 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating End-to-End Speech Recognition Models for Sentiment Analysis
Feb 28, 2019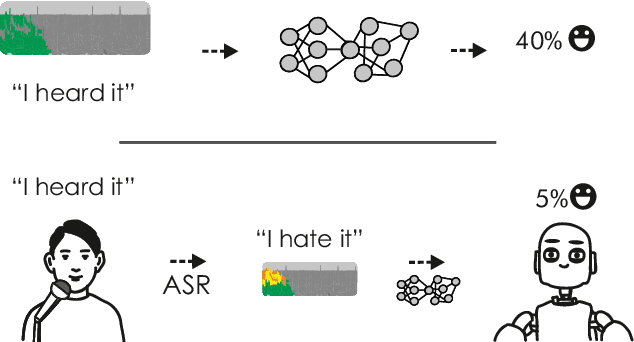
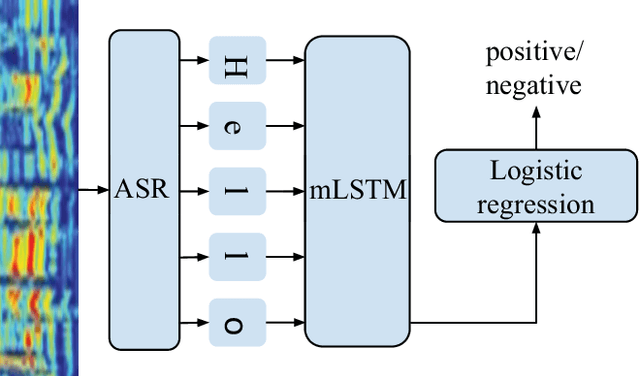
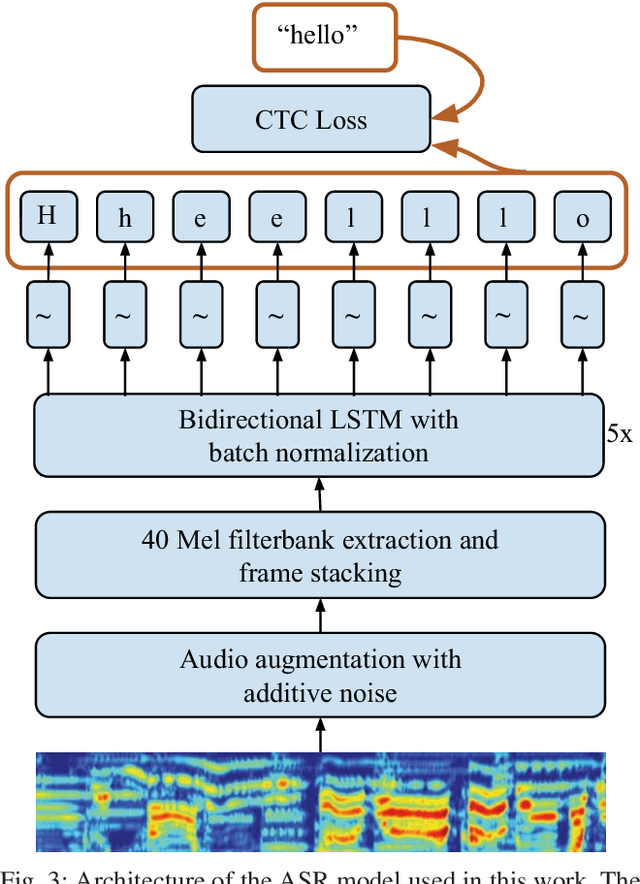
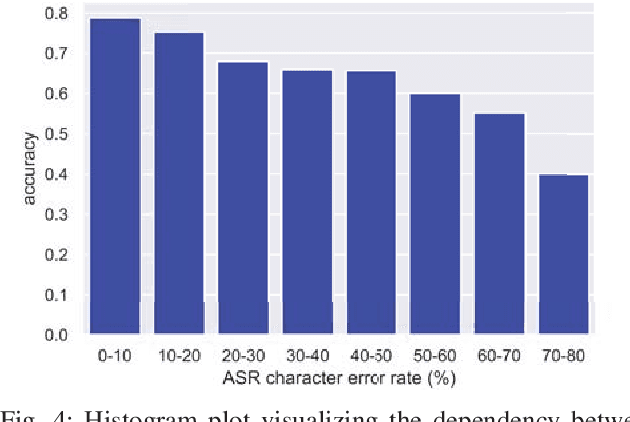
Previous work on emotion recognition demonstrated a synergistic effect of combining several modalities such as auditory, visual, and transcribed text to estimate the affective state of a speaker. Among these, the linguistic modality is crucial for the evaluation of an expressed emotion. However, manually transcribed spoken text cannot be given as input to a system practically. We argue that using ground-truth transcriptions during training and evaluation phases leads to a significant discrepancy in performance compared to real-world conditions, as the spoken text has to be recognized on the fly and can contain speech recognition mistakes. In this paper, we propose a method of integrating an automatic speech recognition (ASR) output with a character-level recurrent neural network for sentiment recognition. In addition, we conduct several experiments investigating sentiment recognition for human-robot interaction in a noise-realistic scenario which is challenging for the ASR systems. We quantify the improvement compared to using only the acoustic modality in sentiment recognition. We demonstrate the effectiveness of this approach on the Multimodal Corpus of Sentiment Intensity (MOSI) by achieving 73,6% accuracy in a binary sentiment classification task, exceeding previously reported results that use only acoustic input. In addition, we set a new state-of-the-art performance on the MOSI dataset (80.4% accuracy, 2% absolute improvement).
