 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free Linear Quadratic Control via Reduction to Expert Prediction
Oct 05, 2018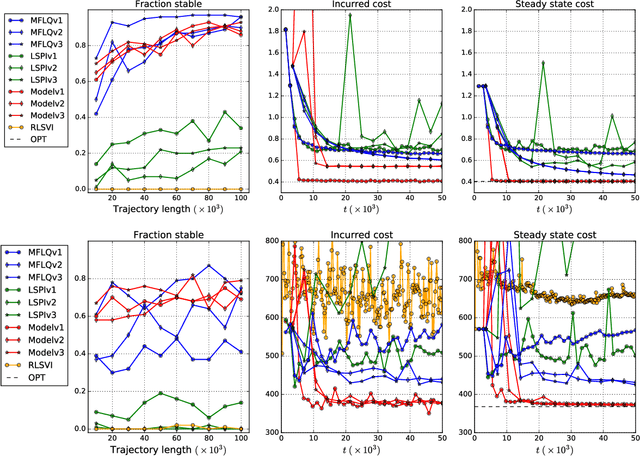
Model-free approaches for reinforcement learning (RL) and continuous control find policies based only on past states and rewards, without fitting a model of the system dynamics. They are appealing as they are general purpose and easy to implement; however, they also come with fewer theoretical guarantees than model-based RL. In this work, we present a new model-free algorithm for controlling linear quadratic (LQ) systems, and show that its regret scales as $O(T^{\xi+2/3})$ for any small $\xi>0$ if time horizon satisfies $T>C^{1/\xi}$ for a constant $C$. The algorithm is based on a reduction of control of Markov decision processes to an expert prediction problem. In practice, it corresponds to a variant of policy iteration with forced exploration, where the policy in each phase is greedy with respect to the average of all previous value functions. This is the first model-free algorithm for adaptive control of LQ systems that provably achieves sublinear regret and has a polynomial computation cost. Empirically, our algorithm dramatically outperforms standard policy iteration, but performs worse than a model-based approach.
PAC-Bayes bounds for stable algorithms with instance-dependent priors
Aug 30, 2018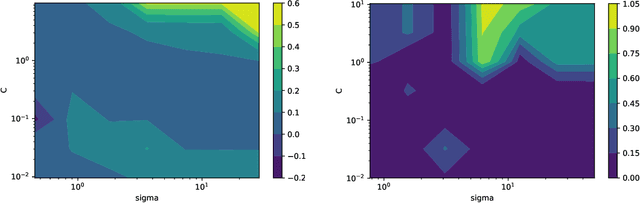
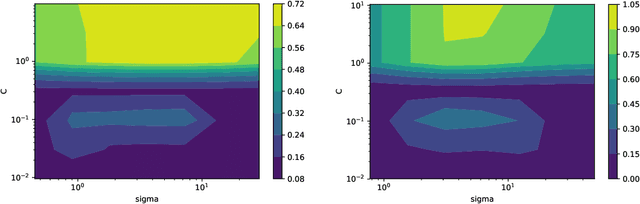
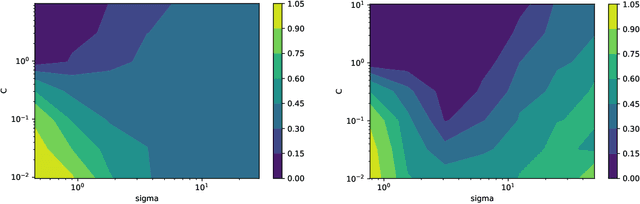

PAC-Bayes bounds have been proposed to get risk estimates based on a training sample. In this paper the PAC-Bayes approach is combined with stability of the hypothesis learned by a Hilbert space valued algorithm. The PAC-Bayes setting is used with a Gaussian prior centered at the expected output. Thus a novelty of our paper is using priors defined in terms of the data-generating distribution. Our main result estimates the risk of the randomized algorithm in terms of the hypothesis stability coefficients. We also provide a new bound for the SVM classifier, which is compared to other known bounds experimentally. Ours appears to be the first stability-based bound that evaluates to non-trivial values.
