 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Reinforcement Learning with Value-Targeted Regression
Jun 01, 2020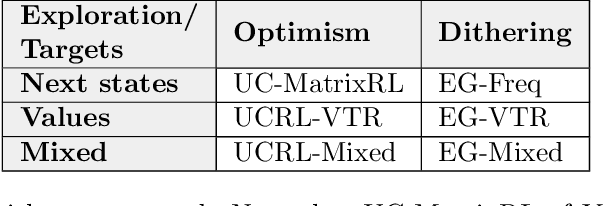
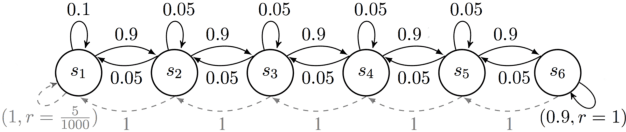
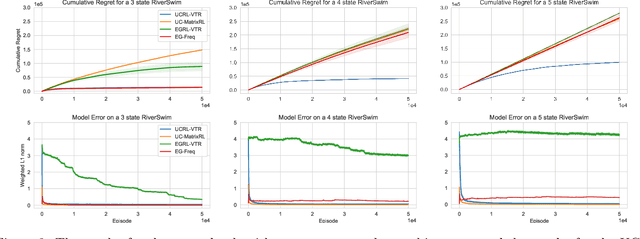
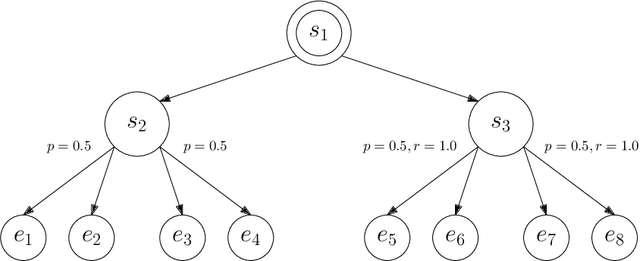
This paper studies model-based reinforcement learning (RL) for regret minimization. We focus on finite-horizon episodic RL where the transition model $P$ belongs to a known family of models $\mathcal{P}$, a special case of which is when models in $\mathcal{P}$ take the form of linear mixtures: $P_{\theta} = \sum_{i=1}^{d} \theta_{i}P_{i}$. We propose a model based RL algorithm that is based on optimism principle: In each episode, the set of models that are `consistent' with the data collected is constructed. The criterion of consistency is based on the total squared error of that the model incurs on the task of predicting \emph{values} as determined by the last value estimate along the transitions. The next value function is then chosen by solving the optimistic planning problem with the constructed set of models. We derive a bound on the regret, which, in the special case of linear mixtures, the regret bound takes the form $\tilde{\mathcal{O}}(d\sqrt{H^{3}T})$, where $H$, $T$ and $d$ are the horizon, total number of steps and dimension of $\theta$, respectively. In particular, this regret bound is independent of the total number of states or actions, and is close to a lower bound $\Omega(\sqrt{HdT})$. For a general model family $\mathcal{P}$, the regret bound is derived using the notion of the so-called Eluder dimension proposed by Russo & Van Roy (2014).
