 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Community Feedback Shapes User Behavior
May 06, 2014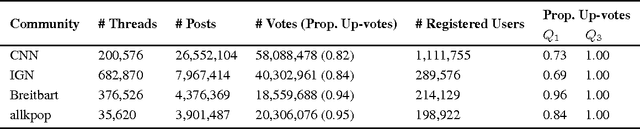
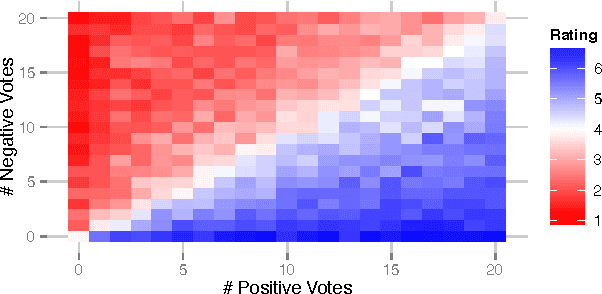
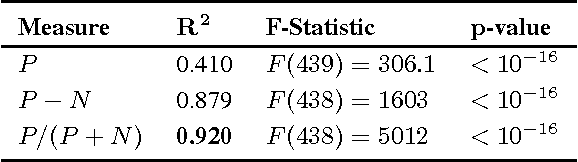
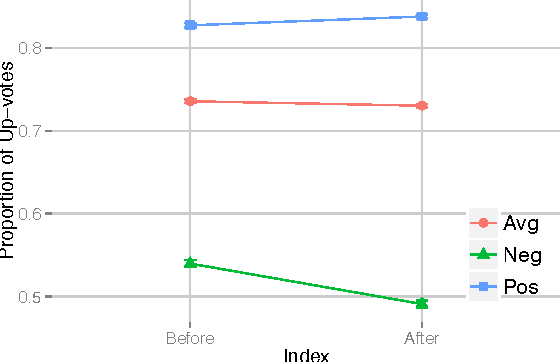
Social media systems rely on user feedback and rating mechanisms for personalization, ranking, and content filtering. However, when users evaluate content contributed by fellow users (e.g., by liking a post or voting on a comment), these evaluations create complex social feedback effects. This paper investigates how ratings on a piece of content affect its author's future behavior. By studying four large comment-based news communities, we find that negative feedback leads to significant behavioral changes that are detrimental to the community. Not only do authors of negatively-evaluated content contribute more, but also their future posts are of lower quality, and are perceived by the community as such. Moreover, these authors are more likely to subsequently evaluate their fellow users negatively, percolating these effects through the community. In contrast, positive feedback does not carry similar effects, and neither encourages rewarded authors to write more, nor improves the quality of their posts. Interestingly, the authors that receive no feedback are most likely to leave a community. Furthermore, a structural analysis of the voter network reveals that evaluations polarize the community the most when positive and negative votes are equally split.
A Computational Approach to Politeness with Application to Social Factors
Jun 25, 2013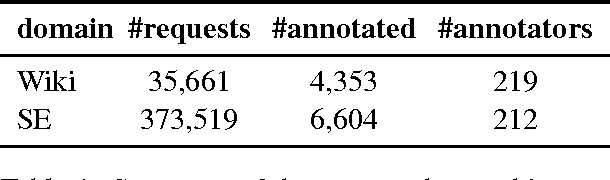
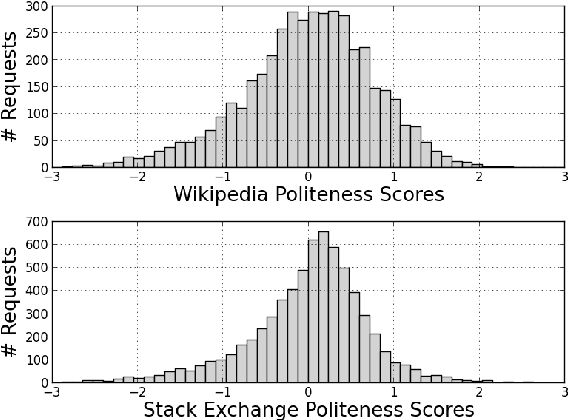
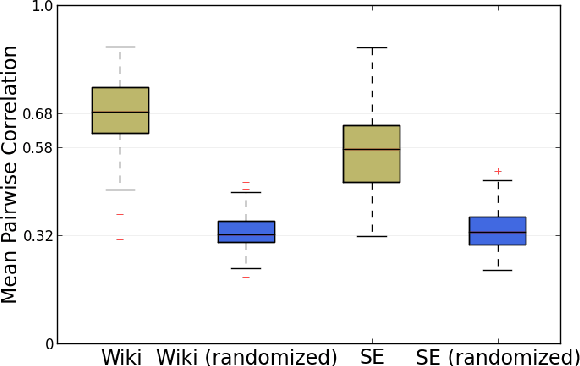
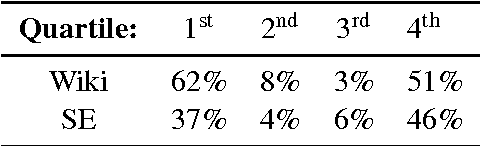
We propose a computational framework for identifying linguistic aspects of politeness. Our starting point is a new corpus of requests annotated for politeness, which we use to evaluate aspects of politeness theory and to uncover new interactions between politeness markers and context. These findings guide our construction of a classifier with domain-independent