 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Denoising Neural Machine Translation Training with Trusted Data and Online Data Selection
Aug 31, 2018



Measuring domain relevance of data and identifying or selecting well-fit domain data for machine translation (MT) is a well-studied topic, but denoising is not yet. Denoising is concerned with a different type of data quality and tries to reduce the negative impact of data noise on MT training, in particular, neural MT (NMT) training. This paper generalizes methods for measuring and selecting data for domain MT and applies them to denoising NMT training. The proposed approach uses trusted data and a denoising curriculum realized by online data selection. Intrinsic and extrinsic evaluations of the approach show its significant effectiveness for NMT to train on data with severe noise.
GroupReduce: Block-Wise Low-Rank Approximation for Neural Language Model Shrinking
Jun 18, 2018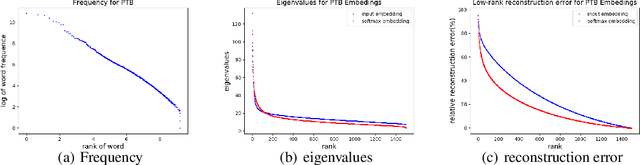

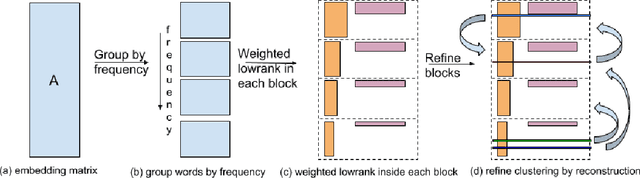
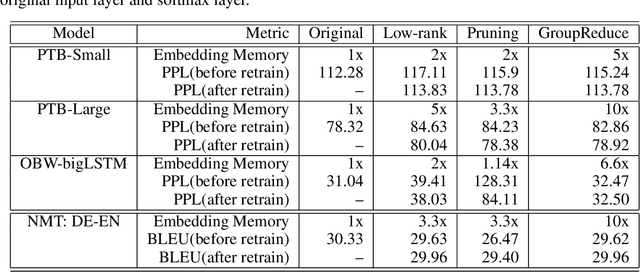
Model compression is essential for serving large deep neural nets on devices with limited resources or applications that require real-time responses. As a case study, a state-of-the-art neural language model usually consists of one or more recurrent layers sandwiched between an embedding layer used for representing input tokens and a softmax layer for generating output tokens. For problems with a very large vocabulary size, the embedding and the softmax matrices can account for more than half of the model size. For instance, the bigLSTM model achieves state-of- the-art performance on the One-Billion-Word (OBW) dataset with around 800k vocabulary, and its word embedding and softmax matrices use more than 6GBytes space, and are responsible for over 90% of the model parameters. In this paper, we propose GroupReduce, a novel compression method for neural language models, based on vocabulary-partition (block) based low-rank matrix approximation and the inherent frequency distribution of tokens (the power-law distribution of words). The experimental results show our method can significantly outperform traditional compression methods such as low-rank approximation and pruning. On the OBW dataset, our method achieved 6.6 times compression rate for the embedding and softmax matrices, and when combined with quantization, our method can achieve 26 times compression rate, which translates to a factor of 12.8 times compression for the entire model with very little degradation in perplexity.