On the Global Convergence Rates of Softmax Policy Gradient Methods
May 13, 2020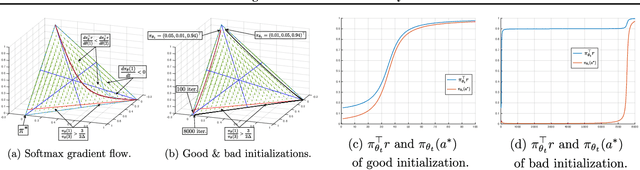
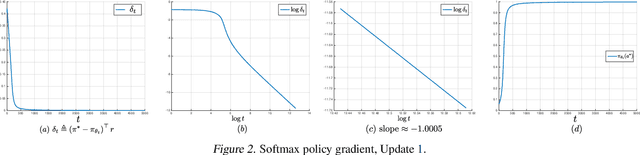
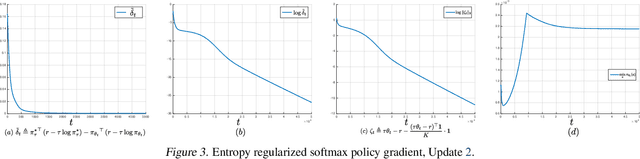
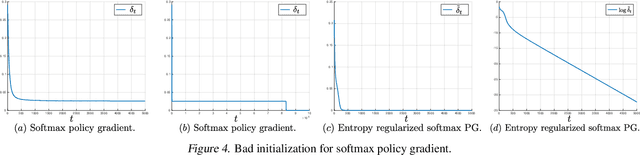
We make three contributions toward better understanding policy gradient methods in the tabular setting. First, we show that with the true gradient, policy gradient with a softmax parametrization converges at a $O(1/t)$ rate, with constants depending on the problem and initialization. This result significantly expands the recent asymptotic convergence results. The analysis relies on two findings: that the softmax policy gradient satisfies a \L{}ojasiewicz inequality, and the minimum probability of an optimal action during optimization can be bounded in terms of its initial value. Second, we analyze entropy regularized policy gradient and show that it enjoys a significantly faster linear convergence rate $O(e^{-t})$ toward softmax optimal policy. This result resolves an open question in the recent literature. Finally, combining the above two results and additional new $\Omega(1/t)$ lower bound results, we explain how entropy regularization improves policy optimization, even with the true gradient, from the perspective of convergence rate. The separation of rates is further explained using the notion of non-uniform \L{}ojasiewicz degree. These results provide a theoretical understanding of the impact of entropy and corroborate existing empirical studies.
Provably Efficient Adaptive Approximate Policy Iteration
Mar 15, 2020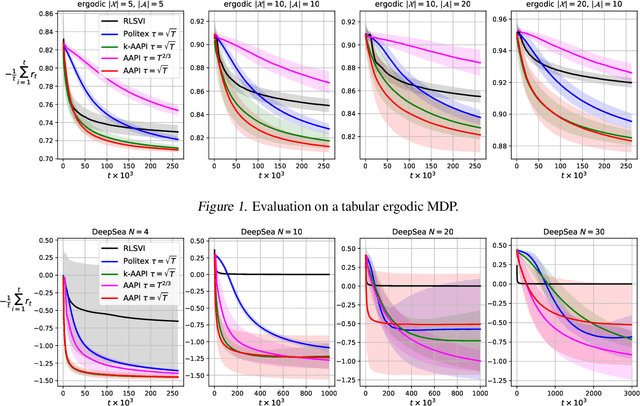
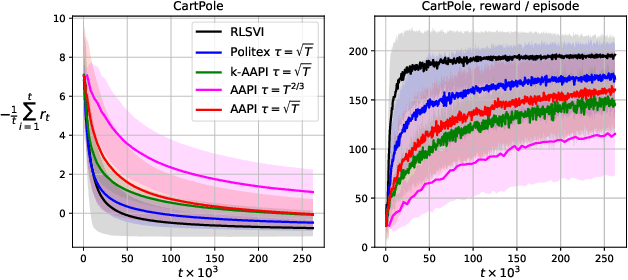
Model-free reinforcement learning algorithms combined with value function approximation have recently achieved impressive performance in a variety of application domains, including games and robotics. However, the theoretical understanding of such algorithms is limited, and existing results are largely focused on episodic or discounted Markov decision processes (MDPs). In this work, we present adaptive approximate policy iteration (AAPI), a learning scheme which enjoys a O(T^{2/3}) regret bound for undiscounted, continuing learning in uniformly ergodic MDPs. This is an improvement over the best existing bound of O(T^{3/4}) for the average-reward case with function approximation. Our algorithm and analysis rely on adversarial online learning techniques, where value functions are treated as losses. The main technical novelty is the use of a data-dependent adaptive learning rate coupled with a so-called optimistic prediction of upcoming losses. In addition to theoretical guarantees, we demonstrate the advantages of our approach empirically on several environments.