lexical and syntactic features operationalizing key components of politeness theory, such as indirection, deference, impersonalization and modality. Our classifier achieves close to human performance and is effective across domains. We use our framework to study the relationship between politeness and social power, showing that polite Wikipedia editors are more likely to achieve high status through elections, but, once elevated, they become less polite. We see a similar negative correlation between politeness and power on Stack Exchange, where users at the top of the reputation scale are less polite than those at the bottom. Finally, we apply our classifier to a preliminary analysis of politeness variation by gender and community.
Hedge detection as a lens on framing in the GMO debates: A position paper
Jun 05, 2012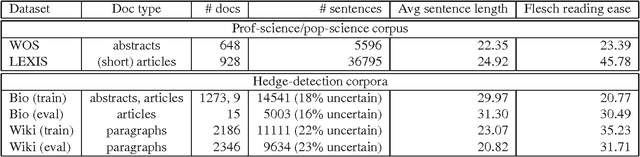


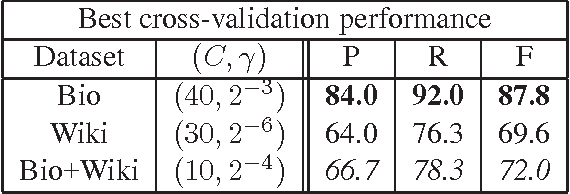
Understanding the ways in which participants in public discussions frame their arguments is important in understanding how public opinion is formed. In this paper, we adopt the position that it is time for more computationally-oriented research on problems involving framing. In the interests of furthering that goal, we propose the following specific, interesting and, we believe, relatively accessible question: In the controversy regarding the use of genetically-modified organisms (GMOs) in agriculture, do pro- and anti-GMO articles differ in whether they choose to adopt a "scientific" tone? Prior work on the rhetoric and sociology of science suggests that hedging may distinguish popular-science text from text written by professional scientists for their colleagues. We propose a detailed approach to studying whether hedge detection can be used to understanding scientific framing in the GMO debates, and provide corpora to facilitate this study. Some of our preliminary analyses suggest that hedges occur less frequently in scientific discourse than in popular text, a finding that contradicts prior assertions in the literature. We hope that our initial work and data will encourage others to pursue this promising line of inquiry.