BubbleRank: Safe Online Learning to Rerank
Jun 15, 2018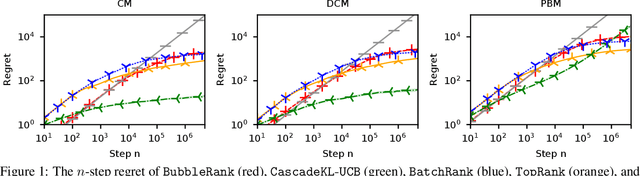
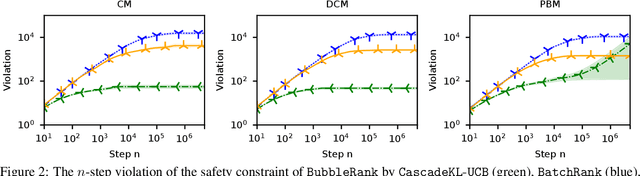
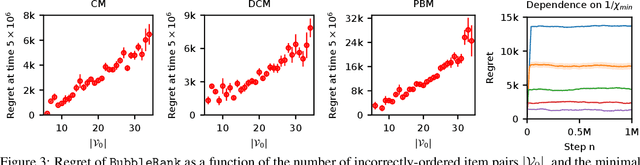
We study the problem of online learning to re-rank, where users provide feedback to improve the quality of displayed lists. Learning to rank has been traditionally studied in two settings. In the offline setting, rankers are typically learned from relevance labels of judges. These approaches have become the industry standard. However, they lack exploration, and thus are limited by the information content of offline data. In the online setting, an algorithm can propose a list and learn from the feedback on it in a sequential fashion. Bandit algorithms developed for this setting actively experiment, and in this way overcome the biases of offline data. But they also tend to ignore offline data, which results in a high initial cost of exploration. We propose BubbleRank, a bandit algorithm for re-ranking that combines the strengths of both settings. The algorithm starts with an initial base list and improves it gradually by swapping higher-ranked less attractive items for lower-ranked more attractive items. We prove an upper bound on the n-step regret of BubbleRank that degrades gracefully with the quality of the initial base list. Our theoretical findings are supported by extensive numerical experiments on a large real-world click dataset.
Bandits with Delayed, Aggregated Anonymous Feedback
Jun 13, 2018
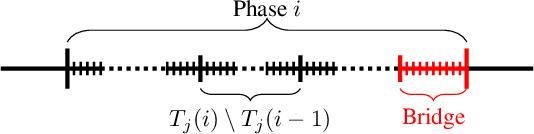
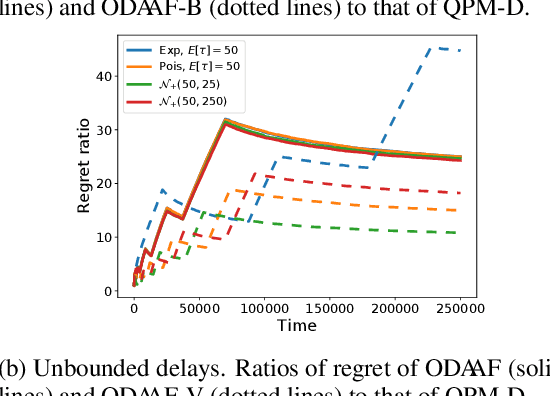
We study a variant of the stochastic $K$-armed bandit problem, which we call "bandits with delayed, aggregated anonymous feedback". In this problem, when the player pulls an arm, a reward is generated, however it is not immediately observed. Instead, at the end of each round the player observes only the sum of a number of previously generated rewards which happen to arrive in the given round. The rewards are stochastically delayed and due to the aggregated nature of the observations, the information of which arm led to a particular reward is lost. The question is what is the cost of the information loss due to this delayed, aggregated anonymous feedback? Previous works have studied bandits with stochastic, non-anonymous delays and found that the regret increases only by an additive factor relating to the expected delay. In this paper, we show that this additive regret increase can be maintained in the harder delayed, aggregated anonymous feedback setting when the expected delay (or a bound on it) is known. We provide an algorithm that matches the worst case regret of the non-anonymous problem exactly when the delays are bounded, and up to logarithmic factors or an additive variance term for unbounded delays.
