 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Distance-distributions Separation for Unsupervised Person Re-identification
Jun 01, 2020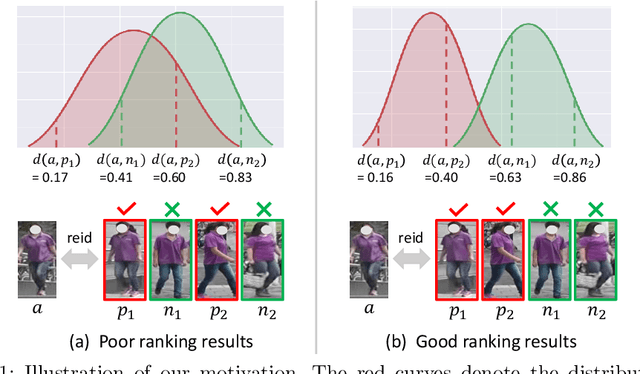
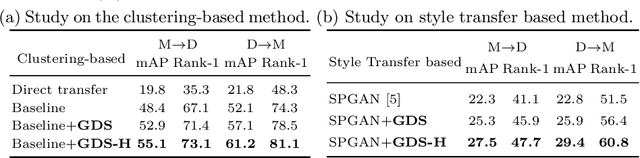
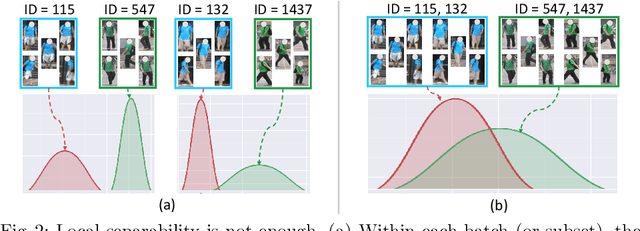
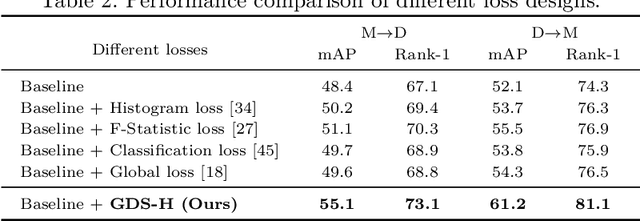
Supervised person re-identification (ReID) often has poor scalability and usability in real-world deployments due to domain gaps and the lack of annotations for the target domain data. Unsupervised person ReID through domain adaptation is attractive yet challenging. Existing unsupervised ReID approaches often fail in correctly identifying the positive samples and negative samples through the distance-based matching/ranking. The two distributions of distances for positive sample pairs (Pos-distr) and negative sample pairs (Neg-distr) are often not well separated, having large overlap. To address this problem, we introduce a global distance-distributions separation (GDS) constraint over the two distributions to encourage the clear separation of positive and negative samples from a global view. We model the two global distance distributions as Gaussian distributions and push apart the two distributions while encouraging their sharpness in the unsupervised training process. Particularly, to model the distributions from a global view and facilitate the timely updating of the distributions and the GDS related losses, we leverage a momentum update mechanism for building and maintaining the distribution parameters (mean and variance) and calculate the loss on the fly during the training. Distribution-based hard mining is proposed to further promote the separation of the two distributions. We validate the effectiveness of the GDS constraint in unsupervised ReID networks. Extensive experiments on multiple ReID benchmark datasets show our method leads to significant improvement over the baselines and achieves the state-of-the-art performance.
