 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration by Optimisation in Partial Monitoring
Jul 24, 2019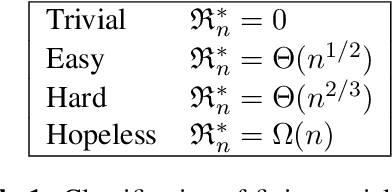

We provide a simple and efficient algorithm for adversarial $k$-action $d$-outcome non-degenerate locally observable partial monitoring game for which the $n$-round minimax regret is bounded by $6(d+1) k^{3/2} \sqrt{n \log(k)}$, matching the best known information-theoretic upper bound. The same algorithm also achieves near-optimal regret for full information, bandit and globally observable games.
Randomized Exploration in Generalized Linear Bandits
Jun 21, 2019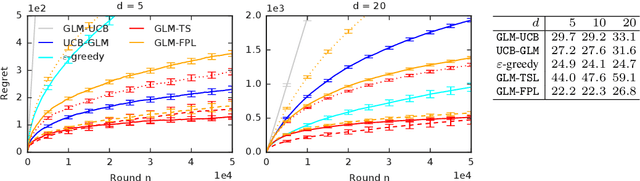
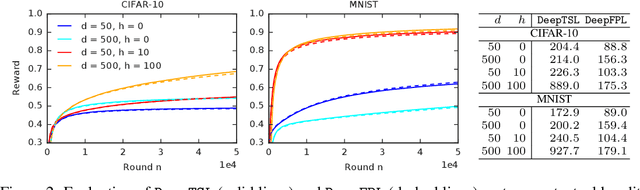
We study two randomized algorithms for generalized linear bandits, GLM-TSL and GLM-FPL. GLM-TSL samples a generalized linear model (GLM) from the Laplace approximation to the posterior distribution. GLM-FPL, a new algorithm proposed in this work, fits a GLM to a randomly perturbed history of past rewards. We prove a $\tilde{O}(d \sqrt{n} + d^2)$ upper bound on the $n$-round regret of GLM-TSL, where $d$ is the number of features. This is the first regret bound of a Thompson sampling-like algorithm in GLM bandits where the leading term is $\tilde{O}(d \sqrt{n})$. We apply both GLM-TSL and GLM-FPL to logistic and neural network bandits, and show that they perform well empirically. In more complex models, GLM-FPL is significantly faster. Our results showcase the role of randomization, beyond posterior sampling, in exploration.
Gradient Descent for Sparse Rank-One Matrix Completion for Crowd-Sourced Aggregation of Sparsely Interacting Workers
Apr 25, 2019


We consider worker skill estimation for the single-coin Dawid-Skene crowdsourcing model. In practice, skill-estimation is challenging because worker assignments are sparse and irregular due to the arbitrary and uncontrolled availability of workers. We formulate skill estimation as a rank-one correlation-matrix completion problem, where the observed components correspond to observed label correlations between workers. We show that the correlation matrix can be successfully recovered and skills are identifiable if and only if the sampling matrix (observed components) does not have a bipartite connected component. We then propose a projected gradient descent scheme and show that skill estimates converge to the desired global optima for such sampling matrices. Our proof is original and the results are surprising in light of the fact that even the weighted rank-one matrix factorization problem is NP-hard in general. Next, we derive sample complexity bounds in terms of spectral properties of the signless Laplacian of the sampling matrix. Our proposed scheme achieves state-of-art performance on a number of real-world datasets.