Deep Intrinsically Motivated Continuous Actor-Critic for Efficient Robotic Visuomotor Skill Learning
Feb 18, 2019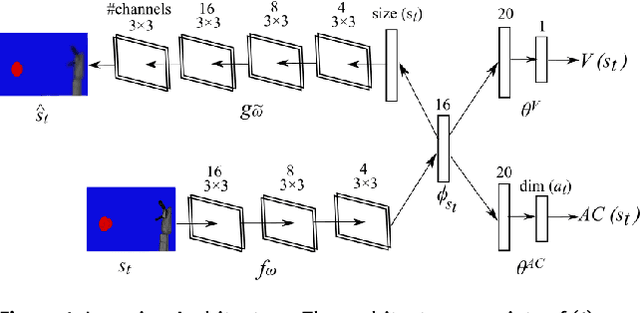
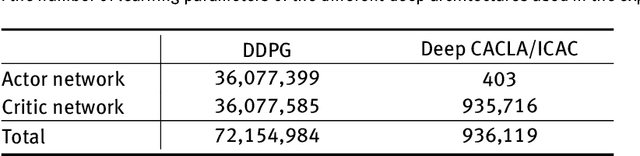
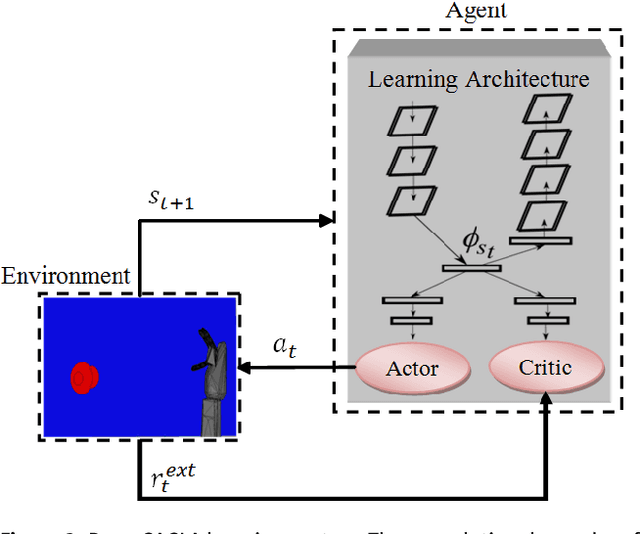
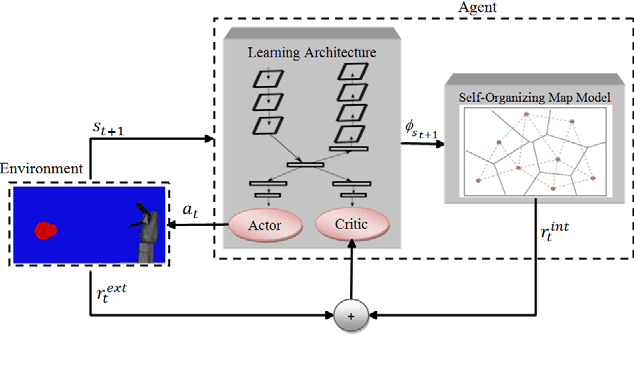
In this paper, we present a new intrinsically motivated actor-critic algorithm for learning continuous motor skills directly from raw visual input. Our neural architecture is composed of a critic and an actor network. Both networks receive the hidden representation of a deep convolutional autoencoder which is trained to reconstruct the visual input, while the centre-most hidden representation is also optimized to estimate the state value. Separately, an ensemble of predictive world models generates, based on its learning progress, an intrinsic reward signal which is combined with the extrinsic reward to guide the exploration of the actor-critic learner. Our approach is more data-efficient and inherently more stable than the existing actor-critic methods for continuous control from pixel data. We evaluate our algorithm for the task of learning robotic reaching and grasping skills on a realistic physics simulator and on a humanoid robot. The results show that the control policies learned with our approach can achieve better performance than the compared state-of-the-art and baseline algorithms in both dense-reward and challenging sparse-reward settings.
