 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Neural vs. Matrix-Factorization Collaborative Filtering: the Theoretical Perspectives
Oct 23, 2021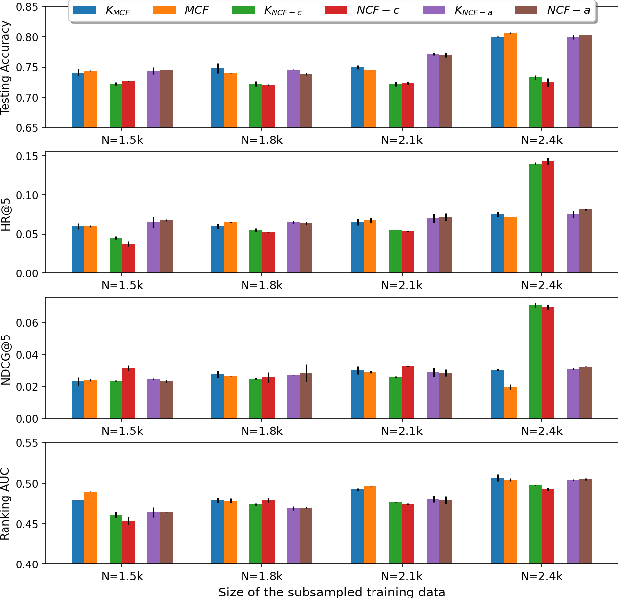
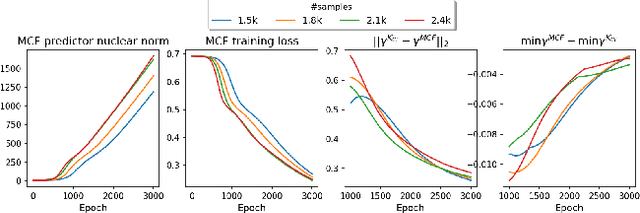
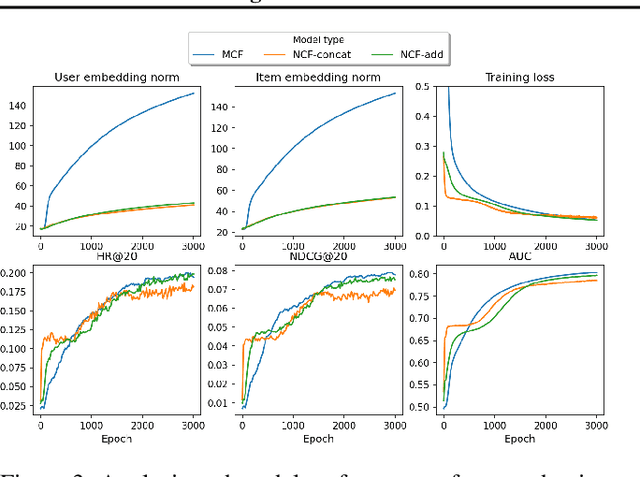
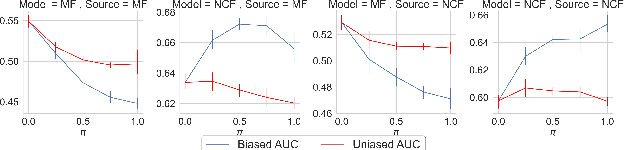
The recent work by Rendle et al. (2020), based on empirical observations, argues that matrix-factorization collaborative filtering (MCF) compares favorably to neural collaborative filtering (NCF), and conjectures the dot product's superiority over the feed-forward neural network as similarity function. In this paper, we address the comparison rigorously by answering the following questions: 1. what is the limiting expressivity of each model; 2. under the practical gradient descent, to which solution does each optimization path converge; 3. how would the models generalize under the inductive and transductive learning setting. Our results highlight the similar expressivity for the overparameterized NCF and MCF as kernelized predictors, and reveal the relation between their optimization paths. We further show their different generalization behaviors, where MCF and NCF experience specific tradeoff and comparison in the transductive and inductive collaborative filtering setting. Lastly, by showing a novel generalization result, we reveal the critical role of correcting exposure bias for model evaluation in the inductive setting. Our results explain some of the previously observed conflicts, and we provide synthetic and real-data experiments to shed further insights to this topic.