Empirical Bayes Regret Minimization
Apr 04, 2019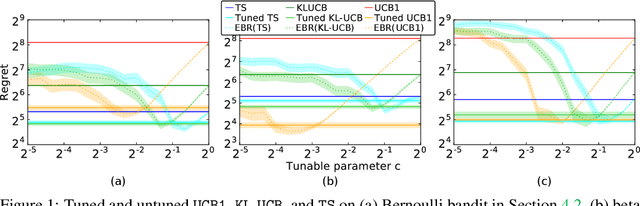

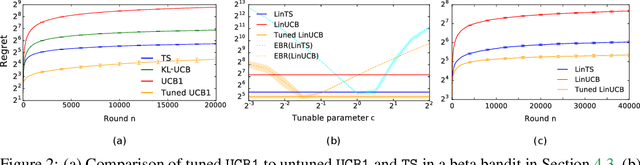
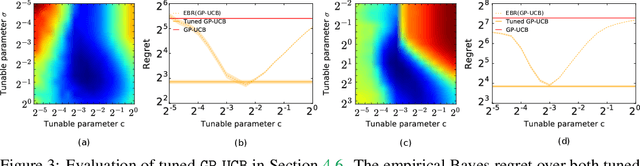
The prevalent approach to bandit algorithm design is to have a low-regret algorithm by design. While celebrated, this approach is often conservative because it ignores many intricate properties of actual problem instances. In this work, we pioneer the idea of minimizing an empirical approximation to the Bayes regret, the expected regret with respect to a distribution over problems. This approach can be viewed as an instance of learning-to-learn, it is conceptually straightforward, and easy to implement. We conduct a comprehensive empirical study of empirical Bayes regret minimization in a wide range of bandit problems, from Bernoulli bandits to structured problems, such as generalized linear and Gaussian process bandits. We report significant improvements over state-of-the-art bandit algorithms, often by an order of magnitude, by simply optimizing over a sample from the distribution.
Perturbed-History Exploration in Stochastic Linear Bandits
Mar 21, 2019
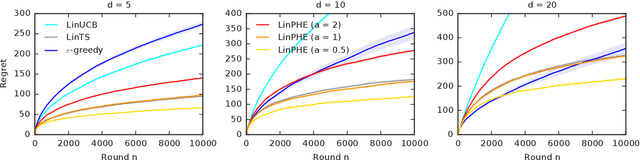
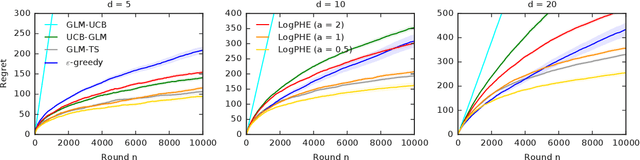
We propose a new online algorithm for minimizing the cumulative regret in stochastic linear bandits. The key idea is to build a perturbed history, which mixes the history of observed rewards with a pseudo-history of randomly generated i.i.d. pseudo-rewards. Our algorithm, perturbed-history exploration in a linear bandit (LinPHE), estimates a linear model from its perturbed history and pulls the arm with the highest value under that model. We prove a $\tilde{O}(d \sqrt{n})$ gap-free bound on the expected $n$-round regret of LinPHE, where $d$ is the number of features. Our analysis relies on novel concentration and anti-concentration bounds on the weighted sum of Bernoulli random variables. To show the generality of our design, we extend LinPHE to a logistic reward model. We evaluate both algorithms empirically and show that they are practical.
An Exponential Efron-Stein Inequality for Lq Stable Learning Rules
Mar 12, 2019There is accumulating evidence in the literature that stability of learning algorithms is a key characteristic that permits a learning algorithm to generalize. Despite various insightful results in this direction, there seems to be an overlooked dichotomy in the type of stability-based generalization bounds we have in the literature. On one hand, the literature seems to suggest that exponential generalization bounds for the estimated risk, which are optimal, can be only obtained through stringent, distribution independent and computationally intractable notions of stability such as uniform stability. On the other hand, it seems that weaker notions of stability such as hypothesis stability, although it is distribution dependent and more amenable to computation, can only yield polynomial generalization bounds for the estimated risk, which are suboptimal. In this paper, we address the gap between these two regimes of results. In particular, the main question we address here is whether it is possible to derive exponential generalization bounds for the estimated risk using a notion of stability that is computationally tractable and distribution dependent, but weaker than uniform stability. Using recent advances in concentration inequalities, and using a notion of stability that is weaker than uniform stability but distribution dependent and amenable to computation, we derive an exponential tail bound for the concentration of the estimated risk of a hypothesis returned by a general learning rule, where the estimated risk is expressed in terms of either the resubstitution estimate (empirical error), or the deleted (or, leave-one-out) estimate. As an illustration, we derive exponential tail bounds for ridge regression with unbounded responses -- a setting where uniform stability results of Bousquet and Elisseeff (2002) are not applicable.