Lifelong Learning of Spatiotemporal Representations with Dual-Memory Recurrent Self-Organization
Oct 30, 2018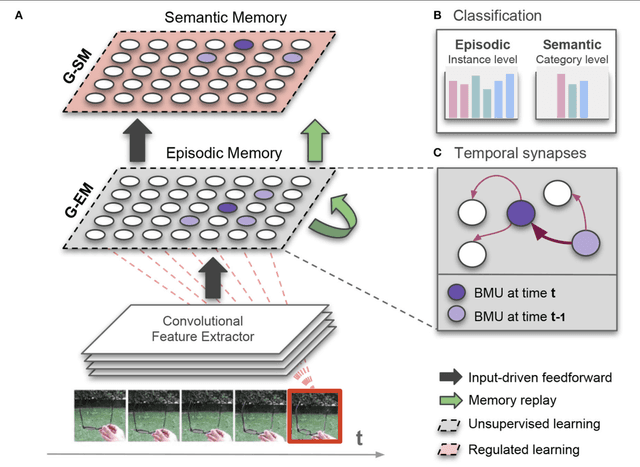



Artificial autonomous agents and robots interacting in complex environments are required to continually acquire and fine-tune knowledge over sustained periods of time. The ability to learn from continuous streams of information is referred to as lifelong learning and represents a long-standing challenge for neural network models due to catastrophic forgetting. Computational models of lifelong learning typically alleviate catastrophic forgetting in experimental scenarios with given datasets of static images and limited complexity, thereby differing significantly from the conditions artificial agents are exposed to. In more natural settings, sequential information may become progressively available over time and access to previous experience may be restricted. In this paper, we propose a dual-memory self-organizing architecture for lifelong learning scenarios. The architecture comprises two growing recurrent networks with the complementary tasks of learning object instances (episodic memory) and categories (semantic memory). Both growing networks can expand in response to novel sensory experience: the episodic memory learns fine-grained spatiotemporal representations of object instances in an unsupervised fashion while the semantic memory uses task-relevant signals to regulate structural plasticity levels and develop more compact representations from episodic experience. For the consolidation of knowledge in the absence of external sensory input, the episodic memory periodically replays trajectories of neural reactivations. We evaluate the proposed model on the CORe50 benchmark dataset for continuous object recognition, showing that we significantly outperform current methods of lifelong learning in three different incremental learning scenarios
Discourse-Wizard: Discovering Deep Discourse Structure in your Conversation with RNNs
Jun 29, 2018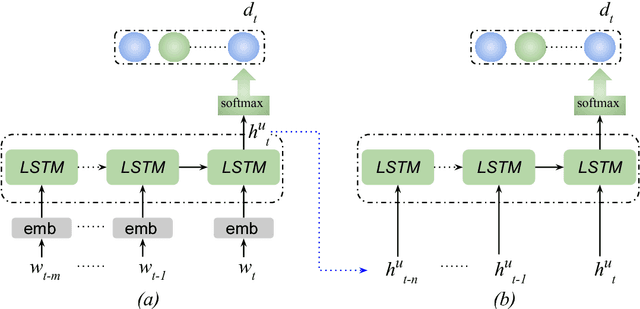

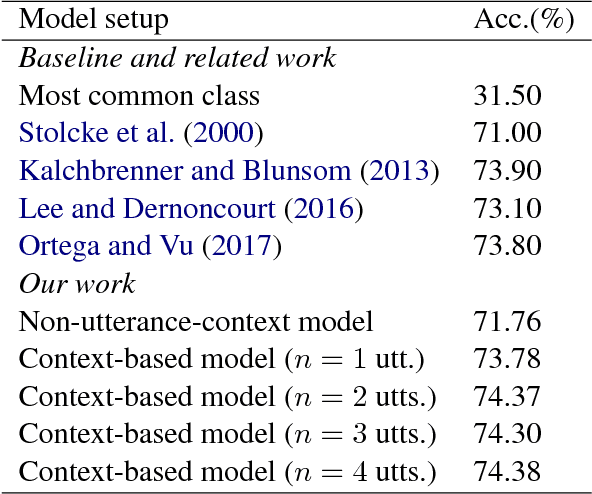
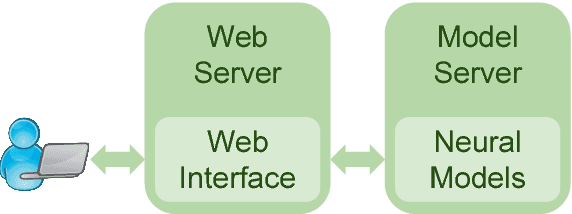