Model Selection in Contextual Stochastic Bandit Problems
Mar 03, 2020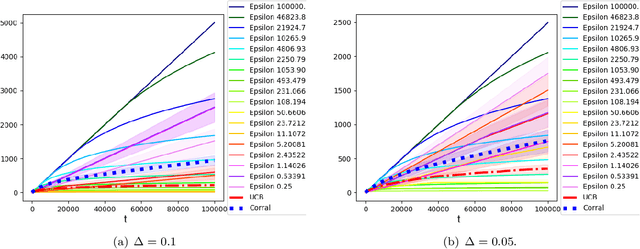
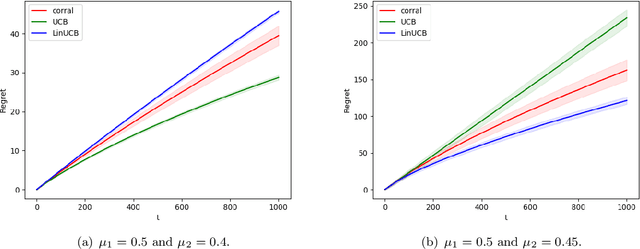
We study model selection in stochastic bandit problems. Our approach relies on a master algorithm that selects its actions among candidate base algorithms. While this problem is studied for specific classes of stochastic base algorithms, our objective is to provide a method that can work with more general classes of stochastic base algorithms. We propose a master algorithm inspired by CORRAL \cite{DBLP:conf/colt/AgarwalLNS17} and introduce a novel and generic smoothing transformation for stochastic bandit algorithms that permits us to obtain $O(\sqrt{T})$ regret guarantees for a wide class of base algorithms when working along with our master. We exhibit a lower bound showing that even when one of the base algorithms has $O(\log T)$ regret, in general it is impossible to get better than $\Omega(\sqrt{T})$ regret in model selection, even asymptotically. We apply our algorithm to choose among different values of $\epsilon$ for the $\epsilon$-greedy algorithm, and to choose between the $k$-armed UCB and linear UCB algorithms. Our empirical studies further confirm the effectiveness of our model-selection method.
Differentiable Bandit Exploration
Feb 17, 2020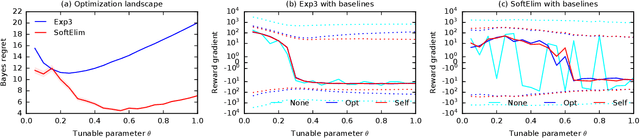
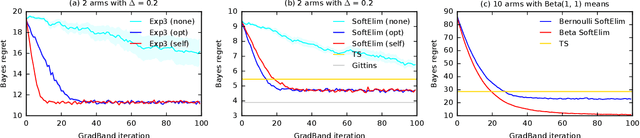
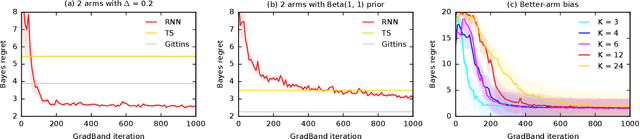
We learn bandit policies that maximize the average reward over bandit instances drawn from an unknown distribution $\mathcal{P}$, from a sample from $\mathcal{P}$. Our approach is an instance of meta-learning and its appeal is that the properties of $\mathcal{P}$ can be exploited without restricting it. We parameterize our policies in a differentiable way and optimize them by policy gradients - an approach that is easy to implement and pleasantly general. Then the challenge is to design effective gradient estimators and good policy classes. To make policy gradients practical, we introduce novel variance reduction techniques. We experiment with various bandit policy classes, including neural networks and a novel soft-elimination policy. The latter has regret guarantees and is a natural starting point for our optimization. Our experiments highlight the versatility of our approach. We also observe that neural network policies can learn implicit biases, which are only expressed through sampled bandit instances during training.
Learning with Good Feature Representations in Bandits and in RL with a Generative Model
Nov 18, 2019The construction in the recent paper by Du et al. [2019] implies that searching for a near-optimal action in a bandit sometimes requires examining essentially all the actions, even if the learner is given linear features in $\mathbb R^d$ that approximate the rewards with a small uniform error. In this note we use the Kiefer-Wolfowitz theorem to show that by checking only a few actions, a learner can always find an action which is suboptimal with an error of at most $O(\varepsilon \sqrt{d})$ where $\varepsilon$ is the approximation error of the features. Thus, features are useful when the approximation error is small relative to the dimensionality of the features. The idea is applied to stochastic bandits and reinforcement learning with a generative model where the learner has access to $d$-dimensional linear features that approximate the action-value functions for all policies to an accuracy of $\varepsilon$. For bandits we prove a bound on the regret of order $\sqrt{dn \log(k)} + \varepsilon n \sqrt{d} \log(n)$ with $k$ the number of actions and $n$ the horizon. For RL we show that approximate policy iteration can learn a policy that is optimal up to an additive error of order $\varepsilon \sqrt{d} / (1 - \gamma)^2$ and using about $d / (\varepsilon^2(1-\gamma)^4)$ samples from the generative model.