You had me at hello: How phrasing affects memorability
Apr 30, 2012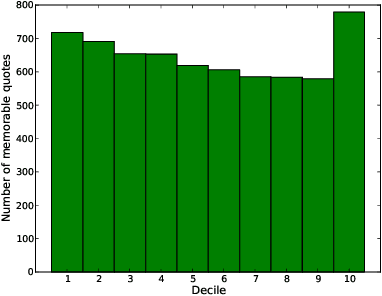

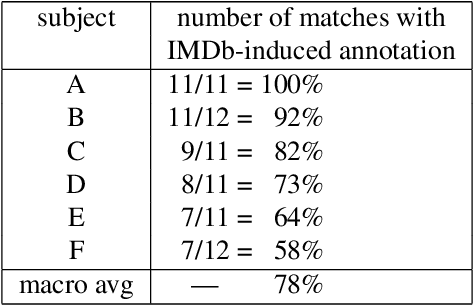
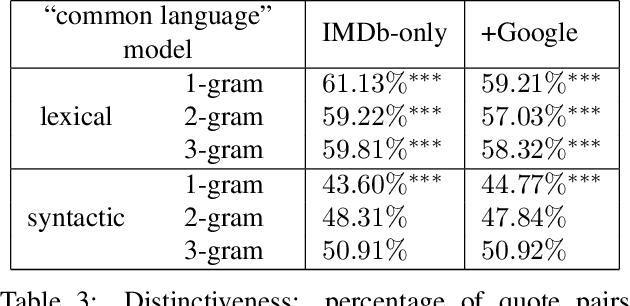
Understanding the ways in which information achieves widespread public awareness is a research question of significant interest. We consider whether, and how, the way in which the information is phrased --- the choice of words and sentence structure --- can affect this process. To this end, we develop an analysis framework and build a corpus of movie quotes, annotated with memorability information, in which we are able to control for both the speaker and the setting of the quotes. We find that there are significant differences between memorable and non-memorable quotes in several key dimensions, even after controlling for situational and contextual factors. One is lexical distinctiveness: in aggregate, memorable quotes use less common word choices, but at the same time are built upon a scaffolding of common syntactic patterns. Another is that memorable quotes tend to be more general in ways that make them easy to apply in new contexts --- that is, more portable. We also show how the concept of "memorable language" can be extended across domains.
Echoes of power: Language effects and power differences in social interaction
Apr 13, 2012
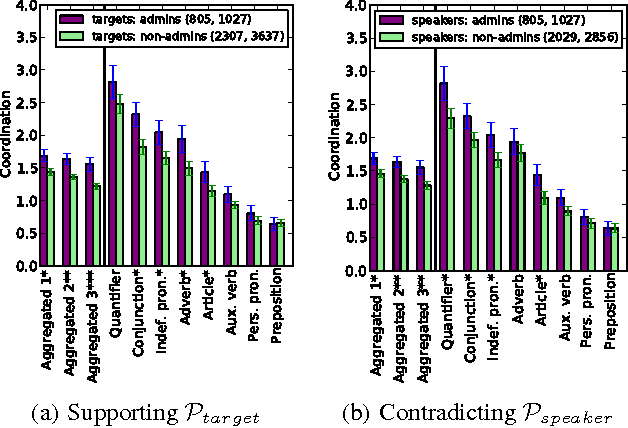
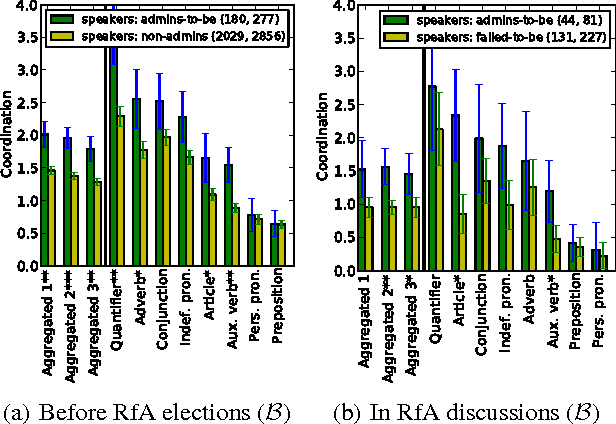

Understanding social interaction within groups is key to analyzing online communities. Most current work focuses on structural properties: who talks to whom, and how such interactions form larger network structures. The interactions themselves, however, generally take place in the form of natural language --- either spoken or written --- and one could reasonably suppose that signals manifested in language might also provide information about roles, status, and other aspects of the group's dynamics. To date, however, finding such domain-independent language-based signals has been a challenge. Here, we show that in group discussions power differentials between participants are subtly revealed by how much one individual immediately echoes the linguistic style of the person they are responding to. Starting from this observation, we propose an analysis framework based on linguistic coordination that can be used to shed light on power relationships and that works consistently across multiple types of power --- including a more "static" form of power based on status differences, and a more "situational" form of power in which one individual experiences a type of dependence on another. Using this framework, we study how conversational behavior can reveal power relationships in two very different settings: discussions among Wikipedians and arguments before the U.S. Supreme Court.