Towards the D-Optimal Online Experiment Design for Recommender Selection
Oct 23, 2021
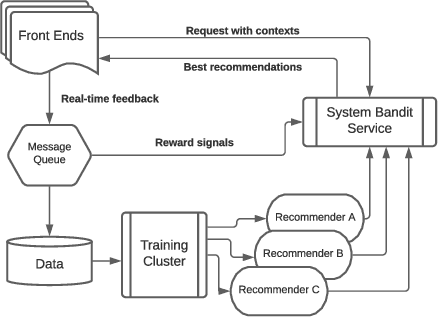
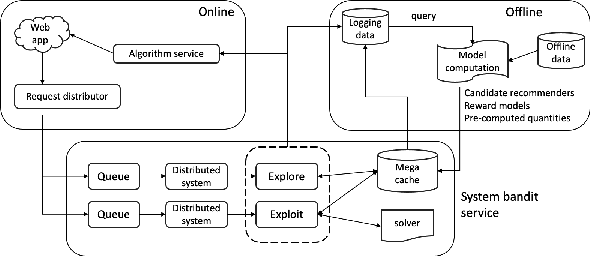
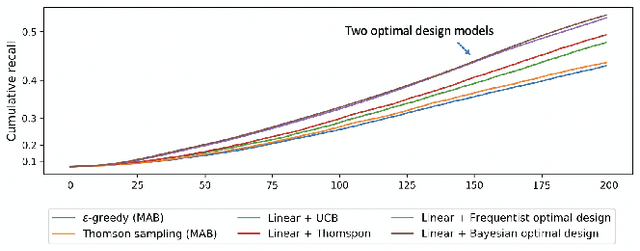
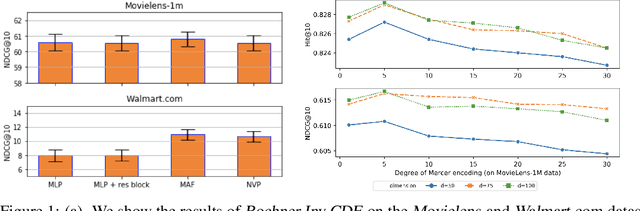
Selecting the optimal recommender via online exploration-exploitation is catching increasing attention where the traditional A/B testing can be slow and costly, and offline evaluations are prone to the bias of history data. Finding the optimal online experiment is nontrivial since both the users and displayed recommendations carry contextual features that are informative to the reward. While the problem can be formalized via the lens of multi-armed bandits, the existing solutions are found less satisfactorily because the general methodologies do not account for the case-specific structures, particularly for the e-commerce recommendation we study. To fill in the gap, we leverage the \emph{D-optimal design} from the classical statistics literature to achieve the maximum information gain during exploration, and reveal how it fits seamlessly with the modern infrastructure of online inference. To demonstrate the effectiveness of the optimal designs, we provide semi-synthetic simulation studies with published code and data for reproducibility purposes. We then use our deployment example on Walmart.com to fully illustrate the practical insights and effectiveness of the proposed methods.
An Efficient Group-based Search Engine Marketing System for E-Commerce
Jul 17, 2021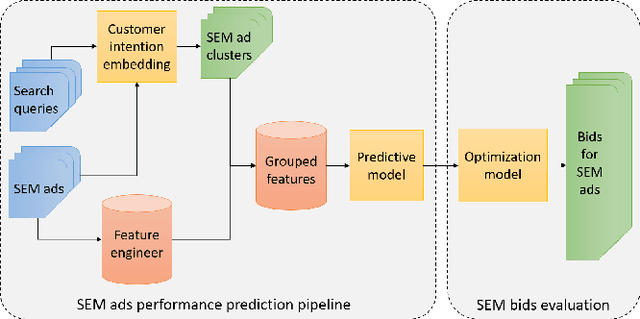
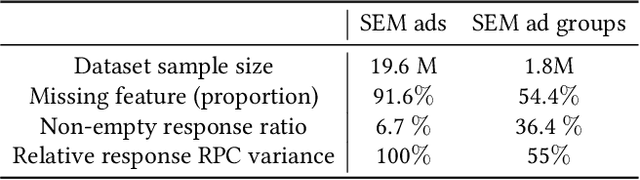
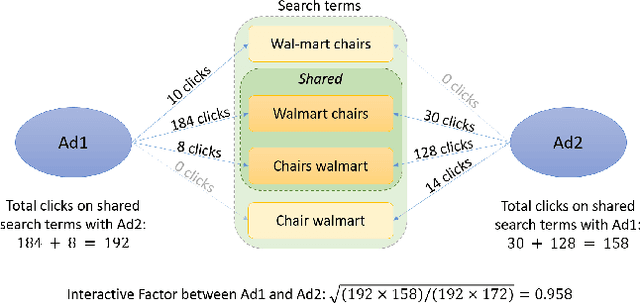

With the increasing scale of search engine marketing, designing an efficient bidding system is becoming paramount for the success of e-commerce companies. The critical challenges faced by a modern industrial-level bidding system include: 1. the catalog is enormous, and the relevant bidding features are of high sparsity; 2. the large volume of bidding requests induces significant computation burden to both the offline and online serving. Leveraging extraneous user-item information proves essential to mitigate the sparsity issue, for which we exploit the natural language signals from the users' query