Spoken language understanding is one of the key factors in a dialogue system, and a context in a conversation plays an important role to understand the current utterance. In this work, we demonstrate the importance of context within the dialogue for neural network models through an online web interface live demo. We developed two different neural models: a model that does not use context and a context-based model. The no-context model classifies dialogue acts at an utterance-level whereas the context-based model takes some preceding utterances into account. We make these trained neural models available as a live demo called Discourse-Wizard using a modular server architecture. The live demo provides an easy to use interface for conversational analysis and for discovering deep discourse structures in a conversation.
Conversational Analysis using Utterance-level Attention-based Bidirectional Recurrent Neural Networks
Jun 20, 2018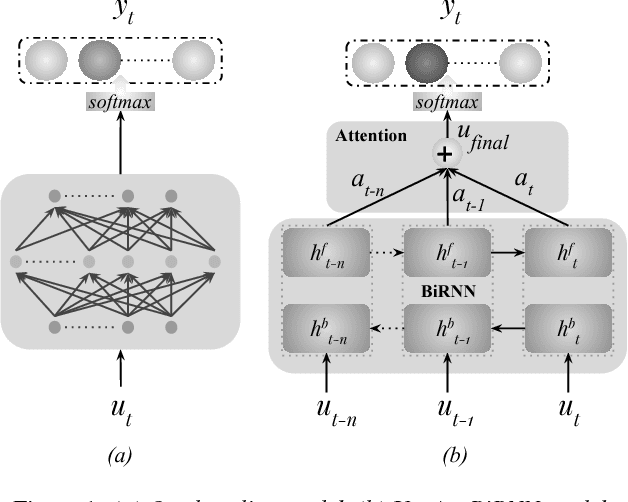
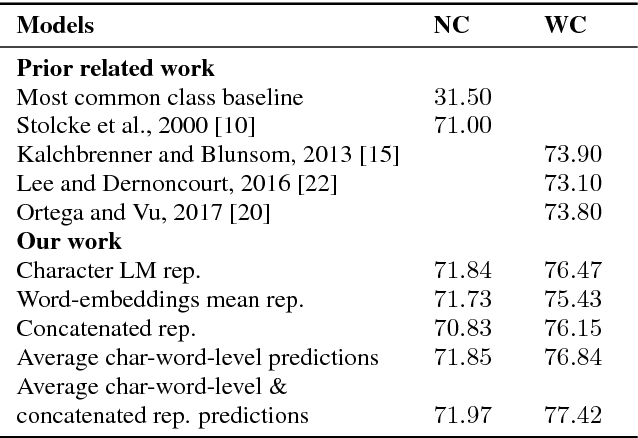
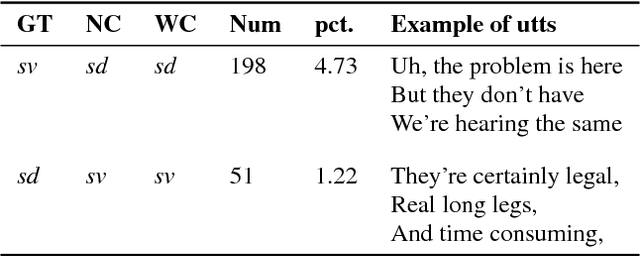
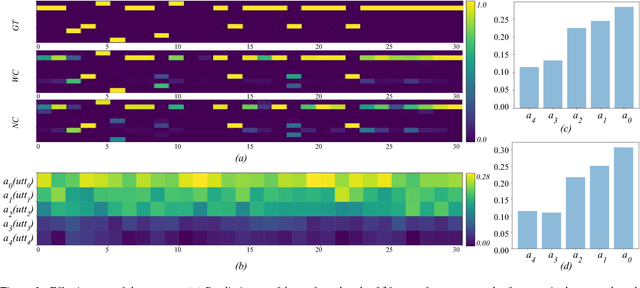
Recent approaches for dialogue act recognition have shown that context from preceding utterances is important to classify the subsequent one. It was shown that the performance improves rapidly when the context is taken into account. We propose an utterance-level attention-based bidirectional recurrent neural network (Utt-Att-BiRNN) model to analyze the importance of preceding utterances to classify the current one. In our setup, the BiRNN is given the input set of current and preceding utterances. Our model outperforms previous models that use only preceding utterances as context on the used corpus. Another contribution of the article is to discover the amount of information in each utterance to classify the subsequent one and to show that context-based learning not only improves the performance but also achieves higher confidence in the classification. We use character- and word-level features to represent the utterances. The results are presented for character and word feature representations and as an ensemble model of both representations. We found that when classifying short utterances, the closest preceding utterances contributes to a higher degree.