Style Normalization and Restitution for Generalizable Person Re-identification
May 22, 2020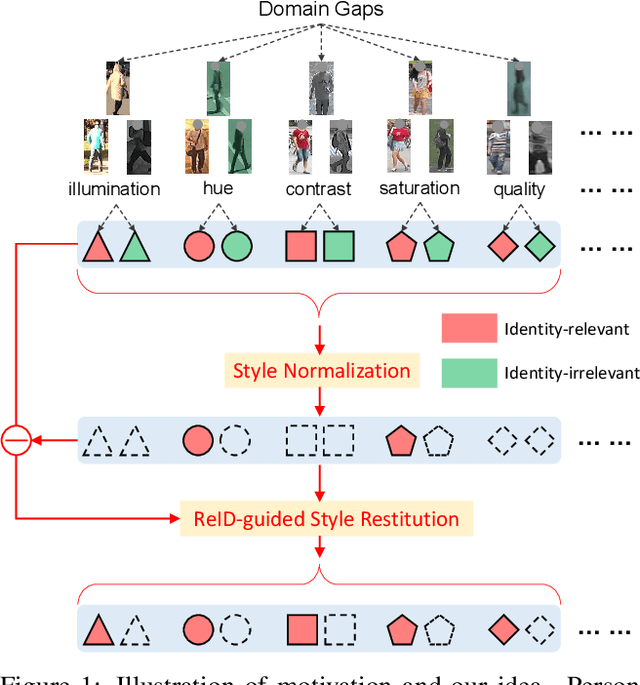
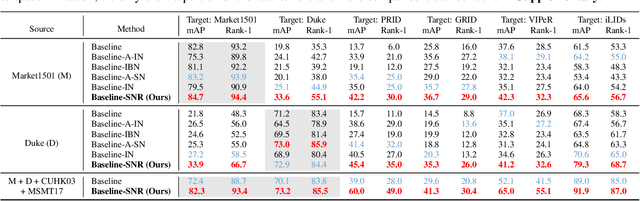
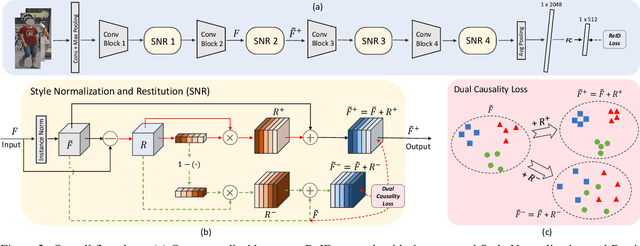
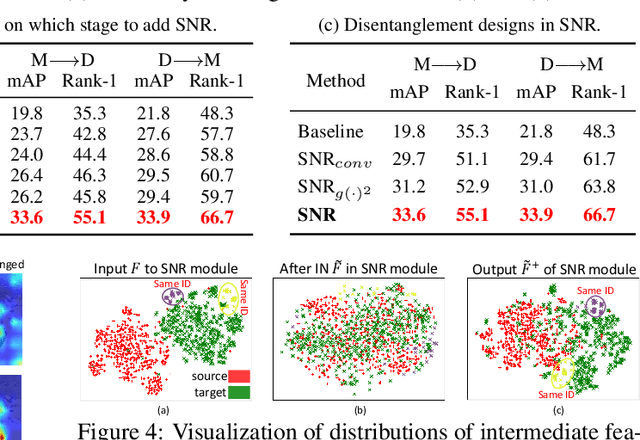
Existing fully-supervised person re-identification (ReID) methods usually suffer from poor generalization capability caused by domain gaps. The key to solving this problem lies in filtering out identity-irrelevant interference and learning domain-invariant person representations. In this paper, we aim to design a generalizable person ReID framework which trains a model on source domains yet is able to generalize/perform well on target domains. To achieve this goal, we propose a simple yet effective Style Normalization and Restitution (SNR) module. Specifically, we filter out style variations (e.g., illumination, color contrast) by Instance Normalization (IN). However, such a process inevitably removes discriminative information. We propose to distill identity-relevant feature from the removed information and restitute it to the network to ensure high discrimination. For better disentanglement, we enforce a dual causal loss constraint in SNR to encourage the separation of identity-relevant features and identity-irrelevant features. Extensive experiments demonstrate the strong generalization capability of our framework. Our models empowered by the SNR modules significantly outperform the state-of-the-art domain generalization approaches on multiple widely-used person ReID benchmarks, and also show superiority on unsupervised domain adaptation.