N-gram Language Modeling using Recurrent Neural Network Estimation
Jun 20, 2017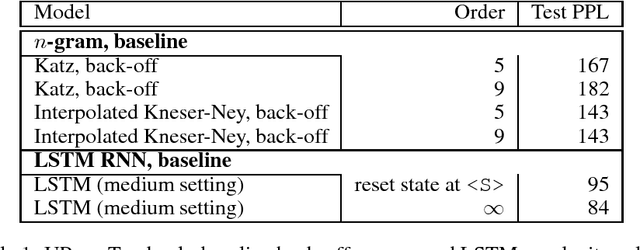
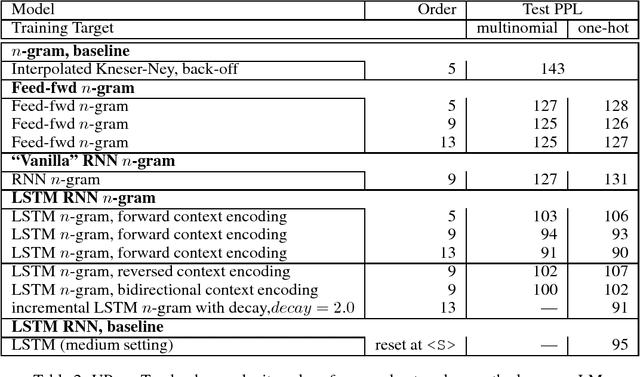


We investigate the effective memory depth of RNN models by using them for $n$-gram language model (LM) smoothing. Experiments on a small corpus (UPenn Treebank, one million words of training data and 10k vocabulary) have found the LSTM cell with dropout to be the best model for encoding the $n$-gram state when compared with feed-forward and vanilla RNN models. When preserving the sentence independence assumption the LSTM $n$-gram matches the LSTM LM performance for $n=9$ and slightly outperforms it for $n=13$. When allowing dependencies across sentence boundaries, the LSTM $13$-gram almost matches the perplexity of the unlimited history LSTM LM. LSTM $n$-gram smoothing also has the desirable property of improving with increasing $n$-gram order, unlike the Katz or Kneser-Ney back-off estimators. Using multinomial distributions as targets in training instead of the usual one-hot target is only slightly beneficial for low $n$-gram orders. Experiments on the One Billion Words benchmark show that the results hold at larger scale: while LSTM smoothing for short $n$-gram contexts does not provide significant advantages over classic N-gram models, it becomes effective with long contexts ($n > 5$); depending on the task and amount of data it can match fully recurrent LSTM models at about $n=13$. This may have implications when modeling short-format text, e.g. voice search/query LMs. Building LSTM $n$-gram LMs may be appealing for some practical situations: the state in a $n$-gram LM can be succinctly represented with $(n-1)*4$ bytes storing the identity of the words in the context and batches of $n$-gram contexts can be processed in parallel. On the downside, the $n$-gram context encoding computed by the LSTM is discarded, making the model more expensive than a regular recurrent LSTM LM.
Multinomial Loss on Held-out Data for the Sparse Non-negative Matrix Language Model
Feb 22, 2016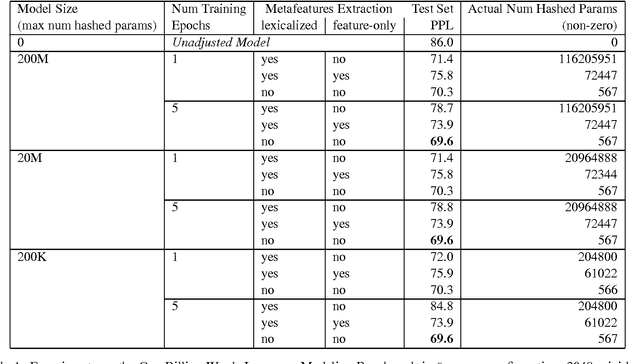
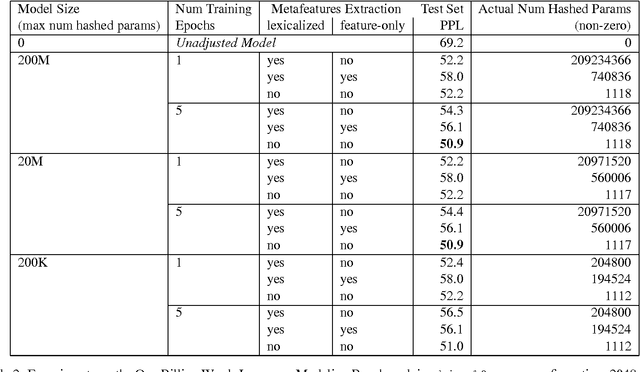

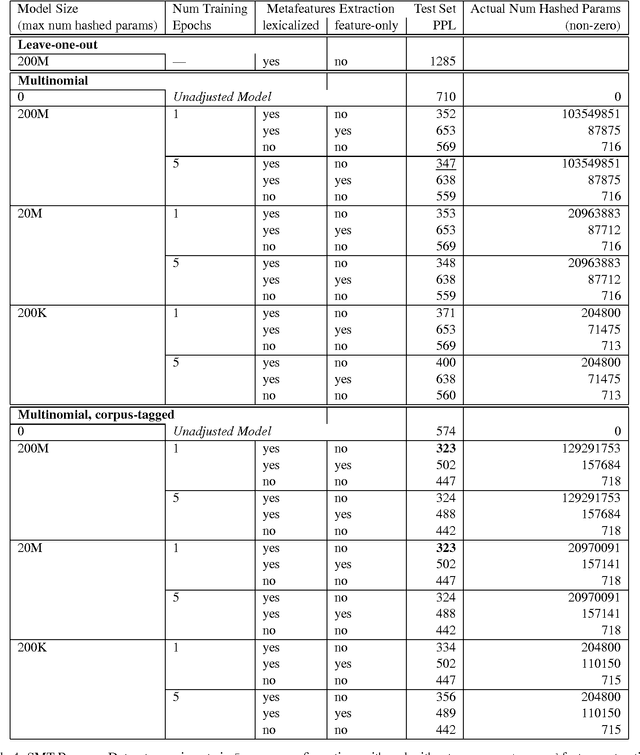
We describe Sparse Non-negative Matrix (SNM) language model estimation using multinomial loss on held-out data. Being able to train on held-out data is important in practical situations where the training data is usually mismatched from the held-out/test data. It is also less constrained than the previous training algorithm using leave-one-out on training data: it allows the use of richer meta-features in the adjustment model, e.g. the diversity counts used by Kneser-Ney smoothing which would be difficult to deal with correctly in leave-one-out training. In experiments on the one billion words language modeling benchmark, we are able to slightly improve on our previous results which use a different loss function, and employ leave-one-out training on a