Chameleons in imagined conversations: A new approach to understanding coordination of linguistic style in dialogs
Jun 15, 2011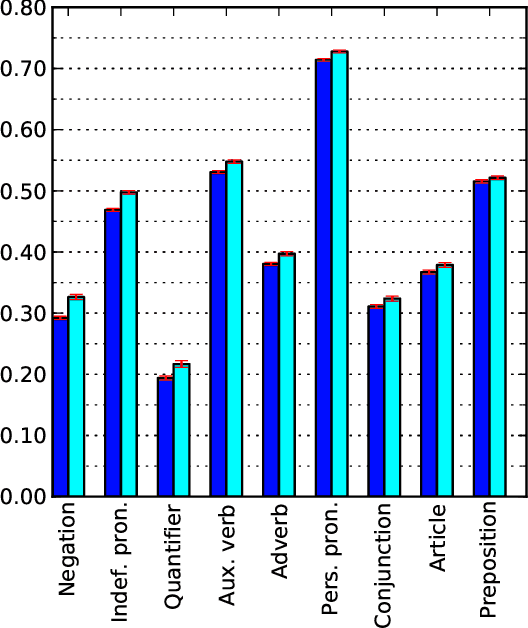
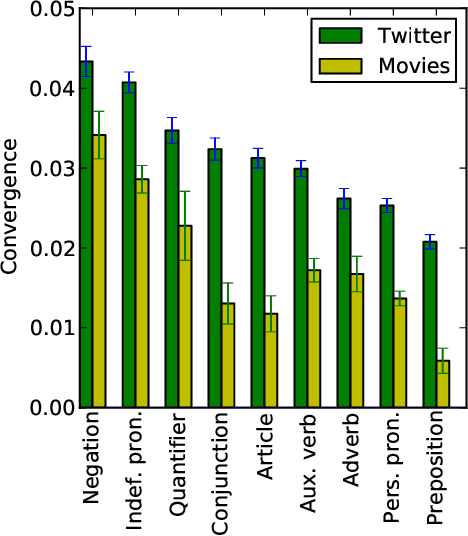
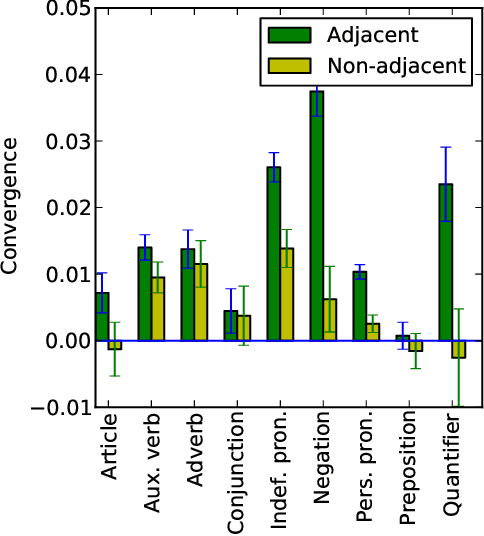
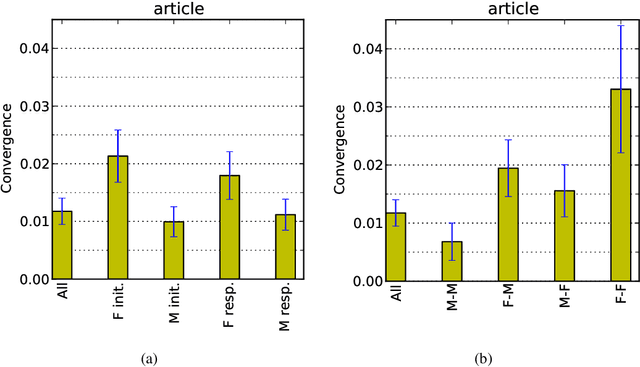
Conversational participants tend to immediately and unconsciously adapt to each other's language styles: a speaker will even adjust the number of articles and other function words in their next utterance in response to the number in their partner's immediately preceding utterance. This striking level of coordination is thought to have arisen as a way to achieve social goals, such as gaining approval or emphasizing difference in status. But has the adaptation mechanism become so deeply embedded in the language-generation process as to become a reflex? We argue that fictional dialogs offer a way to study this question, since authors create the conversations but don't receive the social benefits (rather, the imagined characters do). Indeed, we find significant coordination across many families of function words in our large movie-script corpus. We also report suggestive preliminary findings on the effects of gender and other features; e.g., surprisingly, for articles, on average, characters adapt more to females than to males.