Autonomous exploration for navigating in non-stationary CMPs
Oct 18, 2019
We consider a setting in which the objective is to learn to navigate in a controlled Markov process (CMP) where transition probabilities may abruptly change. For this setting, we propose a performance measure called exploration steps which counts the time steps at which the learner lacks sufficient knowledge to navigate its environment efficiently. We devise a learning meta-algorithm, MNM and prove an upper bound on the exploration steps in terms of the number of changes.
Adaptive Exploration in Linear Contextual Bandit
Oct 15, 2019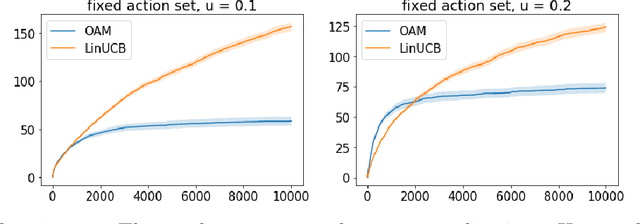
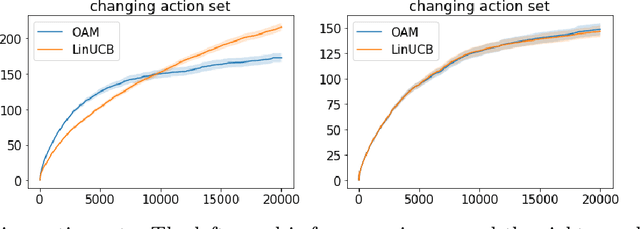
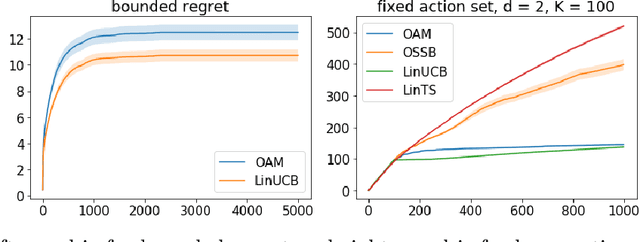
Contextual bandits serve as a fundamental model for many sequential decision making tasks. The most popular theoretically justified approaches are based on the optimism principle. While these algorithms can be practical, they are known to be suboptimal asymptotically (Lattimore and Szepesvari, 2017). On the other hand, existing asymptotically optimal algorithms for this problem do not exploit the linear structure in an optimal way and suffer from lower-order terms that dominate the regret in all practically interesting regimes. We start to bridge the gap by designing an algorithm that is asymptotically optimal and has good finite-time empirical performance. At the same time, we make connections to the recent literature on when exploration-free methods are effective. Indeed, if the distribution of contexts is well behaved, then our algorithm acts mostly greedily and enjoys sub-logarithmic regret. Furthermore, our approach is adaptive in the sense that it automatically detects the nice case. Numerical results demonstrate significant regret reductions by our method relative to several baselines.