Multi-Granularity Reference-Aided Attentive Feature Aggregation for Video-based Person Re-identification
Mar 27, 2020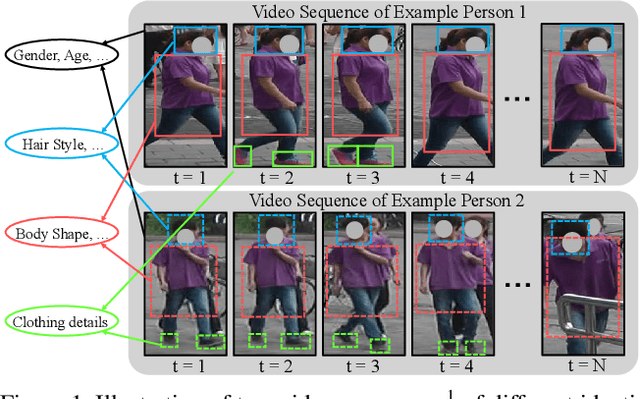
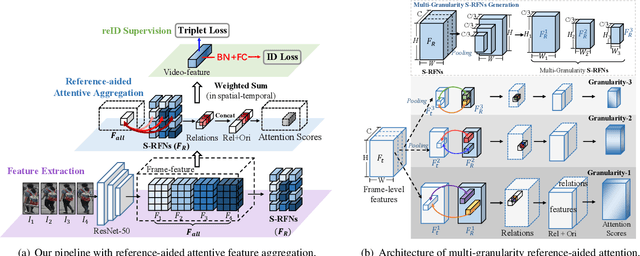

Video-based person re-identification (reID) aims at matching the same person across video clips. It is a challenging task due to the existence of redundancy among frames, newly revealed appearance, occlusion, and motion blurs. In this paper, we propose an attentive feature aggregation module, namely Multi-Granularity Reference-aided Attentive Feature Aggregation (MG-RAFA), to delicately aggregate spatio-temporal features into a discriminative video-level feature representation. In order to determine the contribution/importance of a spatial-temporal feature node, we propose to learn the attention from a global view with convolutional operations. Specifically, we stack its relations, i.e., pairwise correlations with respect to a representative set of reference feature nodes (S-RFNs) that represents global video information, together with the feature itself to infer the attention. Moreover, to exploit the semantics of different levels, we propose to learn multi-granularity attentions based on the relations captured at different granularities. Extensive ablation studies demonstrate the effectiveness of our attentive feature aggregation module MG-RAFA. Our framework achieves the state-of-the-art performance on three benchmark datasets.
STC-Flow: Spatio-temporal Context-aware Optical Flow Estimation
Mar 01, 2020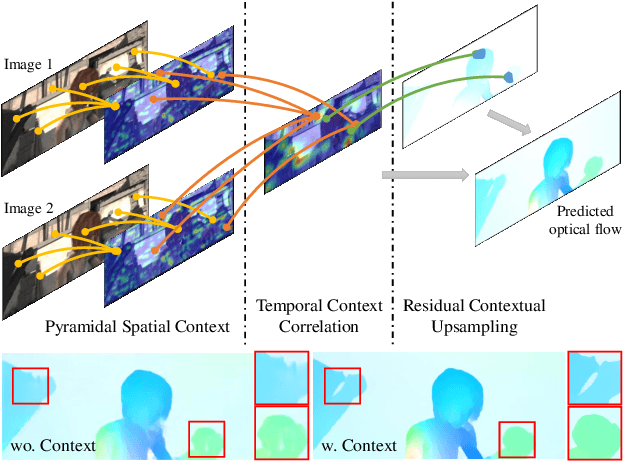

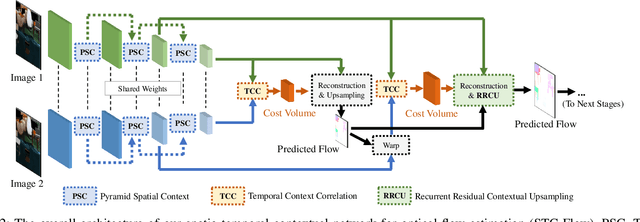
In this paper, we propose a spatio-temporal contextual network, STC-Flow, for optical flow estimation. Unlike previous optical flow estimation approaches with local pyramid feature extraction and multi-level correlation, we propose a contextual relation exploration architecture by capturing rich long-range dependencies in spatial and temporal dimensions. Specifically, STC-Flow contains three key context modules - pyramidal spatial context module, temporal context correlation module and recurrent residual contextual upsampling module, to build the relationship in each stage of feature extraction, correlation, and flow reconstruction, respectively. Experimental results indicate that the proposed scheme achieves the state-of-the-art performance of two-frame based methods on the Sintel dataset and the KITTI 2012/2015 datasets.