* data available at http://www.cs.cornell.edu/~cristian/movies
Mark My Words! Linguistic Style Accommodation in Social Media
May 03, 2011
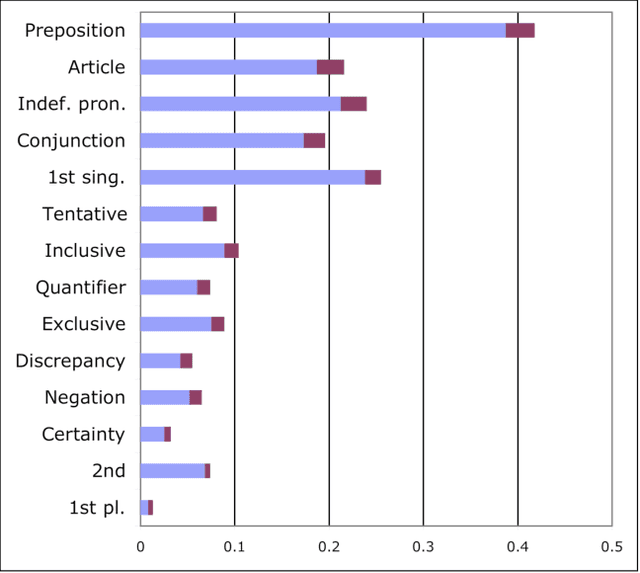
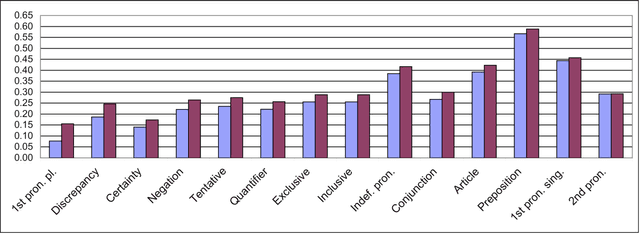
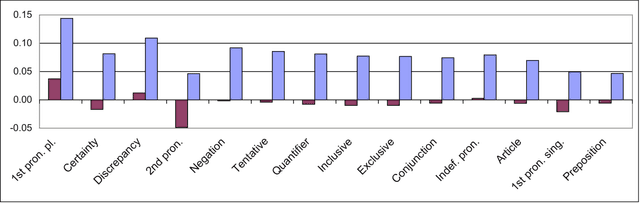
The psycholinguistic theory of communication accommodation accounts for the general observation that participants in conversations tend to converge to one another's communicative behavior: they coordinate in a variety of dimensions including choice of words, syntax, utterance length, pitch and gestures. In its almost forty years of existence, this theory has been empirically supported exclusively through small-scale or controlled laboratory studies. Here we address this phenomenon in the context of Twitter conversations. Undoubtedly, this setting is unlike any other in which accommodation was observed and, thus, challenging to the theory. Its novelty comes not only from its size, but also from the non real-time nature of conversations, from the 140 character length restriction, from the wide variety of social relation types, and from a design that was initially not geared towards conversation at all. Given such constraints, it is not clear a priori whether accommodation is robust enough to occur given the constraints of this new environment. To investigate this, we develop a probabilistic framework that can model accommodation and measure its effects. We apply it to a large Twitter conversational dataset specifically developed for this task. This is the first time the hypothesis of linguistic style accommodation has been examined (and verified) in a large scale, real world setting. Furthermore, when investigating concepts such as stylistic influence and symmetry of accommodation, we discover a complexity of the phenomenon which was never observed before. We also explore the potential relation between stylistic influence and network features commonly associated with social status.