and the contextual knowledge from the products. In particular, we extract the vector representations of ads via the Transformer model and leverage their geometric relation to building collaborative bidding predictions via clustering. The two-step procedure also significantly reduces the computation stress of bid evaluation and optimization. In this paper, we introduce the end-to-end structure of the bidding system for search engine marketing for Walmart e-commerce, which successfully handles tens of millions of bids each day. We analyze the online and offline performances of our approach and discuss how we find it as a production-efficient solution.
A Temporal Kernel Approach for Deep Learning with Continuous-time Information
Mar 28, 2021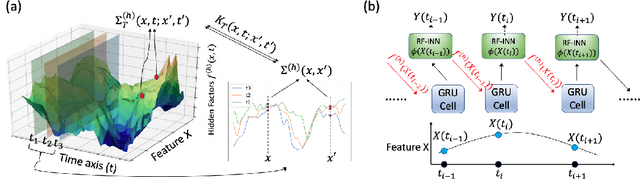
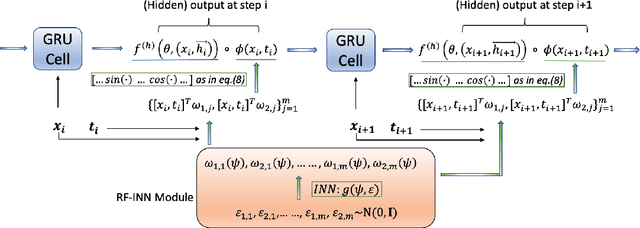
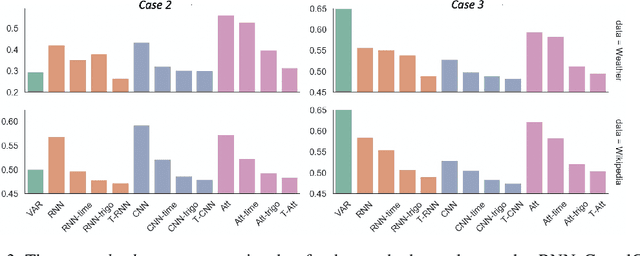
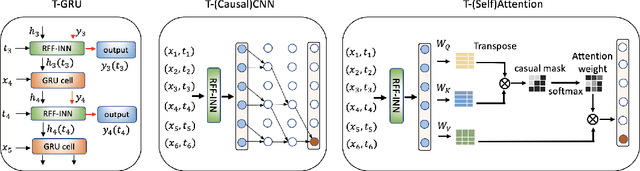
Sequential deep learning models such as RNN, causal CNN and attention mechanism do not readily consume continuous-time information. Discretizing the temporal data, as we show, causes inconsistency even for simple continuous-time processes. Current approaches often handle time in a heuristic manner to be consistent with the existing deep learning architectures and implementations. In this paper, we provide a principled way to characterize continuous-time systems using deep learning tools. Notably, the proposed approach applies to all the major deep learning architectures and requires little modifications to the implementation. The critical insight is to represent the continuous-time system by composing neural networks with a temporal kernel, where we gain our intuition from the recent advancements in understanding deep learning with Gaussian process and neural tangent kernel. To represent the temporal kernel, we introduce the random feature approach and convert the kernel learning problem to spectral density estimation under reparameterization. We further prove the convergence and consistency results even when the temporal kernel is non-stationary, and the spectral density is misspecified. The simulations and real-data experiments demonstrate the empirical effectiveness of our temporal kernel approach in a broad range of settings.
