 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Adaptive Approximate Policy Iteration
Paper and Code
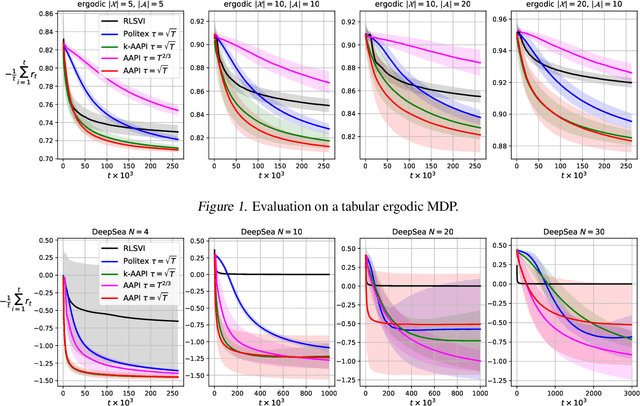
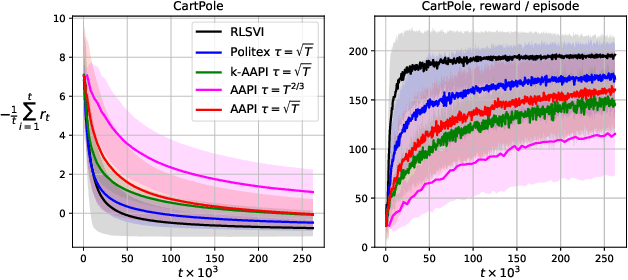
Model-free reinforcement learning algorithms combined with value function approximation have recently achieved impressive performance in a variety of application domains, including games and robotics. However, the theoretical understanding of such algorithms is limited, and existing results are largely focused on episodic or discounted Markov decision processes (MDPs). In this work, we present adaptive approximate policy iteration (AAPI), a learning scheme which enjoys a O(T^{2/3}) regret bound for undiscounted, continuing learning in uniformly ergodic MDPs. This is an improvement over the best existing bound of O(T^{3/4}) for the average-reward case with function approximation. Our algorithm and analysis rely on adversarial online learning techniques, where value functions are treated as losses. The main technical novelty is the use of a data-dependent adaptive learning rate coupled with a so-called optimistic prediction of upcoming losses. In addition to theoretical guarantees, we demonstrate the advantages of our approach empirically on several environments.