* Talk slides available at http://www.cs.cornell.edu/~cristian/www2011
Don't 'have a clue'? Unsupervised co-learning of downward-entailing operators
Nov 27, 2010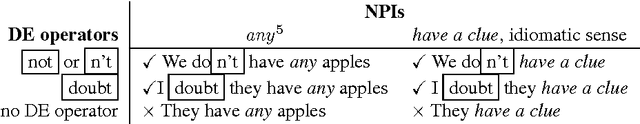
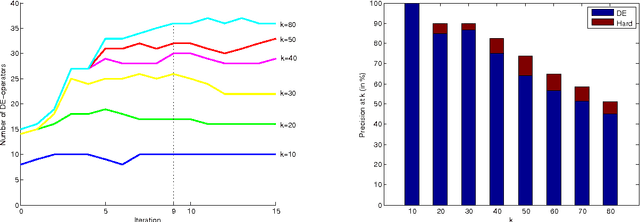
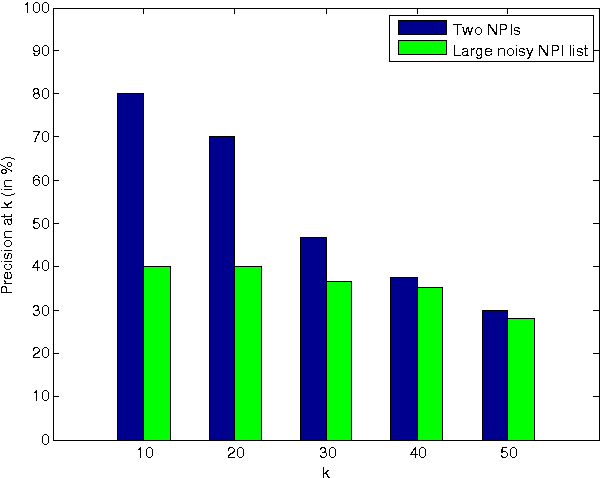
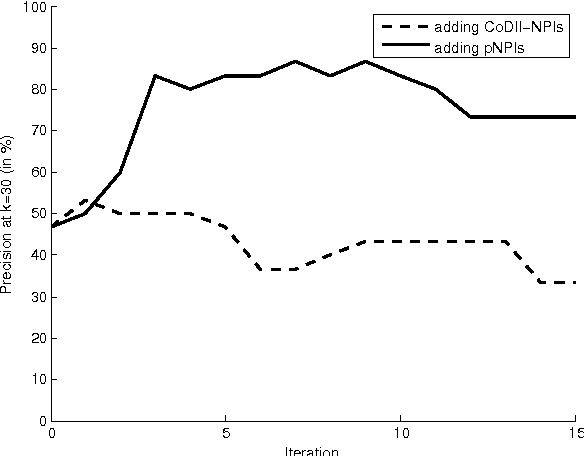
Researchers in textual entailment have begun to consider inferences involving 'downward-entailing operators', an interesting and important class of lexical items that change the way inferences are made. Recent work proposed a method for learning English downward-entailing operators that requires access to a high-quality collection of 'negative polarity items' (NPIs). However, English is one of the very few languages for which such a list exists. We propose the first approach that can be applied to the many languages for which there is no pre-existing high-precision database of NPIs. As a case study, we apply our method to Romanian and show that our method yields good results. Also, we perform a cross-linguistic analysis that suggests interesting connections to some findings in linguistic typology.
* pp 1-6 are identical to the ACL 2010 published version; pp. 7-8 are the "externally-available appendices". Revision contains an additional appendix correcting the origin of the term "pseudo-polarity item"
For the sake of simplicity: Unsupervised extraction of lexical simplifications from Wikipedia
Aug 11, 2010We report on work in progress on extracting lexical simplifications (e.g., "collaborate" -> "work together"), focusing on utilizing edit histories in Simple English Wikipedia for this task. We consider two main approaches: (1) deriving simplification probabilities via an edit model that accounts for a mixture of different operations, and (2) using metadata to focus on edits that are more likely to be simplification operations. We find our methods to outperform a reasonable baseline and yield many high-quality lexical simplifications not included in an independently-created manually prepared list.