subset of the main training set. Surprisingly, an adjustment model with meta-features that discard all lexical information can perform as well as lexicalized meta-features. We find that fairly small amounts of held-out data (on the order of 30-70 thousand words) are sufficient for training the adjustment model. In a real-life scenario where the training data is a mix of data sources that are imbalanced in size, and of different degrees of relevance to the held-out and test data, taking into account the data source for a given skip-/n-gram feature and combining them for best performance on held-out/test data improves over skip-/n-gram SNM models trained on pooled data by about 8% in the SMT setup, or as much as 15% in the ASR/IME setup. The ability to mix various data sources based on how relevant they are to a mismatched held-out set is probably the most attractive feature of the new estimation method for SNM LM.
Skip-gram Language Modeling Using Sparse Non-negative Matrix Probability Estimation
Jun 26, 2015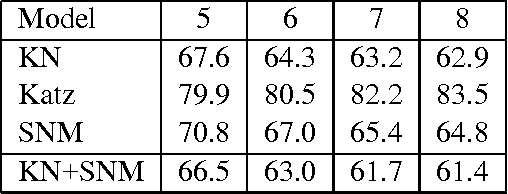


We present a novel family of language model (LM) estimation techniques named Sparse Non-negative Matrix (SNM) estimation. A first set of experiments empirically evaluating it on the One Billion Word Benchmark shows that SNM $n$-gram LMs perform almost as well as the well-established Kneser-Ney (KN) models. When using skip-gram features the models are able to match the state-of-the-art recurrent neural network (RNN) LMs; combining the two modeling techniques yields the best known result on the benchmark. The computational advantages of SNM over both maximum entropy and RNN LM estimation are probably its main strength, promising an approach that has the same flexibility in combining arbitrary features effectively and yet should scale to very large amounts of data as gracefully as $n$-gram LMs do.
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
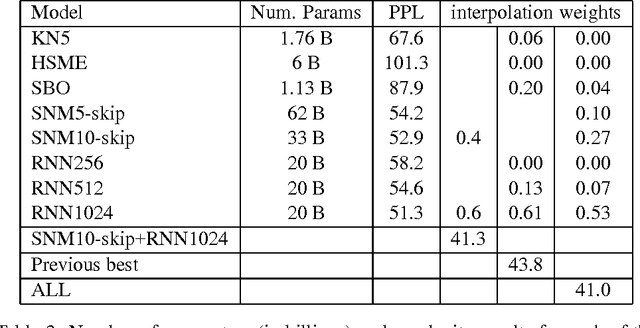
Mar 04, 2014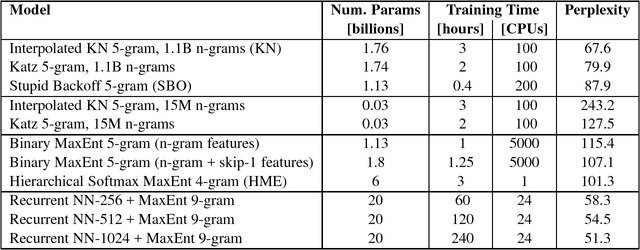

We propose a new benchmark corpus to be used for measuring progress in statistical language modeling. With almost one billion words of training data, we hope this benchmark will be useful to quickly evaluate novel language modeling techniques, and to compare their contribution when combined with other advanced techniques. We show performance of several well-known types of language models, with the best results achieved with a recurrent neural network based language model. The baseline unpruned Kneser-Ney 5-gram model achieves perplexity 67.6; a combination of techniques leads to 35% reduction in perplexity, or 10% reduction in cross-entropy (bits), over that baseline. The benchmark is available as a code.google.com project; besides the scripts needed to rebuild the training/held-out data, it also makes available log-probability values for each word in each of ten held-out data sets, for each of the baseline n-gram models.