Uncertainty-Aware Multi-Shot Knowledge Distillation for Image-Based Object Re-Identification
Jan 21, 2020



Object re-identification (re-id) aims to identify a specific object across times or camera views, with the person re-id and vehicle re-id as the most widely studied applications. Re-id is challenging because of the variations in viewpoints, (human) poses, and occlusions. Multi-shots of the same object can cover diverse viewpoints/poses and thus provide more comprehensive information. In this paper, we propose exploiting the multi-shots of the same identity to guide the feature learning of each individual image. Specifically, we design an Uncertainty-aware Multi-shot Teacher-Student (UMTS) Network. It consists of a teacher network (T-net) that learns the comprehensive features from multiple images of the same object, and a student network (S-net) that takes a single image as input. In particular, we take into account the data dependent heteroscedastic uncertainty for effectively transferring the knowledge from the T-net to S-net. To the best of our knowledge, we are the first to make use of multi-shots of an object in a teacher-student learning manner for effectively boosting the single image based re-id. We validate the effectiveness of our approach on the popular vehicle re-id and person re-id datasets. In inference, the S-net alone significantly outperforms the baselines and achieves the state-of-the-art performance.
FPCR-Net: Feature Pyramidal Correlation and Residual Reconstruction for Semi-supervised Optical Flow Estimation
Jan 17, 2020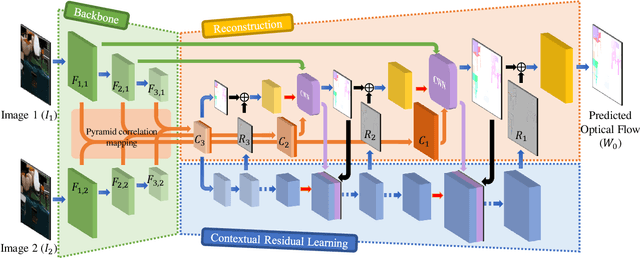
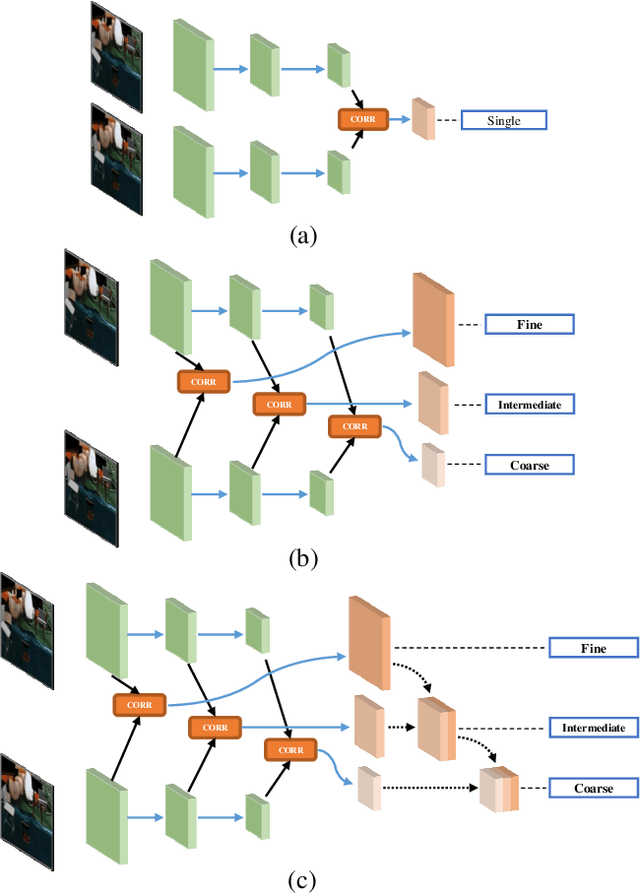
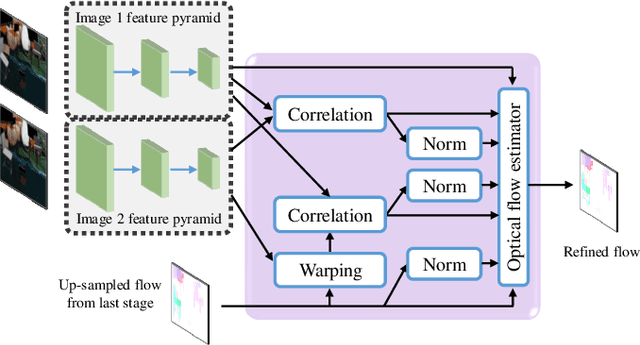
Optical flow estimation is an important yet challenging problem in the field of video analytics. The features of different semantics levels/layers of a convolutional neural network can provide information of different granularity. To exploit such flexible and comprehensive information, we propose a semi-supervised Feature Pyramidal Correlation and Residual Reconstruction Network (FPCR-Net) for optical flow estimation from frame pairs. It consists of two main modules: pyramid correlation mapping and residual reconstruction. The pyramid correlation mapping module takes advantage of the multi-scale correlations of global/local patches by aggregating