* 4 pp; data available at http://www.cs.cornell.edu/home/llee/data/simple/
How opinions are received by online communities: A case study on Amazon.com helpfulness votes
Jun 21, 2009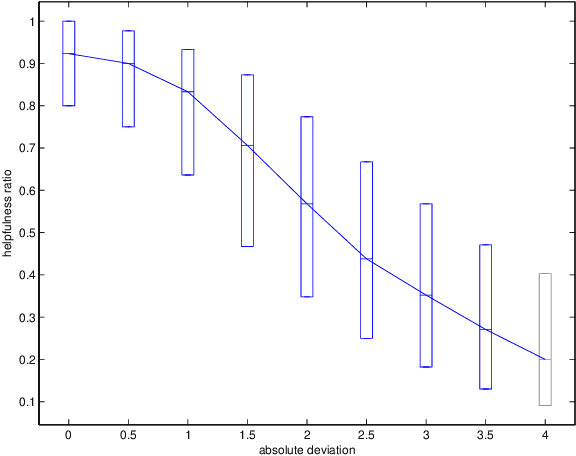
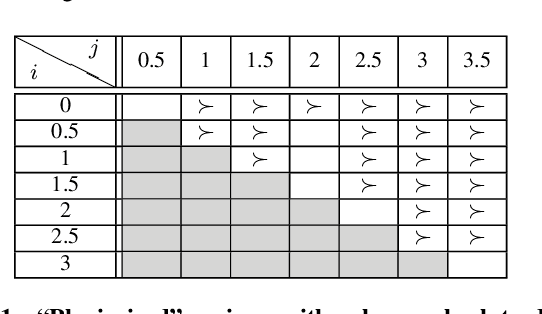
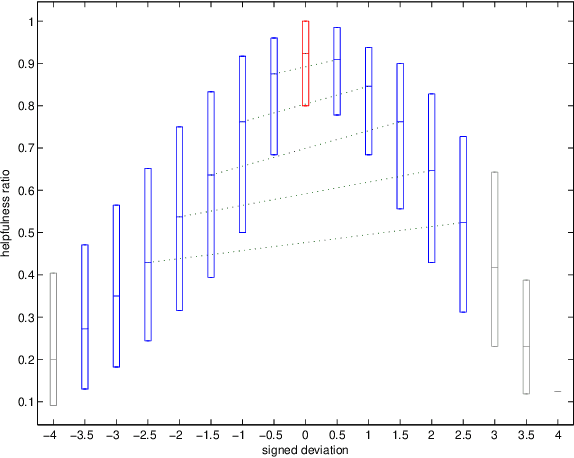
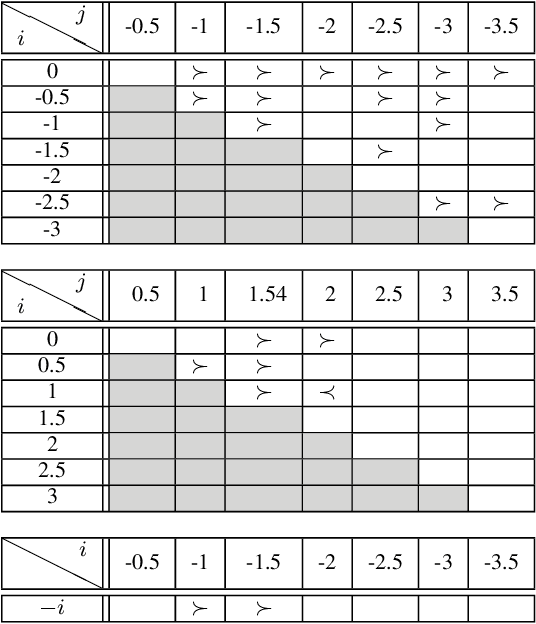
There are many on-line settings in which users publicly express opinions. A number of these offer mechanisms for other users to evaluate these opinions; a canonical example is Amazon.com, where reviews come with annotations like "26 of 32 people found the following review helpful." Opinion evaluation appears in many off-line settings as well, including market research and political campaigns. Reasoning about the evaluation of an opinion is fundamentally different from reasoning about the opinion itself: rather than asking, "What did Y think of X?", we are asking, "What did Z think of Y's opinion of X?" Here we develop a framework for analyzing and modeling opinion evaluation, using a large-scale collection of Amazon book reviews as a dataset. We find that the perceived helpfulness of a review depends not just on its content but also but also in subtle ways on how the expressed evaluation relates to other evaluations of the same product. As part of our approach, we develop novel methods that take advantage of the phenomenon of review "plagiarism" to control for the effects of text in opinion evaluation, and we provide a simple and natural mathematical model consistent with our findings. Our analysis also allows us to distinguish among the predictions of competing theories from sociology and social psychology, and to discover unexpected differences in the collective opinion-evaluation behavior of user populations from different countries.