 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistTalk: Intensity Controllable Temporally Consistent Talking Head Generation with Diffusion Noise Search
Nov 10, 2025Recent advancements in video diffusion models have significantly enhanced audio-driven portrait animation. However, current methods still suffer from flickering, identity drift, and poor audio-visual synchronization. These issues primarily stem from entangled appearance-motion representations and unstable inference strategies. In this paper, we introduce \textbf{ConsistTalk}, a novel intensity-controllable and temporally consistent talking head generation framework with diffusion noise search inference. First, we propose \textbf{an optical flow-guided temporal module (OFT)} that decouples motion features from static appearance by leveraging facial optical flow, thereby reducing visual flicker and improving temporal consistency. Second, we present an \textbf{Audio-to-Intensity (A2I) model} obtained through multimodal teacher-student knowledge distillation. By transforming audio and facial velocity features into a frame-wise intensity sequence, the A2I model enables joint modeling of audio and visual motion, resulting in more natural dynamics. This further enables fine-grained, frame-wise control of motion dynamics while maintaining tight audio-visual synchronization. Third, we introduce a \textbf{diffusion noise initialization strategy (IC-Init)}. By enforcing explicit constraints on background coherence and motion continuity during inference-time noise search, we achieve better identity preservation and refine motion dynamics compared to the current autoregressive strategy. Extensive experiments demonstrate that ConsistTalk significantly outperforms prior methods in reducing flicker, preserving identity, and delivering temporally stable, high-fidelity talking head videos.
Joint Resource Management for Energy-efficient UAV-assisted SWIPT-MEC: A Deep Reinforcement Learning Approach
May 06, 2025The integration of simultaneous wireless information and power transfer (SWIPT) technology in 6G Internet of Things (IoT) networks faces significant challenges in remote areas and disaster scenarios where ground infrastructure is unavailable. This paper proposes a novel unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) system enhanced by directional antennas to provide both computational resources and energy support for ground IoT terminals. However, such systems require multiple trade-off policies to balance UAV energy consumption, terminal battery levels, and computational resource allocation under various constraints, including limited UAV battery capacity, non-linear energy harvesting characteristics, and dynamic task arrivals. To address these challenges comprehensively, we formulate a bi-objective optimization problem that simultaneously considers system energy efficiency and terminal battery sustainability. We then reformulate this non-convex problem with a hybrid solution space as a Markov decision process (MDP) and propose an improved soft actor-critic (SAC) algorithm with an action simplification mechanism to enhance its convergence and generalization capabilities. Simulation results have demonstrated that our proposed approach outperforms various baselines in different scenarios, achieving efficient energy management while maintaining high computational performance. Furthermore, our method shows strong generalization ability across different scenarios, particularly in complex environments, validating the effectiveness of our designed boundary penalty and charging reward mechanisms.
Fast Inference for Augmented Large Language Models
Oct 25, 2024



Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Efficient Inference for Augmented Large Language Models
Oct 23, 2024Augmented Large Language Models (LLMs) enhance the capabilities of standalone LLMs by integrating external data sources through API calls. In interactive LLM applications, efficient scheduling is crucial for maintaining low request completion times, directly impacting user engagement. However, these augmentations introduce scheduling challenges due to the need to manage limited memory for cached information (KV caches). As a result, traditional size-based scheduling algorithms, such as Shortest Job First (SJF), become less effective at minimizing completion times. Existing work focuses only on handling requests during API calls by preserving, discarding, or swapping memory without considering how to schedule requests with API calls. In this paper, we propose LAMPS, a novel LLM inference framework for augmented LLMs. LAMPS minimizes request completion time through a unified scheduling approach that considers the total length of requests and their handling strategies during API calls. Recognizing that LLM inference is memory-bound, our approach ranks requests based on their consumption of memory over time, which depends on both the output sizes and how a request is managed during its API calls. To implement our scheduling, LAMPS predicts the strategy that minimizes memory waste of a request during its API calls, aligning with but improving upon existing approaches. We also propose starvation prevention techniques and optimizations to mitigate the overhead of our scheduling. We implement LAMPS on top of vLLM and evaluate its performance against baseline LLM inference systems, demonstrating improvements in end-to-end latency by 27%-85% and reductions in TTFT by 4%-96% compared to the existing augmented-LLM system, with even greater gains over vLLM.