A Context-based Approach for Dialogue Act Recognition using Simple Recurrent Neural Networks
May 16, 2018
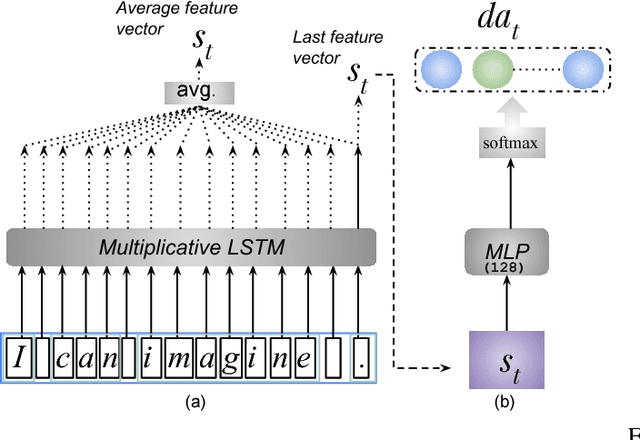
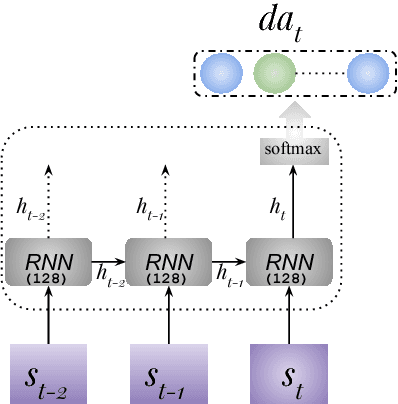

Dialogue act recognition is an important part of natural language understanding. We investigate the way dialogue act corpora are annotated and the learning approaches used so far. We find that the dialogue act is context-sensitive within the conversation for most of the classes. Nevertheless, previous models of dialogue act classification work on the utterance-level and only very few consider context. We propose a novel context-based learning method to classify dialogue acts using a character-level language model utterance representation, and we notice significant improvement. We evaluate this method on the Switchboard Dialogue Act corpus, and our results show that the consideration of the preceding utterances as a context of the current utterance improves dialogue act detection.