features of different scales to form a multi-level cost volume. The residual reconstruction module aims to reconstruct the sub-band high-frequency residuals of finer optical flow in each stage. Based on the pyramid correlation mapping, we further propose a correlation-warping-normalization (CWN) module to efficiently exploit the correlation dependency. Experiment results show that the proposed scheme achieves the state-of-the-art performance, with improvement by 0.80, 1.15 and 0.10 in terms of average end-point error (AEE) against competing baseline methods - FlowNet2, LiteFlowNet and PWC-Net on the Final pass of Sintel dataset, respectively.
EleAtt-RNN: Adding Attentiveness to Neurons in Recurrent Neural Networks
Sep 03, 2019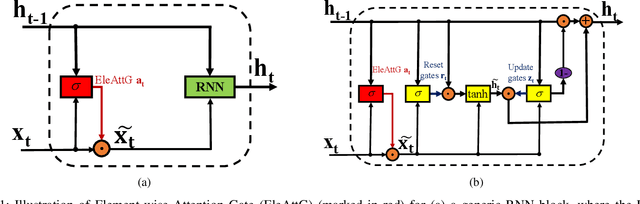
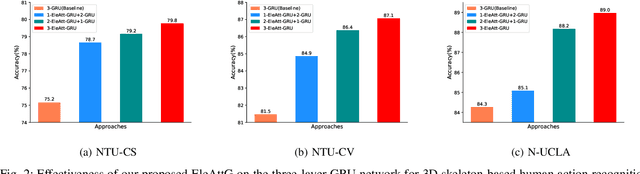


Recurrent neural networks (RNNs) are capable of modeling temporal dependencies of complex sequential data. In general, current available structures of RNNs tend to concentrate on controlling the contributions of current and previous information. However, the exploration of different importance levels of different elements within an input vector is always ignored. We propose a simple yet effective Element-wise-Attention Gate (EleAttG), which can be easily added to an RNN block (e.g. all RNN neurons in an RNN layer), to empower the RNN neurons to have attentiveness capability. For an RNN block, an EleAttG is used for adaptively modulating the input by assigning different levels of importance, i.e., attention, to each element/dimension of the input. We refer to an RNN block equipped with an EleAttG as an EleAtt-RNN block. Instead of modulating the input as a whole, the EleAttG modulates the input at fine granularity, i.e., element-wise, and the modulation is content adaptive. The proposed EleAttG, as an additional fundamental unit, is general and can be applied to any RNN structures, e.g., standard RNN, Long Short-Term Memory (LSTM), or Gated Recurrent Unit (GRU). We demonstrate the effectiveness of the proposed EleAtt-RNN by applying it to different tasks including the action recognition, from both skeleton-based data and RGB videos, gesture recognition, and sequential MNIST classification. Experiments show that adding attentiveness through EleAttGs to RNN blocks significantly improves the power of RNNs.