Understanding the role of importance weighting for deep learning
Mar 28, 2021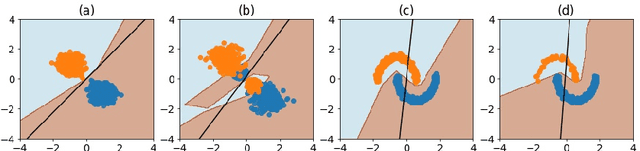
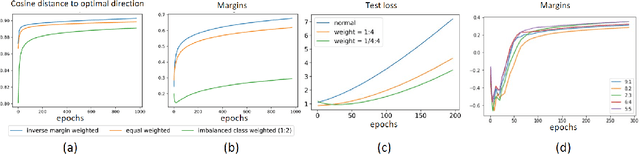
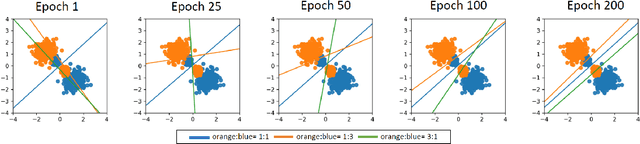
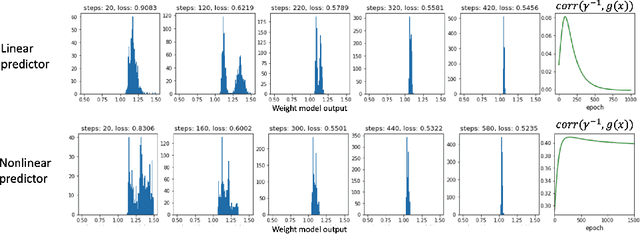
The recent paper by Byrd & Lipton (2019), based on empirical observations, raises a major concern on the impact of importance weighting for the over-parameterized deep learning models. They observe that as long as the model can separate the training data, the impact of importance weighting diminishes as the training proceeds. Nevertheless, there lacks a rigorous characterization of this phenomenon. In this paper, we provide formal characterizations and theoretical justifications on the role of importance weighting with respect to the implicit bias of gradient descent and margin-based learning theory. We reveal both the optimization dynamics and generalization performance under deep learning models. Our work not only explains the various novel phenomenons observed for importance weighting in deep learning, but also extends to the studies where the weights are being optimized as part of the model, which applies to a number of topics under active research.
Theoretical Understandings of Product Embedding for E-commerce Machine Learning
Feb 24, 2021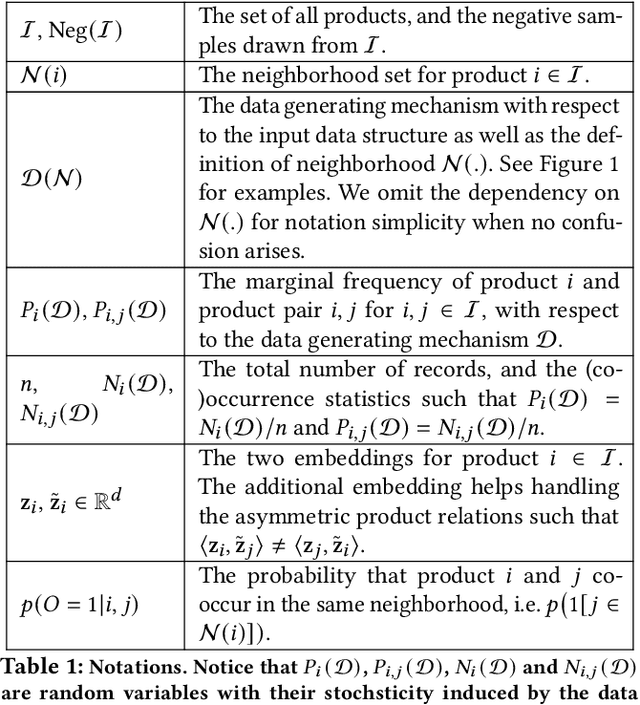
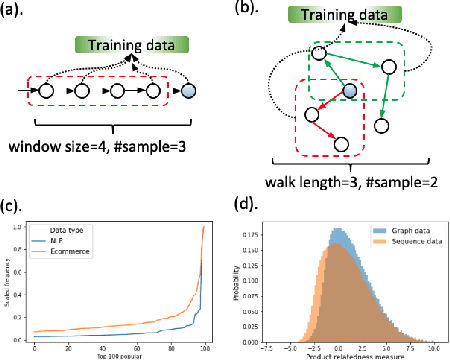
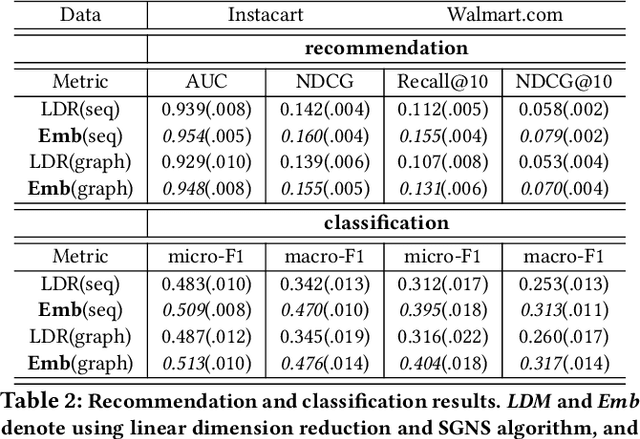
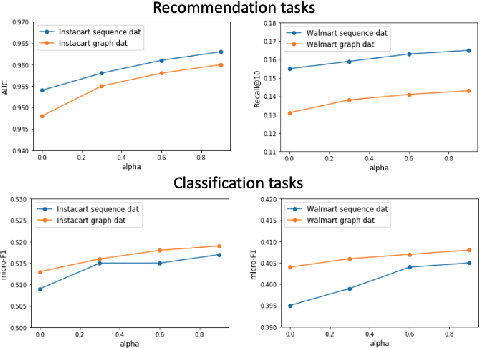
Product embeddings have been heavily investigated in the past few years, serving as the cornerstone for a broad range of machine learning applications in e-commerce. Despite the empirical success of product embeddings, little is known on how and why they work from the theoretical standpoint. Analogous results from the natural language processing (NLP) often rely on domain-specific properties that are not transferable to the e-commerce setting, and the downstream tasks