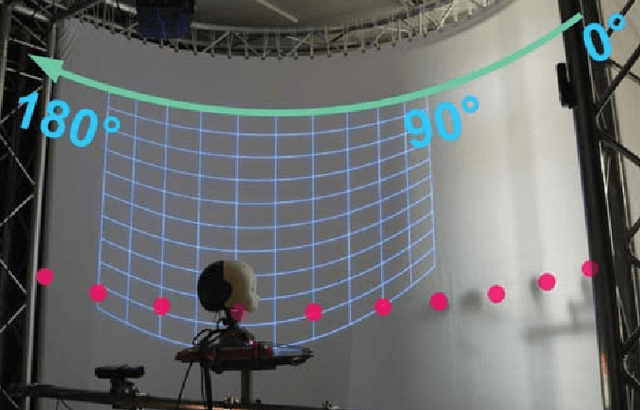
On the Robustness of Speech Emotion Recognition for Human-Robot Interaction with Deep Neural Networks
Apr 06, 2018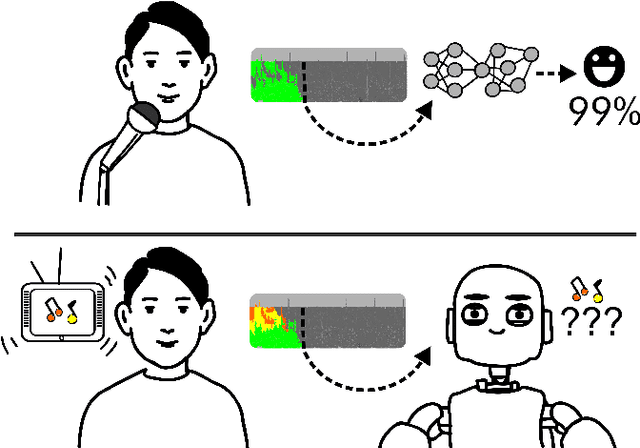
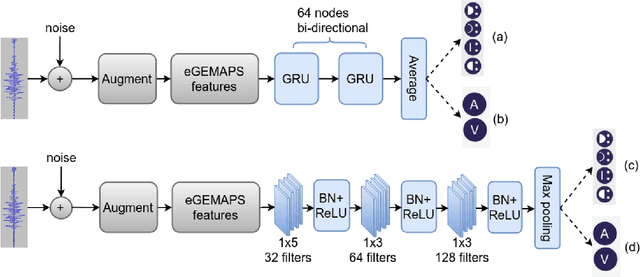

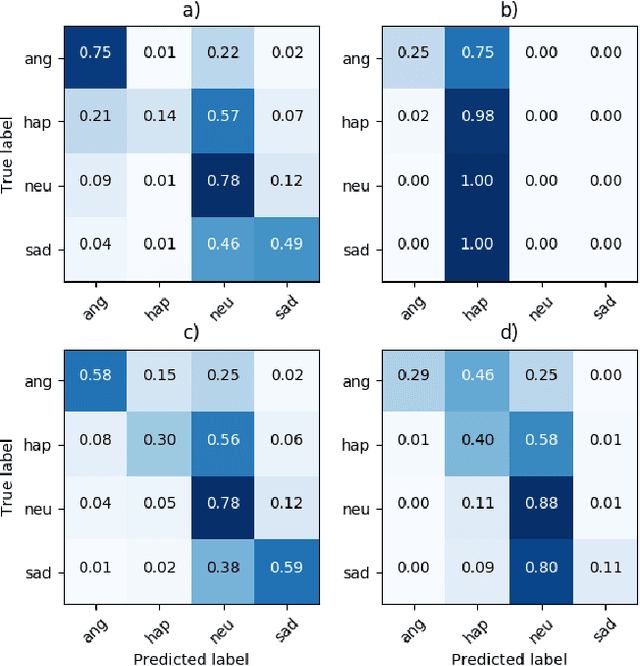
Speech emotion recognition (SER) is an important aspect of effective human-robot collaboration and received a lot of attention from the research community. For example, many neural network-based architectures were proposed recently and pushed the performance to a new level. However, the applicability of such neural SER models trained only on in-domain data to noisy conditions is currently under-researched. In this work, we evaluate the robustness of state-of-the-art neural acoustic emotion recognition models in human-robot interaction scenarios. We hypothesize that a robot's ego noise, room conditions, and various acoustic events that can occur in a home environment can significantly affect the performance of a model. We conduct several experiments on the iCub robot platform and propose several novel ways to reduce the gap between the model's performance during training and testing in real-world conditions. Furthermore, we observe large improvements in the model performance on the robot and demonstrate the necessity of introducing several data augmentation techniques like overlaying background noise and loudness variations to improve the robustness of the neural approaches.