Semantics-Aligned Representation Learning for Person Re-identification
May 30, 2019
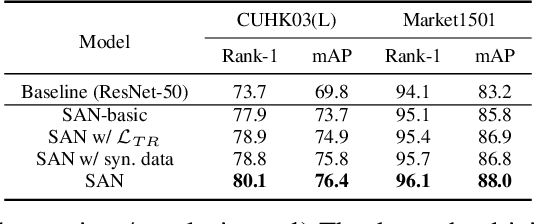
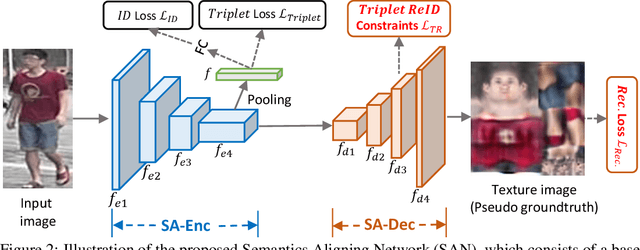
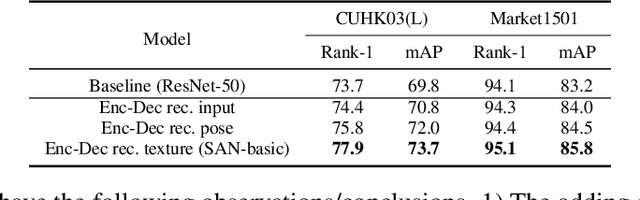
Person re-identification (reID) aims to match person images to retrieve the ones with the same identity. This is a challenging task, as the images to be matched are generally semantically misaligned due to the diversity of human poses and capture viewpoints, incompleteness of the visible bodies (due to occlusion), etc. In this paper, we propose a framework that drives the reID network to learn semantics-aligned feature representation through delicate supervision designs. Specifically, we build a Semantics Aligning Network (SAN) which consists of a base network as encoder (SA-Enc) for re-ID, and a decoder (SA-Dec) for reconstructing/regressing the densely semantics aligned full texture image. We jointly train the SAN under the supervisions of person re-identification and aligned texture generation. Moreover, at the decoder, besides the reconstruction loss, we add triplet reID constraints/losses over the feature maps as the perceptual losses. The decoder is discarded in the inference/test and thus our scheme is computationally efficient. Ablation studies demonstrate the effectiveness of our design. We achieve the state-of-the-art performances on the benchmark datasets CUHK03, Market1501, MSMT17, and the partial person reID dataset Partial REID.