often focus on different aspects of the embeddings. We take an e-commerce-oriented view of the product embeddings and reveal a complete theoretical view from both the representation learning and the learning theory perspective. We prove that product embeddings trained by the widely-adopted skip-gram negative sampling algorithm and its variants are sufficient dimension reduction regarding a critical product relatedness measure. The generalization performance in the downstream machine learning task is controlled by the alignment between the embeddings and the product relatedness measure. Following the theoretical discoveries, we conduct exploratory experiments that supports our theoretical insights for the product embeddings.
Sparse Symmetric Tensor Regression for Functional Connectivity Analysis
Oct 28, 2020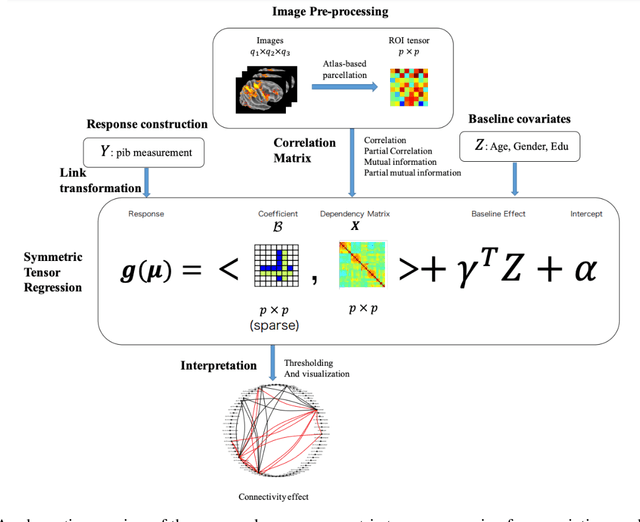
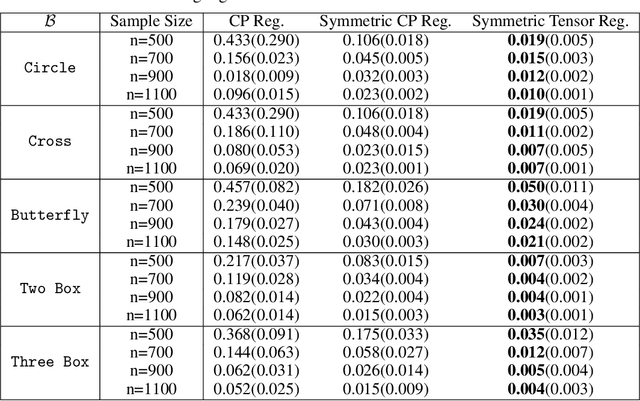

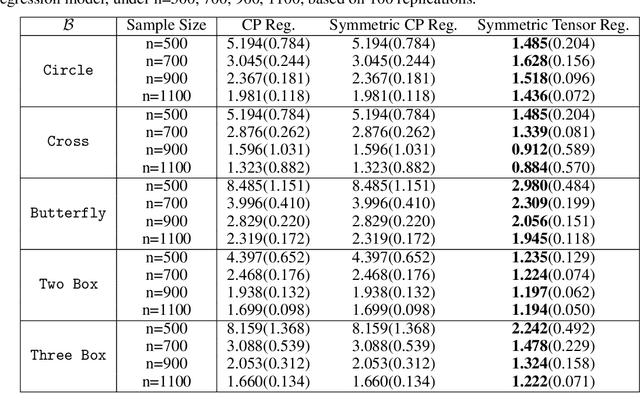
Tensor regression models, such as CP regression and Tucker regression, have many successful applications in neuroimaging analysis where the covariates are of ultrahigh dimensionality and possess complex spatial structures. The high-dimensional covariate arrays, also known as tensors, can be approximated by low-rank structures and fit into the generalized linear models. The resulting tensor regression achieves a significant reduction in dimensionality while remaining efficient in estimation and prediction. Brain functional connectivity is an essential measure of brain activity and has shown significant association with neurological disorders such as Alzheimer's disease. The symmetry nature of functional connectivity is a property that has not been explored in previous tensor regression models. In this work, we propose a sparse symmetric tensor regression that further reduces the number of free parameters and achieves superior performance over symmetrized and ordinary CP regression, under a variety of simulation settings. We apply the proposed method to a study of Alzheimer's disease (AD) and normal ageing from the Berkeley Aging Cohort Study (BACS) and detect two regions of interest that have been identified important to AD.