EmoRL: Continuous Acoustic Emotion Classification using Deep Reinforcement Learning
Apr 03, 2018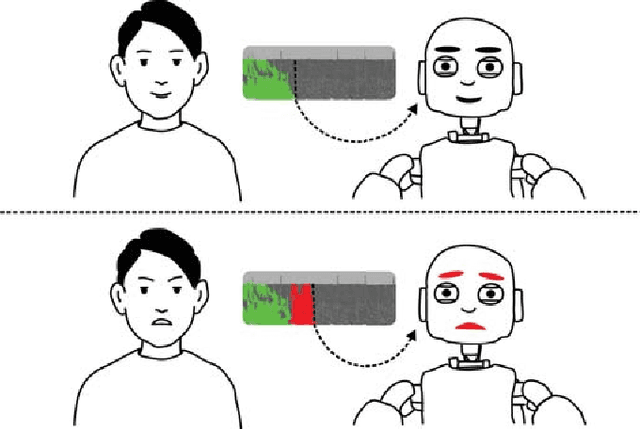
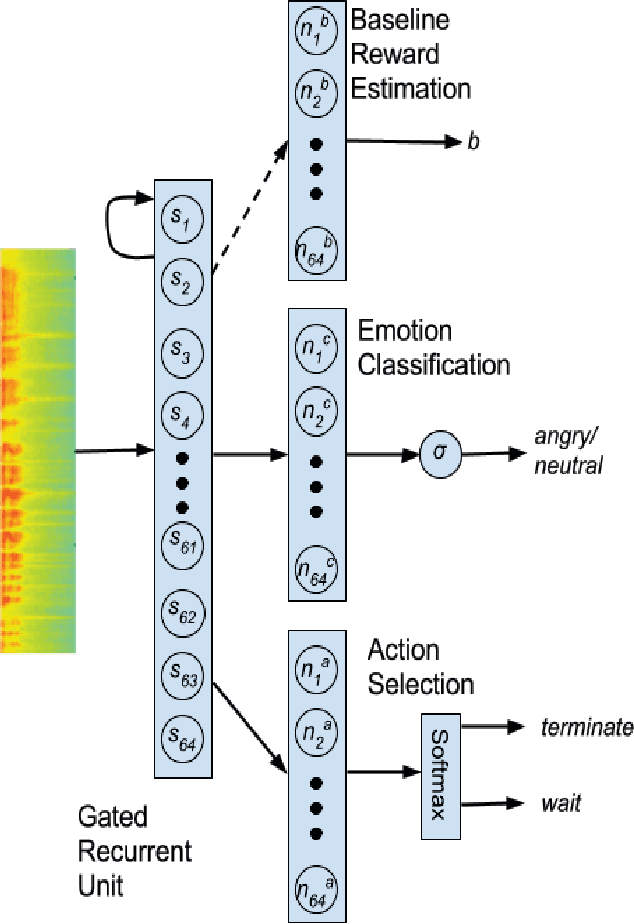
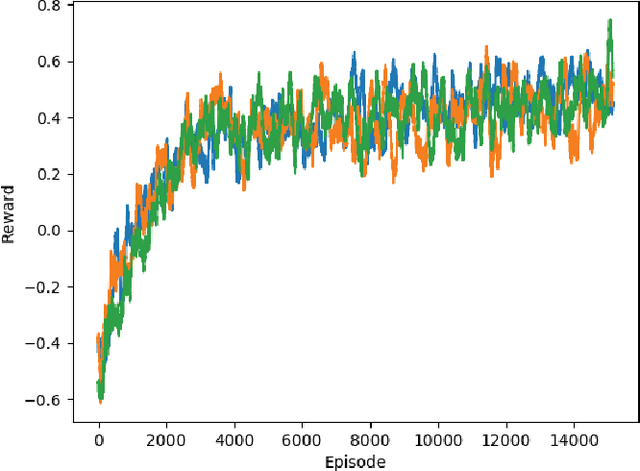
Acoustically expressed emotions can make communication with a robot more efficient. Detecting emotions like anger could provide a clue for the robot indicating unsafe/undesired situations. Recently, several deep neural network-based models have been proposed which establish new state-of-the-art results in affective state evaluation. These models typically start processing at the end of each utterance, which not only requires a mechanism to detect the end of an utterance but also makes it difficult to use them in a real-time communication scenario, e.g. human-robot interaction. We propose the EmoRL model that triggers an emotion classification as soon as it gains enough confidence while listening to a person speaking. As a result, we minimize the need for segmenting the audio signal for classification and achieve lower latency as the audio signal is processed incrementally. The method is competitive with the accuracy of a strong baseline model, while allowing much earlier prediction.