CaseNet: Content-Adaptive Scale Interaction Networks for Scene Parsing
Apr 17, 2019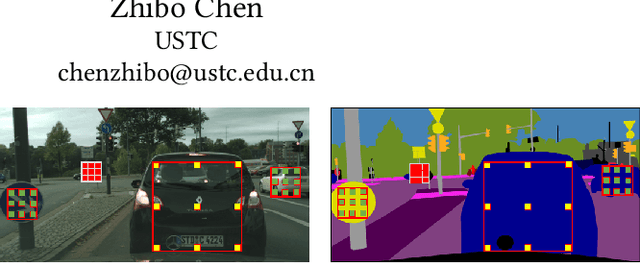
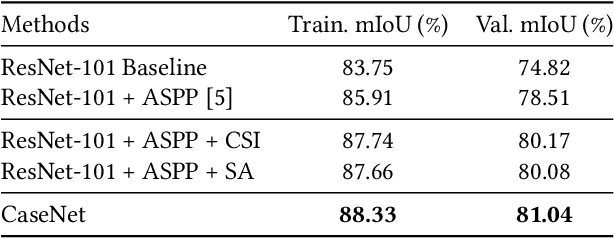
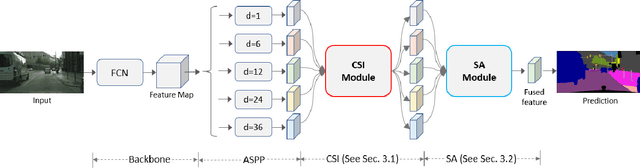

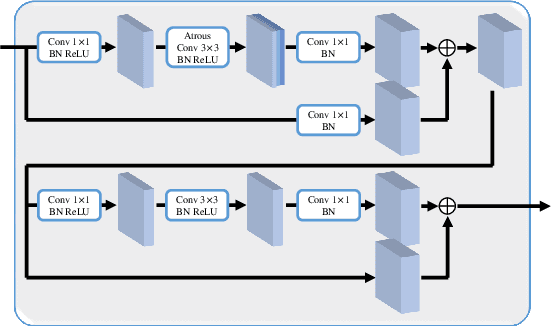
Objects in an image exhibit diverse scales. Adaptive receptive fields are expected to catch suitable range of context for accurate pixel level semantic prediction for handling objects of diverse sizes. Recently, atrous convolution with different dilation rates has been used to generate features of multi-scales through several branches and these features are fused for prediction. However, there is a lack of explicit interaction among the branches to adaptively make full use of the contexts. In this paper, we propose a Content-Adaptive Scale Interaction Network (CaseNet) to exploit the multi-scale features for scene parsing. We build the CaseNet based on the classic Atrous Spatial Pyramid Pooling (ASPP) module, followed by the proposed contextual scale interaction (CSI) module, and the scale adaptation (SA) module. Specifically, first, for each spatial position, we enable context interaction among different scales through scale-aware non-local operations across the scales, \ie, CSI module, which facilitates the generation of flexible mixed receptive fields, instead of a traditional flat one. Second, the scale adaptation module (SA) explicitly and softly selects the suitable scale for each spatial position and each channel. Ablation studies demonstrate the effectiveness of the proposed modules. We achieve state-of-the-art performance on three scene parsing benchmarks Cityscapes, ADE20K and LIP.
