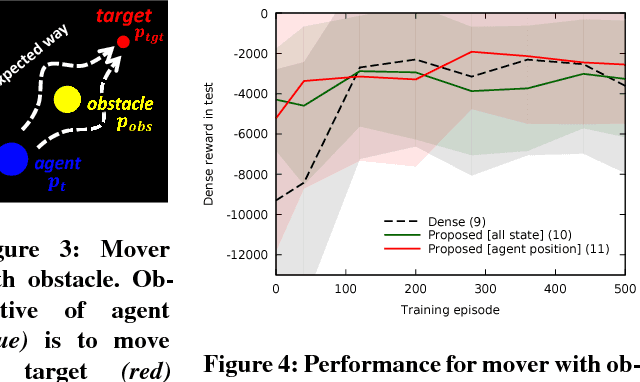
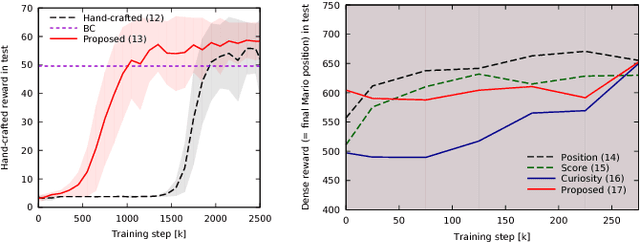
Reinforcement learning methods require careful design involving a reward function to obtain the desired action policy for a given task. In the absence of hand-crafted reward functions, prior work on the topic has proposed several methods for reward estimation by using expert state trajectories and action pairs. However, there are cases where complete or good action information cannot be obtained from expert demonstrations. We propose a novel reinforcement learning method in which the agent learns an internal model of observation on the basis of expert-demonstrated state trajectories to estimate rewards without completely learning the dynamics of the external environment from state-action pairs. The internal model is obtained in the form of a predictive model for the given expert state distribution. During reinforcement learning, the agent predicts the reward as a function of the difference between the actual state and the state predicted by the internal model. We conducted multiple experiments in environments of varying complexity, including the Super Mario Bros and Flappy Bird games. We show our method successfully trains good policies directly from expert game-play videos.
Video Imitation GAN: Learning control policies by imitating raw videos using generative adversarial reward estimation
Oct 02, 2018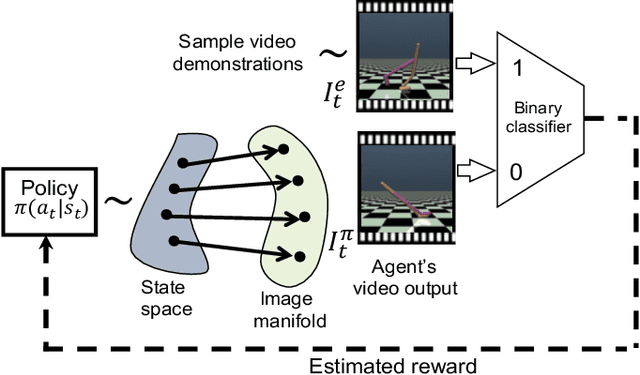
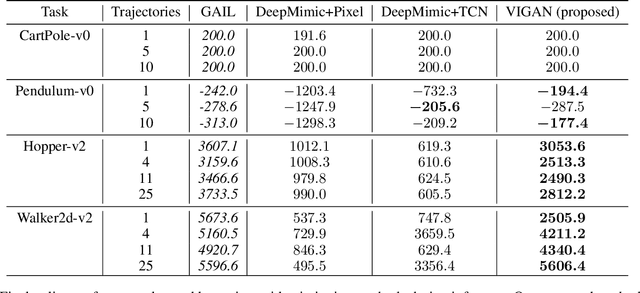
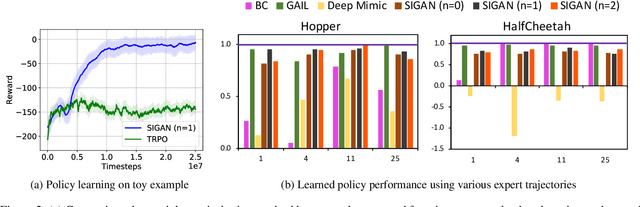
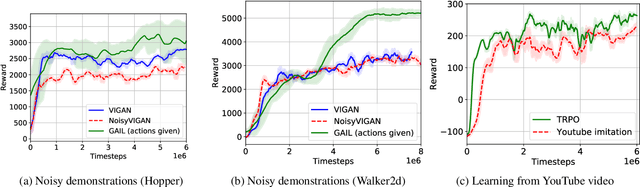
Natural imitation in humans usually consists of mimicking visual demonstrations of another person by continuously refining our skills until our performance is visually akin to the expert demonstrations. In this paper, we are interested in imitation learning of artificial agents in the natural setting - acquiring motor skills by watching raw video demonstrations. Traditional methods for learning from videos rely on extracting meaningful low-dimensional features from the videos followed by a separate hand-crafted reward estimation step based on feature separation between the agent and expert. We propose an imitation learning framework from raw video demonstrations, that reduces the dependence on hand engineered reward functions, by jointly learning the feature extraction and separation estimation steps, using generative adversarial networks. Additionally, we establish the equivalence between adversarial imitation from image manifolds and low-level state distribution matching, under certain conditions. Experimental results show that our proposed imitation learning method from raw videos produces a similar performance to state-of-the-art imitation learning techniques with low-level state and action information available while outperforming existing video imitation methods. Furthermore, we show that our method can learn action policies by imitating video demonstrations available on YouTube with performance comparable to learned agents from true reward signal. Please see the video at https://youtu.be/bvNpV2Q4rOA.