Large Scale Distributed Acoustic Modeling With Back-off N-grams
Feb 05, 2013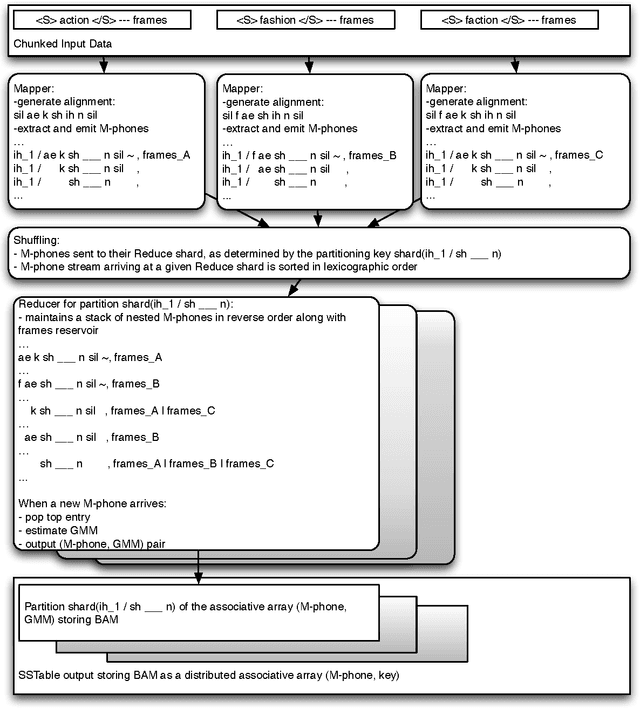
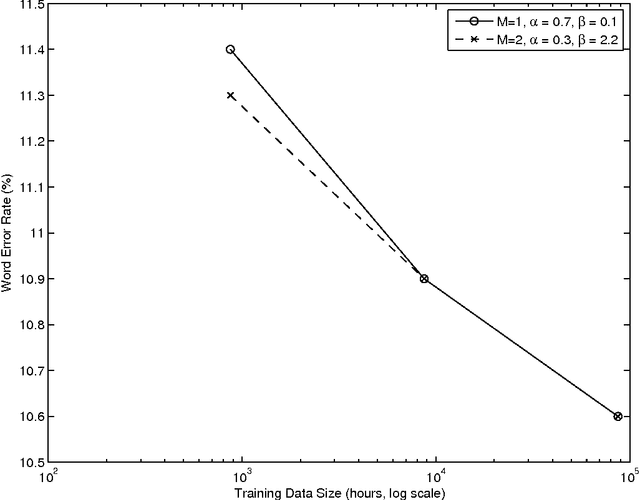
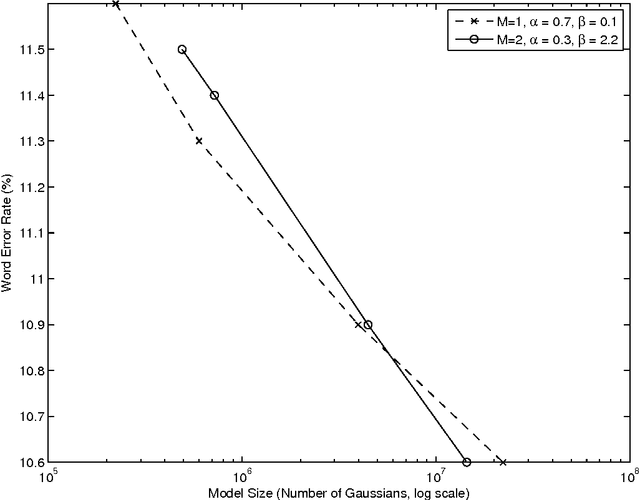
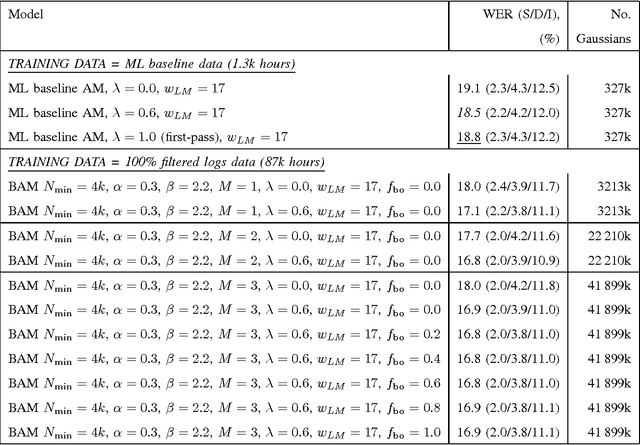
The paper revives an older approach to acoustic modeling that borrows from n-gram language modeling in an attempt to scale up both the amount of training data and model size (as measured by the number of parameters in the model), to approximately 100 times larger than current sizes used in automatic speech recognition. In such a data-rich setting, we can expand the phonetic context significantly beyond triphones, as well as increase the number of Gaussian mixture components for the context-dependent states that allow it. We have experimented with contexts that span seven or more context-independent phones, and up to 620 mixture components per state. Dealing with unseen phonetic contexts is accomplished using the familiar back-off technique used in language modeling due to implementation simplicity. The back-off acoustic model is estimated, stored and served using MapReduce distributed computing infrastructure. Speech recognition experiments are carried out in an N-best list rescoring framework for Google Voice Search. Training big models on large amounts of data