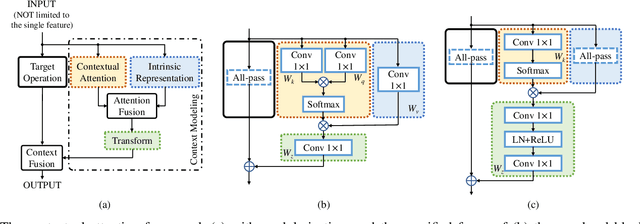
Relation-Aware Global Attention
Apr 05, 2019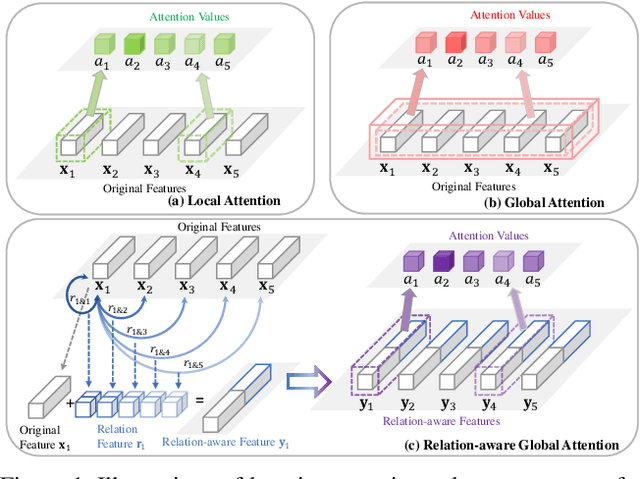
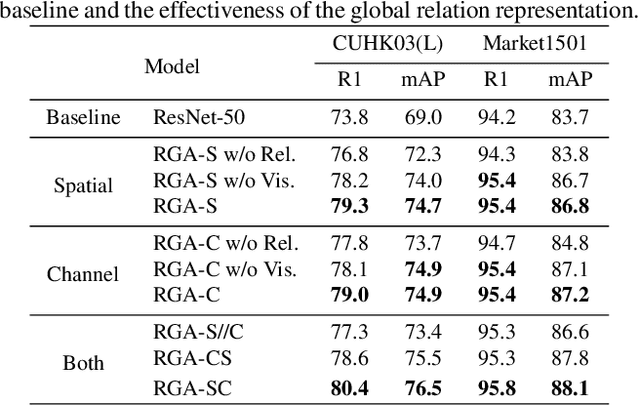
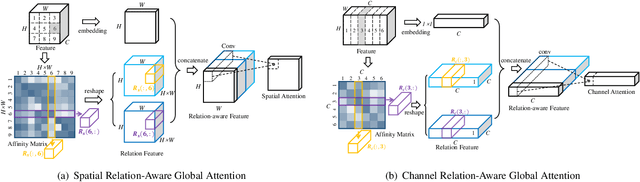
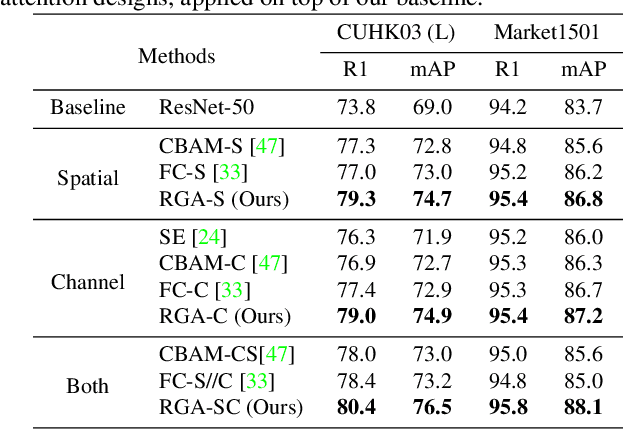
Attention mechanism aims to increase the representation power by focusing on important features and suppressing unnecessary ones. For convolutional neural networks (CNNs), attention is typically learned with local convolutions, which ignores the global information and the hidden relation. How to efficiently exploit the long-range context to globally learn attention is underexplored. In this paper, we propose an effective Relation-Aware Global Attention (RGA) module for CNNs to fully exploit the global correlations to infer the attention. Specifically, when computing the attention at a feature position, in order to grasp information of global scope, we propose to stack the relations, i.e., its pairwise correlations/affinities with all the feature positions, and the feature itself together for learning the attention with convolutional operations. Given an intermediate feature map, we have validated the effectiveness of this design across both the spatial and channel dimensions. When applied to the task of person re-identification, our model achieves the state-of-the-art performance. Extensive ablation studies demonstrate that our RGA can significantly enhance the feature representation power. We further demonstrate the general applicability of RGA to vision tasks by applying it to the scene segmentation and image classification tasks resulting in consistent performance improvement.