Focusing on What is Relevant: Time-Series Learning and Understanding using Attention
Jun 22, 2018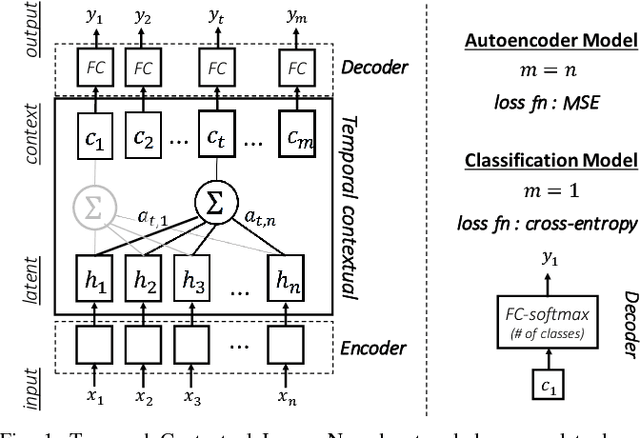
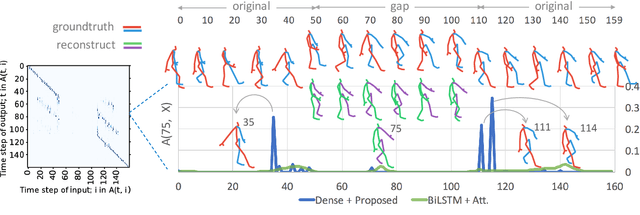

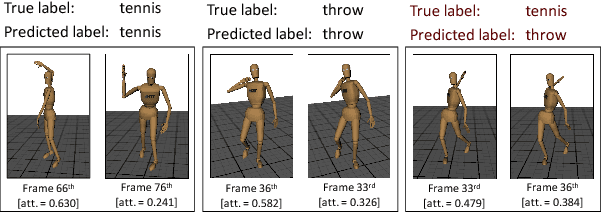
This paper is a contribution towards interpretability of the deep learning models in different applications of time-series. We propose a temporal attention layer that is capable of selecting the relevant information to perform various tasks, including data completion, key-frame detection and classification. The method uses the whole input sequence to calculate an attention value for each time step. This results in more focused attention values and more plausible visualisation than previous methods. We apply the proposed method to three different tasks. Experimental results show that the proposed network produces comparable results to a state of the art. In addition, the network provides better interpretability of the decision, that is, it generates more significant attention weight to related frames compared to similar techniques attempted in the past.
MaestROB: A Robotics Framework for Integrated Orchestration of Low-Level Control and High-Level Reasoning
Jun 03, 2018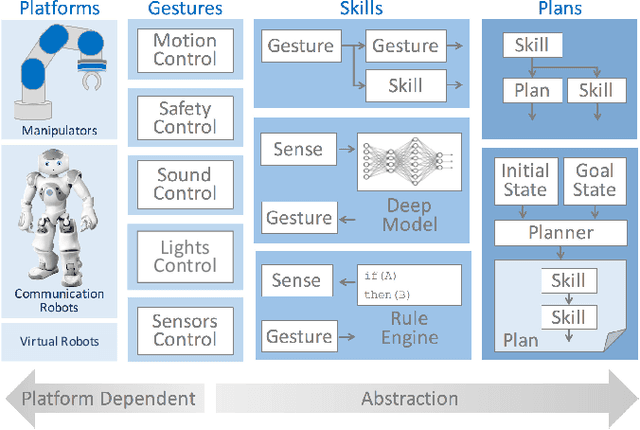
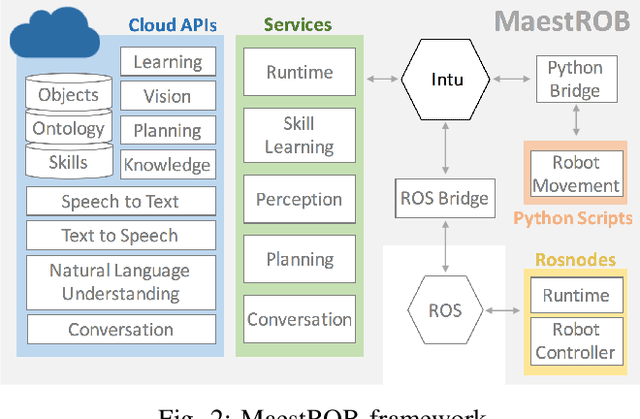
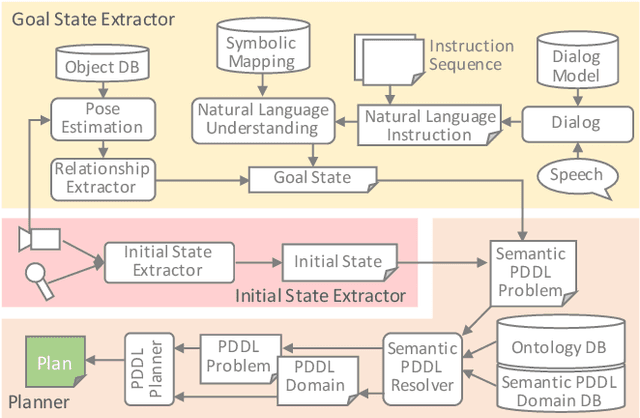
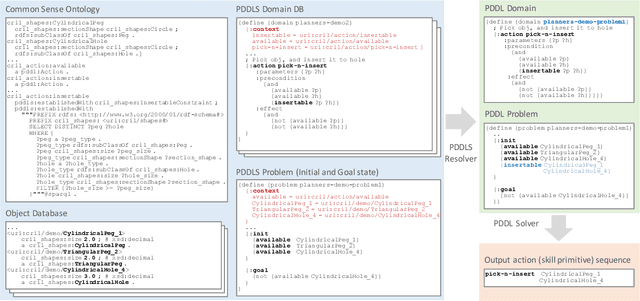
This paper describes a framework called MaestROB. It is designed to make the robots perform complex tasks with high precision by simple high-level instructions given by natural language or demonstration. To realize this, it handles a hierarchical structure by using the knowledge stored in the forms of ontology and rules for bridging among different levels of instructions. Accordingly, the framework has multiple layers of processing components; perception and actuation control at the low level, symbolic