proves to be an effective way to increase the accuracy of a state-of-the-art automatic speech recognition system. We use 87,000 hours of training data (speech along with transcription) obtained by filtering utterances in Voice Search logs on automatic speech recognition confidence. Models ranging in size between 20--40 million Gaussians are estimated using maximum likelihood training. They achieve relative reductions in word-error-rate of 11% and 6% when combined with first-pass models trained using maximum likelihood, and boosted maximum mutual information, respectively. Increasing the context size beyond five phones (quinphones) does not help.
Large Scale Language Modeling in Automatic Speech Recognition
Oct 31, 2012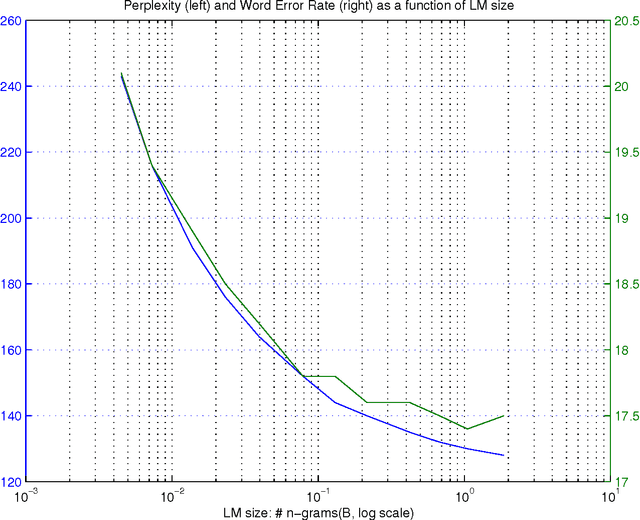
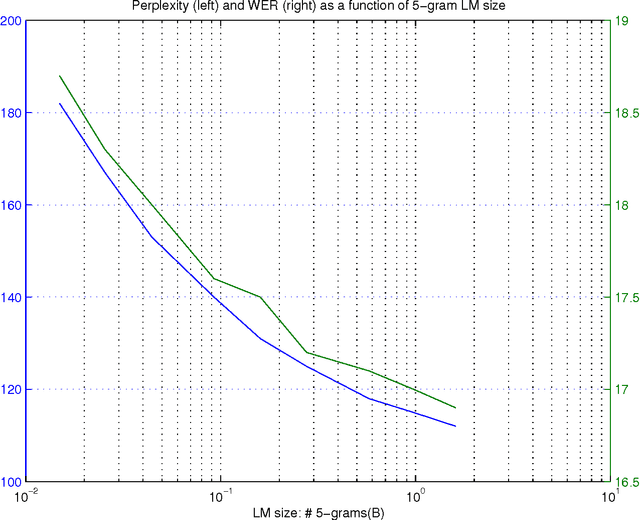


Large language models have been proven quite beneficial for a variety of automatic speech recognition tasks in Google. We summarize results on Voice Search and a few YouTube speech transcription tasks to highlight the impact that one can expect from increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, language model size and amount of work and care put into integrating them in the lattice rescoring step we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points between 17% and 52% word error rate.