Inductive Representation Learning on Temporal Graphs
Feb 19, 2020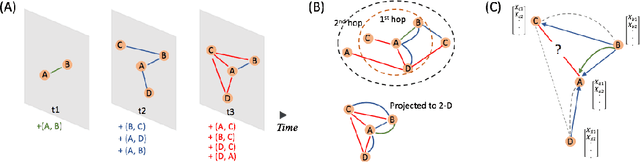
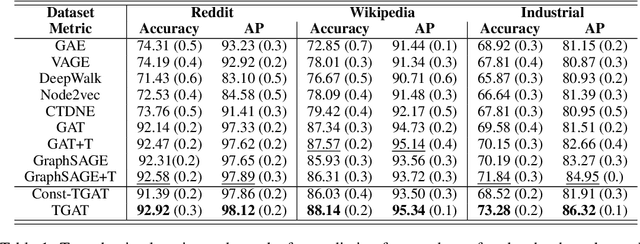
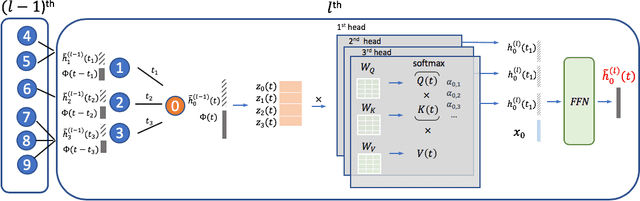
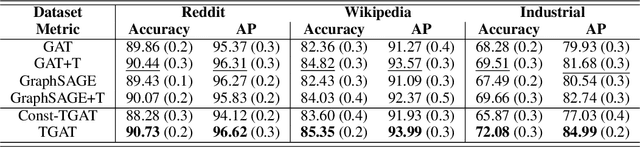
Inductive representation learning on temporal graphs is an important step toward salable machine learning on real-world dynamic networks. The evolving nature of temporal dynamic graphs requires handling new nodes as well as capturing temporal patterns. The node embeddings, which are now functions of time, should represent both the static node features and the evolving topological structures. Moreover, node and topological features can be temporal as well, whose patterns the node embeddings should also capture. We propose the temporal graph attention (TGAT) layer to efficiently aggregate temporal-topological neighborhood features as well as to learn the time-feature interactions. For TGAT, we use the self-attention mechanism as building block and develop a novel functional time encoding technique based on the classical Bochner's theorem from harmonic analysis. By stacking TGAT layers, the network recognizes the node embeddings as functions of time and is able to inductively infer embeddings for both new and observed nodes as the graph evolves. The proposed approach handles both node classification and link prediction task, and can be naturally extended to include the temporal edge features. We evaluate our method with transductive and inductive tasks under temporal settings with two benchmark and one industrial dataset. Our TGAT model compares favorably to state-of-the-art baselines as well as the previous temporal graph embedding approaches.
