 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA paradox of AI fluency
Apr 28, 2026How much does a user's skill with AI shape what AI actually delivers for them? This question is critical for users, AI product builders, and society at large, but it remains underexplored. Using a richly annotated sample of 27K transcripts from WildChat-4.8M, we show that fluent users take on more complex tasks than novices and adopt a fundamentally different interactional mode: they iterate collaboratively with the AI, refining goals and critically assessing outputs, whereas novices take a passive stance. These differences lead to a paradox of AI fluency: fluent users experience more failures than novices -- but their failures tend to be visible (a direct consequence of their engagement), they are more likely to lead to partial recovery, and they occur alongside greater success on complex tasks. Novices, by contrast, more often experience invisible failures: conversations that appear to end successfully but in fact miss the mark. Taken together, these results reframe what success with AI depends on. Individuals should adopt a stance of active engagement rather than passive acceptance. AI product builders should recognize that they are designing not just model behavior but user behavior; encouraging deep engagement, rather than friction-free experiences, will lead to more success overall. Our code and data are available at https://github.com/bigspinai/bigspin-fluency-outcomes
Invisible failures in human-AI interactions
Mar 16, 2026AI systems fail silently far more often than they fail visibly. In a large-scale quantitative analysis of human-AI interactions from the WildChat dataset, we find that 78% of AI failures are invisible: something went wrong but the user gave no overt indication that there was a problem. These invisible failures cluster into eight archetypes that help us characterize where and how AI systems are failing to meet users' needs. In addition, the archetypes show systematic co-occurrence patterns indicating higher-level failure types. To address the question of whether these archetypes will remain relevant as AI systems become more capable, we also assess failures for whether they are primarily interactional or capability-driven, finding that 91% involve interactional dynamics, and we estimate that 94% of such failures would persist even with a more capable model. Finally, we illustrate how the archetypes help us to identify systematic and variable AI limitations across different usage domains. Overall, we argue that our invisible failure taxonomy can be a key component in reliable failure monitoring for product developers, scientists, and policy makers. Our code and data are available at https://github.com/bigspinai/bigspin-invisible-failure-archetypes
A Computational Approach to Politeness with Application to Social Factors
Jun 25, 2013
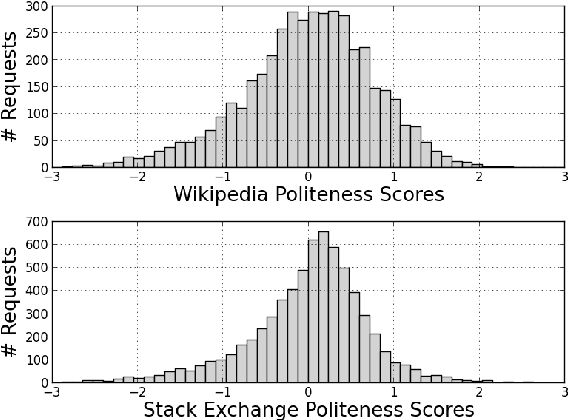
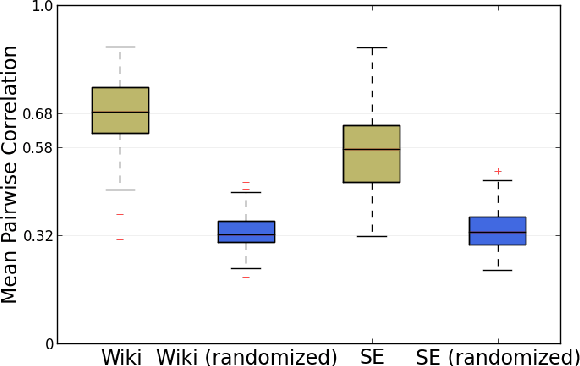
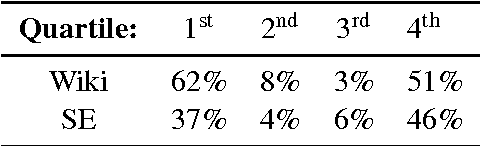
We propose a computational framework for identifying linguistic aspects of politeness. Our starting point is a new corpus of requests annotated for politeness, which we use to evaluate aspects of politeness theory and to uncover new interactions between politeness markers and context. These findings guide our construction of a classifier with domain-independent lexical and syntactic features operationalizing key components of politeness theory, such as indirection, deference, impersonalization and modality. Our classifier achieves close to human performance and is effective across domains. We use our framework to study the relationship between politeness and social power, showing that polite Wikipedia editors are more likely to achieve high status through elections, but, once elevated, they become less polite. We see a similar negative correlation between politeness and power on Stack Exchange, where users at the top of the reputation scale are less polite than those at the bottom. Finally, we apply our classifier to a preliminary analysis of politeness variation by gender and community.