Reusing Neural Speech Representations for Auditory Emotion Recognition
Mar 30, 2018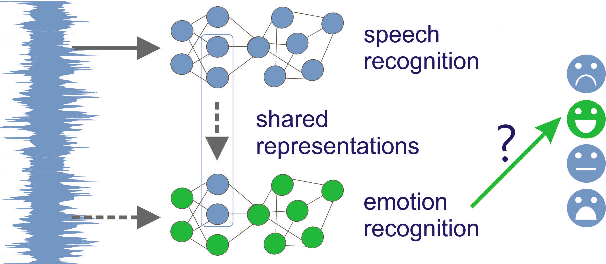
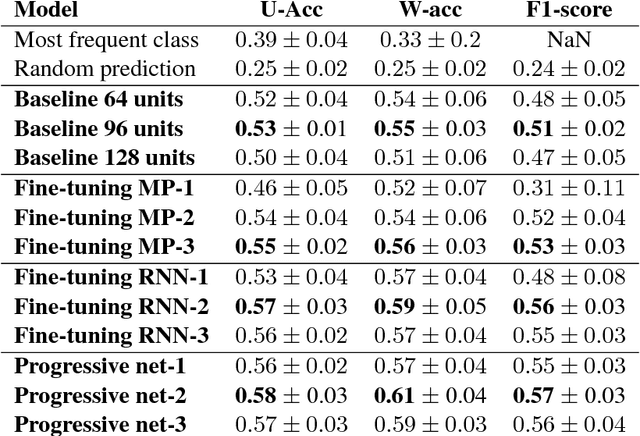
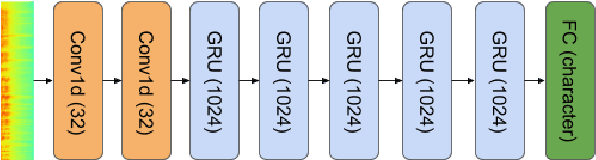
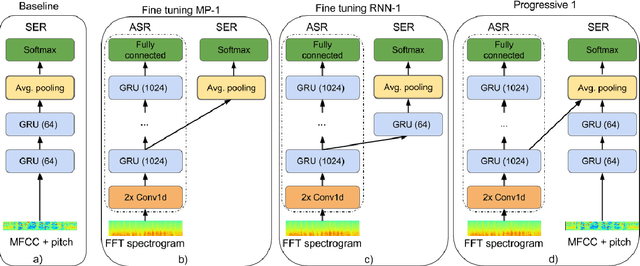
Acoustic emotion recognition aims to categorize the affective state of the speaker and is still a difficult task for machine learning models. The difficulties come from the scarcity of training data, general subjectivity in emotion perception resulting in low annotator agreement, and the uncertainty about which features are the most relevant and robust ones for classification. In this paper, we will tackle the latter problem. Inspired by the recent success of transfer learning methods we propose a set of architectures which utilize neural representations inferred by training on large speech databases for the acoustic emotion recognition task. Our experiments on the IEMOCAP dataset show ~10% relative improvements in the accuracy and F1-score over the baseline recurrent neural network which is trained end-to-end for emotion recognition.
Automatically augmenting an emotion dataset improves classification using audio
Mar 30, 2018
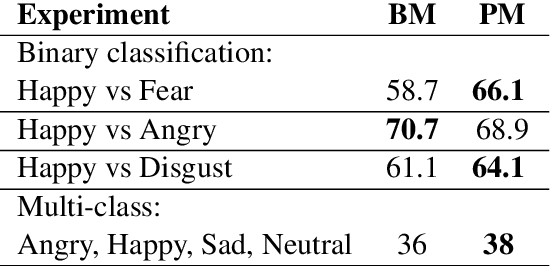
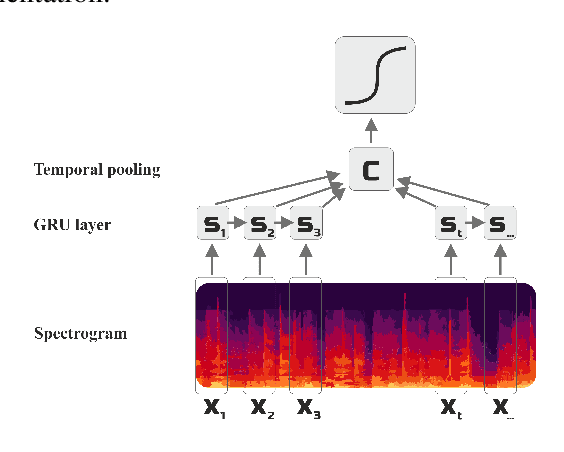
In this work, we tackle a problem of speech emotion classification. One of the issues in the area of affective computation is that the amount of annotated data is very limited. On the other hand, the number of ways that the same emotion can be expressed verbally is enormous due to variability between speakers. This is one of the factors that limits performance and generalization. We propose a simple method that extracts audio samples from movies using textual sentiment analysis. As a result, it is possible to automatically construct a larger dataset of audio samples with positive, negative emotional and neutral speech. We show that pretraining recurrent neural network on such a dataset yields better results on the challenging EmotiW corpus. This experiment shows a potential benefit of combining textual sentiment analysis with vocal information.