Self-attention with Functional Time Representation Learning
Nov 28, 2019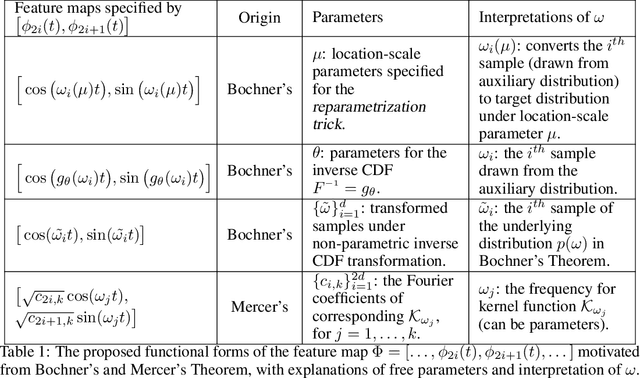
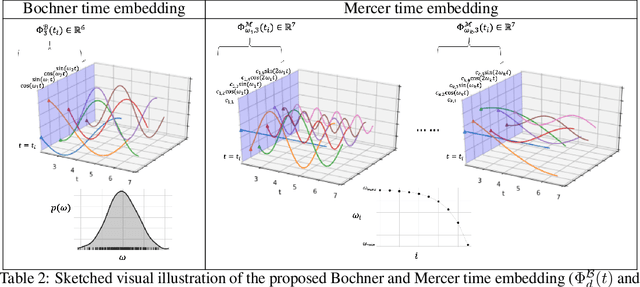
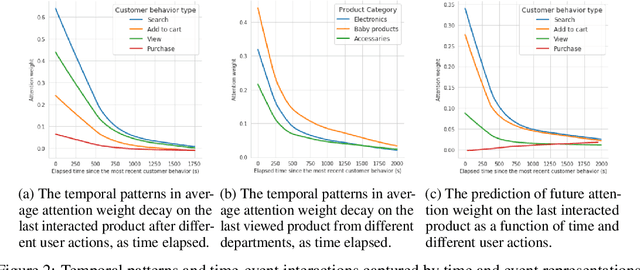
Sequential modelling with self-attention has achieved cutting edge performances in natural language processing. With advantages in model flexibility, computation complexity and interpretability, self-attention is gradually becoming a key component in event sequence models. However, like most other sequence models, self-attention does not account for the time span between events and thus captures sequential signals rather than temporal patterns. Without relying on recurrent network structures, self-attention recognizes event orderings via positional encoding. To bridge the gap between modelling time-independent and time-dependent event sequence, we introduce a functional feature map that embeds time span into high-dimensional spaces. By constructing the associated translation-invariant time kernel function, we reveal the functional forms of the feature map under classic functional function analysis results, namely Bochner's Theorem and Mercer's Theorem. We propose several models to learn the functional time representation and the interactions with event representation. These methods are evaluated on real-world datasets under various continuous-time event sequence prediction tasks. The experiments reveal that the proposed methods compare favorably to baseline models while also capturing useful time-event interactions.