Communication Optimization for Distributed Training: Architecture, Advances, and Opportunities
Mar 12, 2024The past few years have witnessed the flourishing of large-scale deep neural network models with ever-growing parameter numbers. Training such large-scale models typically requires massive memory and computing resources that exceed those of a single GPU, necessitating distributed training. As GPU performance has rapidly evolved in recent years, computation time has shrunk, thereby increasing the proportion of communication in the overall training time. Therefore, optimizing communication for distributed training has become an urgent issue. In this article, we briefly introduce the general architecture of distributed deep neural network training and analyze relationships among Parallelization Strategy, Collective Communication Library, and Network from the perspective of communication optimization, which forms a three-layer paradigm. We then review current representative research advances with this three-layer paradigm. We find that layers in the current three-layer paradigm are relatively independent, but there is a rich design space for cross-layer collaborative optimization in distributed training scenarios. Therefore, we further advocate a communication-efficient five-layer paradigm underlining opportunities for collaboration designs and look forward to the perspectives of "Vertical", "Horizontal", "Intra-Inter" and "Host-Net" collaboration designs. We hope this article can shed some light on future research on communication optimization for distributed training.
Deep Squared Euclidean Approximation to the Levenshtein Distance for DNA Storage
Jul 11, 2022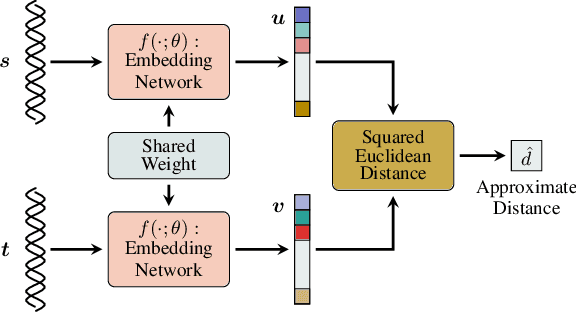
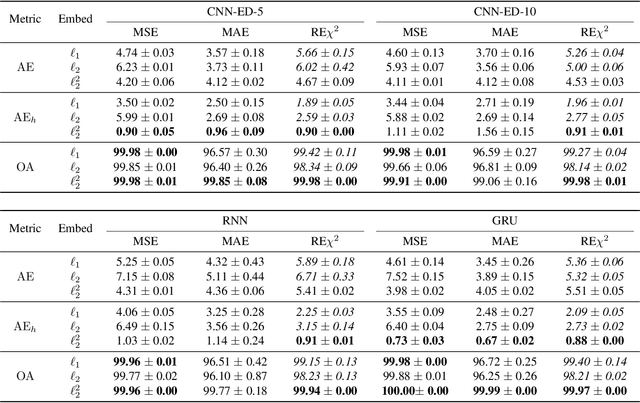
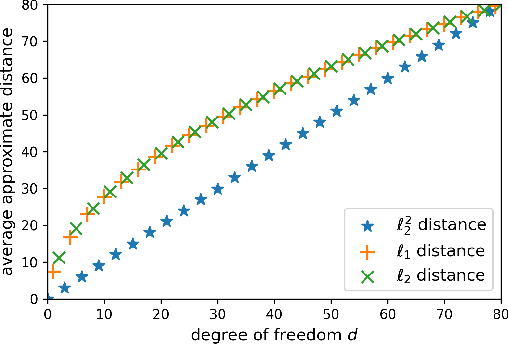
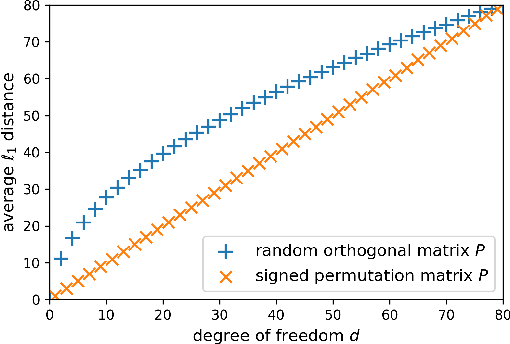
Storing information in DNA molecules is of great interest because of its advantages in longevity, high storage density, and low maintenance cost. A key step in the DNA storage pipeline is to efficiently cluster the retrieved DNA sequences according to their similarities. Levenshtein distance is the most suitable metric on the similarity between two DNA sequences, but it is inferior in terms of computational complexity and less compatible with mature clustering algorithms. In this work, we propose a novel deep squared Euclidean embedding for DNA sequences using Siamese neural network, squared Euclidean embedding, and chi-squared regression. The Levenshtein distance is approximated by the squared Euclidean distance between the embedding vectors, which is fast calculated and clustering algorithm friendly. The proposed approach is analyzed theoretically and experimentally. The results show that the proposed embedding is efficient and robust.