* To appear in ALT 2019. arXiv admin note: text overlap with arXiv:1706.05801
Perturbed-History Exploration in Stochastic Multi-Armed Bandits
Feb 26, 2019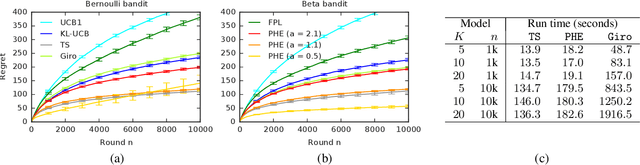
We propose an online algorithm for cumulative regret minimization in a stochastic multi-armed bandit. The algorithm adds $O(t)$ i.i.d. pseudo-rewards to its history in round $t$ and then pulls the arm with the highest estimated value in its perturbed history. Therefore, we call it perturbed-history exploration (PHE). The pseudo-rewards are designed to offset the underestimated values of arms in round $t$ with a sufficiently high probability. We analyze PHE in a $K$-armed bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ is the minimum gap between the expected rewards of the optimal and suboptimal arms. The key to our analysis is a novel argument that shows that randomized Bernoulli rewards lead to optimism. We compare PHE empirically to several baselines and show that it is competitive with the best of them.
An Information-Theoretic Approach to Minimax Regret in Partial Monitoring
Feb 01, 2019
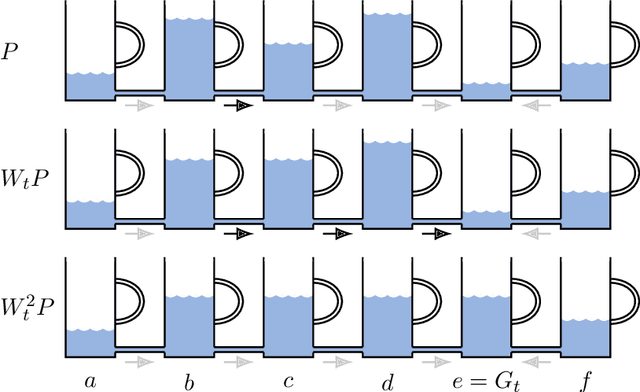

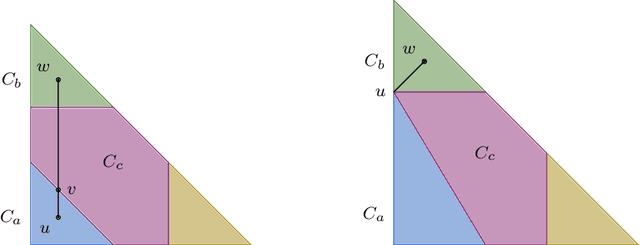
We prove a new minimax theorem connecting the worst-case Bayesian regret and minimax regret under partial monitoring with no assumptions on the space of signals or decisions of the adversary. We then generalise the information-theoretic tools of Russo and Van Roy (2016) for proving Bayesian regret bounds and combine them with the minimax theorem to derive minimax regret bounds for various partial monitoring settings. The highlight is a clean analysis of `non-degenerate easy' and `hard' finite partial monitoring, with new regret bounds that are independent of arbitrarily large game-dependent constants. The power of the generalised machinery is further demonstrated by proving that the minimax regret for k-armed adversarial bandits is at most sqrt{2kn}, improving on existing results by a factor of 2. Finally, we provide a simple analysis of the cops and robbers game, also improving best known constants.
Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures
Dec 04, 2018
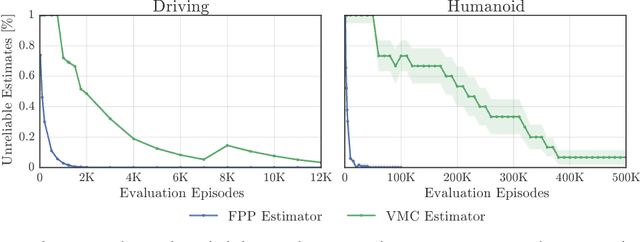
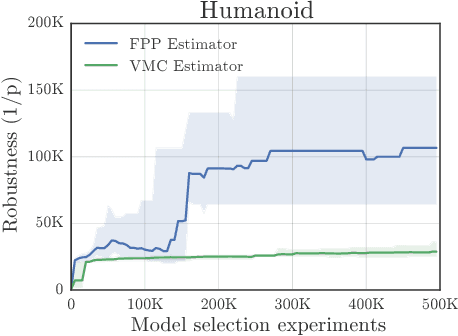

This paper addresses the problem of evaluating learning systems in safety critical domains such as autonomous driving, where failures can have catastrophic consequences. We focus on two problems: searching for scenarios when learned agents fail and assessing their probability of failure. The standard method for agent evaluation in reinforcement learning, Vanilla Monte Carlo, can miss failures entirely, leading to the deployment of unsafe agents. We demonstrate this is an issue for current agents, where even matching the compute used for training is sometimes insufficient for evaluation. To address this shortcoming, we draw upon the rare event probability estimation literature and propose an adversarial evaluation approach. Our approach focuses evaluation on adversarially chosen situations, while still providing unbiased estimates of failure probabilities. The key difficulty is in identifying these adversarial situations -- since failures are rare there is little signal to drive optimization. To solve this we propose a continuation approach that learns failure modes in related but less robust agents. Our approach also allows reuse of data already collected for training the agent. We demonstrate the efficacy of adversarial evaluation on two standard domains: humanoid control and simulated driving. Experimental results show that our methods can find catastrophic failures and estimate failures rates of agents multiple orders of magnitude faster than standard evaluation schemes, in minutes to hours rather than days.
Garbage In, Reward Out: Bootstrapping Exploration in Multi-Armed Bandits
Nov 13, 2018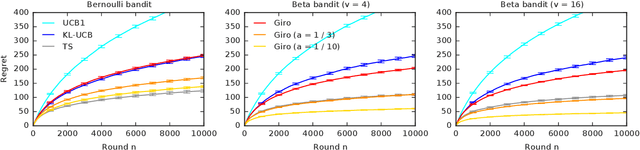
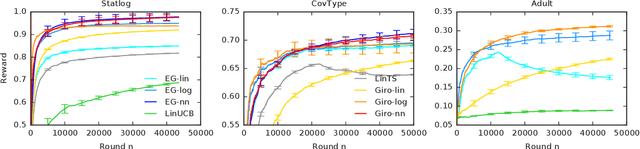
We propose a multi-armed bandit algorithm that explores based on randomizing its history. The key idea is to estimate the value of the arm from the bootstrap sample of its history, where we add pseudo observations after each pull of the arm. The pseudo observations seem to be harmful. But on the contrary, they guarantee that the bootstrap sample is optimistic with a high probability. Because of this, we call our algorithm Giro, which is an abbreviation for garbage in, reward out. We analyze Giro in a $K$-armed Bernoulli bandit and prove a $O(K \Delta^{-1} \log n)$ bound on its $n$-round regret, where $\Delta$ denotes the difference in the expected rewards of the optimal and best suboptimal arms. The main advantage of our exploration strategy is that it can be applied to any reward function generalization, such as neural networks. We evaluate Giro and its contextual variant on multiple synthetic and real-world problems, and observe that Giro is comparable to or better than state-of-the-art algorithms.