PAC-Bayes with Backprop
Oct 04, 2019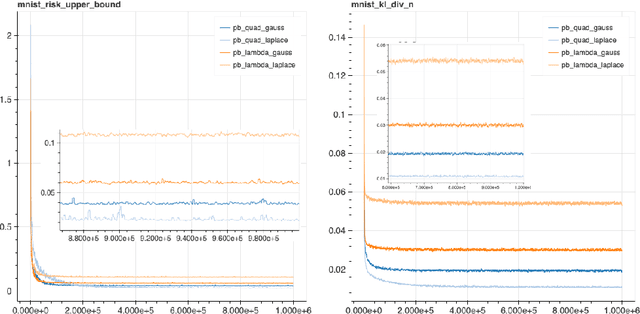
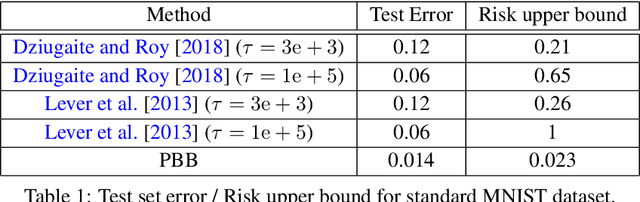
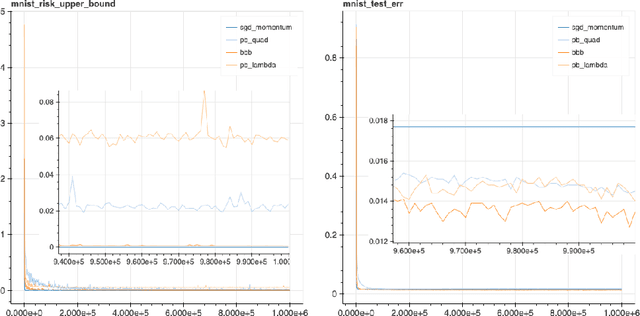

We explore the family of methods "PAC-Bayes with Backprop" (PBB) to train probabilistic neural networks by minimizing PAC-Bayes bounds. We present two training objectives, one derived from a previously known PAC-Bayes bound, and a second one derived from a novel PAC-Bayes bound. Both training objectives are evaluated on MNIST and on various UCI data sets. Our experiments show two striking observations: we obtain competitive test set error estimates (~1.4% on MNIST) and at the same time we compute non-vacuous bounds with much tighter values (~2.3% on MNIST) than previous results. These observations suggest that neural nets trained by PBB may lead to self-bounding learning, where the available data can be used to simultaneously learn a predictor and certify its risk, with no need to follow a data-splitting protocol.
Exploration-Enhanced POLITEX
Aug 27, 2019
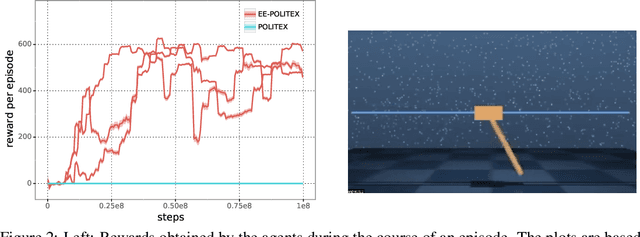
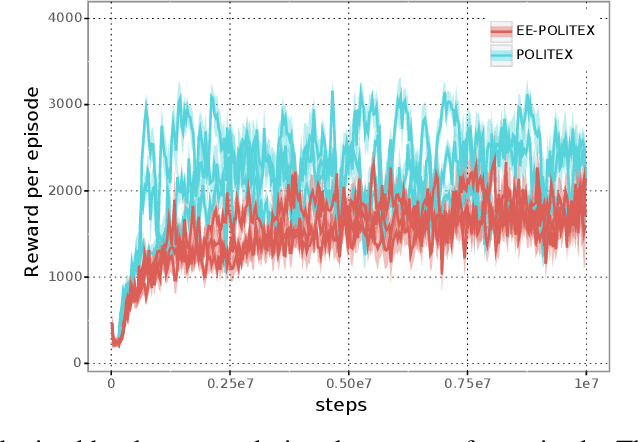
We study algorithms for average-cost reinforcement learning problems with value function approximation. Our starting point is the recently proposed POLITEX algorithm, a version of policy iteration where the policy produced in each iteration is near-optimal in hindsight for the sum of all past value function estimates. POLITEX has sublinear regret guarantees in uniformly-mixing MDPs when the value estimation error can be controlled, which can be satisfied if all policies sufficiently explore the environment. Unfortunately, this assumption is often unrealistic. Motivated by the rapid growth of interest in developing policies that learn to explore their environment in the lack of rewards (also known as no-reward learning), we replace the previous assumption that all policies explore the environment with that a single, sufficiently exploring policy is available beforehand. The main contribution of the paper is the modification of POLITEX to incorporate such an exploration policy in a way that allows us to obtain a regret guarantee similar to the previous one but without requiring that all policies explore environment. In addition to the novel theoretical guarantees, we demonstrate the benefits of our scheme on environments which are difficult to explore using simple schemes like dithering. While the solution we obtain may not achieve the best possible regret, it is the first result that shows how to control the regret in the presence of function approximation errors on problems where exploration is nontrivial. Our approach can also be seen as a way of reducing the problem of minimizing the regret to learning a good exploration policy. We believe that modular approaches like ours can be highly beneficial in tackling harder control problems.