planner and Watson APIs for cognitive capabilities and semantic understanding, and orchestration of these components by a new open source robot middleware called Project Intu at its core. We show how this framework can be used in a complex scenario where multiple actors (human, a communication robot, and an industrial robot) collaborate to perform a common industrial task. Human teaches an assembly task to Pepper (a humanoid robot from SoftBank Robotics) using natural language conversation and demonstration. Our framework helps Pepper perceive the human demonstration and generate a sequence of actions for UR5 (collaborative robot arm from Universal Robots), which ultimately performs the assembly (e.g. insertion) task.
DAQN: Deep Auto-encoder and Q-Network
Jun 02, 2018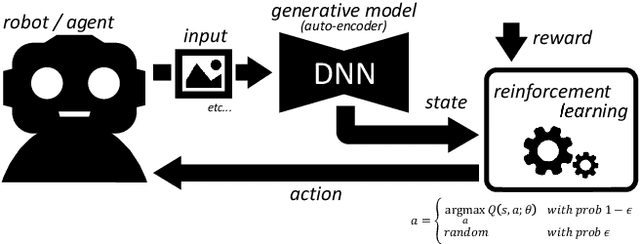
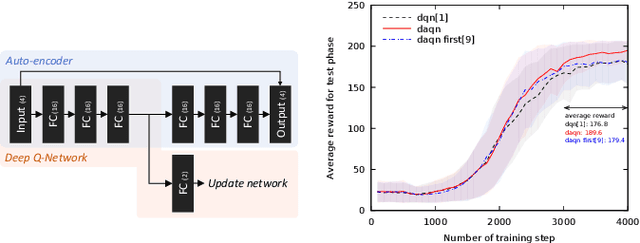
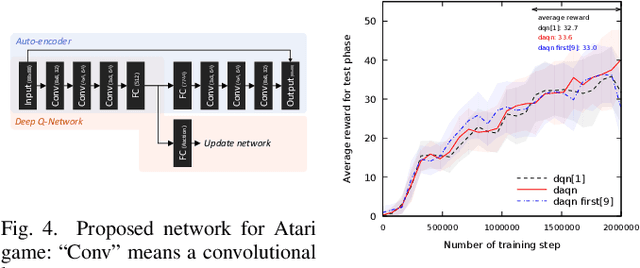

The deep reinforcement learning method usually requires a large number of training images and executing actions to obtain sufficient results. When it is extended a real-task in the real environment with an actual robot, the method will be required more training images due to complexities or noises of the input images, and executing a lot of actions on the real robot also becomes a serious problem. Therefore, we propose an extended deep reinforcement learning method that is applied a generative model to initialize the network for reducing the number of training trials. In this paper, we used a deep q-network method as the deep reinforcement learning method and a deep auto-encoder as the generative model. We conducted experiments on three different tasks: a cart-pole game, an atari game, and a real-game with an actual robot. The proposed method trained efficiently on all tasks than the previous method, especially 2.5 times faster on a task with real environment images.