Optimal size, freshness and time-frame for voice search vocabulary
Oct 31, 2012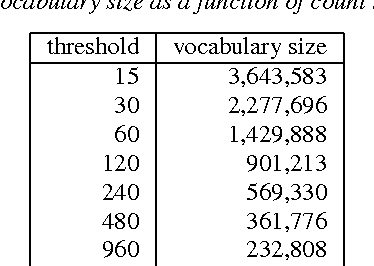
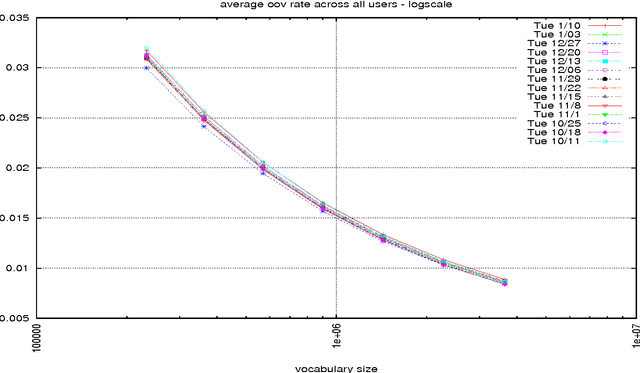
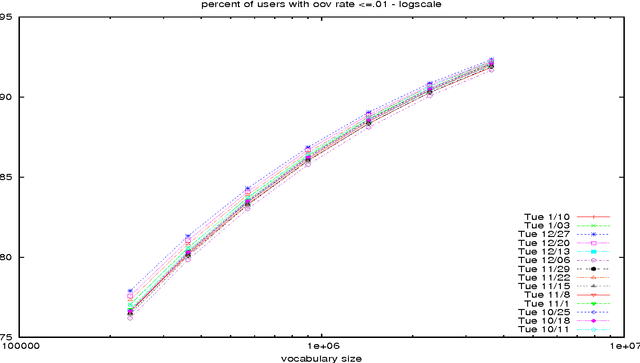
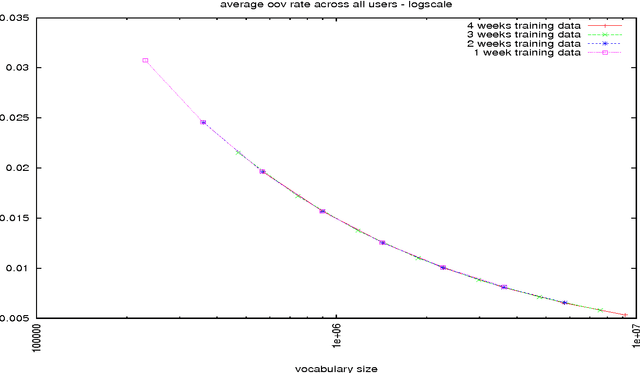
In this paper, we investigate how to optimize the vocabulary for a voice search language model. The metric we optimize over is the out-of-vocabulary (OoV) rate since it is a strong indicator of user experience. In a departure from the usual way of measuring OoV rates, web search logs allow us to compute the per-session OoV rate and thus estimate the percentage of users that experience a given OoV rate. Under very conservative text normalization, we find that a voice search vocabulary consisting of 2 to 2.5 million words extracted from 1 week of search query data will result in an aggregate OoV rate of 1%; at that size, the same OoV rate will also be experienced by 90% of users. The number of words included in the vocabulary is a stable indicator of the OoV rate. Altering the freshness of the vocabulary or the duration of the time window over which the training data is gathered does not significantly change the OoV rate. Surprisingly, a significantly larger vocabulary (approximately 10 million words) is required to guarantee OoV rates below 1% for 95% of the users.