Product Knowledge Graph Embedding for E-commerce
Nov 28, 2019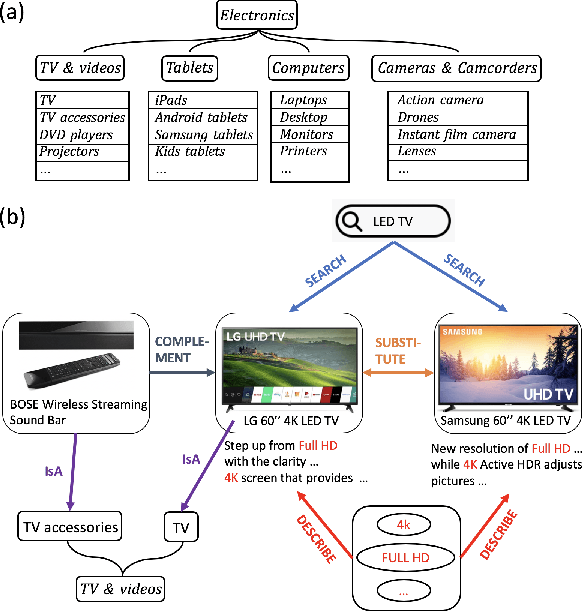
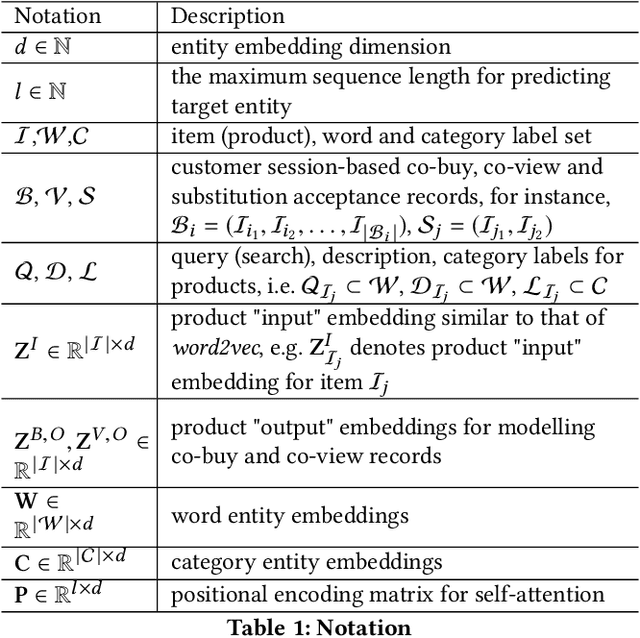
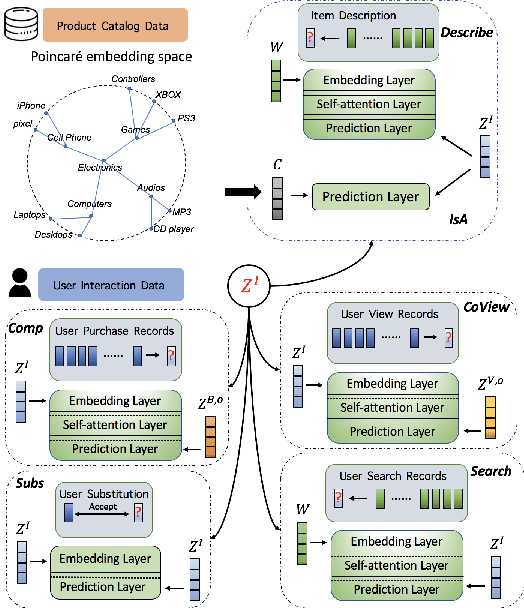

In this paper, we propose a new product knowledge graph (PKG) embedding approach for learning the intrinsic product relations as product knowledge for e-commerce. We define the key entities and summarize the pivotal product relations that are critical for general e-commerce applications including marketing, advertisement, search ranking and recommendation. We first provide a comprehensive comparison between PKG and ordinary knowledge graph (KG) and then illustrate why KG embedding methods are not suitable for PKG learning. We construct a self-attention-enhanced distributed representation learning model for learning PKG embeddings from raw customer activity data in an end-to-end fashion. We design an effective multi-task learning schema to fully leverage the multi-modal e-commerce data. The Poincare embedding is also employed to handle complex entity structures. We use a real-world dataset from grocery.walmart.com to evaluate the performances on knowledge completion, search ranking and recommendation. The proposed approach compares favourably to baselines in knowledge completion and downstream tasks.