TopRank: A practical algorithm for online stochastic ranking
Jun 06, 2018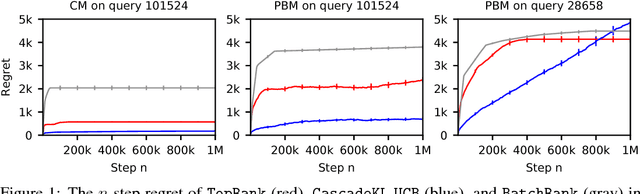
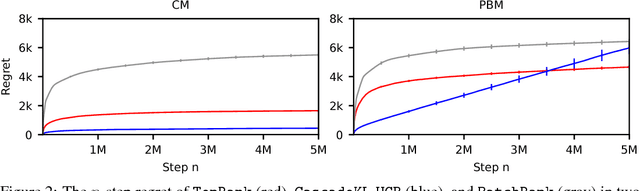
Online learning to rank is a sequential decision-making problem where in each round the learning agent chooses a list of items and receives feedback in the form of clicks from the user. Many sample-efficient algorithms have been proposed for this problem that assume a specific click model connecting rankings and user behavior. We propose a generalized click model that encompasses many existing models, including the position-based and cascade models. Our generalization motivates a novel online learning algorithm based on topological sort, which we call TopRank. TopRank is (a) more natural than existing algorithms, (b) has stronger regret guarantees than existing algorithms with comparable generality, (c) has a more insightful proof that leaves the door open to many generalizations, (d) outperforms existing algorithms empirically.
Cleaning up the neighborhood: A full classification for adversarial partial monitoring
May 23, 2018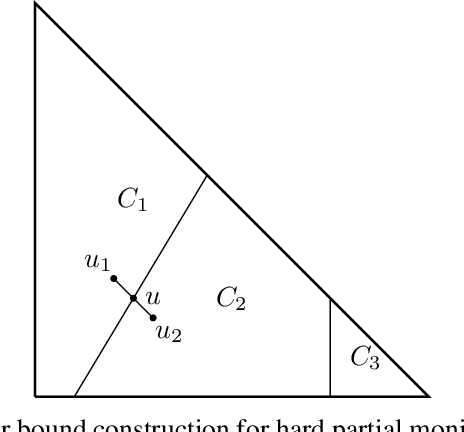
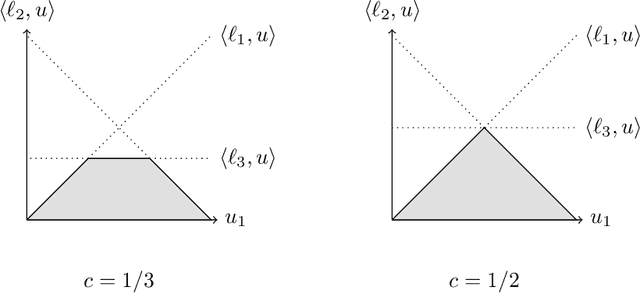
Partial monitoring is a generalization of the well-known multi-armed bandit framework where the loss is not directly observed by the learner. We complete the classification of finite adversarial partial monitoring to include all games, solving an open problem posed by Bartok et al. [2014]. Along the way we simplify and improve existing algorithms and correct errors in previous analyses. Our second contribution is a new algorithm for the class of games studied by Bartok [2013] where we prove upper and lower regret bounds that shed more light on the dependence of the regret on the game structure.
Stochastic Low-Rank Bandits
Dec 13, 2017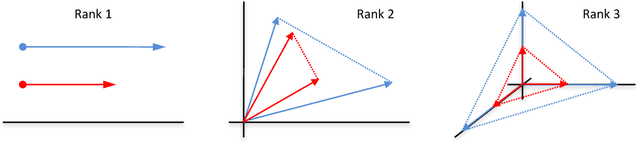
Many problems in computer vision and recommender systems involve low-rank matrices. In this work, we study the problem of finding the maximum entry of a stochastic low-rank matrix from sequential observations. At each step, a learning agent chooses pairs of row and column arms, and receives the noisy product of their latent values as a reward. The main challenge is that the latent values are unobserved. We identify a class of non-negative matrices whose maximum entry can be found statistically efficiently and propose an algorithm for finding them, which we call LowRankElim. We derive a $\DeclareMathOperator{\poly}{poly} O((K + L) \poly(d) \Delta^{-1} \log n)$ upper bound on its $n$-step regret, where $K$ is the number of rows, $L$ is the number of columns, $d$ is the rank of the matrix, and $\Delta$ is the minimum gap. The bound depends on other problem-specific constants that clearly do not depend $K L$. To the best of our knowledge, this is the first such result in the literature.
Crowdsourcing with Sparsely Interacting Workers
Jun 20, 2017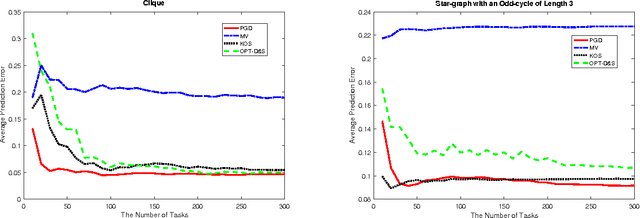



We consider estimation of worker skills from worker-task interaction data (with unknown labels) for the single-coin crowd-sourcing binary classification model in symmetric noise. We define the (worker) interaction graph whose nodes are workers and an edge between two nodes indicates whether or not the two workers participated in a common task. We show that skills are asymptotically identifiable if and only if an appropriate limiting version of the interaction graph is irreducible and has odd-cycles. We then formulate a weighted rank-one optimization problem to estimate skills based on observations on an irreducible, aperiodic interaction graph. We propose a gradient descent scheme and show that for such interaction graphs estimates converge asymptotically to the global minimum. We characterize noise robustness of the gradient scheme in terms of spectral properties of signless Laplacians of the interaction graph. We then demonstrate that a plug-in estimator based on the estimated skills achieves state-of-art performance on a number of real-world datasets. Our results have implications for rank-one matrix completion problem in that gradient descent can provably recover $W \times W$ rank-one matrices based on $W+1$ off-diagonal observations of a connected graph with a single odd-cycle.
Online Learning to Rank in Stochastic Click Models
Jun 20, 2017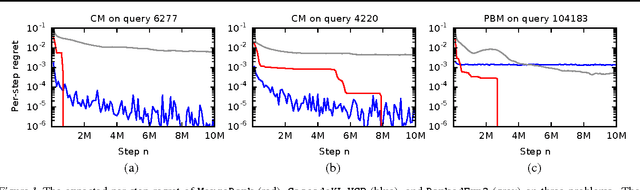
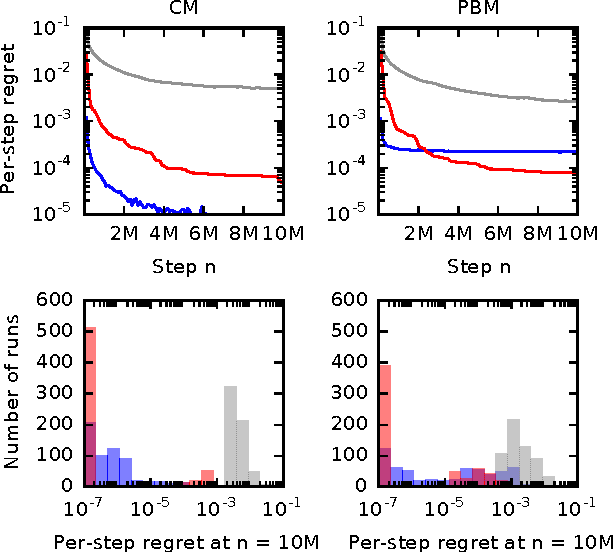
Online learning to rank is a core problem in information retrieval and machine learning. Many provably efficient algorithms have been recently proposed for this problem in specific click models. The click model is a model of how the user interacts with a list of documents. Though these results are significant, their impact on practice is limited, because all proposed algorithms are designed for specific click models and lack convergence guarantees in other models. In this work, we propose BatchRank, the first online learning to rank algorithm for a broad class of click models. The class encompasses two most fundamental click models, the cascade and position-based models. We derive a gap-dependent upper bound on the $T$-step regret of BatchRank and evaluate it on a range of web search queries. We observe that BatchRank outperforms ranked bandits and is more robust than CascadeKL-UCB, an existing algorithm for the cascade model.
An a Priori Exponential Tail Bound for k-Folds Cross-Validation
Jun 19, 2017We consider a priori generalization bounds developed in terms of cross-validation estimates and the stability of learners. In particular, we first derive an exponential Efron-Stein type tail inequality for the concentration of a general function of n independent random variables. Next, under some reasonable notion of stability, we use this exponential tail bound to analyze the concentration of the k-fold cross-validation (KFCV) estimate around the true risk of a hypothesis generated by a general learning rule. While the accumulated literature has often attributed this concentration to the bias and variance of the estimator, our bound attributes this concentration to the stability of the learning rule and the number of folds k. This insight raises valid concerns related to the practical use of KFCV and suggests research directions to obtain reliable empirical estimates of the actual risk.